

Java基础——String类缓存hashcode与对象头markword中缓存的hashcode
写给自己
永远记得,能看懂和能说明白是两回事。最典型的,好比是网络知识,学过的都能理解个大概,但如果尝试讲出来那是另一般风景,“The next level~”。我常认为,学习者应该为自己学习的知识做“持久化”。其因有二:
- 互联网上的资料良莠不齐,大多是像我等这样的学习者留下的深浅不一的文章,而其中不乏有错误。而对于初学者,则是是非非很难分辨,想要搞到相对正确的说法,则需要翻阅大量的资料去理解一件事,相信对于原理学习者们都深有体会。初次学习时,应该记录下来那些能够将自己思路打开的文章,哪怕是仅仅将自己觉得优秀的文章留在收藏夹里都比什么都不做要好得多。
- 人是会忘的,各位求职者面试前背的滚瓜烂熟的所谓面经,到真正用时又能剩下几成功力?这时脑海中已经有一些印象,可能记得对也可能记得错,再次看互联网上的文章们,是否会对它们进一步产生怀疑,觉得“和我记忆的不一样,谁是对的”?这更加浪费时间。
- callback,能看懂和能说明白是两回事。当你写完了一篇,如果能给别人启发,那么你成了。
所以,不论初学亦是复习,还是兴趣爱好者,都应该做一些记录。最近我也以博客的形式记录,去尝试用文字把要表达的内容说明白,在反复推敲用词和行文的过程中,去感受把一件事说明白的快感。
主题
众所周知,Java当中设计的String类型是不可变的,这样做有很多原因,也有很多好处,如常量池缓存、线程安全等等。不过这不是今天的主题,今天的主题是String类中出现的一个说特别不特别但说不特别又不知道为什么会出现在这里的字段:

为什么要在String中多用一些空间存一次hashcode?对象的对象头[1]中不是已经有hashcode了吗?在Object类中,有一个native方法hashCode,但是却没有一个hash的字段,原因就在于Java将对象的hashcode值放在了对象头里,我们可以通过jol包来验证的确是有hashcode:
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
实验
自定义一个W类,然后来查看对象头中的内容,从输出中可以看到,Java将hashcode的值缓存在了对象头中。(这里还可以看Java的存储是大端法,最高的字节59存在了对象头中最高字节的位置)
package com.jol;
import org.openjdk.jol.info.ClassLayout;
/**
* <p>
*
* <p> create: 2024/5/30 9:33
*
* @author Pidan
*/
public class HashCode {
public static void main (String[] args) {
W w = new W();
w.w = "w";
System.out.println(ClassLayout.parseClass(w.getClass()).toPrintable(w));
System.out.println(Integer.toHexString(w.hashCode()));
System.out.println(ClassLayout.parseClass(w.getClass()).toPrintable(w));
System.out.println("--------------------------------------------------------");
System.out.println(ClassLayout.parseClass(w.w.getClass()).toPrintable(w.w));
System.out.println(w.w.hashCode());
System.out.println(ClassLayout.parseClass(w.w.getClass()).toPrintable(w.w));
