

201871030123-癿盼盼 实验二 个人项目《背包问题》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | https://edu.cnblogs.com/campus/xbsf/2018CST |
| 这个作业要求链接 | https://www.cnblogs.com/nwnu-daizh/p/14552393.html |
| 我的课程学习目标 | 1.根据阅读《构建之法》,掌握PSP流程。 2.根据项目要求,完成项目D{0-1}KP的项目要求。 3.学习使用github。 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.学习和了解PSP流程。 2.了解了D{0-1}KP与最基本的KP问题的区别。 3.掌握如何利用去解决D{0-1}KP问题。 |
| 项目Github的仓库链接地址 | https://github.com/piepanpan/shiiyan |
任务1: 阅读教师博客“常用代码管理工具与开发工具”内容要求,点评班级博客中已提交相关至少三份作业
作业1:https://www.cnblogs.com/niujianjiang/p/14522679.html
作业2:https://www.cnblogs.com/wangfenqxx/p/14539846.html
作业3:https://www.cnblogs.com/wanghuijuan815/p/14548782.html
任务2:详细阅读《构建之法》第1章、第2章,掌握PSP流程
第一章主要是对这门课程的概述,讲述了一个教学基础,对于师生关系我们该有一个怎样的认识和理解。对于当下的几种大学师生关系(春蚕和园丁,餐馆和食客,老板和雇员,报名和幼儿,哥们和哥们,路人甲和路人乙,狱警和犯人),做了一个详细的讲解。其中理想的师生关系是教练与学员的关系,老师和学生要及时的互相反馈。而教师手段是将师生投入到教学活动中,教学评价是教学成熟度模型,而最终的结果是让学生有收获。还通俗易懂的介绍了软件工程是怎样的,以及介绍了微软学术搜索项目10个版本的历程。
第二章重点介绍了PSP,其中PSP对于软件开发的工作量和质量的衡量有四个因素,包括项目/任务有多大,花了多长的时间,质量怎样,是否按时交付。也用实例介绍了一个软件工程师在接到一个任务后应该怎样做,也介绍了PSP流程是怎样的,包括计划,开发,记录时间花费,测试报告,计算工作量,事后总结,提出过程改进计划。我们可以按照给出的实例写出属于我们自己的PSP。也介绍了PSP的特点。还通过实例来讲解了程序效能分析以及单元测试和回归测试。其中运用了VSTS效能分析工具和用VSTS来写单元测试,也学习了一个好的单元测试应该是怎样的。从中可以看到创建单元测试函数的主要步骤:
(1)设置数据(一个假想的正确的E-mail地址);
(2)使用被测试类型的功能(用E-mail地址来创建一个User类的实体);
(3)比较实际结果和预期的结果(Assert.IsTrue(target!= null);)。
任务三
-
需求分析
{0-1}背包问题({0-1 }Knapsack Problem,{0-1}KP)是最基本的KP问题形式,它的一般描述为:从若干具有价值系数与重量系数的物品(或项)中,选择若干个装入一个具有载重限制的背包,如何选择才能使装入物品的重量系数之和在不超过背包载重前提下价值系数之和达到最大?D{0-1} KP 是经典{ 0-1}背包问题的一个拓展形式,用以对实际商业活动中折扣销售、捆绑销售等现象进行最优化求解,达到获利最大化。D{0-1}KP数据集由一组项集组成,每个项集有3项物品可供背包装入选择,其中第三项价值是前两项之和,第三项的重量小于其他两项之和,算法求解过程中,如果选择了某个项集,则需要确定选择项集的哪个物品,每个项集的三个项中至多有一个可以被选择装入背包,D{0-1} KP问题要求计算在不超过背包载重量 的条件下,从给定的一组项集中选择满足要求装入背包的项,使得装入背包所有项的价值系数之和达到最大;D{0-1}KP instances数据集是研究D{0-1}背包问题时,用于评测和观察设计算法性能的标准数据集;动态规划算法、回溯算法是求解D{0-1}背包问题的经典算法。 -
功能设计
-
可正确读入实验数据文件的有效D{0-1}KP数据;
-
能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图;
-
能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;
-
用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位);
-
任意一组D{0-1} KP数据的最优解、求解时间和解向量可保存为txt文件或导出EXCEL文件。
-
-
设计实现
在本次设计中运用了python去编写代码,其中运用到了linecache模块,该模块是用于从文件中得到行的模块,常用于从文件中读取已知位置的行。
(1)函数原型:linecache.getlines(filename)
用于从filename文件中读取全部内容,存储为列表格式。
(2)函数原型:linecache.getline(filename,lineno)
从 filename文件中读取第lineno行。
其中为了更好的得到数据也运用到了split()通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串。remove() 函数用于移除列表中某个值的第一个匹配项(该程序中是为了删除当用split()进行切片时产生的“\n”)。round()方法返回 x 的小数点四舍五入到n个数字(该程序中是为了对于价值重量比结果更加在接下来的排序中方便)。
- 测试运行
读入实验数据文件中的IDKP0:

价值:重量比,再进行非递增排序:

