Rapidminer 9学习笔记,从了解rapidminer到上手操作简单的流程处理,然后再进一步深入学习
一、了解rapidminer数据挖掘工具
1.1功能界面
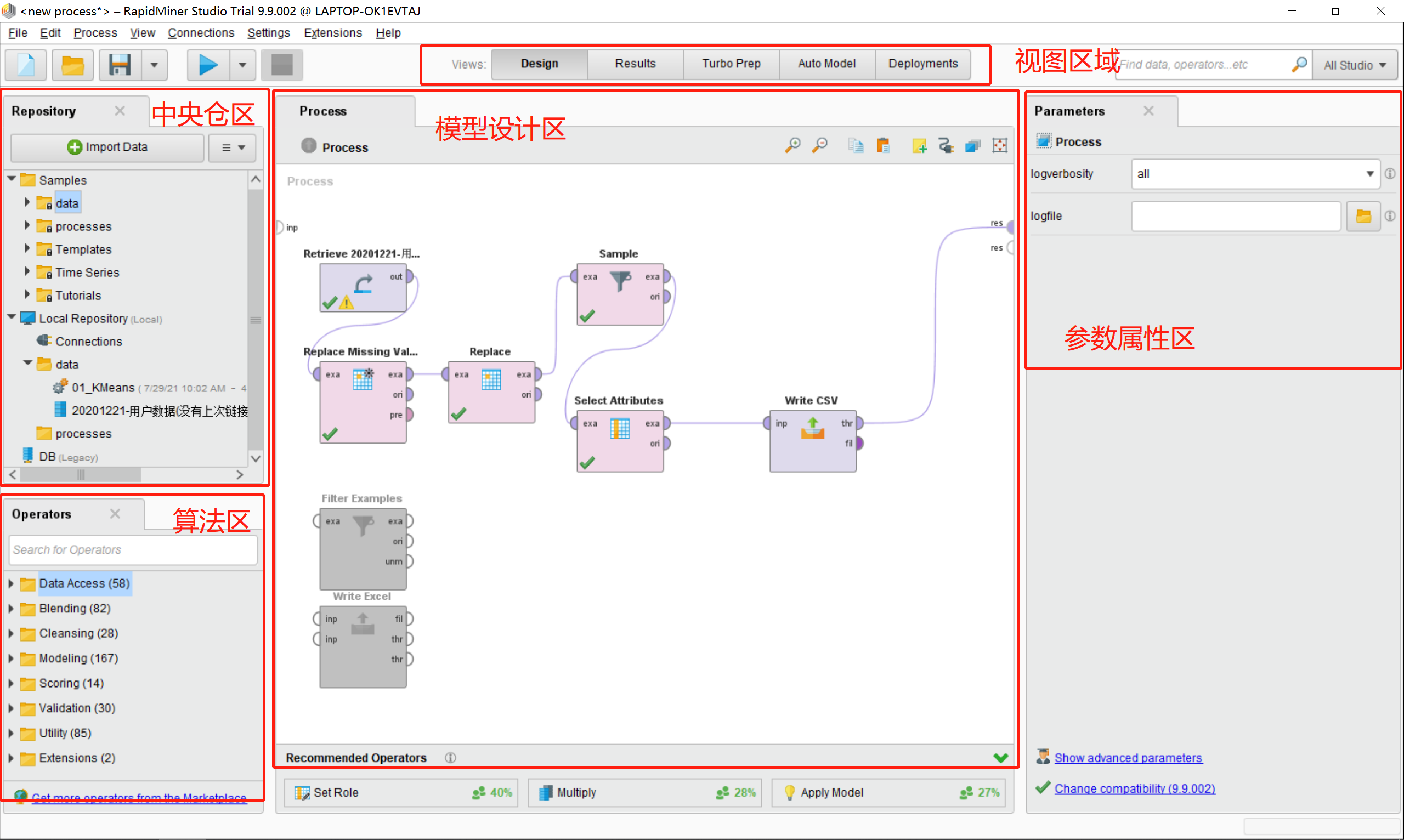
1.2功能区域说明
·视图区
主要包括:
- 设计模型区域的展示
- 根据创建好的模型输出的执行结果展示
·中央仓区
主要包括内容:
- 工具自带的一些示例数据和模型
- 自己创建的模型
·算法区
主要包括内容:
- 工具自带的算法,用户可以根据自身需要进行使用这些算法
·模型设计区
主要包括内容:
- 用来展示工具自带的模型结构
- 用户可以自己导入数据设计自己的模型
- inp代表输入,res代表事件的输出,inp和res是rapidminer固有的属性
·参数属性区
主要包括:
1.用来对模型设计区展示的算法的对应参数属性的设置
二、数据预处理建模
2.1新建流程
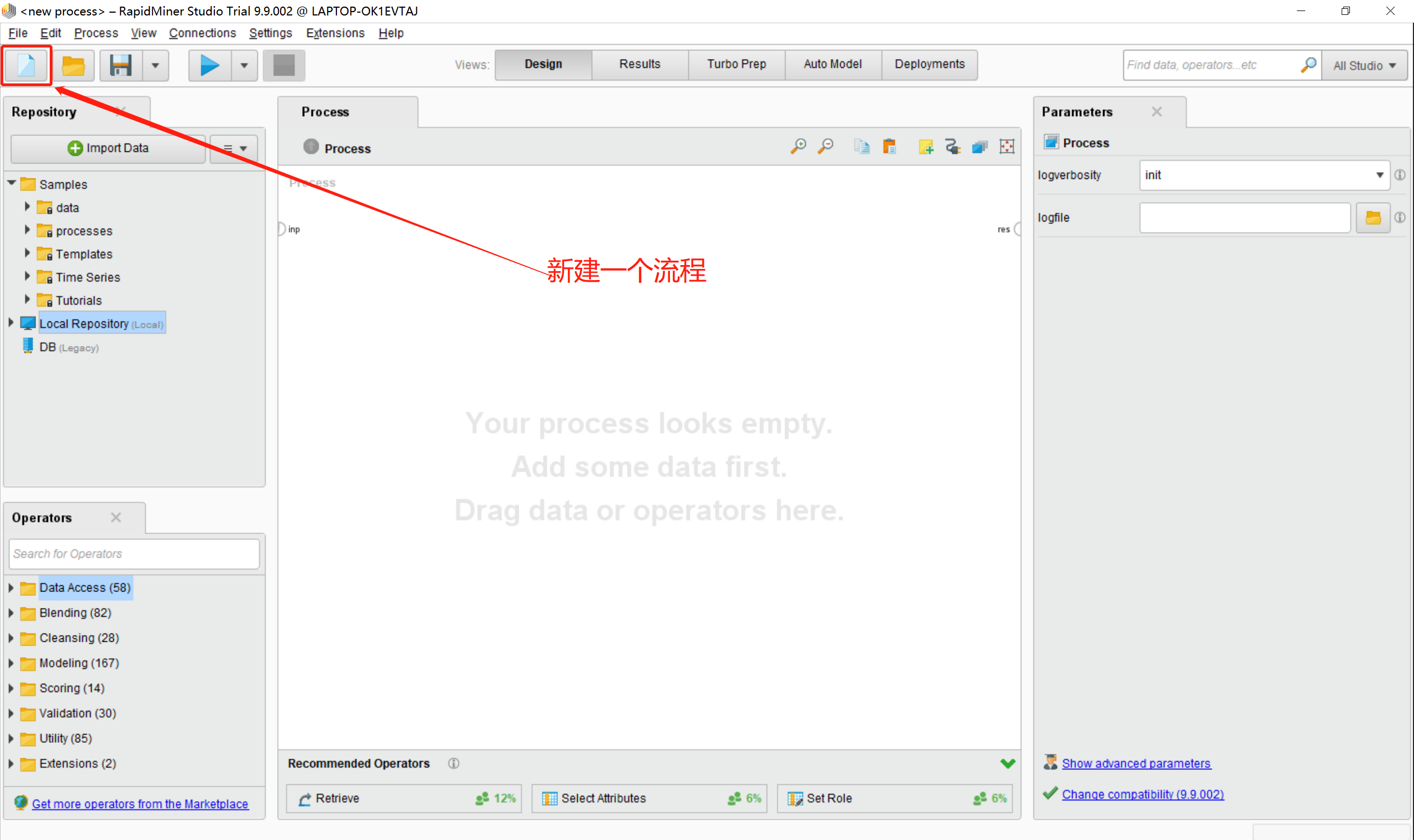
打开rapidminer界面之后,点击左上角的“新建”按钮,新建一个流程,在模型设计区域会出现一个空白的process。
