PyTorch中Dataset, DataLoader, Sampler的关系
PyTorch中Dataset, DataLoader, Sampler的关系可用下图概括:
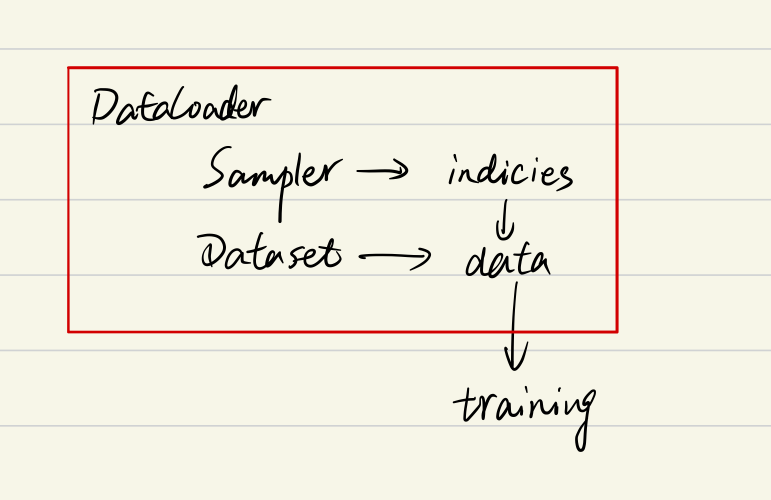
用文字表达就是:Dataloader中包含Sampler和Dataset,Sampler产生索引,Dataset拿着这个索引在数据集文件夹中找到对应的样本(每个样本对应一个索引,就像列表中每个元素对应一个索引),并给该样本配上标签,最后返回(样本+标签)给调用方。
在enumerate过程中,Dataloader按照其参数BatchSampler规定的策略调用其Dataset的getitem方法batchsize次,得到一个batch,该batch中既包含样本,也包含相应的标签。
更详细的分析可参考以下资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号