Pytorch 多卡并行 torch.nn.DistributedDataParallel (DDP)
本文的内容摘自以下资料:
- PyTorch分布式训练简明教程 (知乎,推荐)
- PyTorch分布式训练基础--DDP使用 (知乎,推荐)
- Pytorch DistributedDataParallel简明使用指南 (知乎)
- pytorch多机多卡分布式训练(知乎)
- 详解PyTorch FSDP数据并行(Fully Sharded Data Parallel)-CSDN博客
DDP)是在每一个GPU卡上保存整个model的参数/梯度/优化器状态, 然后对数据集切分为 N NN 个shard分片给不同的GPU进行训练,计算完梯度后通过all-reduce通信来做梯度的融合。如下图:
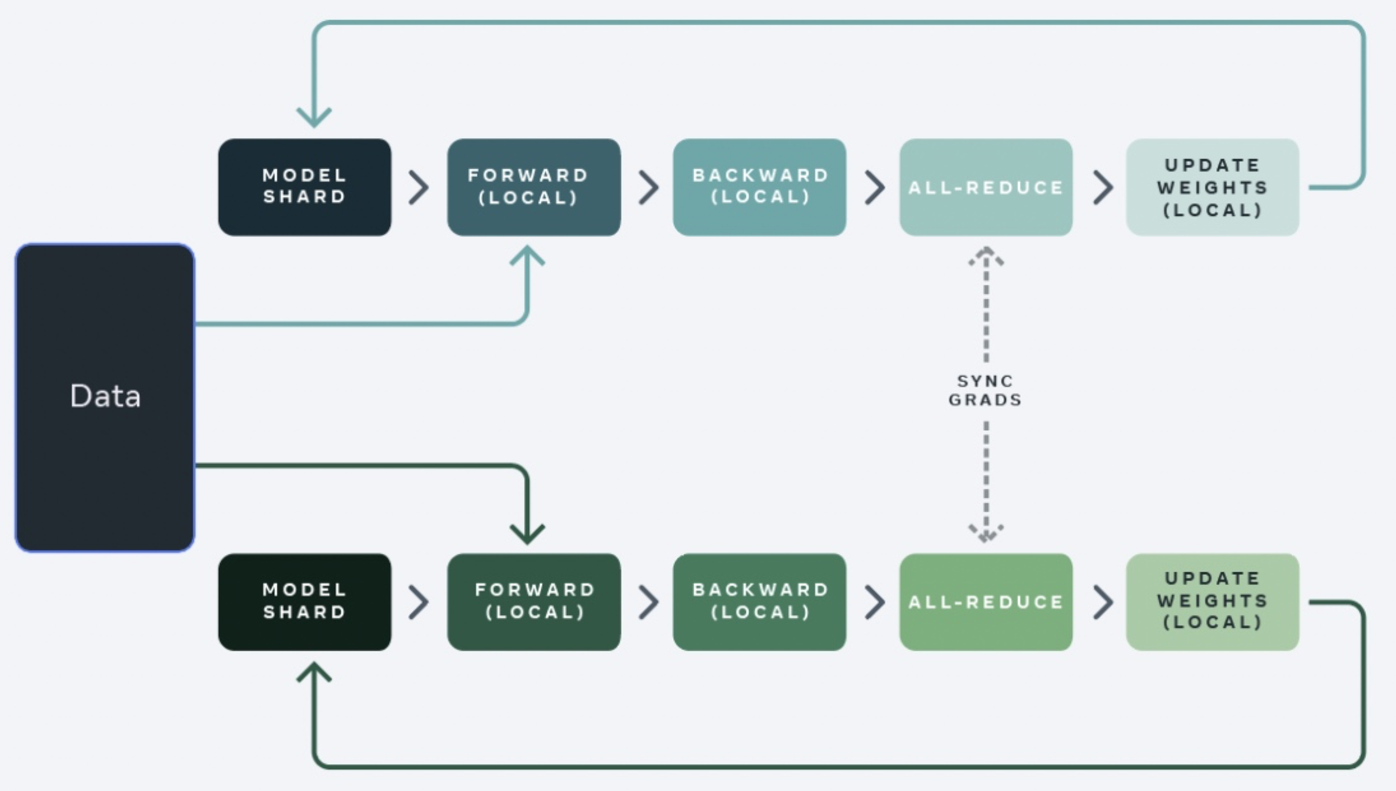
nn.DistributedDataParallel与nn.DataParallel的区别[1]
- DDP支持模型并行,而DP并不支持,这意味如果模型太大单卡显存不足时只能使用前者;
- DP是单进程多线程的,只用于单机情况,而DDP是多进程的,适用于单机和多机情况,真正实现分布式训练;
- DDP的训练更高效,因为每个进程都是独立的Python解释器,避免GIL问题,而且通信成本低,其训练速度更快,基本上
DP已经被弃用; - DDP中每个进程的数据都是从dataset中采样得到的,也就是说各个进程的数据并不相同。
- DDP中每个进程都有独立的优化器,执行自己的更新过程,但是梯度通过通信传递到每个进程,所有执行的内容是相同的。
- DDP比DP训练更快的原因之一是,DP需要在各个GPU之间分发样本数据、传递loss、传递梯度、分发权重等,而DDP只需要传递梯度。
分布式引入的参数及其含义[2]
- rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
- node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
- rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
- nnodes、node_rank与nproc_per_node: nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
- word size : 全局(一个分布式任务)中,rank的数量。
- Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group。
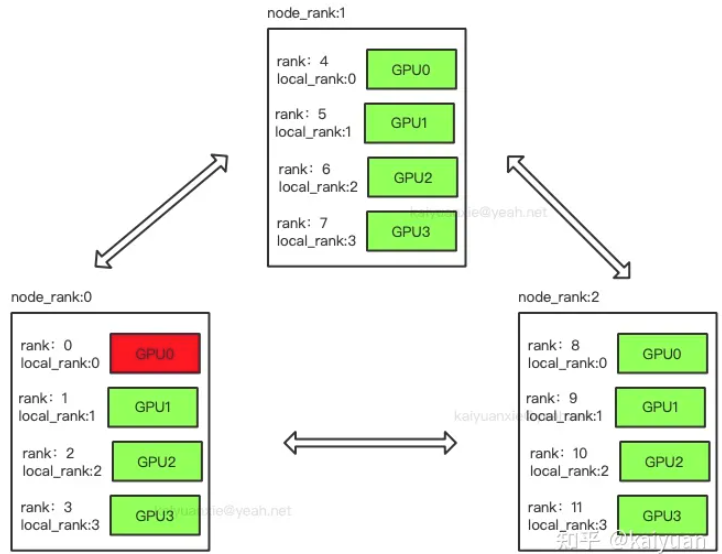
为了方便理解举个例子,比如分布式中有三台机器,每台机器起4个进程,每个进程占用1个GPU,如下图所示。图中:一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都有一个对应的node_rank。
注意:
1、rank与GPU之间没有必然的对应关系,一个rank可以包含多个GPU;一个GPU也可以为多个rank服务(多进程共享GPU)。
这一点在理解分布式通信原理的时候比较重要。因为很多资料里面对RingAllReduce、PS-WorK 等模式解释时,习惯默认一个rank对应着一个GPU,导致了很多人认为rank就是对GPU的编号。
2、"为什么程序里面的进程用rank表示而不用proc表示?"
这是因为pytorch是在不断迭代中开发出来的,有些名词或者概念并不是一开始就设计好的。所以,会发现node_rank 跟软节点的rank没有直接关系。
模型评估 (计算模型准确率)
How to calculate train accuracy with DDP
pytorch ImageNet distributed example
PyTorch Distributed Evaluation (Lei Mao's blog)
[另外可参考CJZ的相关代码]
两个示例[1,2,4]
示例一
import os
from datetime import datetime
import argparse
import torch.multiprocessing as mp
import torchvision
import torchvision.transforms as transforms
import torch
import torch.nn as nn
import torch.distributed as dist
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int, metavar='N',
help='number of total epochs to run')
args = parser.parse_args()
args.world_size = args.gpus * args.nodes
os.environ['MASTER_ADDR'] = '127.0.0.1' # 设置的是通讯的IP地址。在的单机单卡或者单机多卡中,可以设置为'127.0.0.1'(也就是本机)。在多机多卡中可以设置为结点0的IP地址