}
static class W {
private String w;
}
}
先看分割线上面部分的输出:
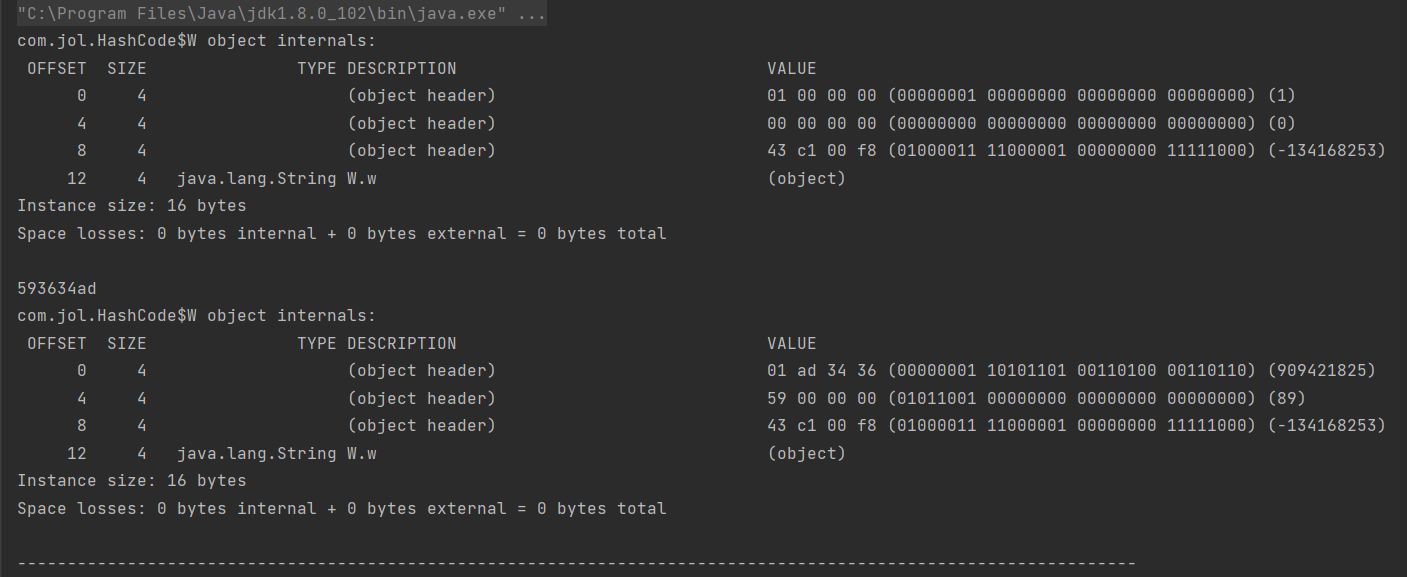
那String会将hashcode缓存吗?来看输出:
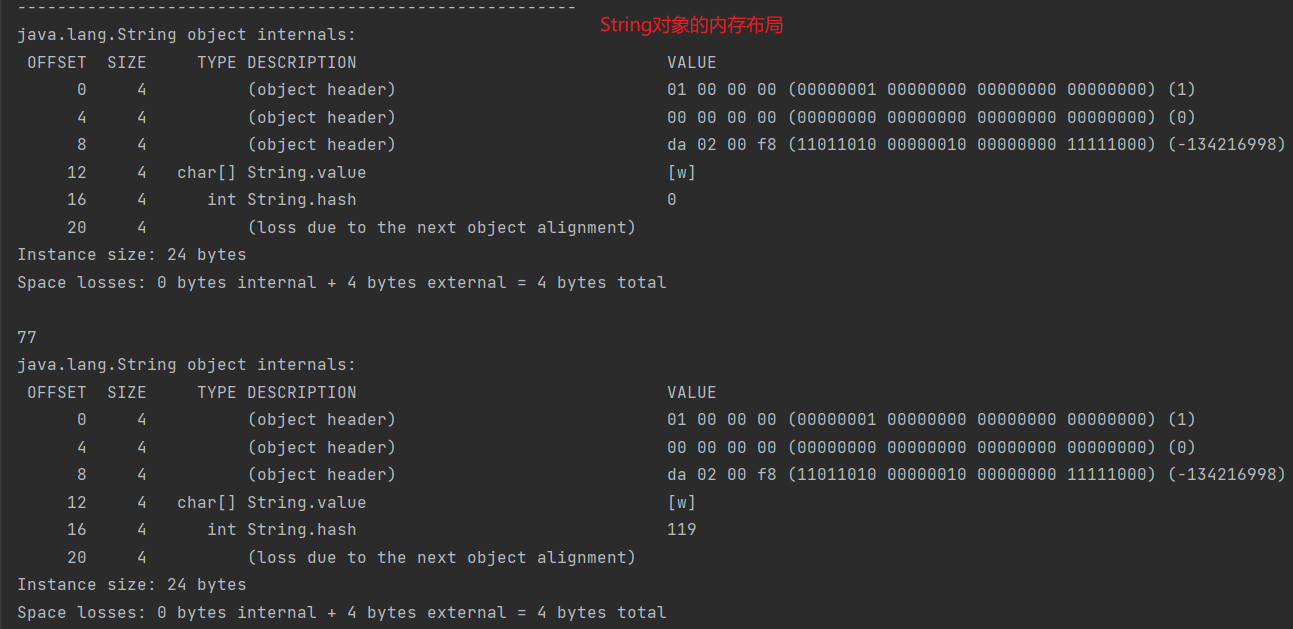
我们发现,String并没有将hashcode放入对象头中,即便调用了hashCode方法,对象头中依然没有写入[2]。仅仅是这样吗?我们再来试试Integer类和StringBuffer类:
System.out.println("---------------------Integer--------------------------");
Integer i = 123456789;
System.out.println(ClassLayout.parseClass(i.getClass()).toPrintable(i));
System.out.println(Integer.toHexString(i.hashCode()));
System.out.println(ClassLayout.parseClass(i.getClass()).toPrintable(i));
System.out.println("---------------------StringBuffer--------------------------");
StringBuffer sb = new StringBuffer();
System.out.println(ClassLayout.parseClass(sb.getClass()).toPrintable(sb));
System.out.println(Integer.toHexString(sb.hashCode()));
System.out.println(ClassLayout.parseClass(sb.getClass()).toPrintable(sb));
输出结果显示,Integer也没有将hashCode缓存到对象头,但是StringBuffer有在存储:
---------------------Integer--------------------------
java.lang.Integer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 67 22 00 f8 (01100111 00100010 00000000 11111000) (-134208921)
12 4 int Integer.value 123456789
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
75bcd15
java.lang.Integer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 67 22 00 f8 (01100111 00100010 00000000 11111000) (-134208921)
12 4 int Integer.value 123456789
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
---------------------StringBuffer--------------------------
java.lang.StringBuffer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) c1 1a 00 f8 (11000001 00011010 00000000 11111000) (-134210879)
