用nni进行模型剪枝的示例
第一步:模型训练
用下面的代码训练一个简单的模型:(数据集参考:利用pytorch的datasets在本地读取MNIST数据集进行分类)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.nn import Sequential
class Simple_CNN(nn.Module):
def __init__(self):
super(Simple_CNN, self).__init__()
self.conv1 = Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv2 = Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc1 = Sequential(
nn.Linear(7 * 7 * 128, 1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.fc2(x)
return x
def train(model, device, train_loader, test_loader, optimizer, criterion, epochs):
# model.train()
for epoch in range(epochs):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
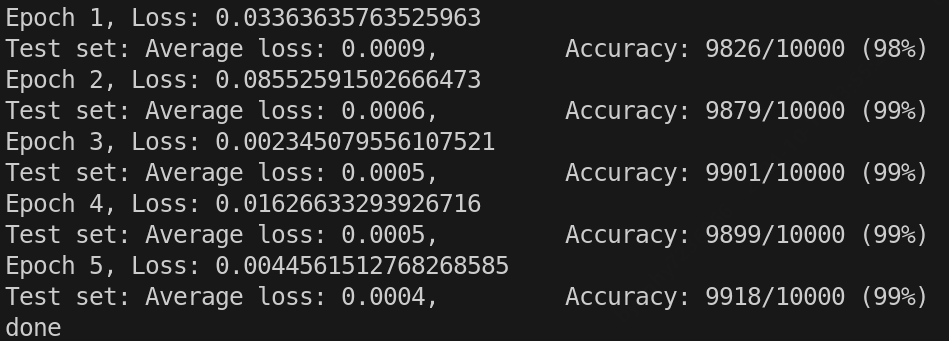
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
test(model, device, test_loader)
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, \
Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)')
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='dataset/mnist/', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='dataset/mnist/', train=False, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
model = Simple_CNN()
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
epochs = 5
train(model, device, train_loader, test_loader, optimizer, criterion, epochs)
# test(model, device, test_loader)
torch.save(model, 'model.pth')
print('done')
输出:
第二步:模型剪枝和模型微调
用下面的代码进行模型剪枝和微调:(用的nni的版本是3.0,直接pip install nni==3.0就可以)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.nn import Sequential
from nni.compression.pruning import L1NormPruner
from nni.compression.speedup import ModelSpeedup
class Simple_CNN(nn.Module):
def __init__(self):
super(Simple_CNN, self).__init__()
self.conv1 = Sequential(
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.conv2 = Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc1 = Sequential(
nn.Linear(7 * 7 * 128, 1024),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.shape[0], -1)
x = self.fc1(x)
x = self.fc2(x)
return x
def train(model, device, train_loader, test_loader, optimizer, criterion, epochs):
# model.train()
for epoch in range(epochs):
model.train()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
test(model, device, test_loader)
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, \
Accuracy: {correct}/{len(test_loader.dataset)} ({100. * correct / len(test_loader.dataset):.0f}%)')
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = torch.load('model.pth')
print('=================================== original model ===================================')
print(model)
# The following `config_list` means all layers whose type is `Linear` or `Conv2d` will be pruned,
# except the layer named `fc3`, because `fc3` is `exclude`.
# The final sparsity ratio for each layer is 50%. The layer named `fc3` will not be pruned.
config_list = [{
'op_types': ['Linear', 'Conv2d'],
'exclude_op_names': ['fc2'],
'sparse_ratio': 0.5
}]
pruner = L1NormPruner(model, config_list)
# show the wrapped model structure, `PrunerModuleWrapper` have wrapped the layers that configured in the config_list.
print('=================================== wrapped model ===================================')
print(model)
# compress the model and generate the masks
_, masks = pruner.compress()
# show the masks sparsity
for name, mask in masks.items():
print(name, ' sparsity : ', '{:.2}'.format(mask['weight'].sum() / mask['weight'].numel()))
# Speedup the original model with masks, note that `ModelSpeedup` requires an unwrapped model.
# The model becomes smaller after speedup,
# and reaches a higher sparsity ratio because `ModelSpeedup` will propagate the masks across layers.
# need to unwrap the model, if the model is wrapped before speedup
pruner.unwrap_model()
