Buffer是nodeJS中的二进制缓存操作模块内容。先来看一段简短的代码。
// 创建一个长度为 10、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(10);
// 创建一个长度为 10、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(10, 1);
// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据,
// 因此需要使用 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(10);
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);
// 创建一个包含 UTF-8 字节 [0x74, 0xc3, 0xa9, 0x73, 0x74] 的 Buffer。
const buf5 = Buffer.from('tést');
// 创建一个包含 Latin-1 字节 [0x74, 0xe9, 0x73, 0x74] 的 Buffer。
const buf6 = Buffer.from('tést', 'latin1');
由上面可知,实际上buffer对象内容展示给我们的时候实际上是一连串的二进制形式的内容,当然我们可以通过不同的二进制编码标准来转化当前的字符串内容,常用的编码(当然也是默认的)是UTF8,这是JS一贯使用的编码方式,我们也可以选择ascii等等其他类型的编码。下面我们来了解一下Buffer模块中的一些方法吧。
首先需要知道的一点就是在新版本的nodeJS之中buffer的构造器获取相关的值的方式已经摈弃了,现在主要是三个Buffer的类方法。下面我们先来了解一下这三个方法内容。
-- Buffer.alloc(size, [fill, [encoding]]):传递的三个参数分别为,buffer的大小,填充每一个占位的字符内容,以及以什么编码格式初始化,编码格式默认为UTF8。这里上一段代码。。。
console.log(Buffer.alloc(10));
//展示 <Buffer 00 00 00 00 00 00 00 00 00 00>
console.log(Buffer.alloc(10, 1));
//展示 <Buffer 01 01 01 01 01 01 01 01 01 01>
console.log(Buffer.alloc(10, 300));
//展示 <Buffer 2c 2c 2c 2c 2c 2c 2c 2c 2c 2c>
由上面可以看出其是以两位16进制数来进行数据的填充的,当我们的想要是使用300进行填充的时候,实际上其转换成为而进制的时候为9位,这node将其内容舍弃了最高位,由此编程了2C即44。
-- Buffer.allocUnsafe(size): 这一方法内容传递的是分配内存大小,但是并不会自动的填充内容。Buffer会将内存模块内容分配制定的大小并返回,但是可以从方法内容来看到这一方法是不安全的,因为不自动填充,所以其中分配出来的内存块内容可能存在之前的数据内容,可能会导致安全的问题。但是由于这一函数的快速和便捷所以有时还是会使用,但是一般最好还是和fill方法同时使用,可以将分配的内存中的数据替换掉,并保证安全性。
-- Buffer.allocUnsafeSlow(size): 这是另外一个不安全的方法内容,同样是分配一个size大小的内存区域,但是和上面方法不同的地方是,这一方法不初始化底层内存信息,当然企业有可能包含敏感信息,所以也需要配合fill方法来使用。(而allocUnsafe方法,当分配的内存小于 4KB 时,默认会从一个单一的预分配的 Buffer 切割出来。 这使得应用程序可以避免垃圾回收机制因创建太多独立分配的 Buffer 实例而过度使用。 这个方法通过像大多数持久对象一样消除追踪与清理的需求,改善了性能与内存使用。)
-- Buffer.from():from方法内容传递的内容和alloc-开头的方法不同了,这一方法传递的是数组,字符串参数或者是一个buffer对象内容。我们直接上代码。
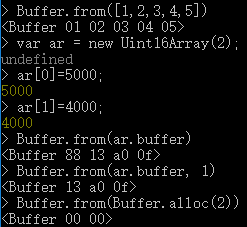
这一段代码可以充分说明Buffer.from的多态了。当然要注意的一点就是在传递的数据为数组的时候,其中的起始位置内容实际上是无效的,只有当我们传递的第一个参数是ArrayBuffer,即Buffer数组才行。
-- Buffer.byteLength(string,[encoding]): 返回一个字符串字符数,第二个参数可能会影响到返回内容的长度,因为不同的编码内容会影响当前字符内容的转化方式。
-- Buffer.compare(buf1, buf2): 比较两个buffer对象内容,通常用于数组排序。
-- Buffer.concat(list, [totalLength]):合并Buffer或者是Uint8Array的实力数组。
-- Buffer.isBuffer(obj):判断传递的参数是不是Buffer对象。