2.2导入数据
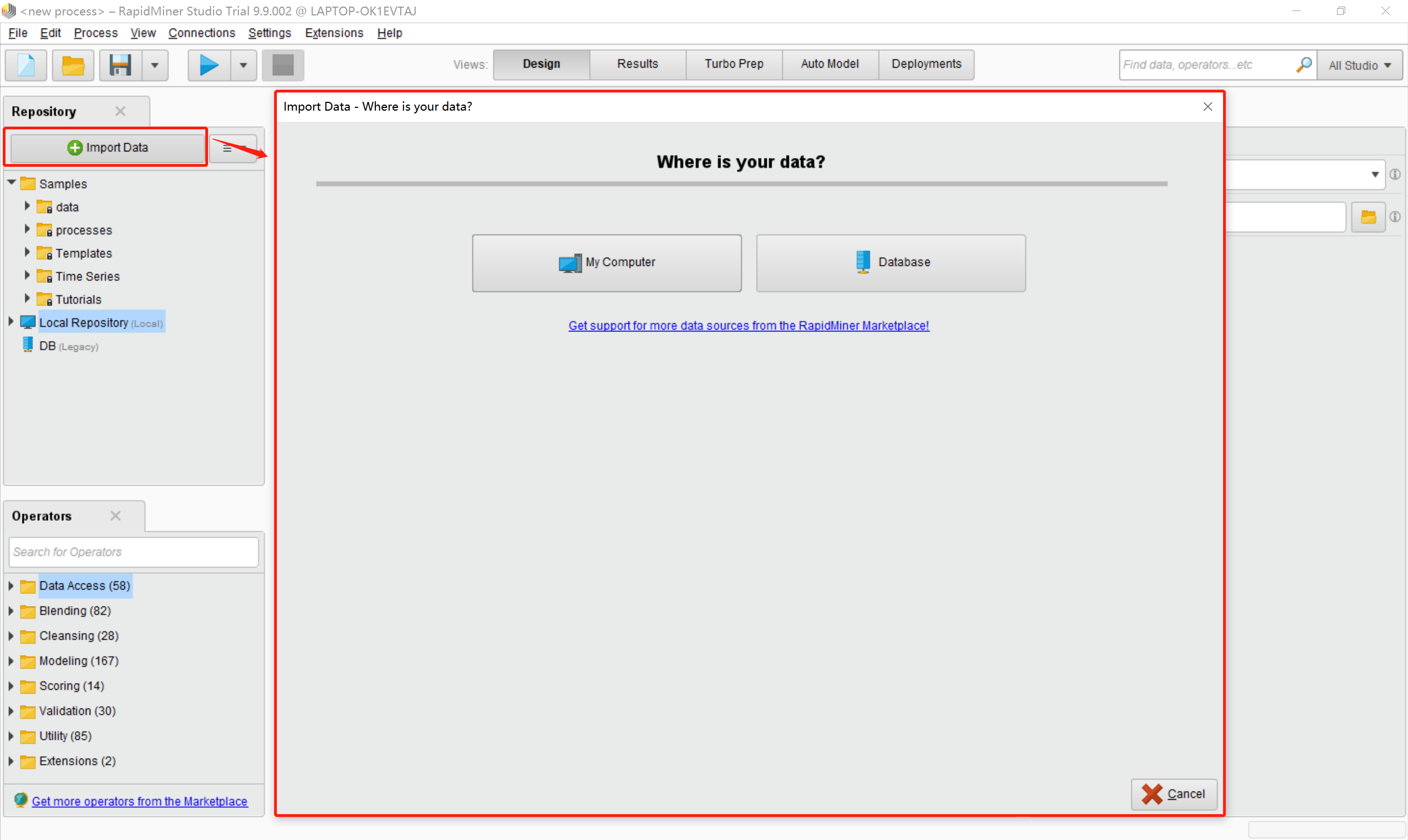
点击左侧的Repository中的Import Data按钮,该按钮表示导入数据,点击之后会弹出一个窗口,数据来源包括My Computer和Database,我们这里以本地数据为例,选择My Computer按钮。
点击My Computer按钮后选择自己本地的数据,如下图所示:
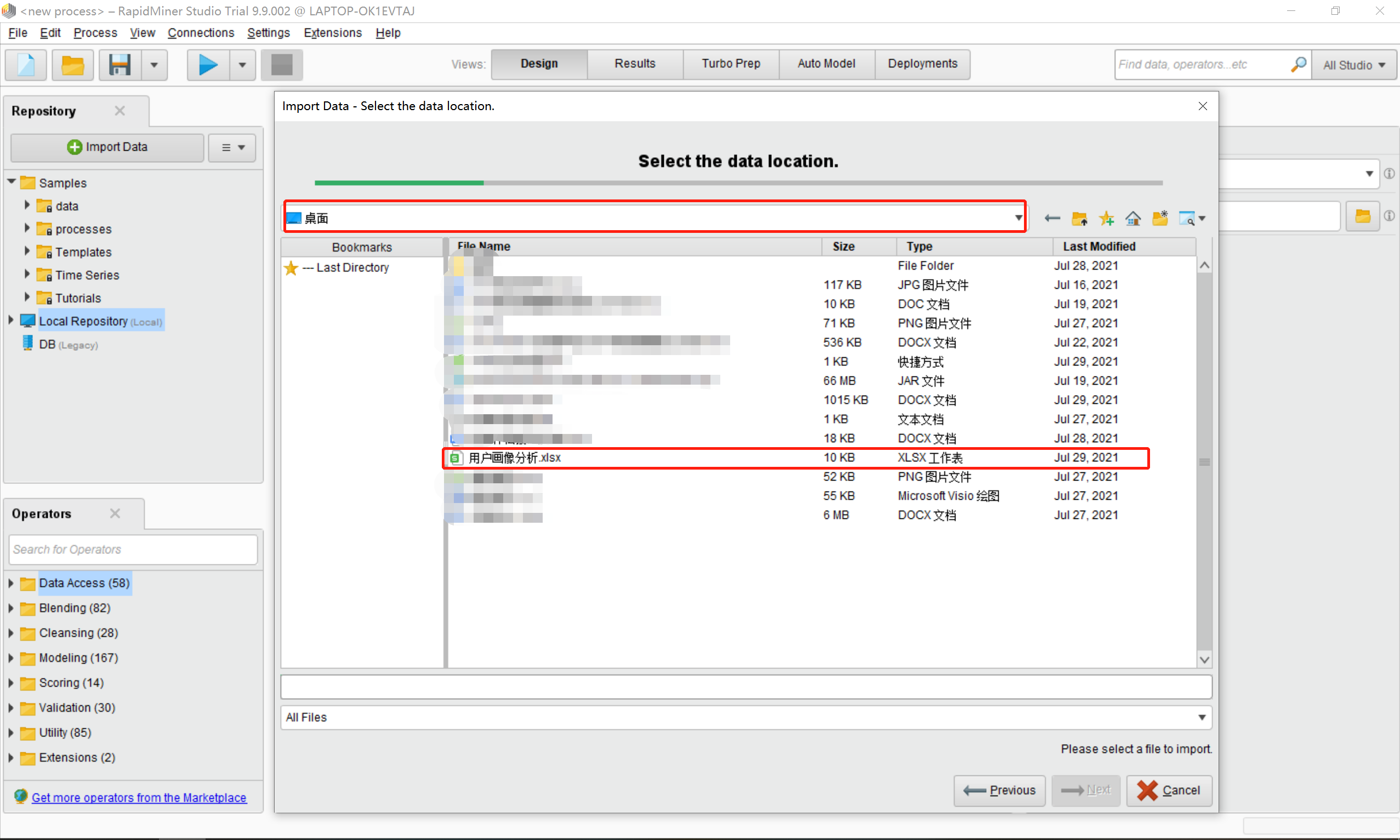
然后选择next,直到finish(这里注意,本地的数据的列名称不要重复,否则会提示错误)
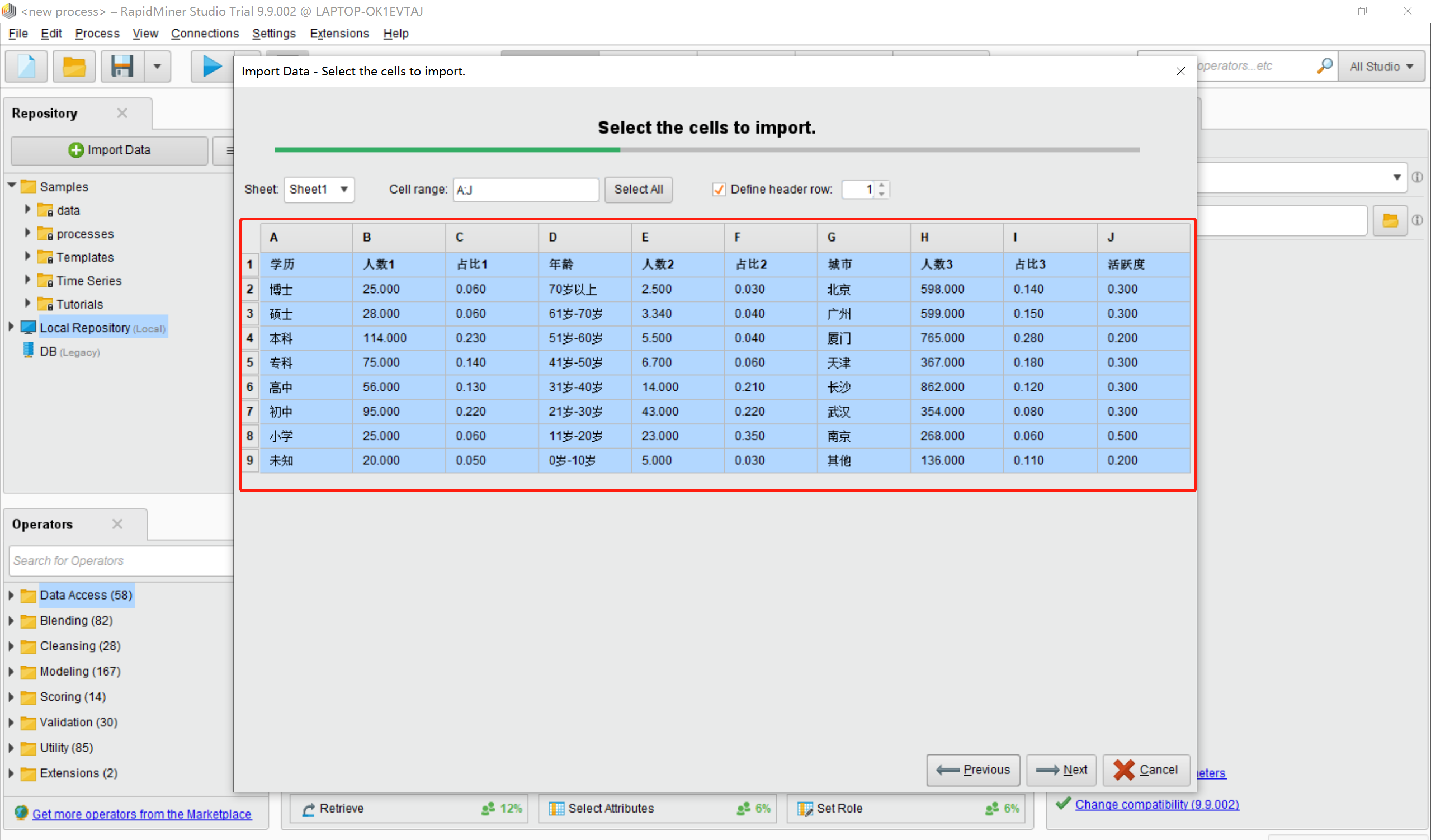
这是导入数据时的界面
数据文件导入成功后,在rapidminer工具的Results选项卡中会展示导入的数据,同时会在Repository栏目中展示出导入的文件名称,如下图所示:
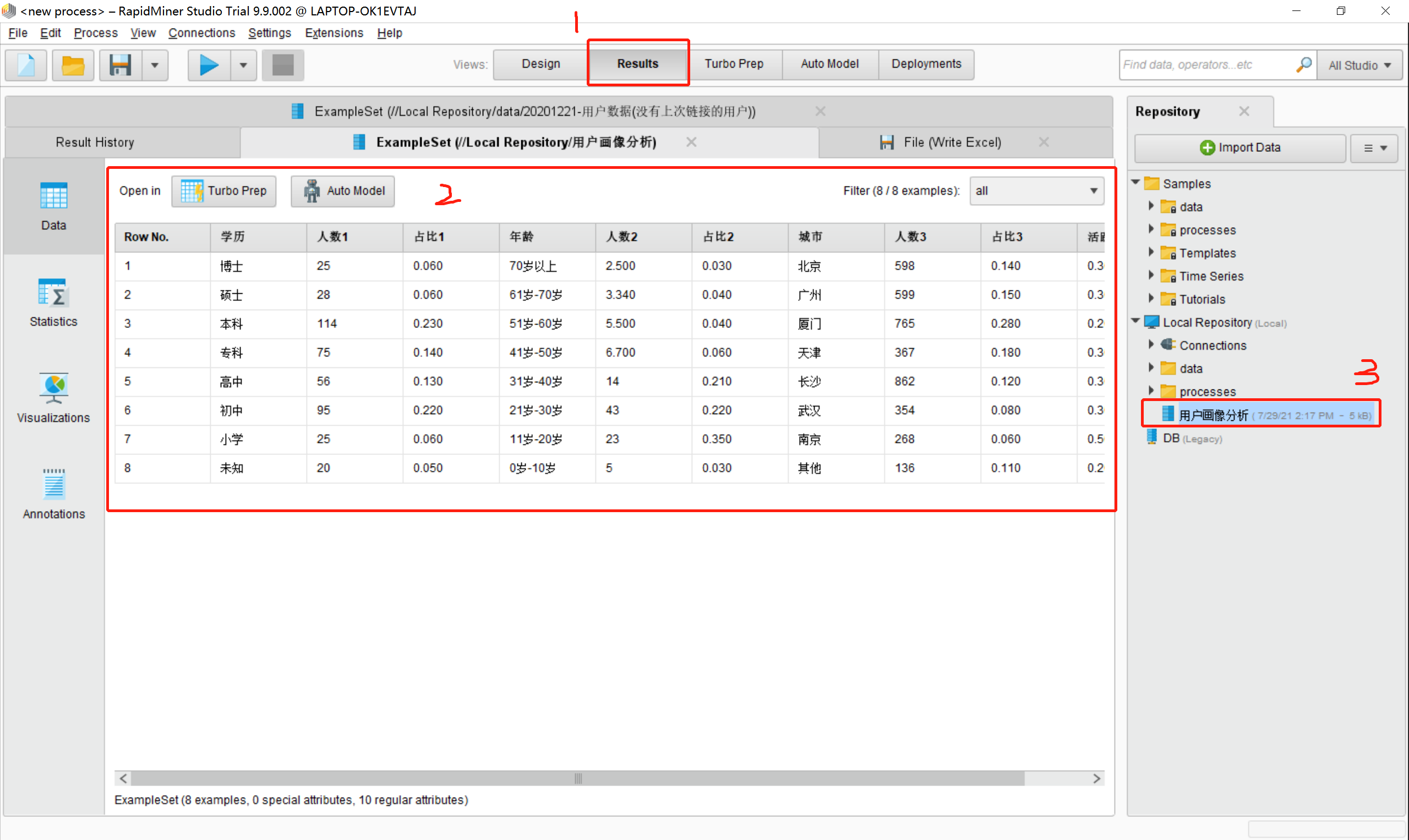
