Node.js实现简单的爬取
学习【node.js】也有几天时间了,所以打算写着练练手;索然我作为一个后端的选手,写起来还有那么一丝熟悉的感觉。emmm~~ ‘货’不多讲 ,开搞........
首先是依赖选择:

代码块如下:
//引入依赖
//https请求
const https = require('https');
//简称node版的jquery
const cheerio = require('cheerio');
//解决防止出现乱码
const iconv = require('iconv-lite')
//http请求
const request = require("request");
//负责读写文件
const fs = require('fs');
//处理文件路径
const path = require('path');
爬取路径:

代码块:(PS:这里单独拿出来是因为这个站的素材比较推荐,可以上去瞅瞅~~)
const url = 'https://unsplash.com/';
初步实现:
网站的基本构成
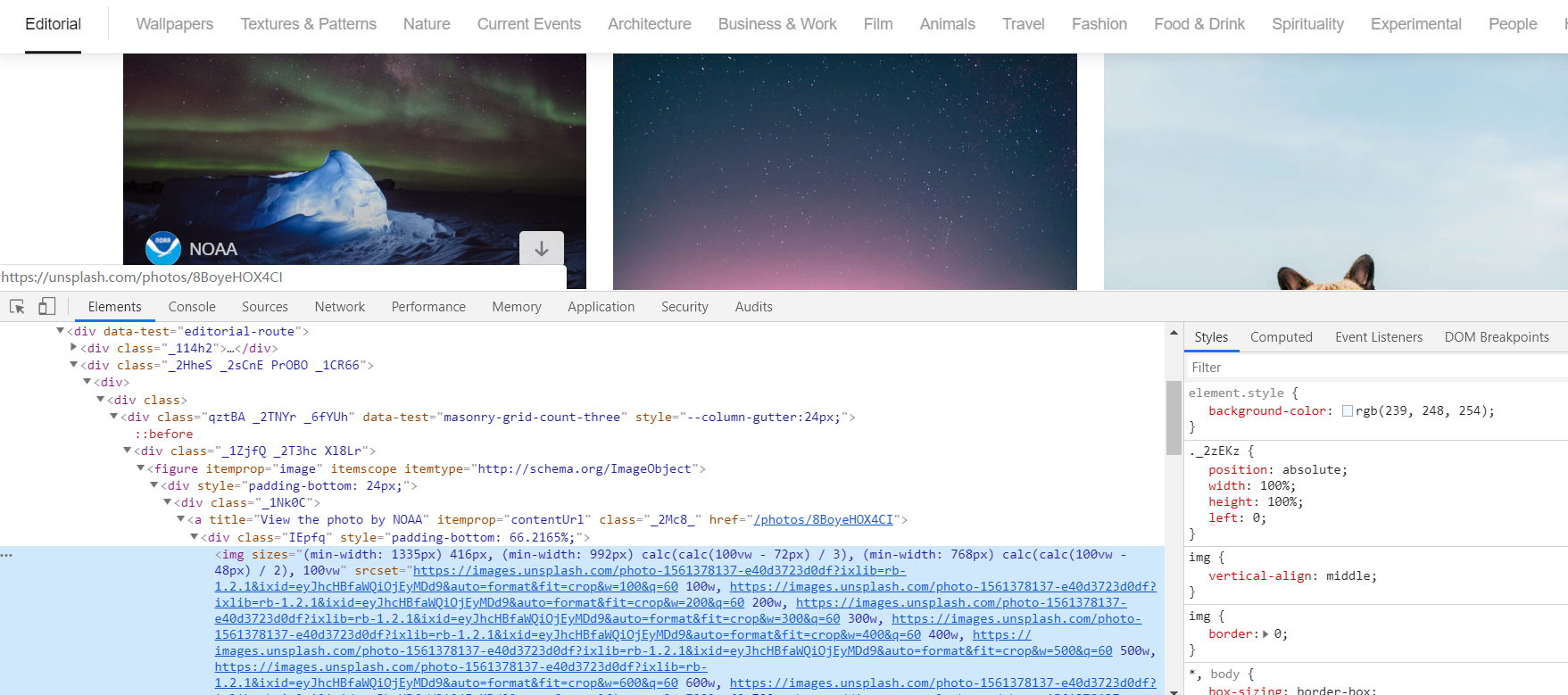
这里主要是我们直接确认一下需要的【img】标签,以及外面的【figure】,然后直接就可以开工了....
核心代码:
//方法对象
const util = {
getsrc: function (url) {
https.get(url, res => {
const chunks = [];
res.on('data', chunk => {
// chunks里面存储着网页的html内容
chunks.push(chunk);
});
res.on('end', e => {
let ALL = [];
//编码格式
let html = iconv.decode(Buffer.concat(chunks), 'utf8');
let $ = cheerio.load(html, { decodeEntities: false });
//标签遍历
$("figure img").each(function (idex, elent) {
let $elent = $(elent);
let $srcset = $elent.attr("srcset");
if ($srcset != undefined) {
let src = ($srcset.split(',').pop()).split('?')[0];
ALL.push({
src: src
})
}
});
//遍历数组 每个后面加.jpg
ALL.forEach(item => {
util.downloadimg(item.src, path.basename(item.src) + ".jpg", function () {
console.log(path.basename(item.src) + ".jpg");
});
})
});
res.on('error', e => {
console.log('Error: ' + e.message);
});
});
},
//运行主函数
main: function () {
console.log("------start--------");
util.getsrc(url);
},
//下载图片函数
downloadimg: function (src, srcname, callback) {
//http请求
request.head(src, function (err, res, body) {
if (err) {
console.log('err:' + err);
return false;
}
console.log('res: ' + res);
//保存数据,这里是防止未来得及记录数据又开始读取数据而导致数据丢失
request(src).pipe(fs.createWriteStream('./img/' + srcname)).on('close', callback);
});
}
}
//主函数
util.main();
然后就可以运行 node xxx.js 看运行结果。
Git源码地址:https://github.com/KelvinKey/node-reptile
END Initial entry into the front end, the inadequacies, please bear with me.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号