《数据密集型应用系统设计》读书笔记--第三章
数据存储与检索
数据结构:
日志是仅支持追加式更新的数据文件。
为了避免查找时从头到尾扫描文件,采用索引结构。
索引:
一、Hash索引
保存内存中的hash map,把每个键一一映射到数据文件中字节偏移量。更新键和插入键时要更新hash map。适合每个键的值频繁更新的场景。
节省空间的方法:压缩段+合并段
当文件达到一定大小时,关闭文件的写入,将新的数据写在新的段上。在已关闭的段上执行压缩,丢弃重复的键,之保留最新的更新。
对关闭写入的段执行合并,合并的段会写入新的文件中。在合并的过程中数据的访问仍然在旧的文件上,合并成功以后,在新的文件上访问。
每个段有自己的Hash表。查找数据时找key,从最新的段的hash表开始找起。
细节问题:
1.删除记录:需要删除一对键值时,在日志文件中追加一个删除记录(墓碑),当合并时如果发现墓碑记录则丢弃这个记录。
2.崩溃恢复:当hash表丢失时避免从头扫描文件重建hash表,会保存每个段的hash表快照到磁盘上。
3.损坏的记录:写的过程中如果发生数据库崩溃,Bitcask文件包含校验值会发现损坏部分并且丢弃。
4.并发控制:写线程一个,读线程多个。
追加式的写入方式优点
1.在磁盘上顺序写速度是最快的。
2.段文件时不可变的,写入时如果发生崩溃,避免出现文件中新值和旧值混杂的情况。
3.合并操作避免出现碎片化的问题。
Hash索引的局限性:
Hash表必须全部放入内存。区间查询效率不高,必须从头遍历所有键值(因为未排序)。
2. SSTable->LSMTree
段文件中key有序,称为排序字符串表。合并时类似于merge排序。
优点:
1.合并简单高效。
2.不需要在内存中保留所有键的索引(保存一个稀疏的索引表即可)。可以按已知键和偏移量在一个范围中找。
3.可以将多条记录按块保存,索引指向块的开头。
写入流程(修改数据相当于写入新值,旧值不会被访问到了):
1.写入时,把数据添加到内存中的平衡树数据结构当中(红黑树)(此树称为内存表)。同时把数据也写进磁盘日志。日志不需要按照key值排序,只用于数据库崩溃以后的恢复。
2.当内存表大于阈值时,所为SSTable文件写入磁盘。此时新写入的数据写到新的内存表中。
