1、需求
2、编码实现
<?php
/**
* 抓取网页
*/
function catch_html($url) {
$urlR = parse_url($url);
$domain = $urlR['scheme'].'://'.$urlR['host'].'/';
$headers=array(
"Accept: application/json, text/javascript, */*; q=0.01",
"Content-Type: application/x-www-form-urlencoded; charset=UTF-8",
"Origin: {$domain}",
"Referer: {$url}",
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36",
);
$curl = curl_init();
curl_setopt($curl, CURLOPT_URL, $url);//设置抓取的url
curl_setopt($curl, CURLOPT_HTTPHEADER, $headers);//指定头部参数
curl_setopt($curl, CURLOPT_HEADER, 0);//设置头文件的信息作为数据流输出
//设置获取的信息以文件流的形式返回,而不是直接输出。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($curl, CURLOPT_ACCEPT_ENCODING, "gzip,deflate");
//重要!
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($curl,CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)"); //模拟浏览器代理
$data = curl_exec($curl);//执行命令
curl_close($curl);//关闭URL请求
$data = mb_convert_encoding($data, 'UTF-8', 'UTF-8,GBK,GB2312,BIG5');//使用该函数对结果进行转码
return $data;
}
/**
* 正则匹配,获取标签内容
*/
function get_tag_data($html,$tag,$attr,$value=''){
$regex = $value ? "/<$tag.*?$attr=\"$value\".*?>(.*?)<\/$tag>/is" : "/<$tag.*?$attr=\".*?$value.*?\".*?>(.*?)<\/$tag>/is";
preg_match_all($regex,$html,$matches,PREG_PATTERN_ORDER);
return $matches[1];//返回值为数组 ,查找到的标签内的内容
}
$url = 'https://www.cnblogs.com/';
$html = catch_html($url);
//echo $html;die;
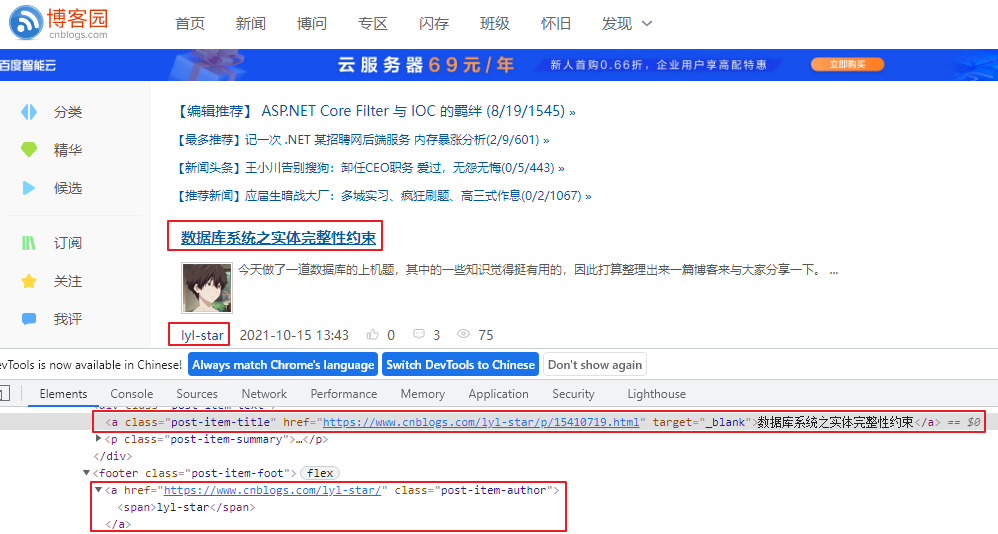
//匹配标题:<a class="post-item-title" href="https://www.cnblogs.com/lyl-star/p/15410719.html" target="_blank">数据库系统之实体完整性约束</a>
$titles = get_tag_data($html,'a','class','post-item-title');
//匹配作者:<a href="https://www.cnblogs.com/lyl-star/" class="post-item-author"><span>lyl-star</span></a>
$authors = get_tag_data($html,'a','class','post-item-author');
//['<span>lyl-star</span>'],
foreach($authors as &$author){
$author = str_replace('<span>','',$author);
$author = str_replace('</span>','',$author);
}
$list = [
'titles' => $titles,
'authors' => $authors,
];
echo '<pre>'; print_r($list); die;
Array
(
[titles] => Array
(
[0] => Centos7最小安装后快速初始化脚本
[1] => ThreadLocal概念以及使用场景
[2] => golang []byte和string的高性能转换
[3] => 数据库系统之实体完整性约束
[4] => 15-ThreadLocalRandom类剖析
[5] => SpringBoot+WebSocket实时监控异常
[6] => Vulnhub实战-DockHole_1靶机👻
[7] => 这几种Java异常处理方法,你会吗?
[8] => 一次OutOfMemoryError: GC overhead limit exceeded
[9] => vue3 element-plus 配置json快速生成table列表组件,提升生产力近500%(已在公司使用,持续优化中)
[10] => redis在微服务领域的贡献
[11] => Task 异步小技巧
[12] => 记一次 .NET 某招聘网后端服务 内存暴涨分析
[13] => asp.net core使用identity+jwt保护你的webapi(三)——refresh token
[14] => 如何做好 NodeJS 框架选型?
[15] => k8s调度器介绍(调度框架版本)
[16] => 【万字长文】吃透负载均衡
[17] => iOS自定义拍照框拍照&裁剪(一)
[18] => Linux 下 SVN 的安装和配置
[19] => C#开发BIMFACE系列46 服务端API之离线数据包下载及结构详解
)
[authors] => Array
(
[0] => 滑了个蛋
[1] => xbhog
[2] => charlieroro
[3] => lyl-star
[4] => 黑夜中的小迷途
[5] => Jae1995
[6] => 胖三斤1
[7] => 华为云开发者社区
[8] => 欢醉
[9] => aehyok
[10] => 捉虫大师
[11] => 一事冇诚
[12] => 一线码农
[13] => xhznl
[14] => 广吾
[15] => goofy_zheng
[16] => 高性能架构探索
[17] => iOS小熊
[18] => Linux开发那些事儿
[19] => 张传宁
)
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号