# speedup the model, for more information about speedup, please refer :doc:`pruning_speedup`.
ModelSpeedup(model, torch.rand(3, 1, 28, 28).to(device), masks).speedup_model()
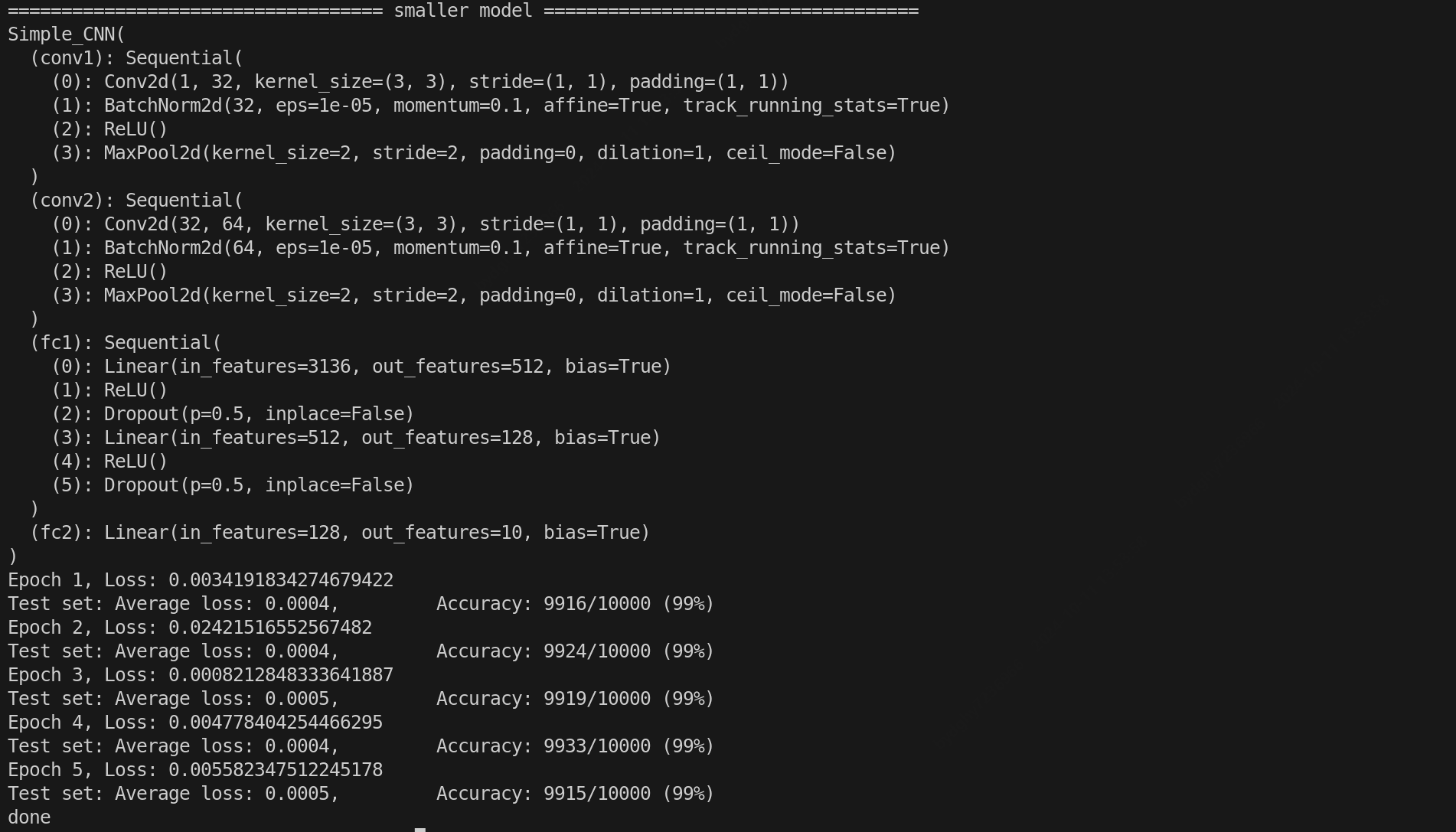
# the model will become real smaller after speedup
print('=================================== pruned model ===================================')
print(model)
torch.save(model, 'pruned_model.pth')