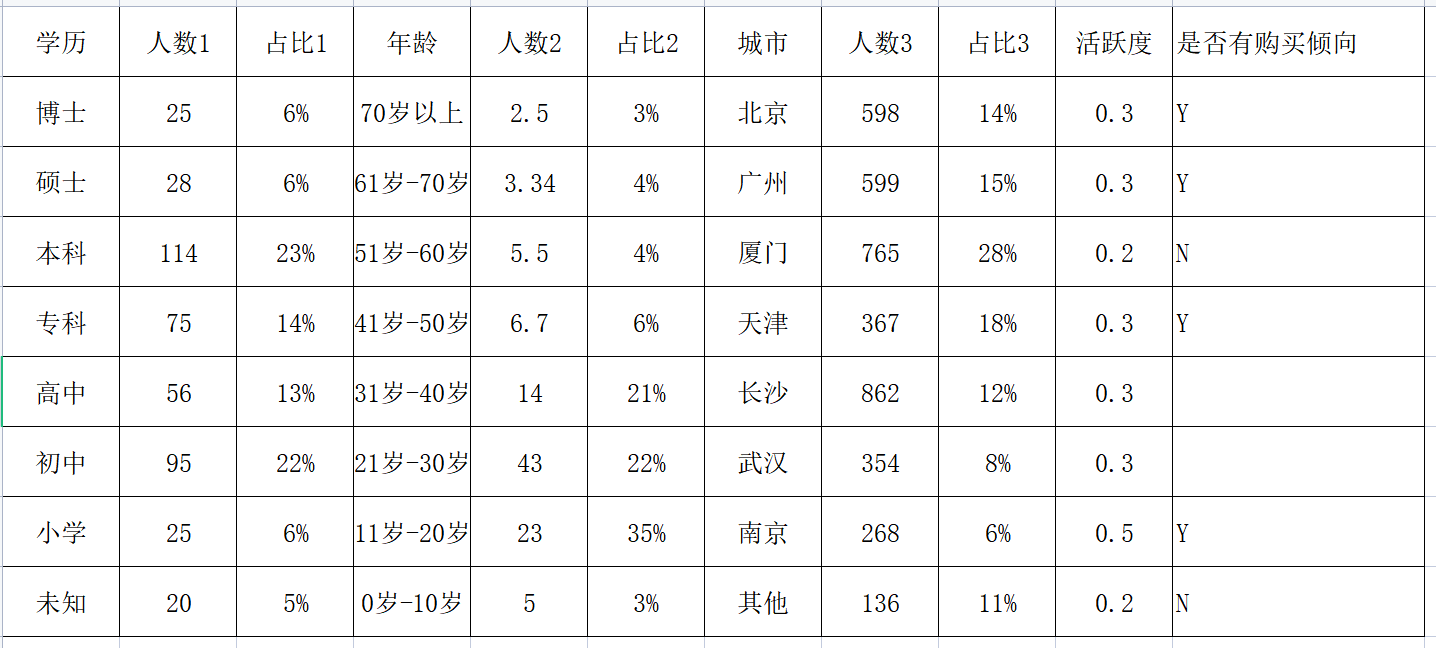
注意:如果没有数据可以根据下图去自行建立一个excel表数据:
2.3数据预处理过程
- 新建完流程并成功导入数据文件之后,在rapidminer中选择Design选项卡
- 在Repository栏目中找到导入的数据文件
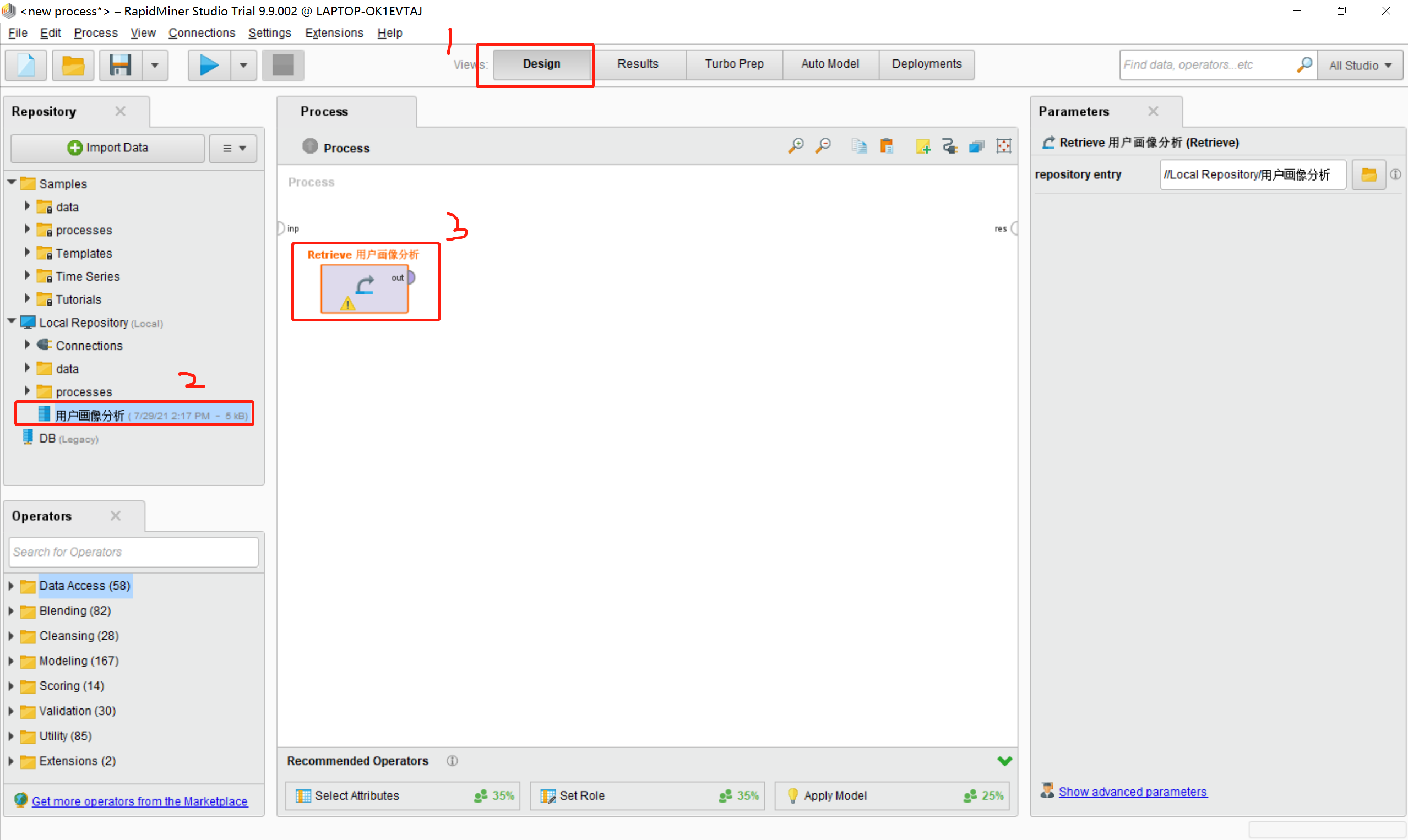
- 将数据文件拖到process区域中,如下图所示:
4.分析用户画像数据,发现数据中包含缺省值,所以我们需要将数据中的缺少值进行处理,查看数据中是否有缺省值,如图所示:
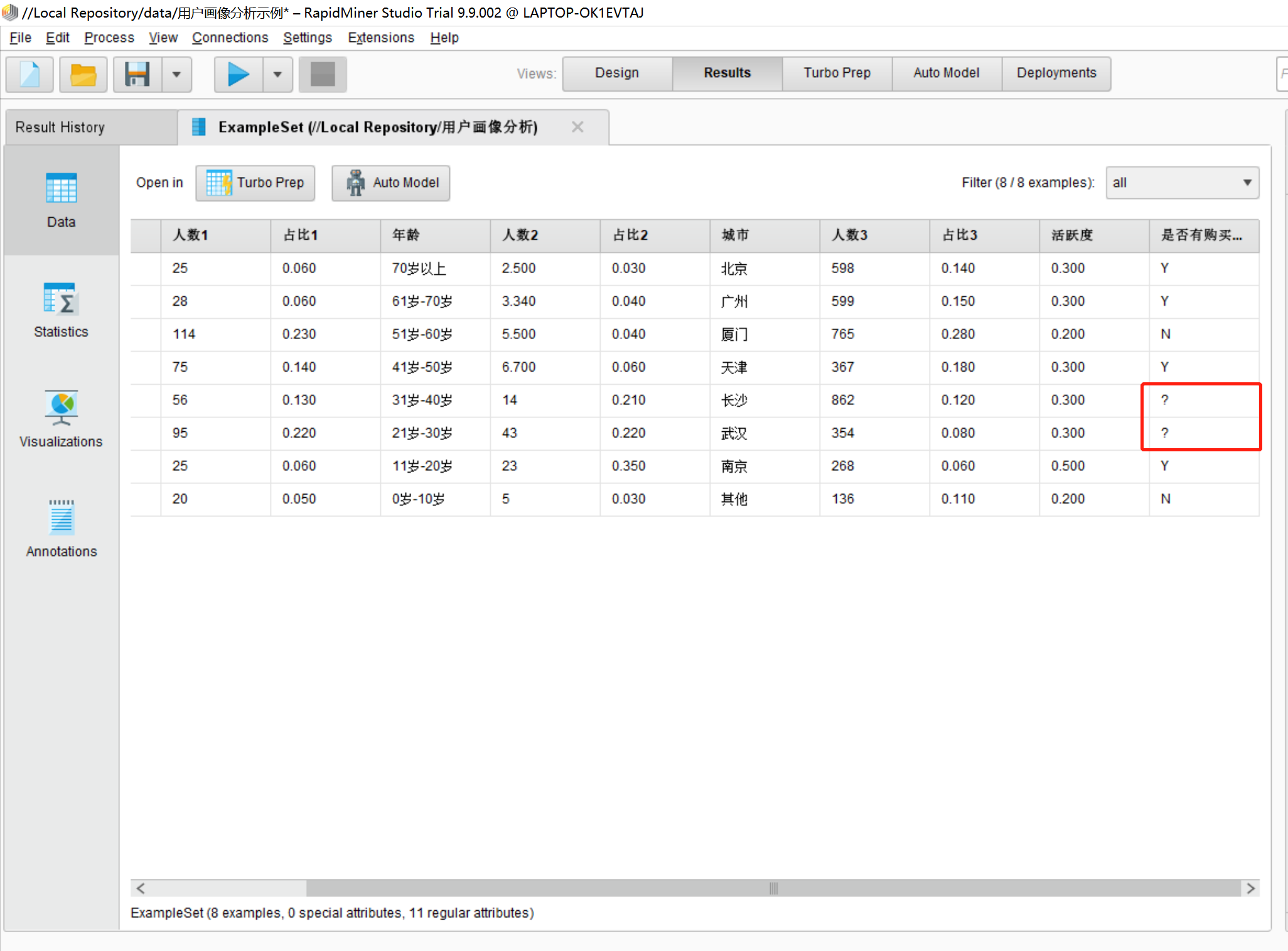 导入的数据中某一字段下没有数据
导入的数据中某一字段下没有数据
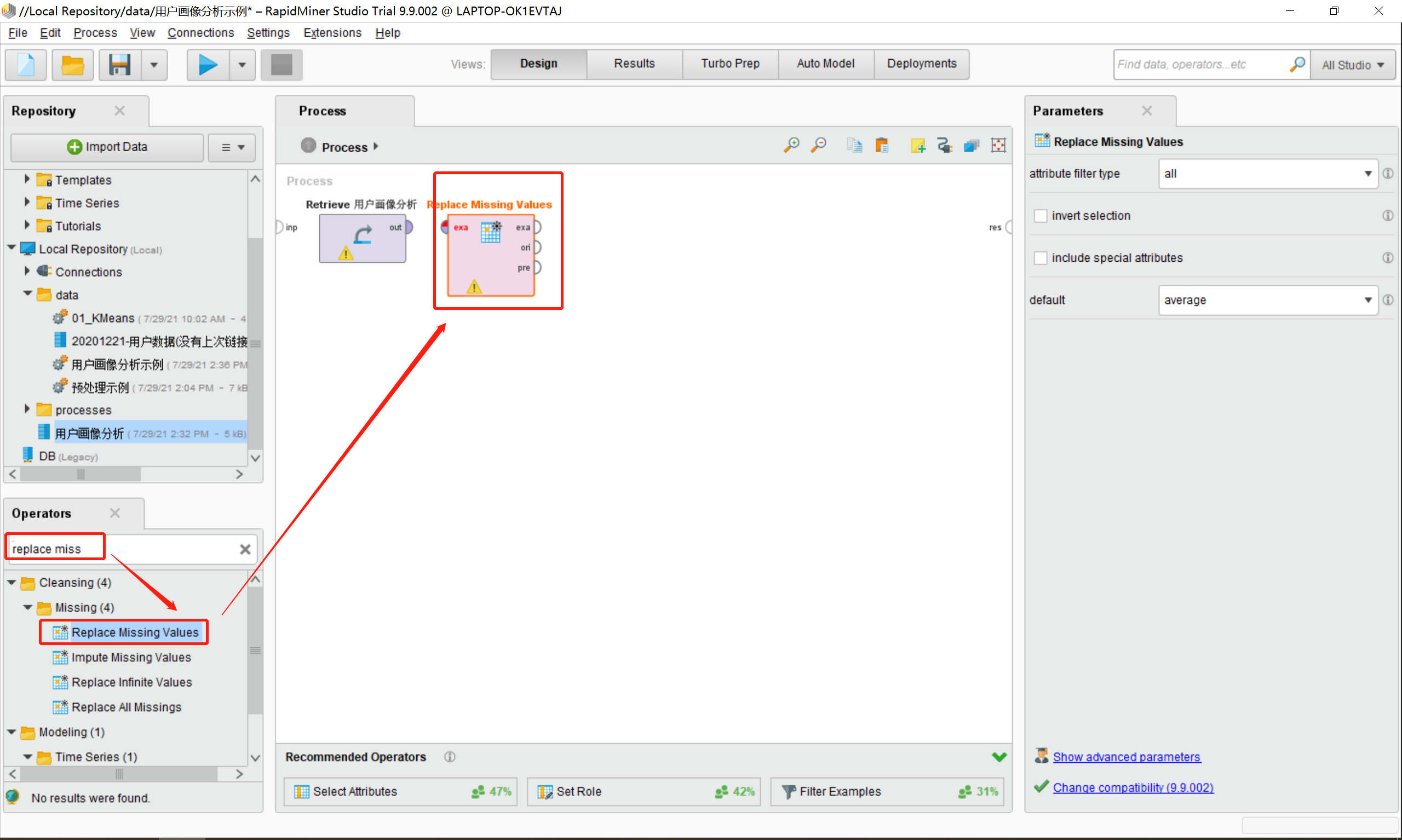
5.根据预先确定好的缺省值,我们在Operators栏目的搜索框中搜索“replace missing values”,即代替缺省值的处理算法模型,如下图所示,将其拖入到Process区域中
