样本不平衡问题
参考资料
- 如何解决数据不平衡问题? (总结的很好,强烈推荐)
- 样本不均衡及解决办法 (推荐)
- 极端类别不平衡数据下的分类问题研究综述
- 处理样本不均衡的8个方法
- 知乎:样本类别不平衡及其处理手段
- 分类样本不平衡问题
- 解决分类样本不平衡问题 ~ ML&DM面试高频问题
总结一下
从数据角度:
- 获取更多的少量样本数据
- 欠采样,从多数类别中删除样本
- 过采样,为少数类别生成新样本
- 欠采样和过采用相结合
从评价指标的角度:
- 选择AUC作为评价指标时,采用PR曲线,而不是ROC曲线。因为在样本不均衡的时候,PR曲线更能准确反映模型的性能。(具体解释可参考这里)
从算法的角度:
- 集成学习(Ensemble集成算法)。首先从多数类中独立随机抽取出若干子集,将每个子集与少数类数据联合起来训练生成多个基分类器,再加权组成新的分类器,如加法模型、Adaboost、随机森林等。
- 将任务转换成异常检测问题。把只有极少数样本点一些类别作为异常值进行检测。
从训练的角度:
- 在损失函数上,对于不同样本数量的类别分别赋予不同的惩罚权重。对小样本量的类别惩罚权重高,大样本量的类别惩罚权重低。
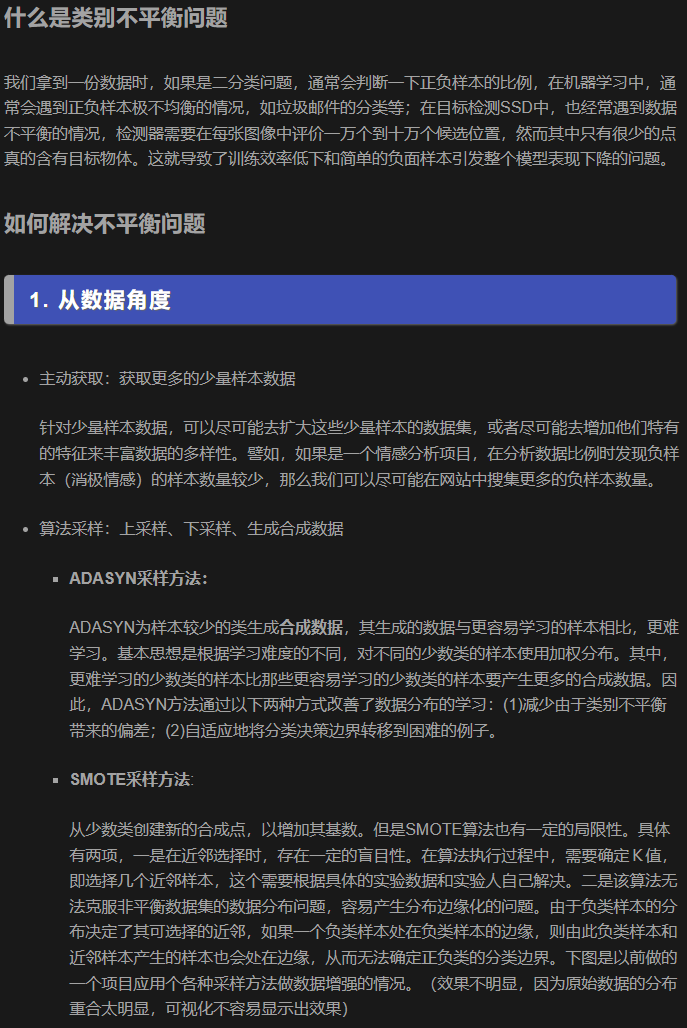
下面的截图来自上文的第一个链接。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号