【论文笔记】2015 Skeleton Based Action Recognition with Convolutional Neural Network
任务
action recognition
基本流程
把一个骨架视频中节点的各个坐标变成一幅图像,对图像用卷积和池化训练,如下图,图像的每一列表示一帧中各节点的坐标,不同列表示不同帧的信息。
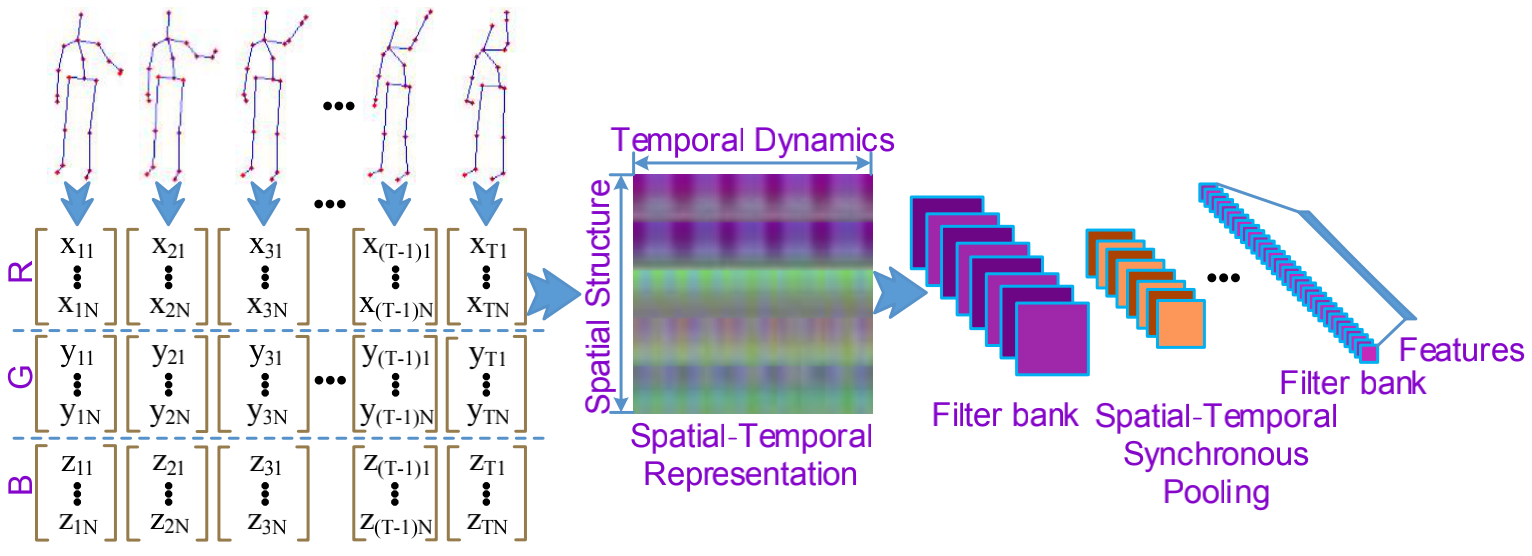
创新点及为什么work
创新点:
- 把时序骨架节点坐标表示成图像,把时序动态特性转换为空间结构
- 提出用这些特殊的图像训练一个CNN模型,也就是提出用CNN模型来做骨架动作识别。并且提出用max-pooling来扮演空间-时间同步池化的角色,以克服动作频率变化的问题。
为什么work:
- CNN的各个filter可以提取不同的特征...
- max-pooling可以克服动作频率变化的问题
其实我觉得作者并没有讲清楚为什么创新点work,只是似是而非地提了一下,然后用实验结果证明了一下。很多深度神经网络论文都有这问题。
数据集
Berkeley MHAD
ChaLearn Gesture Recognition Dataset

 浙公网安备 33010602011771号
浙公网安备 33010602011771号