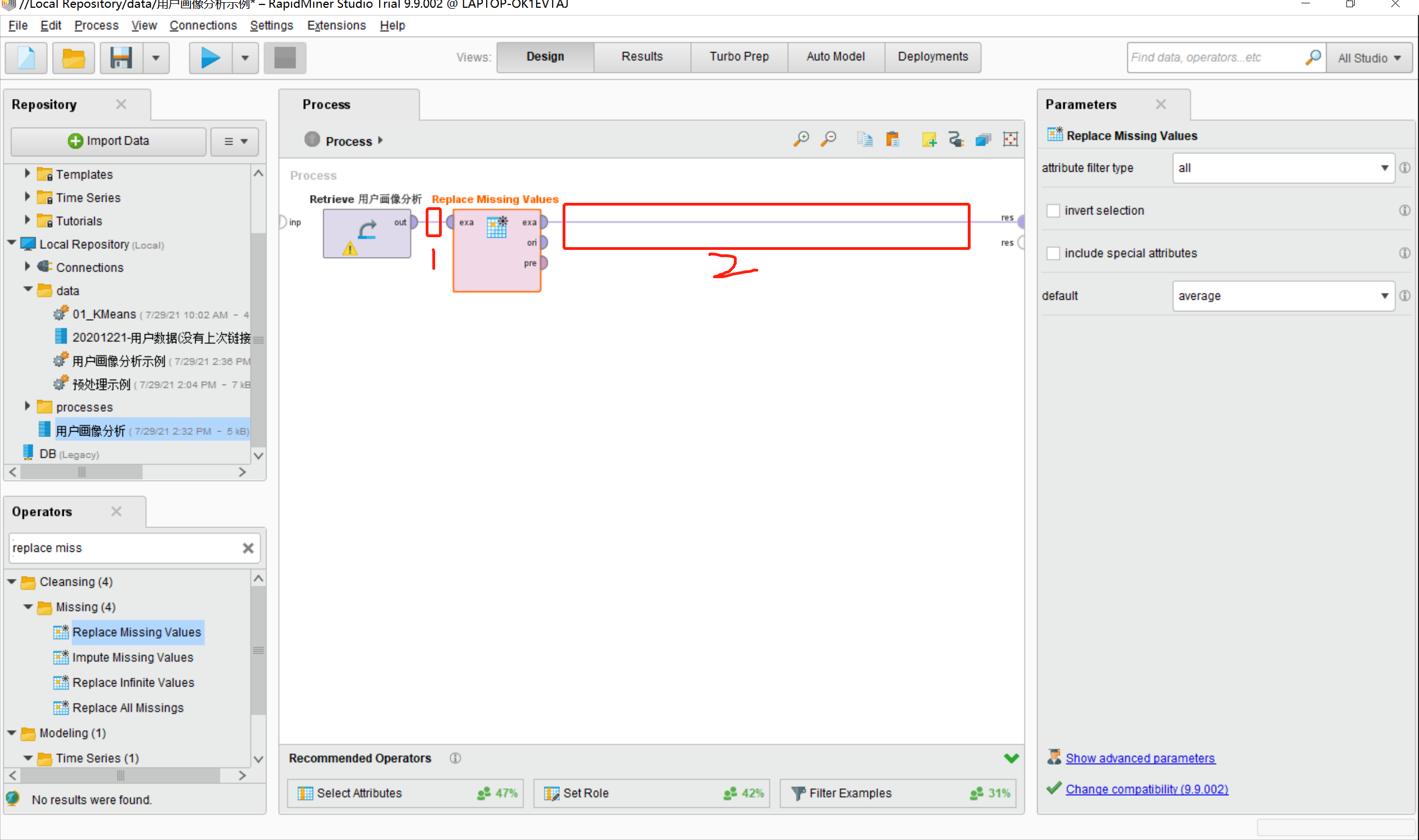
 6.将用户画像分析模型out和“replace Missing Values”模型的exa相连线,并与rapidminer的res输出键连线,如图所示:
6.将用户画像分析模型out和“replace Missing Values”模型的exa相连线,并与rapidminer的res输出键连线,如图所示:
 7.点击Process区域中的“Replace Missing Values”模型后,通过右侧的Parameters来设置相关参数,如下图所示:
7.点击Process区域中的“Replace Missing Values”模型后,通过右侧的Parameters来设置相关参数,如下图所示:
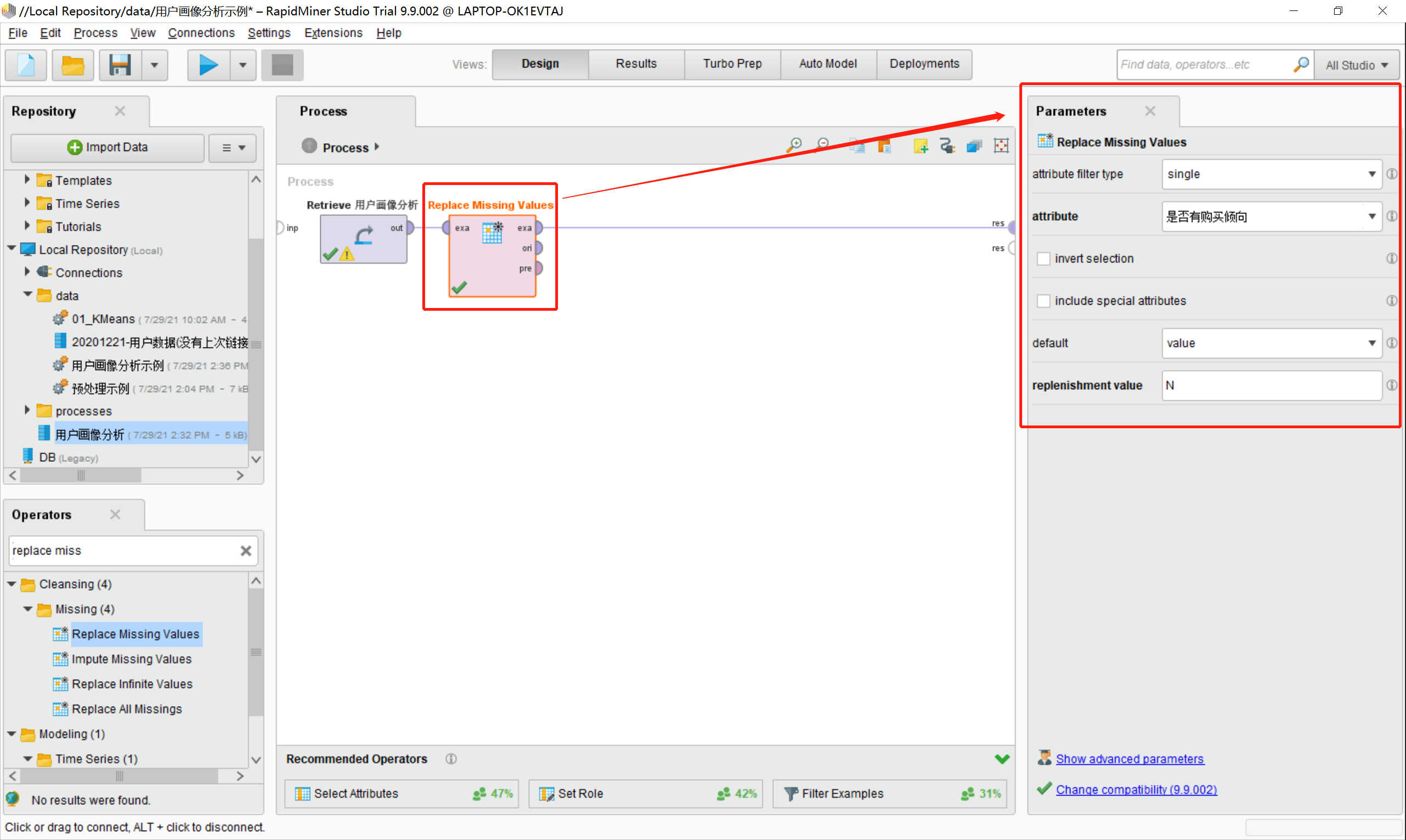
·attribute filter type:属性的过滤标签,可以针对所有的(all)属性进行操作,也可以按照单个的(single)属性进行处理。
·attribute:用户数据的列名称,即针对具体哪个列进行数据处理。