# fine-tune pruned modle
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.MNIST(root='dataset/mnist/', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='dataset/mnist/', train=False, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
epochs = 5
train(model, device, train_loader, test_loader, optimizer, criterion, epochs)
# test(model, device, test_loader)
torch.save(model, 'pruned_and_fine_tuned_model.pth')
print('done')
输出:
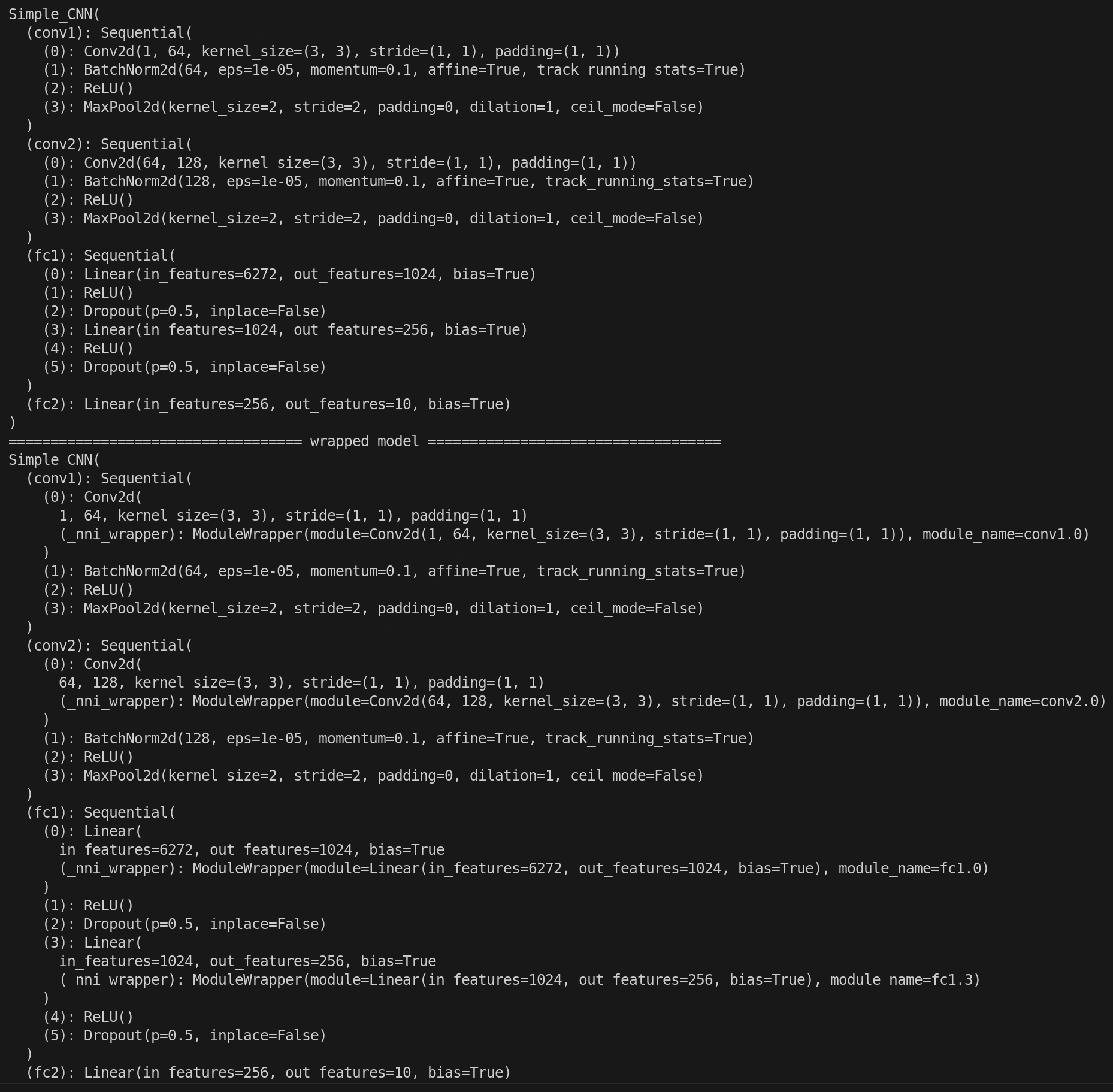
.......
