

HashMap的底层实现原理
1,HashMap 的数据结构
JDK 1.7 的数据结构

JDK 1.8的数据结构
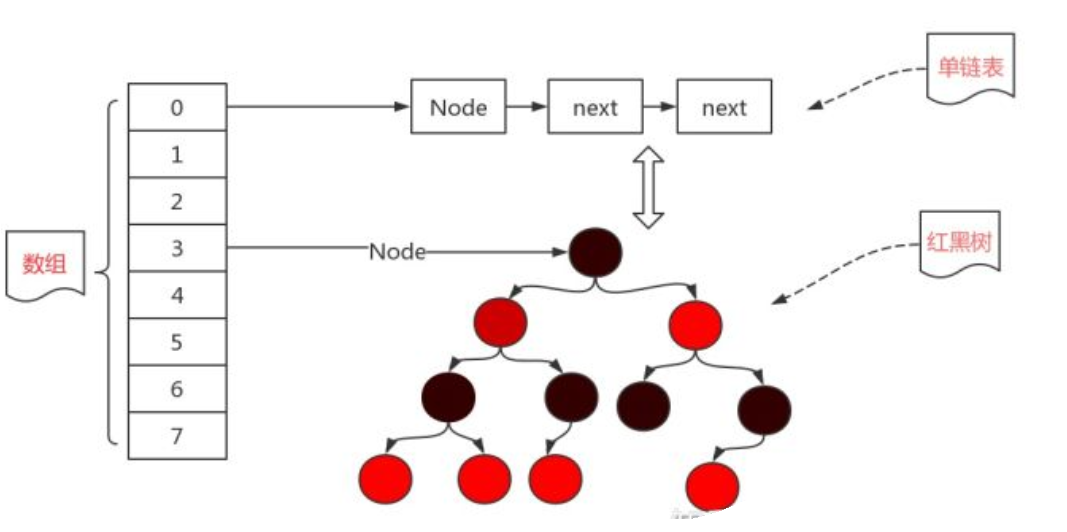
2,Hashmap 的数据结构最小的单位是Node<k,V>, 是一个个键值对,从HashMap 遍历就可以看出来
static class Node<K,V> implements Map.Entry<K,V>
for (Map.Entry<String, String> entry : map.entrySet()) { System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue()); }
Node<K,V>(单向链表) 或者 TreeNode<K,V> (红黑树)
链表的头节点,或者红黑树的根节点是存储在数组上
3,HashMap hash冲突
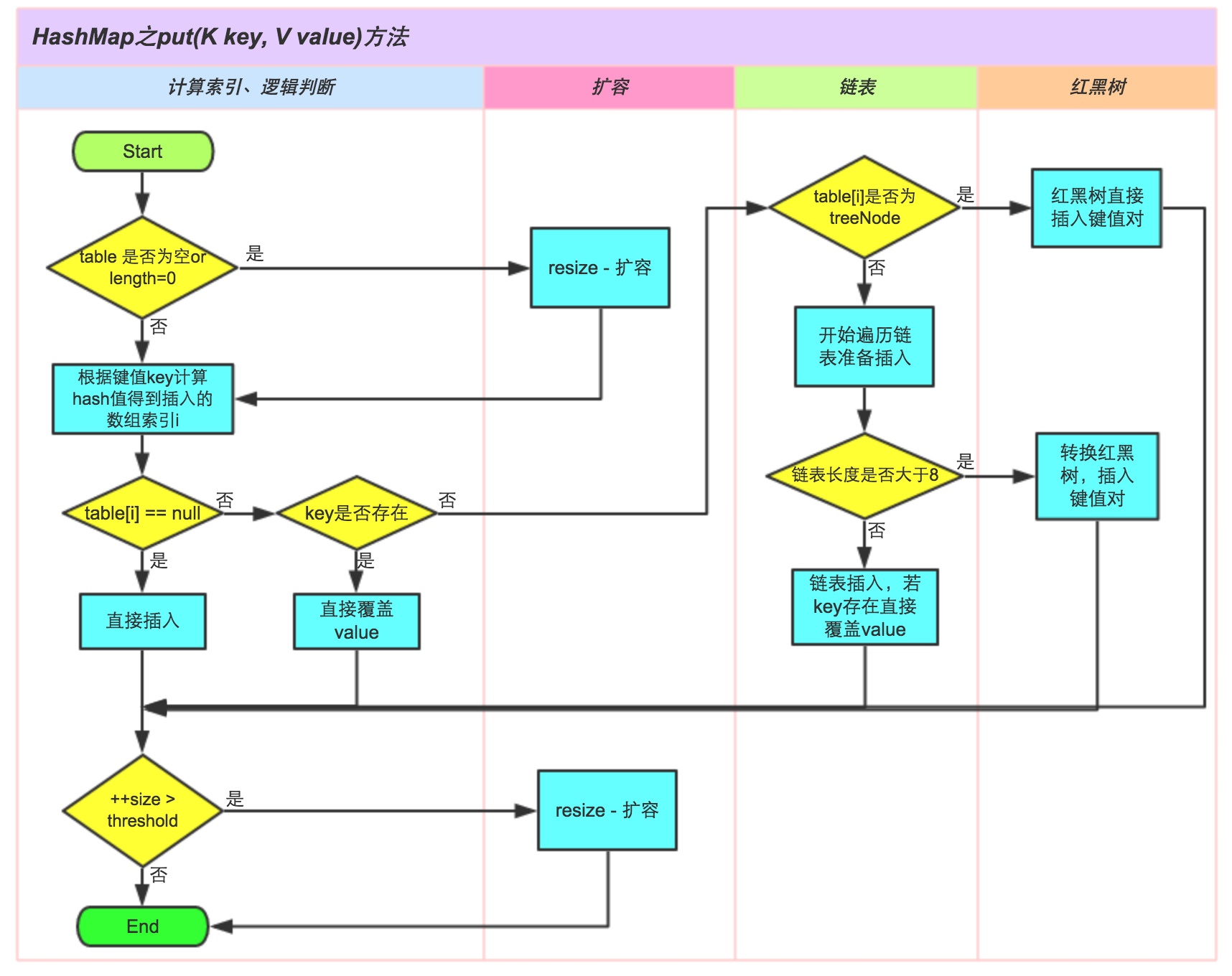
当你往HashMap 增加一个值的时候,首先会调用下面这个方法:
也就是通过hashcode 和 高位算法,得出一个hash 值
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
再通过(n - 1) & hash 查看有没有hash 冲突,其实功能等同于取模算法
就是说,
比如你插入一个key="A",value="A"算出hash 值为11233,再通过取模算法,算出在数组table上下标是2,于是你就新建一个节点 newNode(hash, “A”, "A", null).
在插入一个key="CH",value="CH",算出hash 值未11298,再通过取模算法,算出在table上下标是也是2,判断key又和之前的不一样,于是hash冲突了,这时候,我要新建一个节点,连接之前的节点。
因为,如果相同的hash 值的key,放在同一个数组位置,链表越长,查询效率就越低,其实最后能够让key 的元素均匀分布在数组上,所以数据的长度一般都是2的幂次,hash 发生碰撞的概率就比较小