·default:默认值,比如针对value进行设置
·replenishment value:value对应的值,这里设置为N,意思是我想让所有的缺省值的value都统一设置为N(N代表该用户没有购买倾向)
8.点击执行按钮,看一下效果,如图所示:
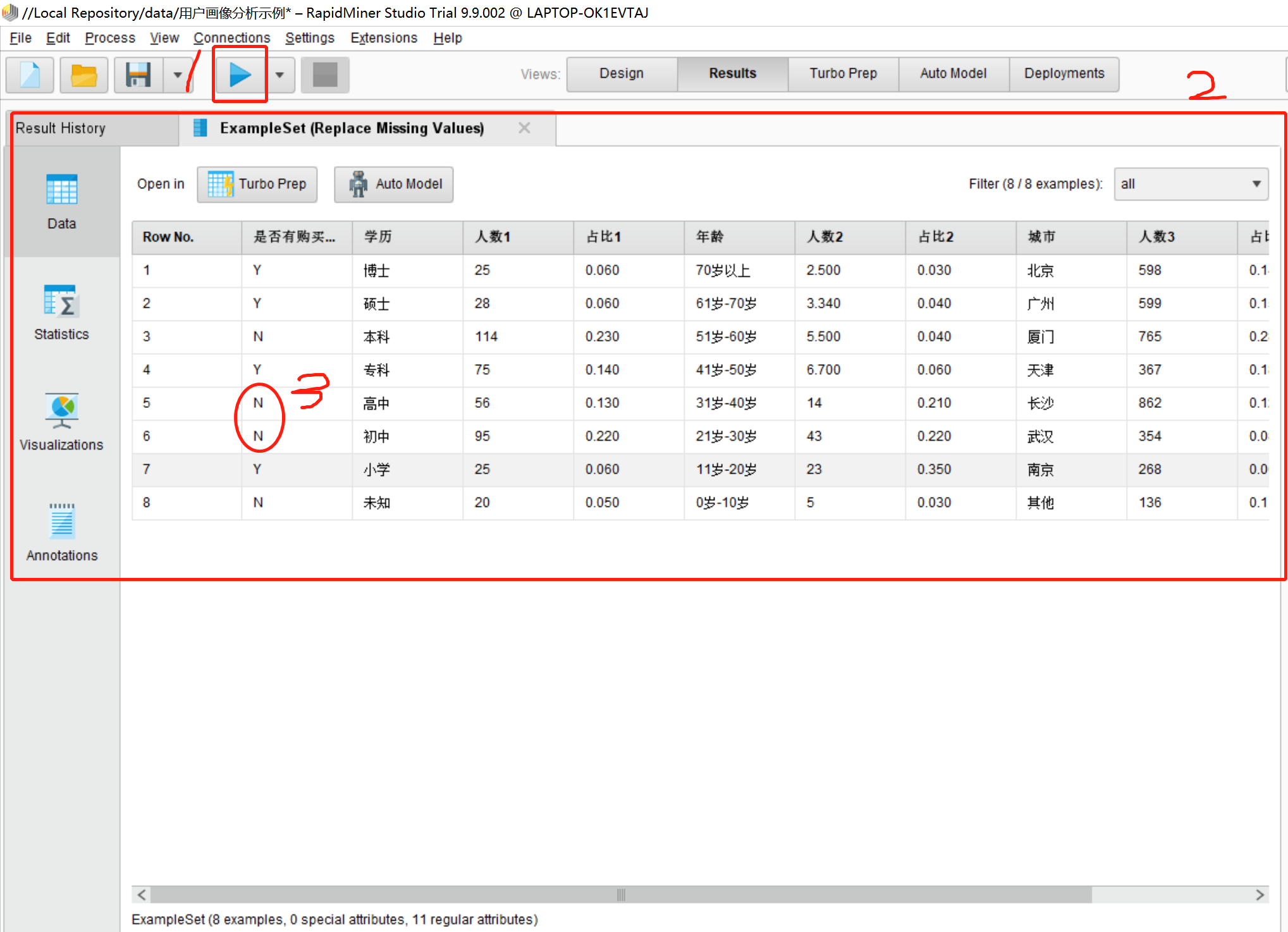
·1处为执行按钮,在第7步的界面下点击执行按钮会出现上图所示的界面效果
·2处为replace missing value后的数据展示
·3处可以明显的看到5行和6行原本的空置被替换成了我们设置的N
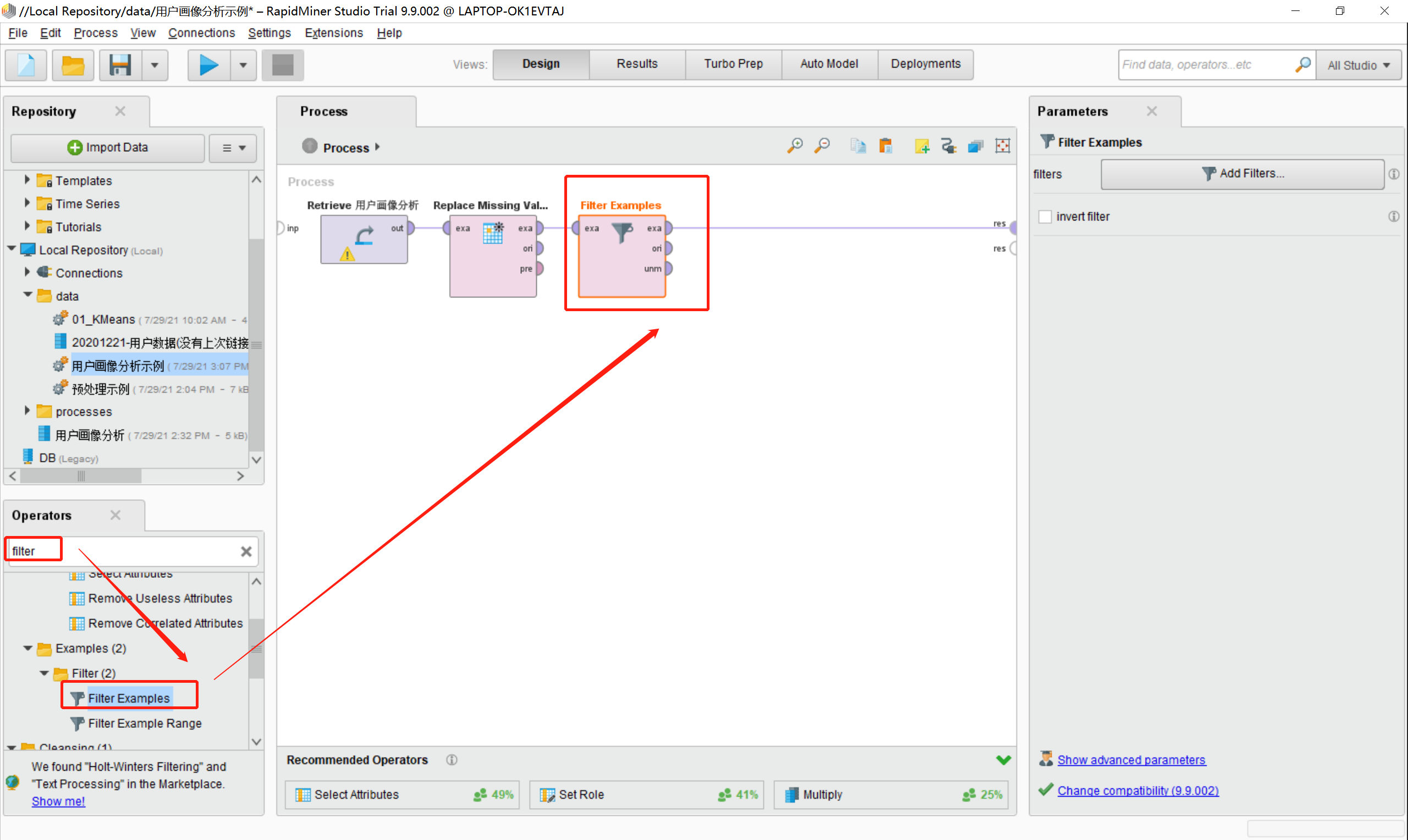
9.在之前的步骤上我们尝试对用户画像分析数据进行数据清洗,在Operators中搜素 “filter Examples”模型,并将模型拖动到Process区域中,并将其连线,如图所示:
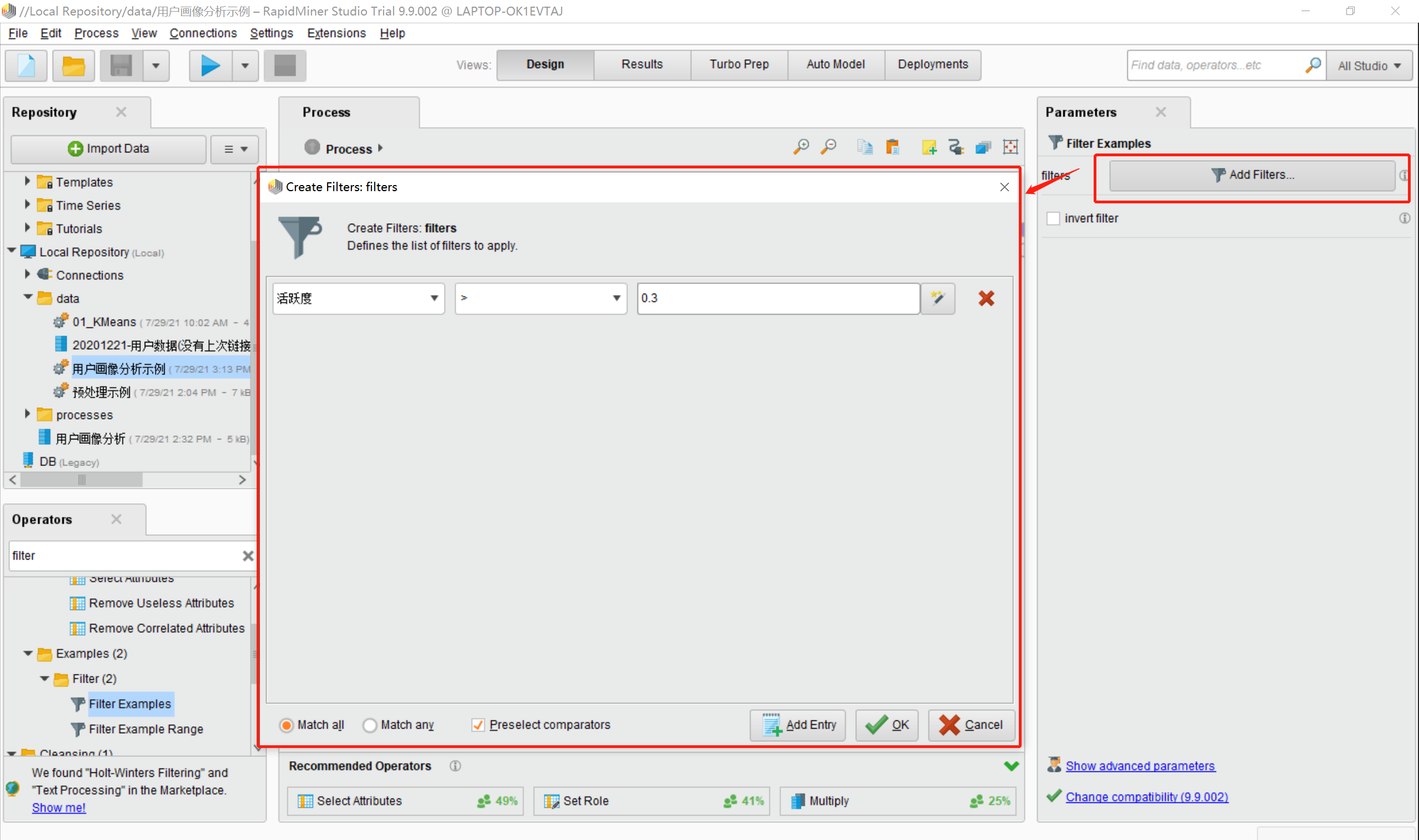
 10.点击Process区域的filter Examples模型,在Parameters栏中设置过滤清洗的条件,我这里设置的是活跃度>=0.3,如下图所示:
