强化学习(十五) A3C
在强化学习(十四) Actor-Critic中,我们讨论了Actor-Critic的算法流程,但是由于普通的Actor-Critic算法难以收敛,需要一些其他的优化。而Asynchronous Advantage Actor-critic(以下简称A3C)就是其中比较好的优化算法。本文我们讨论A3C的算法原理和算法流程。
本文主要参考了A3C的论文,以及ICML 2016的deep RL tutorial。
1. A3C的引入
上一篇Actor-Critic算法的代码,其实很难收敛,无论怎么调参,最后的CartPole都很难稳定在200分,这是Actor-Critic算法的问题。但是我们还是有办法去有优化这个难以收敛的问题的。
回忆下之前的DQN算法,为了方便收敛使用了经验回放的技巧。那么我们的Actor-Critic是不是也可以使用经验回放的技巧呢?当然可以!不过A3C更进一步,还克服了一些经验回放的问题。经验回放有什么问题呢? 回放池经验数据相关性太强,用于训练的时候效果很可能不佳。举个例子,我们学习下棋,总是和同一个人下,期望能提高棋艺。这当然没有问题,但是到一定程度就再难提高了,此时最好的方法是另寻高手切磋。
A3C的思路也是如此,它利用多线程的方法,同时在多个线程里面分别和环境进行交互学习,每个线程都把学习的成果汇总起来,整理保存在一个公共的地方。并且,定期从公共的地方把大家的齐心学习的成果拿回来,指导自己和环境后面的学习交互。
通过这种方法,A3C避免了经验回放相关性过强的问题,同时做到了异步并发的学习模型。
2. A3C的算法优化
现在我们来看看相比Actor-Critic,A3C到底做了哪些具体的优化。
相比Actor-Critic,A3C的优化主要有3点,分别是异步训练框架,网络结构优化,Critic评估点的优化。其中异步训练框架是最大的优化。
我们首先来看这个异步训练框架,如下图所示:
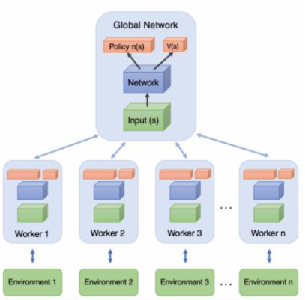
图中上面的Global Network就是上一节说的共享的公共部分,主要是一个公共的神经网络模型,这个神经网络包括Actor网络和Critic网络两部分的功能。下面有n个worker线程,每个线程里有和公共的神经网络一样的网络结构,每个线程会独立的和环境进行交互得到经验数据,这些线程之间互不干扰,独立运行。
每个线程和环境交互到一定量的数据后,就计算在自己线程里的神经网络损失函数的梯度,但是这些梯度却并不更新自己线程里的神经网络,而是去更新公共的神经网络。也就是n个线程会独立的使用累积的梯度分别更新公共部分的神经网络模型参数。每隔一段时间,线程会将自己的神经网络的参数更新为公共神经网络的参数,进而指导后面的环境交互。
可见,公共部分的网络模型就是我们要学习的模型,而线程里的网络模型主要是用于和环境交互使用的,这些线程里的模型可以帮助线程更好的和环境交互,拿到高质量的数据帮助模型更快收敛。
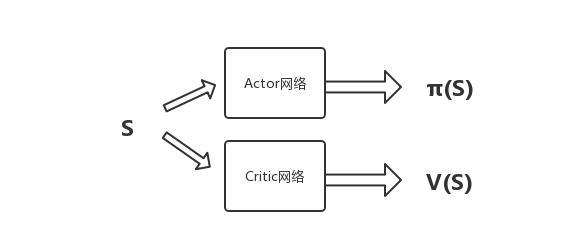
现在我们来看看第二个优化,网络结构的优化。之前在强化学习(十四) Actor-Critic中,我们使用了两个不同的网络Actor和Critic。在A3C这里,我们把两个网络放到了一起,即输入状态$S$,可以输出状态价值$V$,和对应的策略$\pi$, 当然,我们仍然可以把Actor和Critic看做独立的两块,分别处理,如下图所示:
第三个优化点是Critic评估点的优化,在强化学习(十四) Actor-Critic第2节中,我们讨论了不同的Critic评估点的选择,其中d部分讲到了使用优势函数$A$来做Critic评估点,优势函数$A$在时刻t不考虑参数的默认表达式为:$$A(S,A,t) = Q(S,A) - V(S)$$
$Q(S,A)$的值一般可以通过单步采样近似估计,即:$$Q(S,A) = R + \gamma V(S')$$
这样优势函数去掉动作可以表达为:$$A(S,t) = R + \gamma V(S') - V(S)$$
其中$V(S)$的值需要通过Critic网络来学习得到。
在A3C中,采样更进一步,使用了N步采样,以加速收敛。这样A3C中使用的优势函数表达为:$$A(S,t) = R_t + + \gamma R_{t+1} +...\gamma^{n-1} R_{t+n-1} + \gamma^n V(S') - V(S)$$
对于Actor和Critic的损失函数部分,和Actor-Critic基本相同。有一个小的优化点就是在Actor-Critic策略函数的损失函数中,加入了策略$\pi$的熵项,系数为c, 即策略参数的梯度更新和Actor-Critic相比变成了这样:$$\theta = \theta + \alpha \nabla_{\theta}log \pi_{\theta}(s_t,a_t)A(S,t) + c\nabla_{\theta}H(\pi(S_t, \theta))$$
以上就是A3C和Actor-Critic相比有优化的部分。下面我们来总价下A3C的算法流程。
3. A3C算法流程
这里我们对A3C算法流程做一个总结,由于A3C是异步多线程的,我们这里给出任意一个线程的算法流程。
输入:公共部分的A3C神经网络结构,对应参数位$\theta, w$,本线程的A3C神经网络结构,对应参数$\theta ', w'$, 全局共享的迭代轮数$T$,全局最大迭代次数$T_{max}$, 线程内单次迭代时间序列最大长度$T_{local}$,状态特征维度$n$, 动作集$A$, 步长$\alpha,\beta$,熵系数c, 衰减因子$\gamma$
输入:公共部分的A3C神经网络参数$\theta, w$
1. 更新时间序列$t=1$
2. 重置Actor和Critic的梯度更新量:$d\theta \gets 0, dw\gets 0$
3. 从公共部分的A3C神经网络同步参数到本线程的神经网络:$\theta ' =\theta,\;\; w'=w$
4. $t_{start} = t$,初始化状态$s_t$
5. 基于策略$\pi(a_t|s_t;\theta)$选择出动作$a_t$
6. 执行动作$a_t$得到奖励$r_t$和新状态$s_{t+1}$
7. $t \gets t+1, T \gets T+1$
8. 如果$s_t$是终止状态,或$t-t_{start} == t_{local} $,则进入步骤9,否则回到步骤5