所以在JDK 1.7 的时候,可能table 上的一个索引,绑定的链表就会很长很长,导致查询的效率很低,于是JDK 1.8 换成了数组+ 链表 + 红黑树,当链表的长度大于8 的时候会转换成红黑树
4,Hashmap 扩容 以及 Hashmap 死循环
Hashmap 因为是一个数组,当达到一定的使用率的时候,就会扩容。
DEFAULT_LOAD_FACTOR:负载因子
DEFAULT_INITIAL_CAPACITY:初始化的数组的大小
threshold:阀值
hashmap 里面的元素的个数超过 threshold 的时候(DEFAULT_LOAD_FACTOR * CAPACITY )就需要扩容了,也就是站在数组的每个位置只存一个node,当数组使用率达到0.75时候,就需要扩容,扩大2倍
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length;//初始化的时候容量为0 int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) //初始化的不为空的map集合的时候,已经确定了threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr;//重新赋值threshold,链表里面的要添加的元素超过这个参数,意味着要扩容 @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
扩容之后,需要将old table 写入到 new table 里面,JDK 1.7 参考:
遍历旧的数组,每个数组上还有链表,也一致遍历,重新计算hash,重新获取新的数组下标位置
void transfer(Entry[] newTable) { Entry[] src = table; //src引用了旧的Entry数组 int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素 if (e != null) { src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象) do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置 e.next = newTable[i]; //标记[1] newTable[i] = e; //将元素放在数组上 e = next; //访问下一个Entry链上的元素 } while (e != null); } } }