读过程:先尝试在内存表中找键,如果找不到到最新的SSTable中找键。以此类推。(读不存在的key时候效率会比较低,用布隆过滤器优化)
后台:周期性合并和压缩SSTable。
LSMTree:基于合并和压缩排序文件原理的存储引擎通常被称为LSM存储引擎。
二、B-Trees
B-Tree是最广泛使用的索引结构。
日志索引结构将数据库分解为可变大小的段,B-Tree将数据库分解成固定大小的页。页是内部读写的最小单元。页用地址(磁盘地址)标识。
某一页被指定为B-Tree的根。根包含了若干对<key-子页的引用>,每个子页包含一定范围内的键和引用。一个页包含的子页引用数量称为分支因子。
在底层的写操作是覆盖旧页。
崩溃恢复方法:B-Tree修改必须先写日志再修改树本身。
对比LSM-Tree和B-Tree
1.LSM-Tree写放大更低,因为以顺序方式写入SSTable而不是重写树中多个页。
2.LSM-Tree磁盘上文件比B-tree小,因为B-Tree页中某些空间无法使用。LSM-Tree会通过合并减少碎片。
3.日志结构的缺点是压缩占用磁盘有限的并发资源和带宽,会导致读写请求等待,压缩速度和写入速度不匹配等问题。
三、事务处理与分析处理
事务:组成一个逻辑单元的一组读写操作。
OLTP:联机事务处理。是传统关系型数据库的主要应用,用来执行一些基本的、日常的事务处理,比如数据库记录的增、删、改、查等等。
OLAP:对实时性要求不高,但处理的数据量大,通常应用于复杂的动态报表系统上。
数据仓库:用于分析目的的单独的数据库。针对分析访问模式**进行优化。
星型模式:事实表(按时间发生的事件)位于中间,周围围绕着维度表。
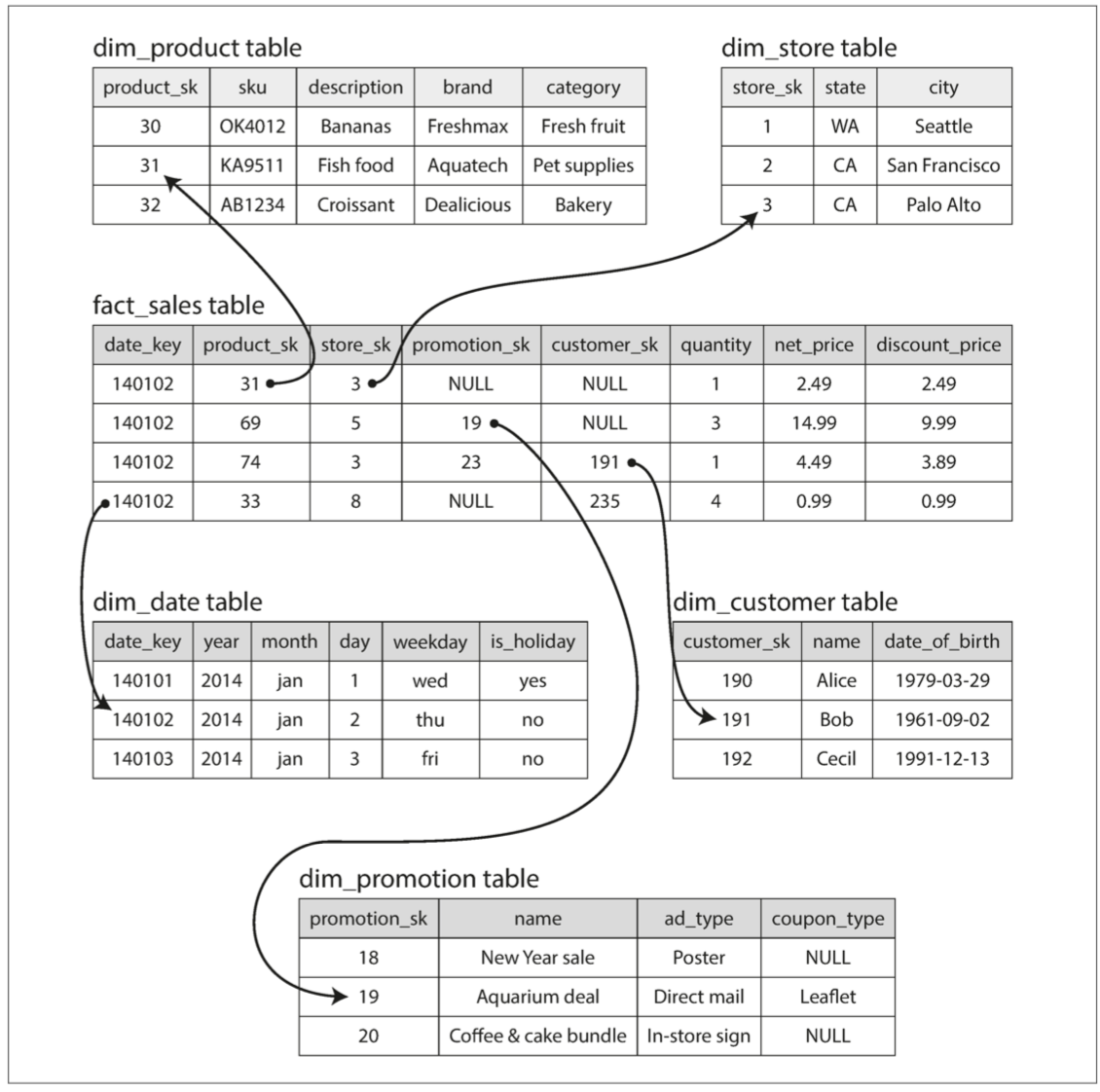

列式存储:行式存储适合的场景:频繁增删改查,每次都会对一条数据的所有属性读取。但读取大量数据但只分析少数属性的场景时,还需要把每条数据都读到内存。列式存储把每列单独保存为一个文件,每个文件以相同的顺序保存数据行,便于组装成行。
列压缩:往往,列中不同值的数量小于行数。每个2不同的值可以转换为一张位图,每一位表示这一位对应的行有没有这个值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号