12 4 int AbstractStringBuilder.count 0
16 4 char[] AbstractStringBuilder.value [ , , , , , , , , , , , , , , , ]
20 4 char[] StringBuffer.toStringCache null
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
2530c12
java.lang.StringBuffer object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 12 0c 53 (00000001 00010010 00001100 01010011) (1393299969)
4 4 (object header) 02 00 00 00 (00000010 00000000 00000000 00000000) (2)
8 4 (object header) c1 1a 00 f8 (11000001 00011010 00000000 11111000) (-134210879)
12 4 int AbstractStringBuilder.count 0
16 4 char[] AbstractStringBuilder.value [ , , , , , , , , , , , , , , , ]
20 4 char[] StringBuffer.toStringCache null
Instance size: 24 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
我的观点
首先,不论在哪里缓存hashCode,我们都清楚它的目的是加快比较的速度,这也是为什么Java的集合框架多用hashCode来比较键是否一致,因为它真的很快,只需要拿出已经缓存的值即可(如果可以缓存)。而用equals判断则需要运行一段逻辑。对于大量读的操作,hashCode是有必要的。在Java开发中,约定在需要在集合中使用的类,重写了equals方法后要重新hashCode方法,其实与对象头中存不存储hashCode息息相关。其实,考虑重写这两个方法的根本原因,是我们要通过这个对象的属性来判断两个对象是否相等,比如两个学生对象,有一个属性是学号,只要这两个对象的学号相同,我们会认为是一个对象,这是很常见的情景。但是,如果真的将这个对象的学号放入对象头中,其实会引来问题:我们不清楚hashCode会不会变。什么意思,详细点说就是,在对象使用过程中,我们可能会更改用于计算hashCode的值的字段,这与程序的设计有关。所以,当hashCode方法被重写时,我们每一次调用这个对象的hashCode方法时,实际上都需要重新计算hashCode,否则可能带来错误,这时再缓存就毫无意义,所以对象头中不再存储hashCode。
那么基于上面的猜想,再来探讨String为什么要在类中加一个hash字段就变得容易了。首先有这样几个前提,String是不可变的,虽然String重写了equals和hashCode方法用于判等,但是由于不可变,实际上hashCode也不会再变了(String的hashCode是基于value字节数组的),这时再每次计算就很浪费,光想想就觉得可惜,明明不会变,难道还要每次把char数组遍历一遍,算一个大家都知道一定跟上次计算结果一模一样的值吗?所以,这就与上面提到的场景不同了,为了减少计算的开销,防止在集合框架这种大量读的时候带来很多不必要的重复计算,还是需要一个缓存,这才在String中加了这样一个字段。
这样看来,每一个字段都是有原因的,最开始考虑不是已经有一个缓存了吗,为什么还要加缓存,是否是浪费?答案到这里就清楚了,当然不是浪费,而且很必要。
“再缓存就毫无意义,所以对象头中不再存储hashCode”这句话是否有根据?