10.点击Process区域的filter Examples模型,在Parameters栏中设置过滤清洗的条件,我这里设置的是活跃度>=0.3,如下图所示:
 11.完成条件设置之后,点击OK,然后回到Design,点击执行按钮,出现如图所示界面:
11.完成条件设置之后,点击OK,然后回到Design,点击执行按钮,出现如图所示界面:
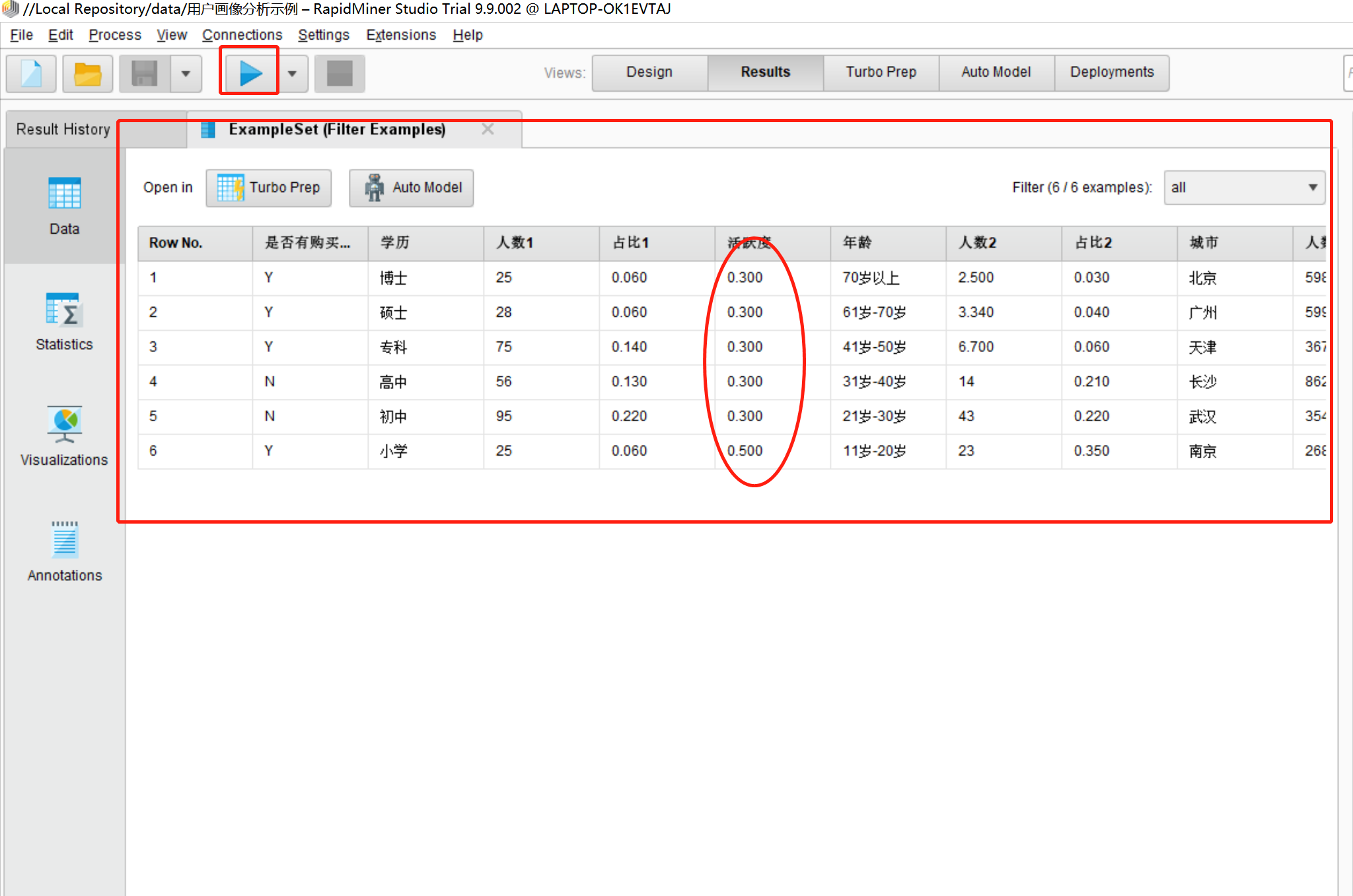
·用户画像数据由原来的九条数据变成了六条数据,将不符合条件的数据清洗掉了
·保留了活跃度>=0.3的数据
12.在之前的步骤上我们尝试对用户画像分析数据进行数据约减属性处理(即只展示有用的列),在Operators中搜素 “select att”模型,并将模型拖动到Process区域中,并将其连线,如图所示:
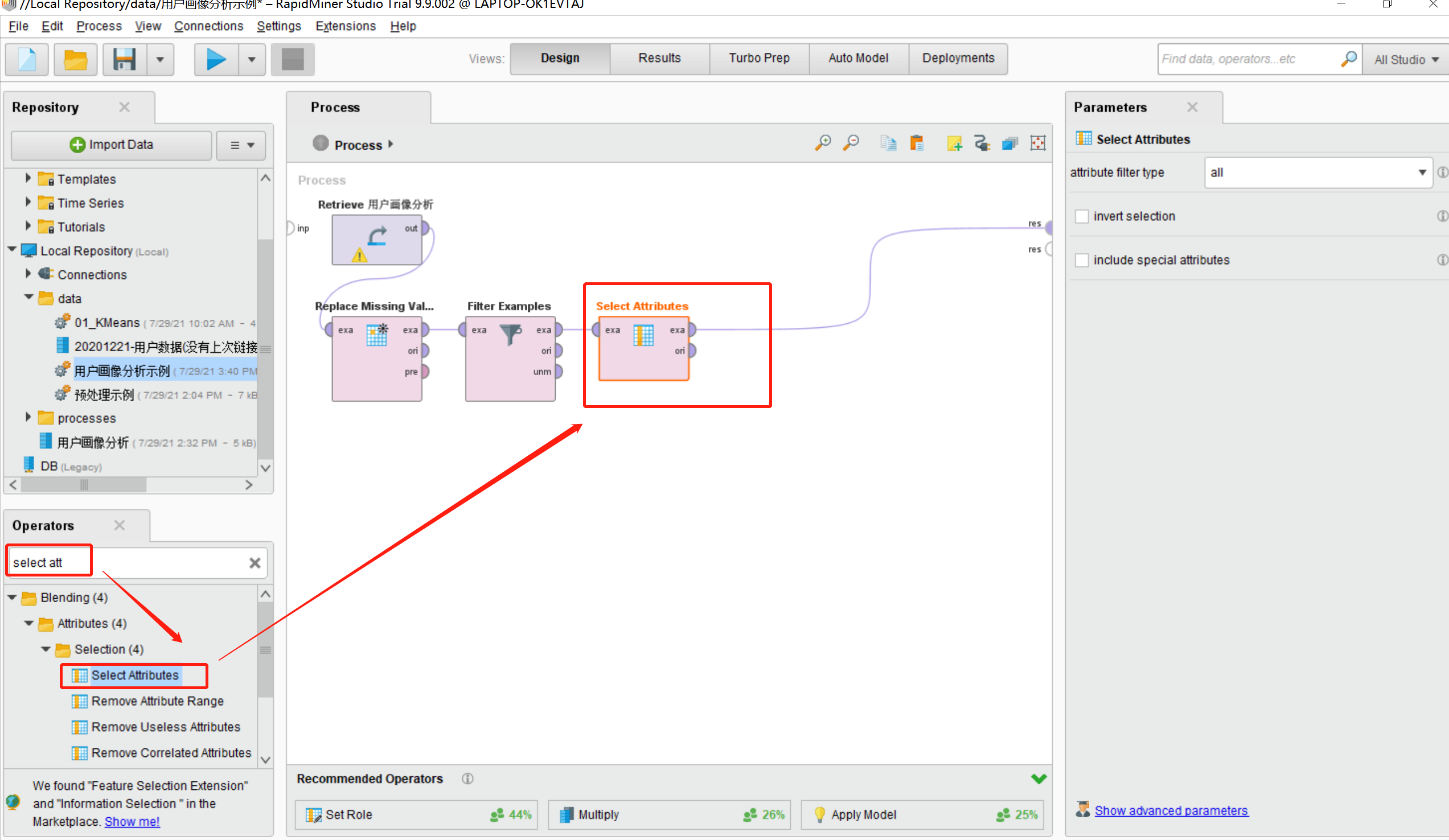 13.点击Process区域的select Attributes模型,在Parameters栏中设置,我这里设置的是subset,然后点击“select Attributes”按钮,选择要保留的列,如下图所示:
