混淆矩阵,准确率,召回率,F-score,PR曲线,ROC曲线,AUC
本文的部分内容摘自韩家炜《数据挖掘》
----------------------------------------------------------------------------------
四个术语

混淆矩阵(Confusion Matrix)
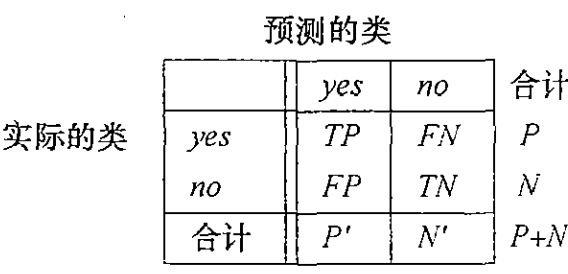
评估度量
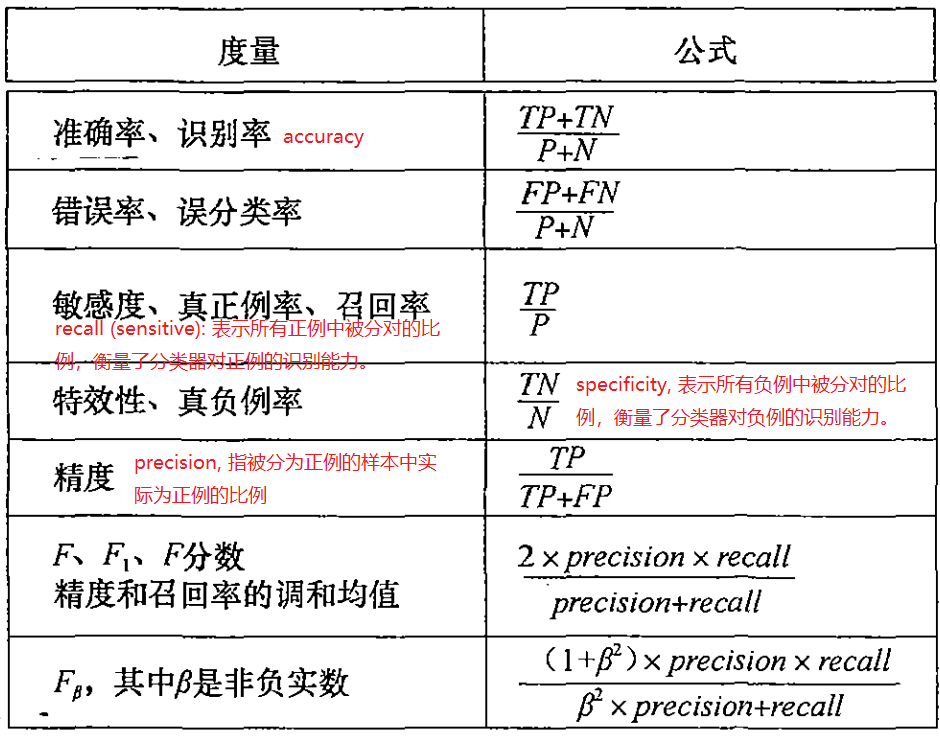
还有一个术语:负正类率(false positive rate, FPR),也叫做打扰率计算公式为:FPR=FP/(FP+TN)=FP/N。负正类率计算的是分类器错认为正类的负实例占所有负实例的比例