os.environ['MASTER_PORT'] = '8888' # 设置通讯的端口,可以随机设置,只要是空闲端口就可以。
mp.spawn(train, nprocs=args.gpus, args=(args,))
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def train(gpu, args):
rank = args.nr * args.gpus + gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=args.world_size, rank=rank)
torch.manual_seed(0)
model = ConvNet()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
# define loss function (criterion) and optimizer
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
model = nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
# Data loading code
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset,
num_replicas=args.world_size,
rank=rank)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
sampler=train_sampler)
start = datetime.now()
total_step = len(train_loader)
for epoch in range(args.epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.cuda(non_blocking=True)
labels = labels.cuda(non_blocking=True)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0 and gpu == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, args.epochs, i + 1, total_step,
loss.item()))
if gpu == 0:
print("Training complete in: " + str(datetime.now() - start))
if __name__ == '__main__':
main()
假设上面的程序文件名为test.py,单机单卡训练命令为 CUDA_VISIBLE_DEVICES=0 python3 test.py -n 1 -g 1 -nr 0
该命令的含义如下:
- CUDA_VISIBLE_DEVICES=0表示只使用服务器的第0张卡
- -n 1表示1个节点共同训练
- -g 1表示每个节点使用1个gpu
- -nr表示在所有的节点中目前节点的编码(从0开始)。
如果想用单机多卡训练,只需要在CUDA_VISIBLE_DEVICES=后面写上要使用的多个GPU的编号,然后将-g改成对应的GPU数量就可以了,例如,运行 CUDA_VISIBLE_DEVICES=0,1,2,3 python3 test.py -n 1 -g 4 -nr 0 使用1机4卡共同训练。
单机单卡训练结果:
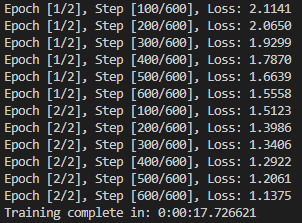
单机多卡训练结果:

从上面的结果中可以看到,虽然训练的都是2个epoch,但是最终loss相差较大,主要是因为单机多卡的实际batch_size=100*4,导致迭代优化次数比单机单卡少很多。
示例二
单机单卡代码:
import torch
import torchvision
import torch.utils.data.distributed
from torchvision import transforms
import torch.nn as nn
from datetime import datetime
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def main():
epochs = 20
batch_size = 100
# 数据加载部分,直接利用torchvision中的datasets
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('./data', train=True, transform=trans, target_transform=None, download=False)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=batch_size)
# 网络搭建,调用torchvision中的resnet
net = ConvNet()
net = net.cuda()