-- Buffer.isEncoding(encode):判断当前的Buffer内容的编码与传递的编码格式是否相同。
-- Buffer.poolSize:用于决定预分配的、内部 Buffer 实例池的大小的字节数。 这个值可以修改。
以上是Buffer模块提供的类方法内容,当然其针对实例对象该内容也是有许多的内容。接下来我们来看一看。
-- 受限我们需要知道的是其实Buffer对象类似于数组的,我们可以通过下标的形式来获取相应位置的值,看一段代码吧
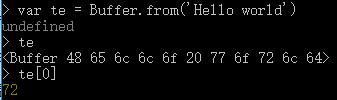
图中展示可以看出,我们获取的Buffer对象实际上是以每个8位内容为一个数位。用类似数组的下标形式来获取相应的数位内容。当然找事出来的内容和其中Buffer对象实例的内容是不相同的是因为,实例中的每一个数位用的是16进制的形式展示的,而当我们获取相关的数据的时候则转变成为了10进制。
-- 实例对象之中有一个buffer属性,可以获取底层的ArrayBuffer对象内容。直接上代码。
> te.buffer
ArrayBuffer { byteLength: 8192 }
我们这里说明一下ArrayBuffer对象吧。这一内容可以在MDN中的javascript标准库中的看到,引用文档中说明 —— ArrayBuffer对象被用来表示一个通用的,固定长度的原始二进制数据缓冲区,但是用户对于这一对象的内容是不能进行直接性质的额操作的。我们可以通过使用类型化数组对象内容或者是DataView对象内容来进行缓冲区数据内容的读写。这里所说的类型化数组对象其实就是TypedArray对象,但是其实不能通过new来直接获取新的对象的,但是存在很多的方法可以获取这一对象的实例内容,例如如下方法。
Int8Array();
Uint8Array();
Uint8ClampedArray();
Int16Array();
Uint16Array();
Int32Array();
Uint32Array();
Float32Array();
Float64Array();
这些方法的调用可以直接获取TypedArray对象内容,具体内容可以看一看MDN这里就不在细说了。这里有一个TypedArray的博客内容(点这里)
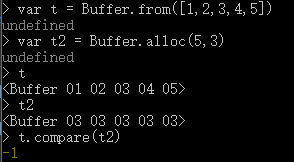
-- buf.compare(target[, targetstart [, targetend [, sourcestart [, sourceend]]]]):主要的参数就是target,传递的是要与buf对象比较的另一个Buffer对象,后面的参数都是偏移量一类的内容咯。相信字面上还是很好理解的。其返回结果倒是需要说明一下,其标明在buf在排序上面排在target前,后,或是相同位置。比较的方式是基于实际的字符串序列,如果target与buf相同则是0,如果target排在buf前面则返回1,如果排在buf后面则返回-1,看段代码:
-- buf.entries():返回一个遍历对象,通过for... of循环来遍历,返回的是[index, value]的形式的选项内容。上代码:
const buf = Buffer.from('buffer');
// 输出:
// [0, 98]
// [1, 117]
// [2, 102]
// [3, 102]
// [4, 101]
// [5, 114]
for (const pair of buf.entries()) {
console.log(pair);
}
-- buf,equals(otherBuffer):比较当前两个Buffer对象内容,如果两个Buffer对象拥有相同的字符级内容,则返回相同,否则返回false
-- buf.fill(value [, offset [, end]] [, encoding]): 填充函数,之前的代码中也有已使用到,填充Buffer对象中的每一个数位为传递的参数内容。
-- buf.include(value [, byteoffset] [, encoding]):测试当前的buffer对象之中是否囊括了传递进入的value值,value的类型可以是字符串,buffer对象或者是整数。第二个数字内容是确定从Buf对象的第几个数位开始查找内容,第三个参数只有在Value内容为字符串的情况之下才能生效,表示将会把value转化成为什么编码形式的内容来比对。
-- buf.indexOf(value [,byteoffset] [,encoding]):测试当前的value是否存在于Buf对象之中,存在则返回匹配起始位置的下标,不存在则返回-1。感觉和字符串的indexOf的内容很像。
-- buf.keys()这一函数的作用是创建一个包含buf索引的迭代器。
-- buf.lastIndexOf():这一函数传递的参数内容与indexOf相同,作用也是类似,只是其返回的不再是陪陪的第一个字符串的位置了,而是最后一段匹配的字符串的位置。
当然还有其他的一些常用或是非常用的Buffer对象的方法,这里就不一一介绍了。可以阅读相关的文档内容。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号