图卷积神经网络GCN:整图分类(含示例及代码)
关于整图分类,有篇知乎写的很好:【图分类】10分钟就学会的图分类教程,基于pytorch和dgl。下面的代码也是来者这篇知乎。
import dgl
import torch
from torch._C import device
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from dgl.data import MiniGCDataset
from dgl.nn.pytorch import GraphConv
from sklearn.metrics import accuracy_score
class Classifier(nn.Module):
def __init__(self, in_dim, hidden_dim, n_classes):
super(Classifier, self).__init__()
self.conv1 = GraphConv(in_dim, hidden_dim) # 定义第一层图卷积
self.conv2 = GraphConv(hidden_dim, hidden_dim) # 定义第二层图卷积
self.classify = nn.Linear(hidden_dim, n_classes) # 定义分类器
def forward(self, g):
"""g表示批处理后的大图,N表示大图的所有节点数量,n表示图的数量
"""
# 为方便,我们用节点的度作为初始节点特征。对于无向图,入度 = 出度
h = g.in_degrees().view(-1, 1).float() # [N, 1]
# 执行图卷积和激活函数
h = F.relu(self.conv1(g, h)) # [N, hidden_dim]
h = F.relu(self.conv2(g, h)) # [N, hidden_dim]
g.ndata['h'] = h # 将特征赋予到图的节点
# 通过平均池化每个节点的表示得到图表示
hg = dgl.mean_nodes(g, 'h') # [n, hidden_dim]
return self.classify(hg) # [n, n_classes]
def collate(samples):
# 输入参数samples是一个列表
# 列表里的每个元素是图和标签对,如[(graph1, label1), (graph2, label2), ...]
# zip(*samples)是解压操作,解压为[(graph1, graph2, ...), (label1, label2, ...)]
graphs, labels = map(list, zip(*samples))
# dgl.batch 将一批图看作是具有许多互不连接的组件构成的大型图
return dgl.batch(graphs), torch.tensor(labels, dtype=torch.long)
# 创建训练集和测试集
trainset = MiniGCDataset(2000, 10, 20) # 生成2000个图,每个图的最小节点数>=10, 最大节点数<=20
testset = MiniGCDataset(1000, 10, 20)
# 用pytorch的DataLoader和之前定义的collect函数
data_loader = DataLoader(trainset, batch_size=64, shuffle=True,
collate_fn=collate)
DEVICE = torch.device("cuda:2")
# 构造模型
model = Classifier(1, 256, trainset.num_classes)
model.to(DEVICE)
# 定义分类交叉熵损失
loss_func = nn.CrossEntropyLoss()
# 定义Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 模型训练
model.train()
epoch_losses = []
for epoch in range(100):
epoch_loss = 0
for iter, (batchg, label) in enumerate(data_loader):
batchg, label = batchg.to(DEVICE), label.to(DEVICE)
prediction = model(batchg)
loss = loss_func(prediction, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.detach().item()
epoch_loss /= (iter + 1)
print('Epoch {}, loss {:.4f}'.format(epoch, epoch_loss))
epoch_losses.append(epoch_loss)
# 测试
test_loader = DataLoader(testset, batch_size=64, shuffle=False,
collate_fn=collate)
model.eval()
test_pred, test_label = [], []
with torch.no_grad():
for it, (batchg, label) in enumerate(test_loader):
batchg, label = batchg.to(DEVICE), label.to(DEVICE)
pred = torch.softmax(model(batchg), 1)
pred = torch.max(pred, 1)[1].view(-1)
test_pred += pred.detach().cpu().numpy().tolist()
test_label += label.cpu().numpy().tolist()
print("Test accuracy: ", accuracy_score(test_label, test_pred))
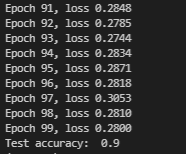
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号