9. 计算最后一个时间序列位置$s_t$的$Q(s,t)$:$$Q(s,t)= \begin{cases} 0& {terminal\;state}\\ V(s_t,w')& {none\;terminal\;state,bootstrapping} \end{cases}$$
10. for $i \in (t-1,t-2,...t_{start})$:
1) 计算每个时刻的$Q(s,i)$:$Q(s,i) = r_i + \gamma Q(s,i+1)$
2) 累计Actor的本地梯度更新:$$d\theta \gets d\theta + \nabla_{\theta '}log \pi_{\theta'}(s_i,a_i)(Q(s,i)-V(S_i, w')) + c\nabla_{\theta '}H(\pi(s_i, \theta '))$$
3) 累计Critic的本地梯度更新:$$dw \gets dw + \frac{\partial (Q(s,i)-V(S_i, w'))^2}{\partial w'}$$
11. 更新全局神经网络的模型参数:$$\theta = \theta +\alpha d\theta,\;w = w -\beta dw$$
12. 如果$T > T_{max}$,则算法结束,输出公共部分的A3C神经网络参数$\theta, w$,否则进入步骤3
以上就是A3C算法单个线程的算法流程。
4. A3C算法实例
下面我们基于上述算法流程给出A3C算法实例。仍然使用了OpenAI Gym中的CartPole-v0游戏来作为我们算法应用。CartPole-v0游戏的介绍参见这里。它比较简单,基本要求就是控制下面的cart移动使连接在上面的pole保持垂直不倒。这个任务只有两个离散动作,要么向左用力,要么向右用力。而state状态就是这个cart的位置和速度, pole的角度和角速度,4维的特征。坚持到200分的奖励则为过关。
算法代码大部分参考了莫烦的A3C代码,增加了模型测试部分的代码并调整了部分模型参数。完整的代码参见我的Github:https://github.com/ljpzzz/machinelearning/blob/master/reinforcement-learning/a3c.py
整个算法的Actor和Critic的网络结构都定义在这里, 所有的线程中的网络结构,公共部分的网络结构都在这里定义。
def _build_net(self, scope): w_init = tf.random_normal_initializer(0., .1) with tf.variable_scope('actor'): l_a = tf.layers.dense(self.s, 200, tf.nn.relu6, kernel_initializer=w_init, name='la') a_prob = tf.layers.dense(l_a, N_A, tf.nn.softmax, kernel_initializer=w_init, name='ap') with tf.variable_scope('critic'): l_c = tf.layers.dense(self.s, 100, tf.nn.relu6, kernel_initializer=w_init, name='lc') v = tf.layers.dense(l_c, 1, kernel_initializer=w_init, name='v') # state value a_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor') c_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic') return a_prob, v, a_params, c_params
所有线程初始化部分,以及本线程和公共的网络结构初始化部分如下:
with tf.device("/cpu:0"): OPT_A = tf.train.RMSPropOptimizer(LR_A, name='RMSPropA') OPT_C = tf.train.RMSPropOptimizer(LR_C, name='RMSPropC') GLOBAL_AC = ACNet(GLOBAL_NET_SCOPE) # we only need its params workers = [] # Create worker for i in range(N_WORKERS): i_name = 'W_%i' % i # worker name workers.append(Worker(i_name, GLOBAL_AC))
本线程神经网络将本地的梯度更新量用于更新公共网络参数的逻辑在update_global函数中,而从公共网络把参数拉回到本线程神经网络的逻辑在pull_global中。
def update_global(self, feed_dict): # run by a local SESS.run([self.update_a_op, self.update_c_op], feed_dict) # local grads applies to global net def pull_global(self): # run by a local SESS.run([self.pull_a_params_op, self.pull_c_params_op])
详细的内容大家可以对照代码和算法流程一起看。在主函数里我新加了一个测试模型效果的过程,大家可以试试看看最后的模型效果如何。
5. A3C小结
A3C解决了Actor-Critic难以收敛的问题,同时更重要的是,提供了一种通用的异步的并发的强化学习框架,也就是说,这个并发框架不光可以用于A3C,还可以用于其他的强化学习算法。这是A3C最大的贡献。目前,已经有基于GPU的A3C框架,这样A3C的框架训练速度就更快了。
除了A3C, DDPG算法也可以改善Actor-Critic难收敛的问题。它使用了Nature DQN,DDQN类似的思想,用两个Actor网络,两个Critic网络,一共4个神经网络来迭代更新模型参数。在下一篇我们讨论DDPG算法。
(欢迎转载,转载请注明出处。欢迎沟通交流: liujianping-ok@163.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号