在mmcv的runner中添加的内容:
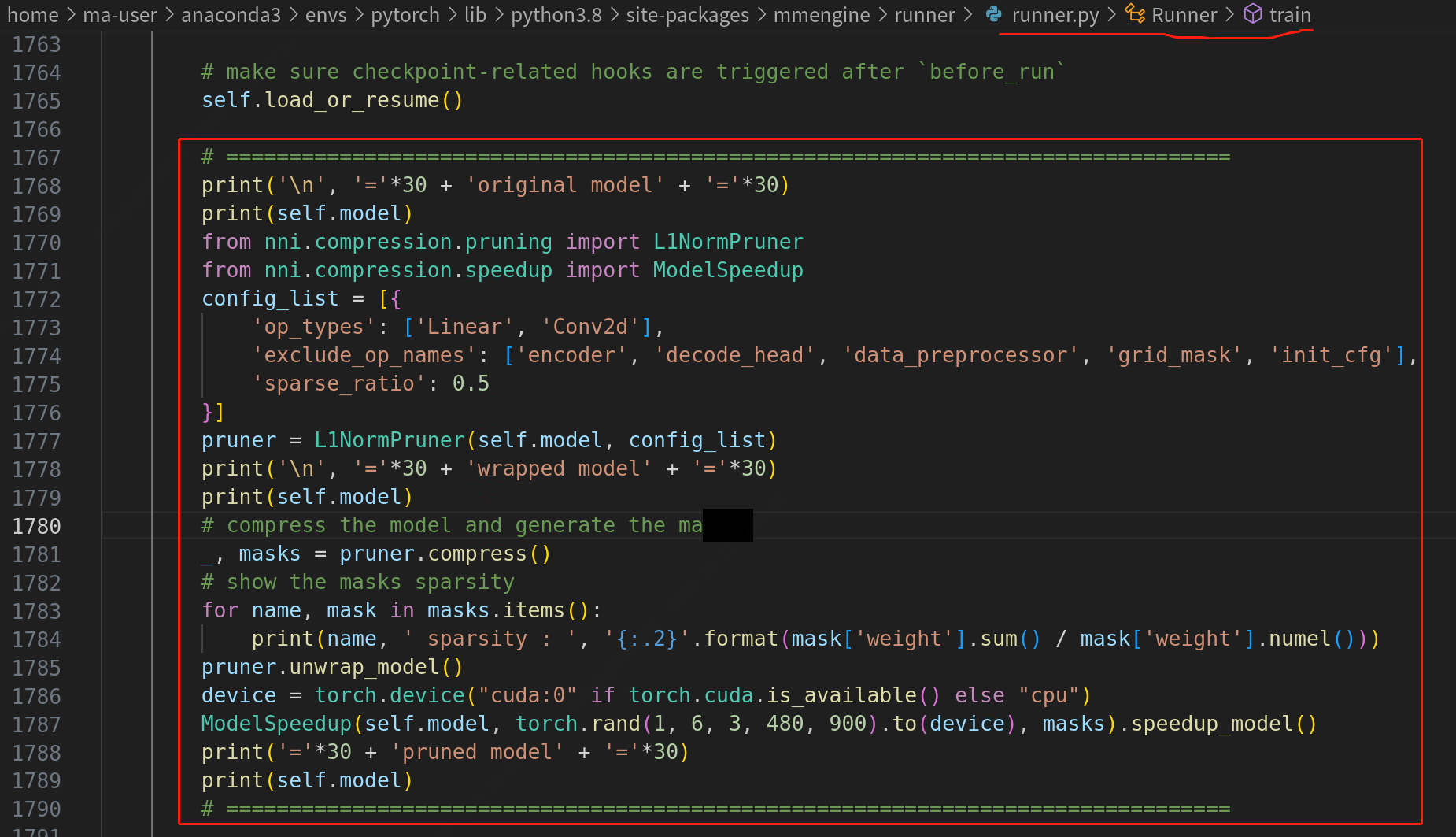
# ================================================================================
print('\n', '='*30 + 'original model' + '='*30)
print(self.model)
from nni.compression.pruning import L1NormPruner
from nni.compression.speedup import ModelSpeedup
config_list = [{
'op_types': ['Linear', 'Conv2d'],
'exclude_op_names': ['encoder', 'decode_head', 'data_preprocessor', 'grid_mask', 'init_cfg'],
'sparse_ratio': 0.5
}]
pruner = L1NormPruner(self.model, config_list)
print('\n', '='*30 + 'wrapped model' + '='*30)
print(self.model)
# compress the model and generate the masks
_, masks = pruner.compress()
# show the masks sparsity
for name, mask in masks.items():
print(name, ' sparsity : ', '{:.2}'.format(mask['weight'].sum() / mask['weight'].numel()))
pruner.unwrap_model()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
ModelSpeedup(self.model, torch.rand(1, 6, 3, 480, 900).to(device), masks).speedup_model()
print('='*30 + 'pruned model' + '='*30)
print(self.model)
# ================================================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号