

数据库聚簇索引——not null条件对唯一键索引成为聚簇索引的影响
本人持虚心学习态度,如有勘误欢迎指正!不胜感激,如帮到您理解,还望点赞支持!
数据库聚簇索引的规则如下:
- 如果有主键,则主键是聚簇索引(当然主键也不一定是单个列的);
- 如果没有主键,但是有not null修饰的唯一键索引,则这个索引是聚簇索引;
- 都没有,创建一个叫db_row_id的6字节隐藏列为聚簇索引,这个索引程序员不可见(这个列存在一定冲突和性能问题,详见大佬:https://www.cnblogs.com/frankcui/p/15226301.html)。
所以一般还是要定义主键。如果不定义主键,再想通过创建索引的方式提高性能,那无论创建多少个索引,本质上都是二级索引,都要进行回表(本来一个主键就可以解决的事情,现在仍旧有一个聚簇索引,还额外多了那个原来定义主键就可以创建的索引,反而占用空间)。同样的查询,IO次数变多,这是不值当的。
那有没有not null是否真的影响unique列成为聚簇索引?
写在前面:其实所谓这个证明与否没有那么重要,结论就摆在那里。重要的是其中隐含的SQL优化芝士知识——是否用到索引?怎么用的?如何看type、key、extra?给出的值含义又是什么?完整的走一遍这个流程,相信再次看这些字段的值会有一些思考,需要优化我们的SQL时会有一些方向。OK,下面正文:
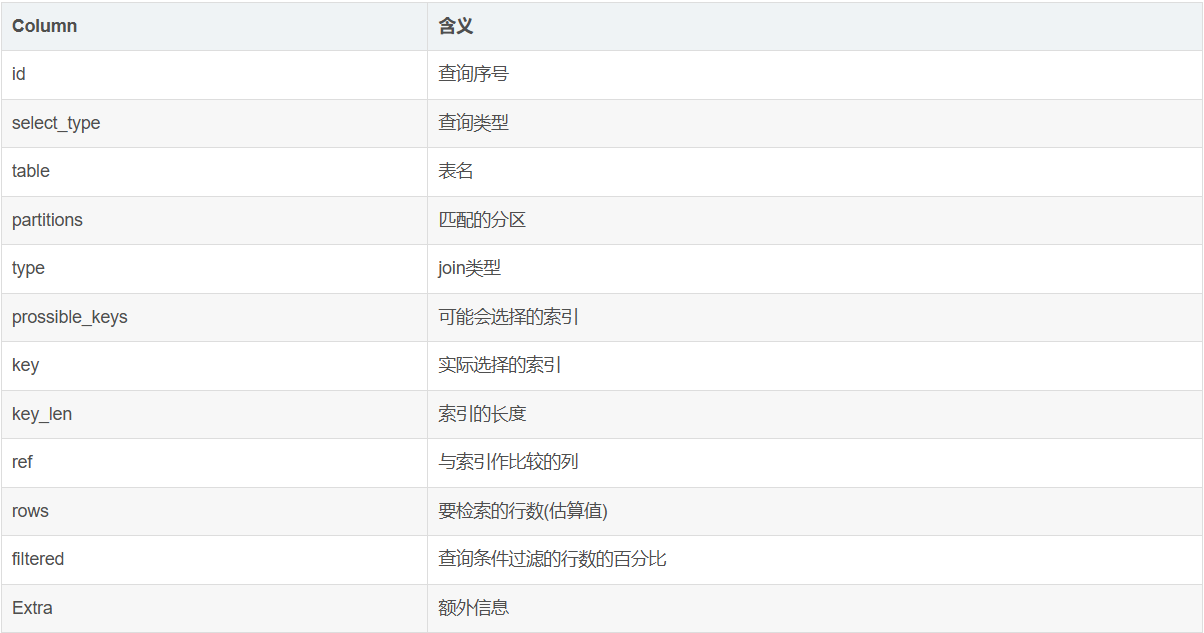
从下面的介绍看起来,我们无法直接从explain中找到是否走聚集索引的信息,官方文档中介绍到,extra字段中大抵只是看是否覆盖,而聚集索引是一个“索引即数据”的概念,它就是完整的表了,即便主键没有覆盖掉所有select的列,它的特点也保证所有的列真正覆盖了(不知道的应自行搜索聚簇索引),所以使用聚集索引的extra字段可能为null。官方文档:
https://www.cnblogs.com/kerrycode/p/9909093.html
Using index (JSON property: using_index)
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
For InnoDB tables that have a user-defined clustered index, that index can be used even when Using index is absent from the Extra column. This is the case if type is index and key is PRIMARY.
从表中仅使用索引树中的信息就能获取查询语句的列的信息, 而不必进行其他额外查找(seek)去读取实际的行记录。当查询的列是单个索引的部分的列时, 可以使用此策略。(简单的翻译就
是:使用索引来直接获取列的数据,而不需回表)。对于具有用户定义的聚集索引的 InnoDB 表, 即使从Extra列中没有使用索引, 也可以使用该索引。如果type是index并且Key是主键, 则会出现这种情况。
翻译翻译就是你用主键的聚簇索引,可能看起来没有覆盖,但是实际上所有数据都在这里了,默认就是覆盖了。
那怎么判断是否走了聚簇索引呢?就算有唯一键的聚簇索引,用了还是不知道的。我有这样一个思路:
如果唯一键可以为null时,按照理论不应该是聚簇索引,当查询的列有的不在唯一键索引覆盖范围内则应该会有回表(回聚集索引去查),即可以从某些方面佐证发生回表,如索引下推。接下来的目的就是寻找这个证据。
准备两张表,id为unique键,分别加上not null(按理论为聚簇索引)和default null(可以为空)修饰。在查询时,查询的列要多于唯一键索引列,这样才能区分出当前唯一键索引中是否保存了全部的数据,即是否聚簇索引:
CREATE TABLE `test_unique` (
`id` int NOT NULL,
`col1` varchar(255),
`col2` varchar(255) NOT NULL,
UNIQUE KEY `uni` (`id`) USING BTREE COMMENT '测试没有主键的情况下,唯一键是不是聚簇索引与not null的关系'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
CREATE TABLE `test_unique2` (
`id` int DEFAULT NULL,
`col1` varchar(255),
`col2` varchar(255) NOT NULL,
UNIQUE KEY `uni` (`id`) USING BTREE COMMENT '测试没有主键的情况下,唯一键是不是聚簇索引与not null的关系'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
准备数据:
分别执行这样一个语句:
explain select id, col1 from test_unique where id in (89,98);
结果:


区别就在于Using index condition,找到对这个值的解释:https://www.cnblogs.com/echoppy/p/14247575.html
很幸运得到这个结果,我的mysql的版本支持索引下推,也从侧面佐证了“当唯一键索引为null时,并不能成为聚簇索引,否则就直接查出所有的值,不发生下推”。到此证明结束。
还有:
using where不代表一定会回表- 可以为null索引列的key长度比同一列NOT NULL属性长度多1个字节
补充——如果extra为Using index condition时代表一定使用了索引下推,至少目前所搜索到的所有资料都是这么描述
似乎并没有完,到这里我产生了另一个疑问,我所拥有的芝士似乎让我无法理解这为什么会有索引下推优化:根据互联网上现有的索引下推的博客也好、解释也好,说的都是两个筛选条件,先将索引中可以推断的条件筛选完毕,筛选条件不在索引的列中的条件自MySQL 5.6以后从 逐一到聚簇索引中搜索 修改为 将结果集从二级索引取出后总体到聚簇索引中筛选where中剩余条件,其目的是为了减少IO的次数,这直观地就能感觉到IO次数的减少。
BUT这里只有一个条件啊?以下是我本人的理解(目前还没能找到相关的、更多其他人相同意见的博客):
首先,所谓索引下推,就是为了减少回表的次数,如果在二级索引中找到10条记录,在不开启索引下推时,这十条记录每次都要去聚簇索引搜索一遍,假设B+树有3层,那就要30次磁盘IO。开启索引下推后,拿出全部的十条记录的键去聚簇索引扫描,哪怕十条记录都分散在10个叶子结点上(考虑mysql的innodb引擎的索引存储模型),也只需要遍历叶子结点的页,即12次IO左右(我希望我的计算是正确的,到达叶子结点后按序遍历叶子结点找到所有的记录的完整的值),减少磁盘IO的次数。
为什么这里也可以是索引下推呢?按照5.6版本以前的操作,找到一条在二级索引中符合条件的记录,就会尝试到聚簇索引中看是否满足其他条件,如满足则将二级索引中未覆盖的列添加到结果集中(这里没有相当于一直是true,只添加其他列的值),如按照索引下推优化的思路来理解,就是在二级索引中拿到所有id的值,再到聚簇索引中拿剩余的列,这与此优化的理念并不冲突!如果我是数据库的开发设计者,我当然不会拒绝这样的优化,不会执拗于是否有多个条件才减少回表操作。
另:
当我在试图寻找佐证时,有一个现象引起了我的好奇:尝试用这样一个语句去判断是否走索引——
explain select id, col1 from test_unique where id > 23;
注意到唯一键索引可以为空时,范围查询会使索引失效:

NOT NULL时,可以发现范围查询走了索引,此时的唯一键索引与主键无二。

小结
实验本身的目的不在于试图推翻现在的结论,而是对现有的结论多一些直观的认识,并通过实践的形式对感兴趣的概念加深认识和理解。本文涉及的知识点有索引以及SQL优化、explain查询计划、索引下推等。
赠给自己
实践本身全在学习,常看常新略有所得。不应过分追究得失,实践过程深浅立知。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具