在JDK 1.7 因为是数组 + 链表的结构 ,所以在并发环境下可能出现死循环的情况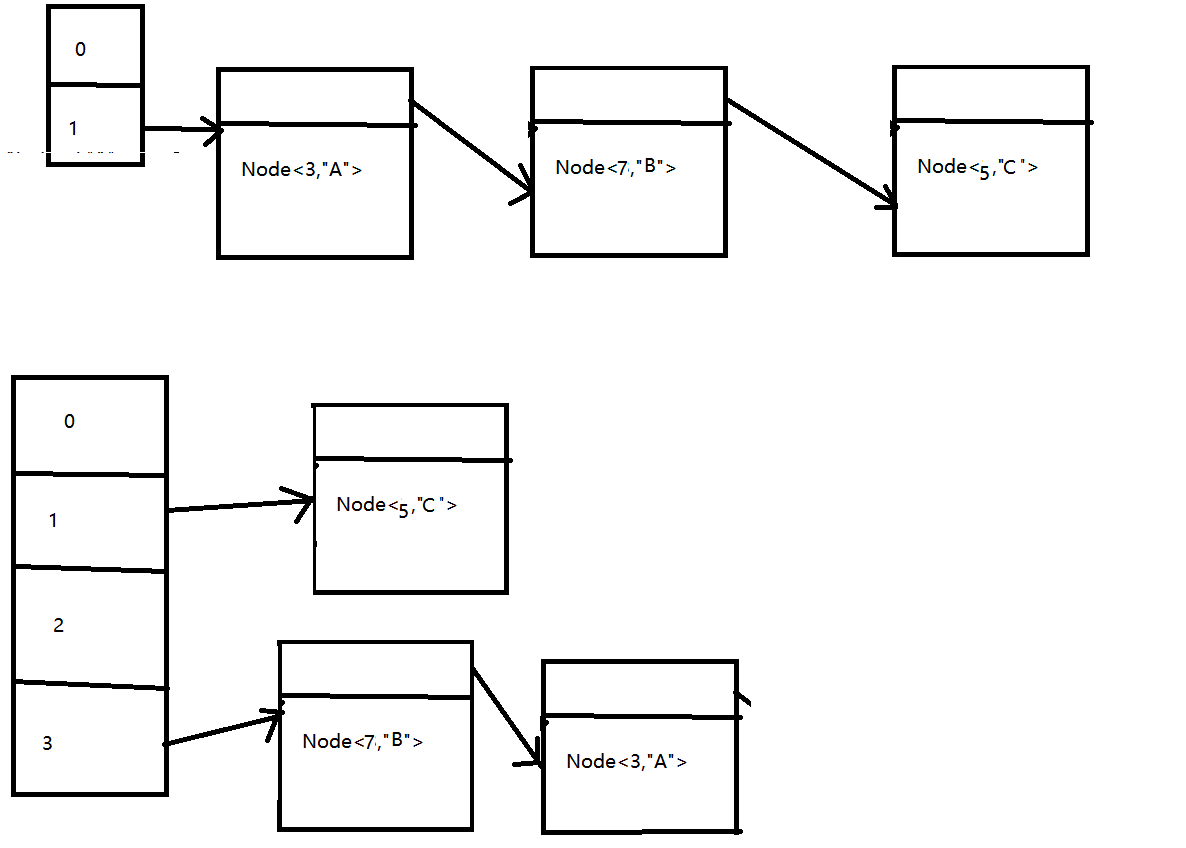
大致意思就是两个线程同时扩容,一个已经扩容完毕,已经更改了链表的结构,另一个没有扩容完毕,导致A线程的在节点Node<3,"A"> 还指向Node<7,"B"> ,但是线程B 已经将Node<7,"B"> 指向了node<3,"A"> 出现了循环指向,死循环出现
//这个算法的目的是找到大于等于cap的最小2的幂的值,n >>> 1,高位补0,不带符号位,(将二进制中高位的1向低位移),n |= n >>> 1 等同 n = n | n >>> 1, |:位移中的或,有真则真(有1 则 1),所以 n | n >>> 1 的值是增大的,同理 n | n >>> 2 也是增大的,直到n | n >>> 16, 因为MAXIMUM_CAPACITY 的值1 << 30 ,01000000000000000000000000000000,所以,最多有效位移是31位,(1 + 2 + 4 +8 +16) 因此到16 位之后,便可以找最小的2的幂的值。 //为什么要cap -1,因为如果cap 正好是2的幂,如果不减1,得到的结果就是cap 的2倍,例如,cap = 8,如果不减1,得到的结果是16,但是想得到的结果就是8.所以需要先减去1,最后再加上1. 如果cap 的结果为9,减去1 之后为8,最后得到的结果是15,在加上1,结果为16,满足大于等于9的最小幂。所以需要先减去1. static final int tableSizeFor(cap){ int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 (n >= MAXIMUM_CAPACITY) ? MAXMUM_CAPACITY : n +1 ; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号