13.点击Process区域的select Attributes模型,在Parameters栏中设置,我这里设置的是subset,然后点击“select Attributes”按钮,选择要保留的列,如下图所示:
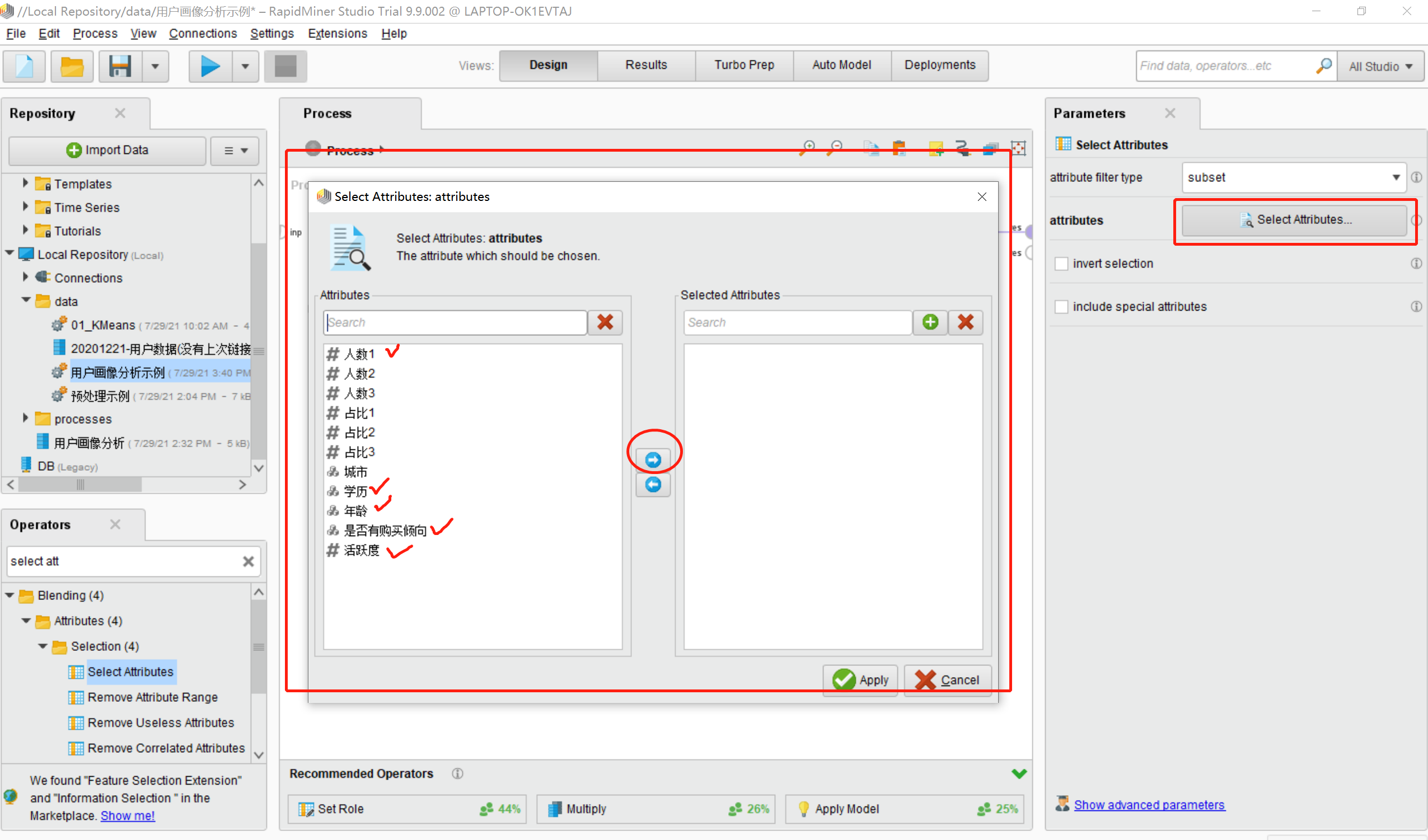
·弹出的窗口会默认展示用户画像分析数据中所有的列名
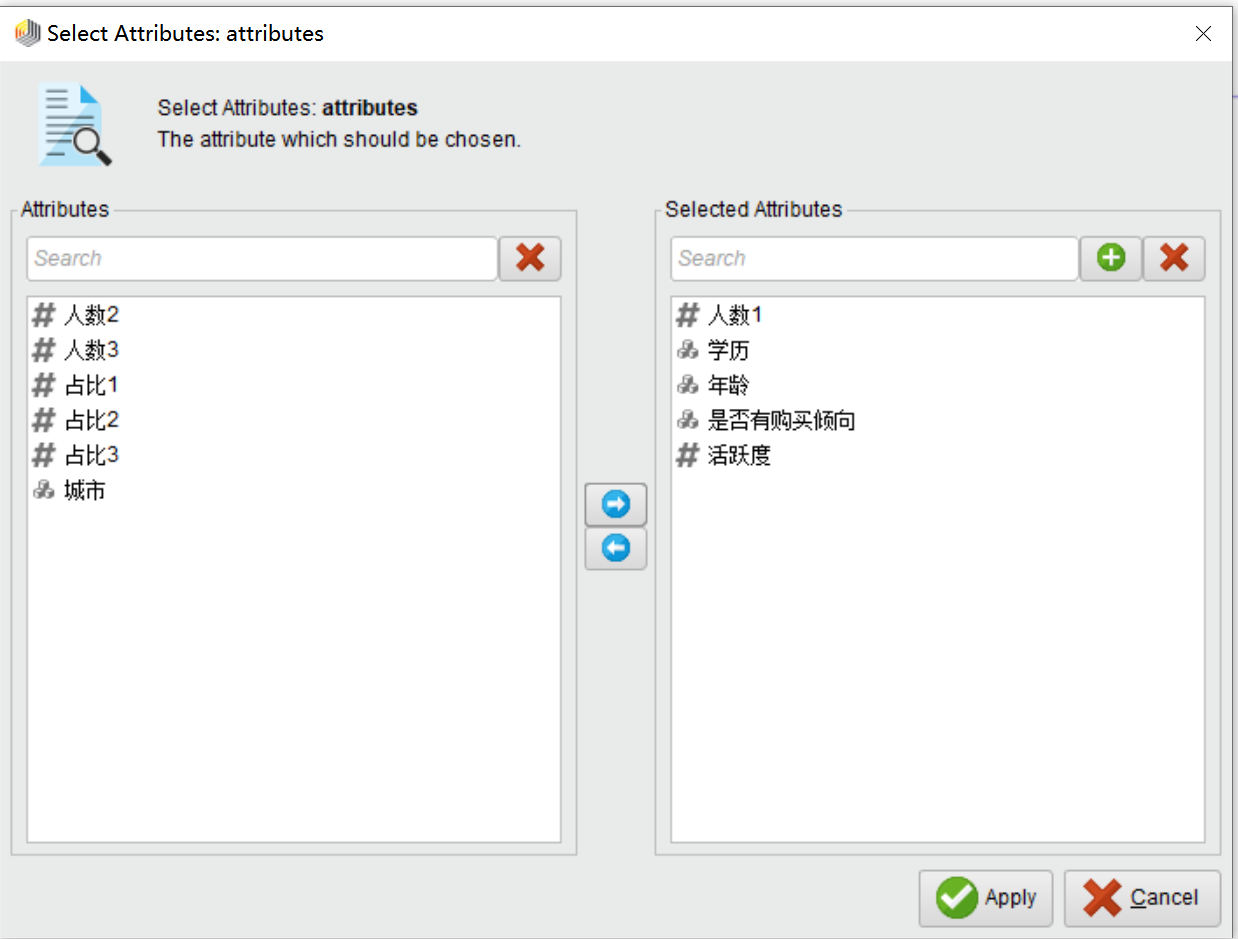
·我这里将画对勾的通过“→”添加到右侧栏中(即我想要展示的列名),效果如下图:
·然后点击apply按钮
 14.点击完apply按钮后会回到Design界面,然后点击执行按钮看一下效果。如下图:
14.点击完apply按钮后会回到Design界面,然后点击执行按钮看一下效果。如下图:
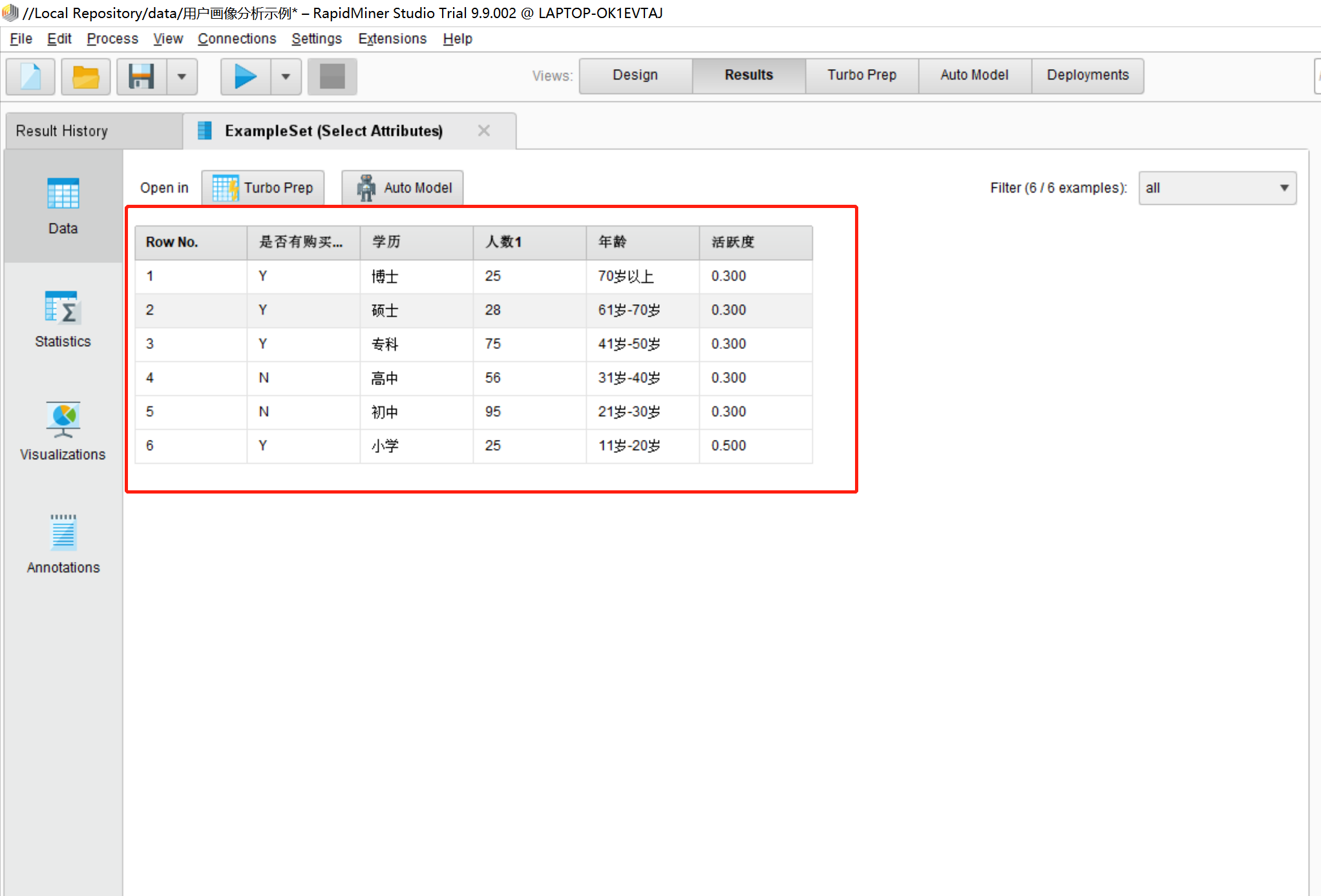
·结果页面中只展示了我们想要展示的列
2.4导出数据
