python下载文件的N中方式
今天我们一起学习如何使用不同的Python模块从web下载文件。此外,你将下载常规文件、web页面、Amazon S3和其他资源。
最后,你将学习如何克服可能遇到的各种挑战,例如下载重定向的文件、下载大型文件、完成一个多线程下载以及其他策略。
1、使用requests
你可以使用requests模块从一个URL下载文件。
考虑以下代码:

path=os.path.realpath(__file__) cwd=os.path.split(path)[0]
open(cwd+os.path.sep+"usage_result.xls","wb").write(response.content)
你只需使用requests模块的get方法获取URL,并将结果存储到一个名为“myfile”的变量中。然后,将这个变量的内容写入文件。
一般下载文件的api,返回的数据是二进制码,都是在浏览器的F12的开发者代码检查工具中 无法直接查看到的,比如:
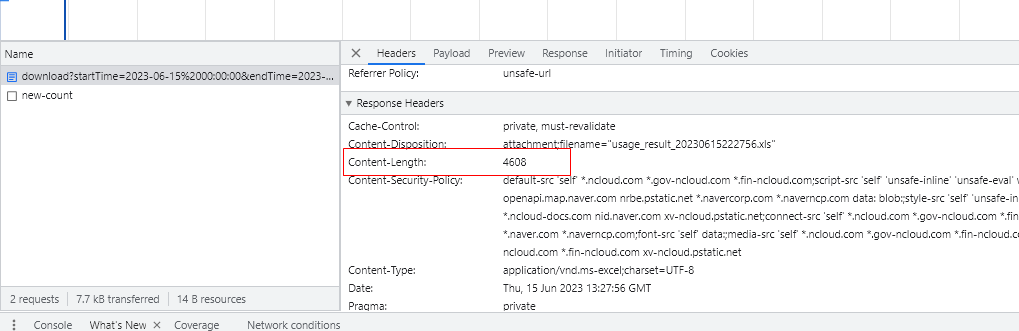
这个时候怎么办呢?这时应该查看Reponse headers栏中的 content-Length,就能看到其实是有文件被下载的:
还有很多种方式:我后面在一一给大家整理
参考:https://blog.csdn.net/weixin_43641920/article/details/122258687

 浙公网安备 33010602011771号
浙公网安备 33010602011771号