F1分数兼顾考虑了召回率recall和精度precision。例如,假设我们有两个分类模型,第一个模型的结果是precision=0.9,recall=0.1,那么F1=0.18;第二个模型的结果是precision=0.5,recall=0.5,那么F1=0.5。显然,F1分数认为第二个模型更好。
召回率(recall)的理解和记忆方法:假设丰田公司有一批汽车投放到了美国市场,后来发现其中有一部分有问题,现在要召回,召回率=召回的汽车中有问题的汽车数量 / 投放到美国市场的这批汽车中有问题的汽车总数,也就是说召回率的关注焦点在有问题的汽车数量,用召回来了的有问题的汽车数目除以总的有问题的汽车数目。
分类准确率(Accuracy),不管是哪个类别,只要预测正确,其数量都放在分子上,而分母是全部数据数量,这说明正确率是对全部数据的判断。
分类精度(precision)在分类中对应的是某个类别,分子是预测该类别正确的数量,分母是预测为该类别的全部数据的数量。或者说,Accuracy是对分类器整体上的正确率的评价,而Precision是分类器预测为某一个类别的正确率的评价。
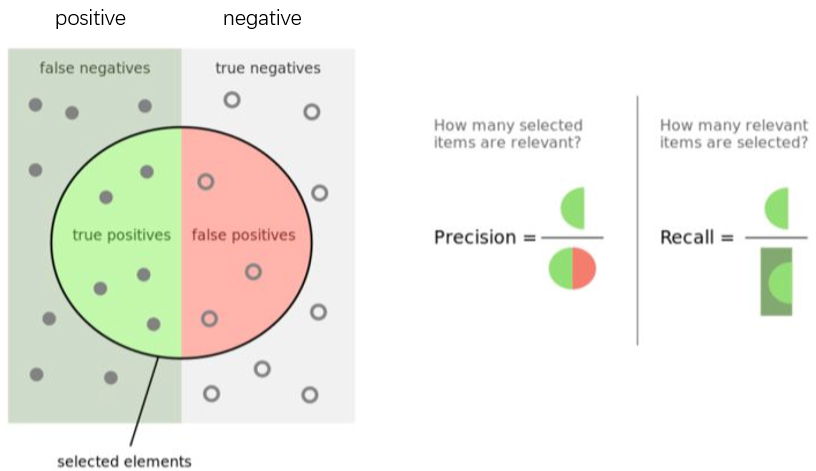
召回率和精度的理解示意图:
假设要从一堆西瓜里面把坏了的西瓜检测出了,positive是指坏了的西瓜,negative是指好的西瓜。
ROC和AUC
ROC是受试者工作特征曲线 receiver operating characteristic curve ) 的简写,又称为感受性曲线(sensitivity curve)。得此名的原因在于曲线上各点反映着相同的感受性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。ROC是反映召回率和打扰率连续变量的综合指标,是用构图法揭示召回率和打扰率的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列召回率和打扰率,再以召回率为纵坐标、打扰率为横坐标绘制成曲线。
AUC是ROC曲线下面积(Area Under Curve)的简称,顾名思义,AUC的值就是处于曲线下方的那部分面积的大小。通常,AUC的值介于0到1.0之间,随机猜测的ROC曲线的AUC值为0.5(例子可参考这篇博客)。
分类模型输出的是某个类别的概率值。设定一个阈值,当概率值大于该阈值时,认为样本属于该类,当概率值小于该阈值时,认为样本不属于该类,然后可以算出该阈值下的(召回率,打扰率)。设定不同的阈值,可以得到不同的(召回率,打扰率)。

PR曲线
precision recall curve, 简称PR曲线。

RO曲线和PR曲线的比较
本节内容摘自ROC曲线 vs Precision-Recall曲线 - hedgehog小子 - 博客园 (cnblogs.com)



对于ROC曲线和PR曲线各自的优点,总结一下就是:
- 对于正负样本大致均匀的时候,ROC曲线作为性能指标更为鲁棒。当正负样本的数目发生相对变化时,ROC曲线能够相对好地保持原貌,但是PR曲线会剧烈变化,因为ROC曲线的FPR和TPR都只与真实的正样本或负样本中的一个相关,而PR曲线的precision与正样本和负样本都有关。
- 当样本分布不平衡时,PR曲线更能反映分类的真实性能。比如负样本远远大于正样本时,ROC曲线可能会显示模型的性能依然不错,但实际上是因为负样本数目远远大于正样本数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号