- 根据上述步骤完成数据的预处理后,我们现在将处理后的数据进行导出
- 回到Design界面下,在Operators中选择Data Access》Files》Write》write CSV,将write CSV拖在Process中,并将其连线,如下图所示:
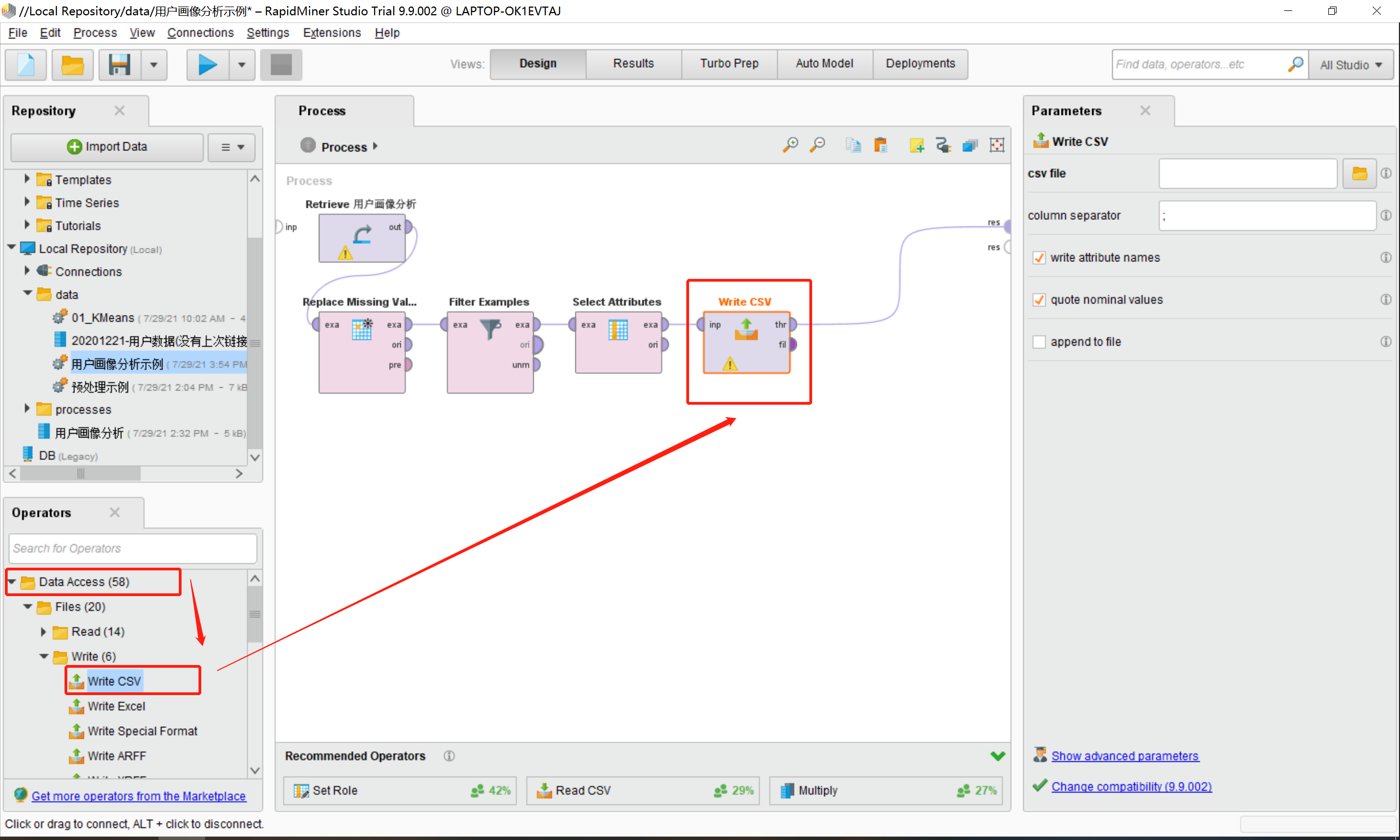 3.单击选中Write CSA模型,在其对应的Parameters中设置相关信息,如下图所示:
3.单击选中Write CSA模型,在其对应的Parameters中设置相关信息,如下图所示:
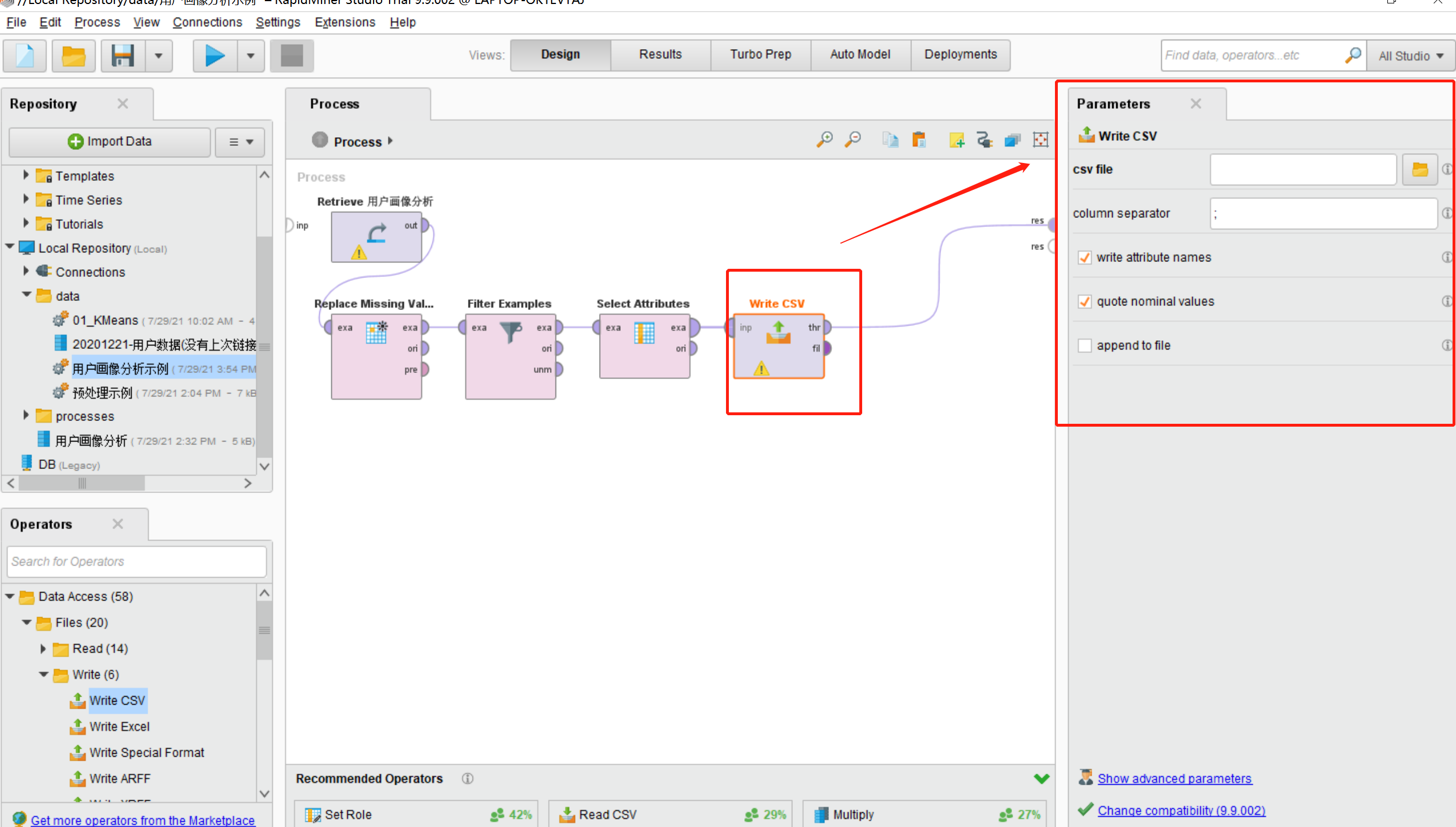
·csv file:导出文件的保存地址
·column separator:分隔符
·write attribute names:是否显示列名称
·quote nominal values:是否显示分隔符
·append to file:在已有的数据基础上新增数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号