为了说服自己,我又再次验证了这个观点——对象头中不再缓存hashCode的确是因为重写了hashCode。定义这样一个类:
class W1 {
private String w1;
@Override
public int hashCode () {
return Objects.hash(w1);
}
}
测试代码:

什么都没变,仅仅只重写了hashCode,对象头中就不再有hashCode了。输出:
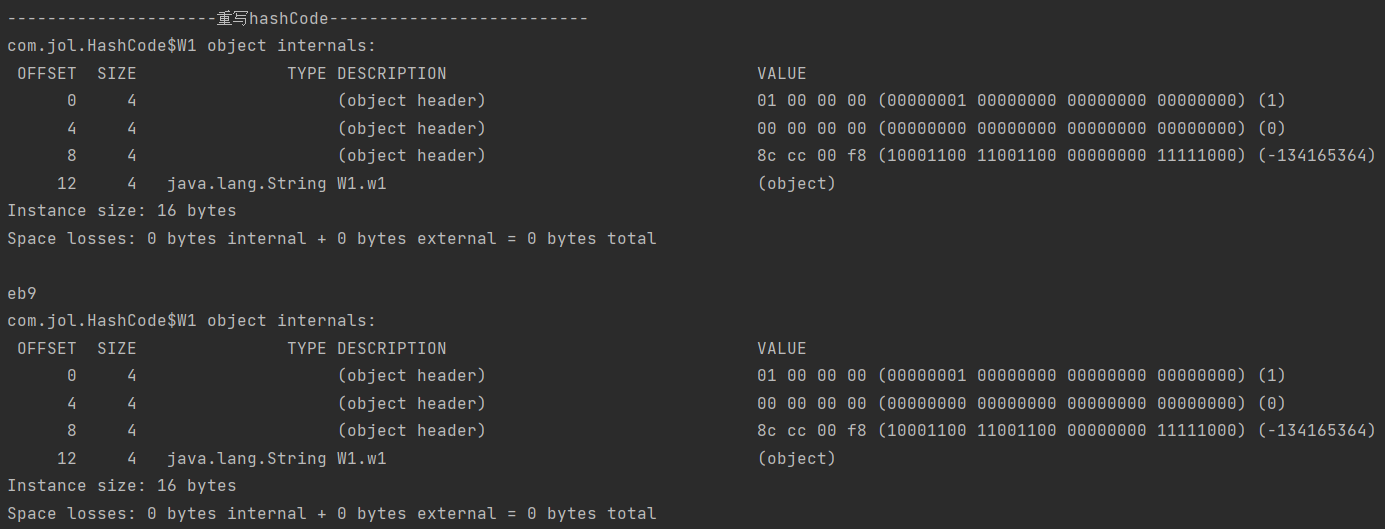
这样就严谨多了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具