

Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图
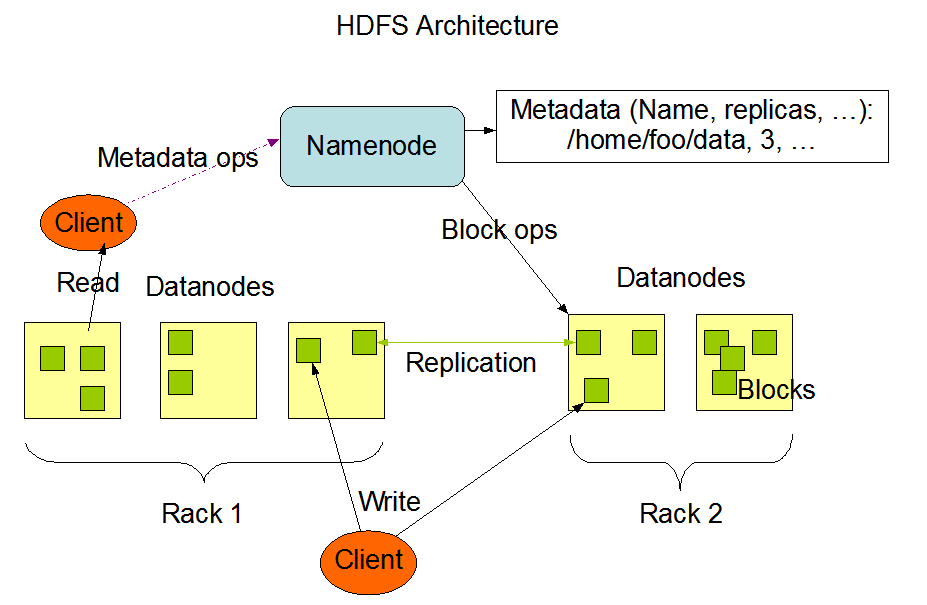
NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等。NameNode将这些信息加载到内存并进行拼装,就成为了一个完整的元数据信息
NameNode的启动过程:
第一次启动:
NameNode存储的元数据放置在:
* 内存
*本地磁盘
*fsimage(镜像文件)
*edits(编辑日志文件)
1, 格式化hfds 文件系统,就是为了生成fsimage
2,启动namenode,就会读取fsimage,就能够读取到里面的文件名称,目录结构,namenode 可以提供对外服务了
3, 启动datanode,首先会注册,会发送block report 给namenode,namenode 会将datanode 发送的block report 加起来,和已经知道的block 数量进行比较,一致,则datanode 也可以对外提供服务了。
至此,文件系统就可以使用,可以读写数据
4,当我们在hdfs创建,修改,删除目录的时候,hdfs 的namespace 已经改变,本地磁盘,内存并没有改变,edits(编辑日志文件)会将namespace 改变的内容写入
第二次启动:
1,读取fsimage w文件
2,读取 edits(编辑日志文件)
获取了最新的namenode 存储的元数据信息
3,会把fsimage 和 edits 写入到内存了, 生成一个新的fsimage
4,生成一个空的edits
5,start namenode
6,start datanode
HDFS集群中存在单点故障(SPOF),对于只有一个NameNode 的集群,若是NameNode 出现故障,则整个集群无法使用,知道NameNode 重新启动。
NameNode 主要在以下两个方面影响HDFS集群
*NameNode 机器发生意外,如宕机,集群将无法使用,直到管理员重启
*NameNode机器发生升级,包括软件,硬件升级,此时集群也将无法使用
HDFS HA 功能则通过配置Active/StandBy 两个NameNodes 实现在集群中对NameNode 的热备来解决上述问题,如果出现故障,如机器崩溃或机器需要升级维护,这时可以通过此种方式将NameNode很快的切换到另一台机器。
HA 的原理理解请参照下面的博主:
https://blog.csdn.net/weixin_39915358/article/details/80216366
DataNode在本地文件系统存储文件块数据,以及块数据的校验
<name>dfs.datanode.data.dir<name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
这个属性,就是配置datanode 存在在本地磁盘的一个目录,现在默认的是${hadoop.tmp.dir}
在core-site.xml 配置如下:
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
Secondary NameNode(上图没有显示出来)用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
SecondaryNameNode 辅助NameNode,定期的将fsimage 和 edits 合并,生成new fsimage,节省下次启动时间
下次启动Hdfs文件系统的时候,只需要读取fsimage 和 没有合并的edits 文件,节省时间
HDFS的基本存储单元(block),文件在HDFS上被分成若干个block块,, 默认的bocksize=128M , 若文件258M,则共有block=3,实际占有存储258M,最后一块只占用2M。如果设置的副本数为3的话,则整个集群上存在9个block,放置位置随机。
YARN 诞生
The fundamental(根本的)idea of YARN is to split up the functionalities(功能) of resource management and job scheduling/monitoring into separate daemons.(守护进程) The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority (最大的权力)that arbitrates(仲裁) resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
在hadoop 1.0 中是没有yarn的,只有MapReduce,MapReduce 负责集群资源的管理(cluster resource management)以及 数据处理(data processing)
在hadoop 2.0 中,Yarn 诞生了,也就是MapReduce(2.0) ,将集群资源的管理和数据处理功能分开,MapReduce只做数据处理框架,YARN 负责集群资源的管理,这样Yarn 成为了Hadoop 的操作系统,因为是操作系统,Yarn 上面就可以运行可以框架,Strorm(流失框架),Spark(内存框架)
YARN 架构图
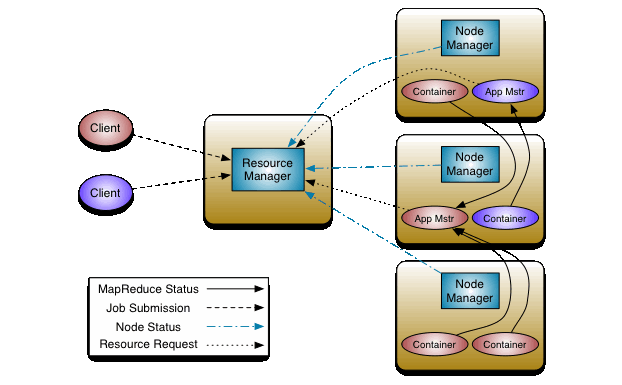
解析:
* YARN 总体上是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave
* ResourceManager负责对各个NodeManager上的资源进行统一的管理和调度。
* 当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,他负责向ResourceManager申请资源,并要求NodeManager启动可以占用一定资源的任务
* 由于不同的ApplicationMaster 被分布到不同的节点上,因此他们之间不会相互影响
ResourceManager:全局的资源管理器,整个集群只有一个,负责集群资源的同一管理和调度分配
处理客户端请求