散列图
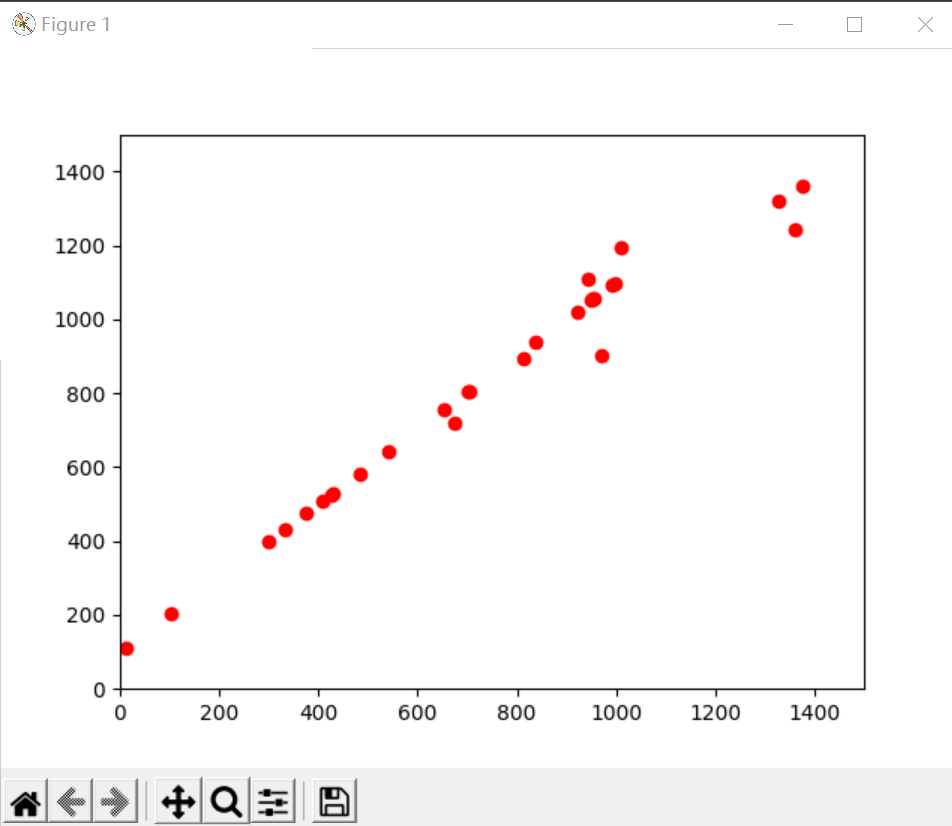
D{0-1}kp问题没有理解,因此进行了{0-1}kp的动态规划算法:

- 粘贴自己觉得比较独特的或满意的代码片段
利用linecache模块进行文件相关内容读取并算出价格:重量比:
profit_weight3
import linecache
the_profit=linecache.getline('idkp1-10.txt',6)#读入价值
the_weight=linecache.getline('idkp1-10.txt',8)#读入重量
the_profit1=the_profit.split(',')
the_weight1=the_weight.split(',')
the_profit1.remove('\n')
the_weight1.remove('\n')
the_profit2=list(map(int,the_profit1))
the_weight2=list(map(int,the_weight1))
profit_weight=[a/b for a,b in zip(the_weight2,the_profit2)]#价格:重量比
profit_weight3=[]
for i in profit_weight:
j=round(i,3)#保留三位小数
profit_weight3.append(j)
print("价值/重量(保留三位小数)排序结果为:")
print(str(profit_weight3)+"\n")
动态回溯算法:
def backpack(number, weight, w, v):
#初始化二维数组,用于记录背包中个数为i,重量为j时能获得的最大价值
result = [[0 for i in range(weight+1)] for i in range(number+1)]
#循环将数组进行填充
for i in range(1, number+1):
for j in range(1, weight+1):
if j < w[i-1]:
result[i][j] = result[i-1][j]
else:
result[i][j] = max(result[i-1][j], result[i-1][j-w[i-1]] + v[i-1])
return result
- 总结
在程序中进行程序模块化,降低了程序的出错率,提高了程序的可靠性。
- 展示PSP
| psp2.1 | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 10 | 15 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 8 | 10 |
| Development | 开发 | 360 | 460 |
| Analysis | 需求分析 | 12 | 14 |
| Design Spoc | 生成设计文档 | 10 | 15 |
| Coding Standard | 代码规范 | 5 | 7 |
| Design | 具体设计 | 15 | 20 |
| Coding | 具体编码 | 240 | 420 |
| Code Review | 代码复审 | 30 | 25 |
| Test | 测试 | 30 | 40 |
| Reporting | 报告 | 15 | 25 |
| Test Report | 测试报告 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 20 | 25 |
在本次项目中只完成了一部分功能,从PSP中我们可以看到项目开发和具体编码花费的时间比较多,在项目开发这一块是有很少的资料去具体讲解D{0-1}kp问题,因此最终将以{0-1}kp问题去解决。对于具体编码这一块是因为本来编码能力较差并且具体的python语法到目前记忆的不多了,需要花费大量的时间去回顾知识点。还有在画散列图时安装pip一直不合适,也花费了较多的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号