Python手动实现kmeans聚类和调用sklearn实现
1. 算法步骤
- 随机选取k个样本点充当k个簇的中心点;
- 计算所有样本点与各个簇中心之间的距离,然后把样本点划入最近的簇中;
- 根据簇中已有的样本点,重新计算簇中心;
- 重复步骤2和3,直到簇中心不再改变或改变很小。
2. 手动Python实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
n_data = 400
n_cluster = 4
# generate training data
X, y = make_blobs(n_samples=n_data, centers=n_cluster, cluster_std=0.60, random_state=0)
# generate centers of clusters
centers = np.random.rand(4, 2)*5
EPOCH = 10
tol = 1e-5
for epoch in range(EPOCH):
labels = np.zeros(n_data, dtype=np.int)
# 计算每个点到簇中心的距离并分配label
for i in range(n_data):
distance = np.sum(np.square(X[i]-centers), axis=1)
label = np.argmin(distance)
labels[i] = label
# 重新计算簇中心
for i in range(n_cluster):
indices = np.where(labels == i)[0] # 找出第i簇的样本点的下标
points = X[indices]
centers[i, :] = np.mean(points, axis=0) # 更新第i簇的簇中心
plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis')
plt.show()
运行结果:(注:当簇中心初始化不好时,可能计算会有点错误)
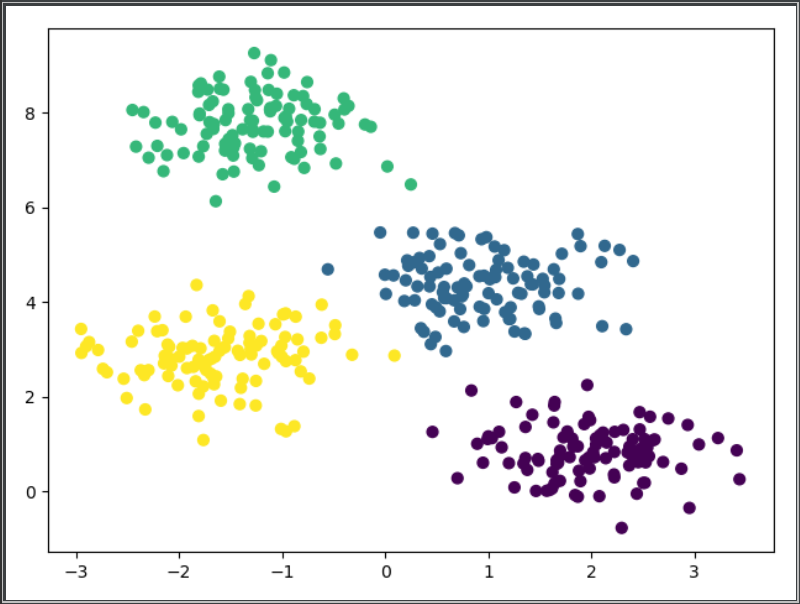
3. 调用sklearn实现kmeans
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets.samples_generator import make_blobs # Generate some data X, y = make_blobs(n_samples=400, centers=4, cluster_std=0.60, random_state=0) # kmeans clustering kmeans = KMeans(4, random_state=0) kmeans.fit(X) # 训练模型 labels = kmeans.predict(X) # 预测分类 plt.scatter(X[:, 0], X[:, 1], c=labels, s=40, cmap='viridis') plt.show()
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号