启动/监控ApplicationMaster
监控NodeManager
资源分配和调度
NodeManager: 整个集群有多个,负责单点资源管理和使用。NodeManager管理抽象容器,这些容器代表可供一个特定应用程序使用的针对每个节点的资源。定时向ResourceManager汇报本节点上的资源使用情况和各个Container的运行状态
单个节点上的资源管理
处理来自ResouceManager 的命令
处理来自ApplicationMaster的命令
ApplicationMaster:管理一个YARN内运行的应用程序的每个实例。负责协调来自ResouceManager的资源,开通过NodeManager监视容器的执行和资源使用(CPU,内存等的资源分配)
数据切分
为应用程序申请资源,并分配给内部任务
任务监控与容错
Container:YARN中的资源抽象,封装某个节点上多维度资源,如内存,CPU,磁盘,网络等,当ApplicationMaster 向 ResourceManager 申请资源时,ResourceManager 向ApplicationManager 返回的资源便是用Container 表示的。YARN 会为每一个任务分配一个Container,且该任务只能使用该Container中描述的资源。
对任务运行环境的抽象,描述一系列信息,封装了CPU,内存等多维资源以及环境变量,启动命令等任务运行相关的信息
Yarn 的 资源管理
*资源调度和资源隔离是Yarn作为一个资源管理系统,最重要和最基础的两个功能。资源调度由ResourceManager完成,而资源隔离是由各个NodeManager 实现
*ResouceManager 将某一个NodeManager上的资源分配给任务(这就是所谓的资源调度)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离
*当谈及到资源时,我们通常指内存,CPU和IO三种资源,Hadoop YARN 同时支持内存和CPU 两种资源的调度。
* 内存资源的多少会决定任务的生死,如果内存不够,任务可能会运行失败,相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
*YARN 允许用户配置每个节点上可用的物理内存资源,“可用的” 是因为一个节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HFDS,一部分给HBASE,YARN配置的只是自己可以使用的,配置参数如下:
1,yarn.nodemanager.resource.memory-mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),如果你的节点内存不够8GB,则需要调小这个值,而YARN不会智能的探测节点的物理内存总量
2,yarn.nodemanager.vmem-pmem-ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1
3,yarn.nodemanager.pmem-check-enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
4,yarn.nodemanager.vmem-check-enabled
是否启动一个线程检查每个任务正使用的虚拟的内存量,如果任务超出分配值,则直接将其杀掉,默认是true
5,yarn.schedule.minimum-allocation-mb
每个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数
6,yarn.schdule.maximum-allocation-mb
每个任务可申请的最多物理内存量,默认是8192(MB)
*目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN 自己引入的概念,初衷是,考虑到不同的节点的CPU性能可能不同,每个CPU具有计算能力也是不一样的,比如某个物理CPU的计算能力可能是另一个物理CPU的2倍,这时候,
你可以通过第一个物理CPU多配置几个虚拟CPU弥补这种差异,用户提交作业时,可以指定每个任务需要的虚拟CPU个数,在YARN中,CPU相关配置参数如下:
1,yarn.nodemanager.resource.cpu-vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是8,目前推荐该值设值为物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调小这个值,而YARN不会智能的探测节点的物理CPU总数
2,yarn.schedule.minimum-allocation-vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数小于该数,则该对应的值改为这个数
3,yarn.schedule.maximum-allocation-vcores
单个任务可申请的最多虚拟CPU个数,默认是32
离线计算框架 MapReduce
将计算过程分为两个阶段,Map和Reduce
*Map 阶段并行处理输入数据
*Reduce 阶段对Map结果进行汇总
Shuffle 连接Map和Reduce 两个阶段
*Map Task 将数据写到本地磁盘
*Reduce Task从每个Map Task 上读取一份数据
仅适合离线批处理
*具有很好的容错性和扩展性
*适合简单的批处理任务
缺点明显
*启动开销大,过多使用磁盘导致效率低下等
mapReduce 运行原理参考以下博文:
https://www.cnblogs.com/sharpxiajun/p/3151395.html
wordCount :