# 定义loss与opt
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.0001)
total_step = len(data_loader_train)
start = datetime.now()
# 网络训练
for epoch in range(epochs):
for i, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.cuda(), labels.cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if (i + 1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, epochs, i + 1, total_step, loss.item()))
print("Training complete in: " + str(datetime.now() - start))
# 保存checkpoint
# torch.save(net, "my_net.pth")
if __name__ == "__main__":
main()
单机多卡代码:
import os
import torch
import torchvision
import torch.distributed as dist
import torch.utils.data.distributed
from torchvision import transforms
from torch.multiprocessing import Process
import torch.nn as nn
from datetime import datetime
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
def main(rank):
epochs = 2
batch_size = 100
dist.init_process_group("gloo", rank=rank, world_size=3)
torch.cuda.set_device(rank)
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.MNIST('./data', train=True, transform=trans, target_transform=None, download=True)
train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=batch_size, sampler=train_sampler)
net = ConvNet()
net = net.cuda()
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[rank])
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.0001)
total_step = len(data_loader_train)
start = datetime.now()
for epoch in range(epochs):
for i, data in enumerate(data_loader_train):
images, labels = data
images, labels = images.cuda(), labels.cuda()
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if (i + 1) % 100 == 0 and rank == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch + 1, epochs, i + 1, total_step, loss.item()))
if rank == 0:
print("Training complete in: " + str(datetime.now() - start))
# if rank == 0:
# torch.save(net, "my_net.pth")
if __name__ == "__main__":
size = 3
processes = []
for rank in range(size):
p = Process(target=main, args=(rank,))
p.start()
processes.append(p)
for p in processes:
p.join()
单机单卡训练结果:
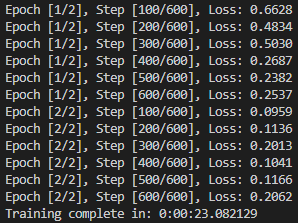
单机多卡训练结果:
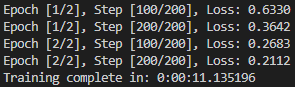
示例二和示例一采用相同的网络和数据,都训练2个epoch,示例二的最终loss比示例一的小很多,估计是因为所采用的的优化器不同,示例二采用的是adam,示例一采用的是SGD。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号