package com.hella.hadoop.mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @author :chris * */ public class WordCountMapReduce extends Configured implements Tool { /* * public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { */ public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { private final static IntWritable MAPOUTPUTVALUE = new IntWritable(1); private Text mapOutputKey = new Text(); @Override protected void cleanup(Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub super.cleanup(context); } @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String lineValue = value.toString(); StringTokenizer token = new StringTokenizer(lineValue); while (token.hasMoreTokens()) { String wordValue = token.nextToken(); mapOutputKey.set(wordValue); context.write(mapOutputKey, MAPOUTPUTVALUE); } } @Override protected void setup(Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub super.setup(context); } } public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { private static IntWritable reduceOutputValue = new IntWritable(); @Override protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub super.cleanup(context); } @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } reduceOutputValue.set(sum); context.write(key, reduceOutputValue); } @Override protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub super.setup(context); } } public static void main(String[] args) throws Exception { // String[] argss = { "/user/chris/mapreduce/wordcount/input", // "/opt/tools/eclipse-workspace/hadoop/src/main/resources/output" }; Configuration configuration = new Configuration(); // set compresss configuration.set("mapreduce.map.output.compress", "true"); // compress format :SnappyCodec configuration.set("mapreduce.map.output.compress.codec", "org.apcahe.hadoop.io.compress.SnappyCodec"); int status = ToolRunner.run(configuration, new WordCountMapReduce(), args); System.exit(status); } public int run(String[] args) throws Exception { Configuration conf = getConf(); // create job Job job = Job.getInstance(conf, this.getClass().getSimpleName()); // run jar job.setJarByClass(this.getClass()); // set job // input > map > reduce > output Path inPath = new Path(args[0]); FileInputFormat.addInputPath(job, inPath); // set map job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // set shuffle // partitioner // job.setPartitionerClass(cls); // sort // job.setSortComparatorClass(cls); // optional , combiner // job.setCombinerClass(cls); // group // job.setGroupingComparatorClass(cls); // set reduce job.setReducerClass(WordCountReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // output Path outPath = new Path(args[1]); FileOutputFormat.setOutputPath(job, outPath); // submit job boolean isSuccess = job.waitForCompletion(true); return isSuccess ? 0 : 1; } }
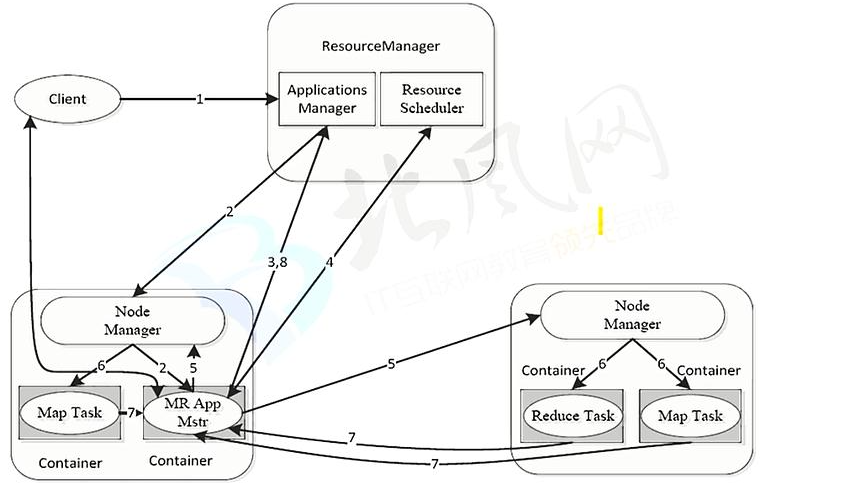
MapReduce On Yarn

 浙公网安备 33010602011771号
浙公网安备 33010602011771号