用PCA对鸢尾花数据集降维并可视化
上篇博客中,我们介绍了并用代码实现了PCA算法,本篇博客我们应用PCA算法对鸢尾花数据集降维,并可视化。
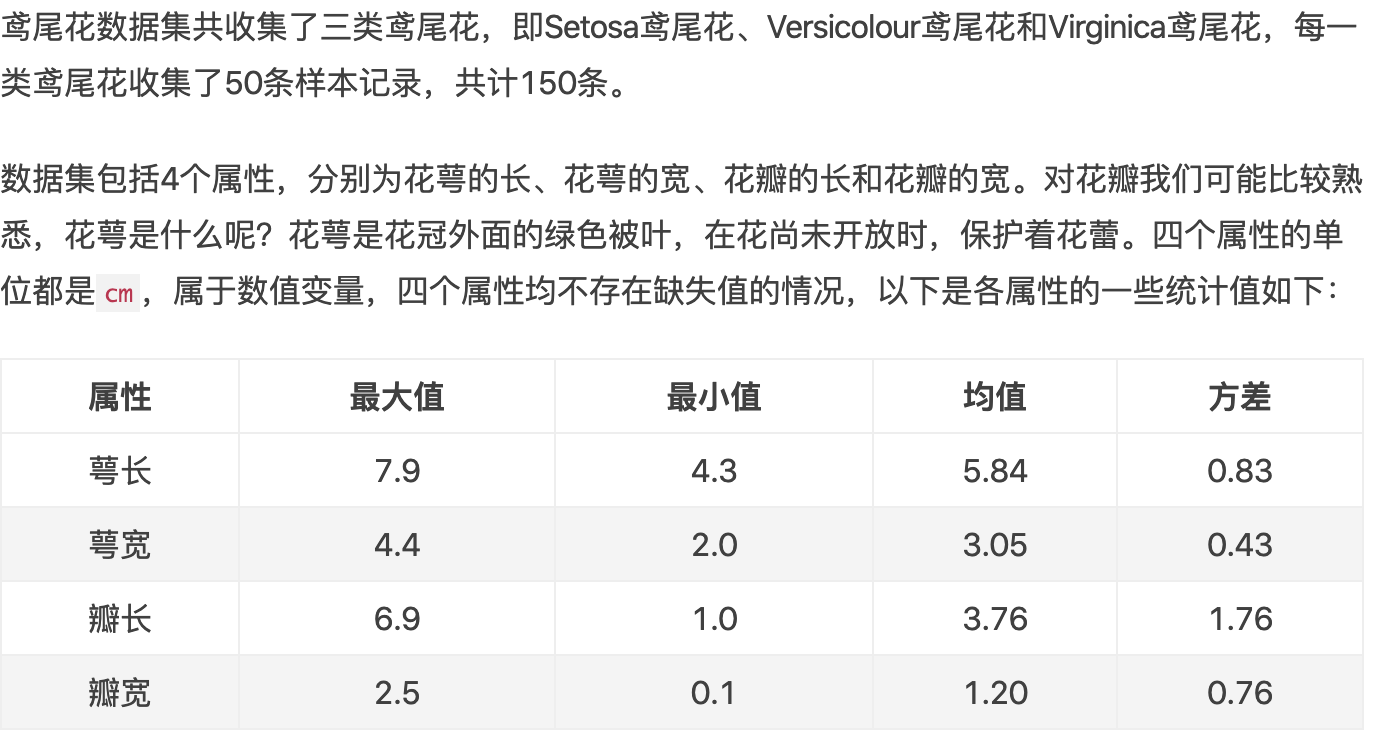
鸢尾花数据集简介
代码实现
代码来自MOOC网的《Python机器学习应用》课程。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data = load_iris() # 以字典形式加载鸢尾花数据集
y = data.target # 使用y表示数据集中的标签
X = data.data # 使用X表示数据集中的属性数据
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_X = pca.fit_transform(X) # 对原始数据进行降维,保存在reduced_X中
red_x, red_y = [], [] # 第一类数据点
blue_x, blue_y = [], [] # 第二类数据点
green_x, green_y = [], [] # 第三类数据点
for i in range(len(reduced_X)): # 按照鸢尾花的类别将降维后的数据点保存在不同的列表中。
if y[i] == 0:
red_x.append(reduced_X[i][0])
red_y.append(reduced_X[i][1])
elif y[i] == 1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
else:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(blue_x, blue_y, c='b', marker='D')
plt.scatter(green_x, green_y, c='g', marker='.')
plt.show()
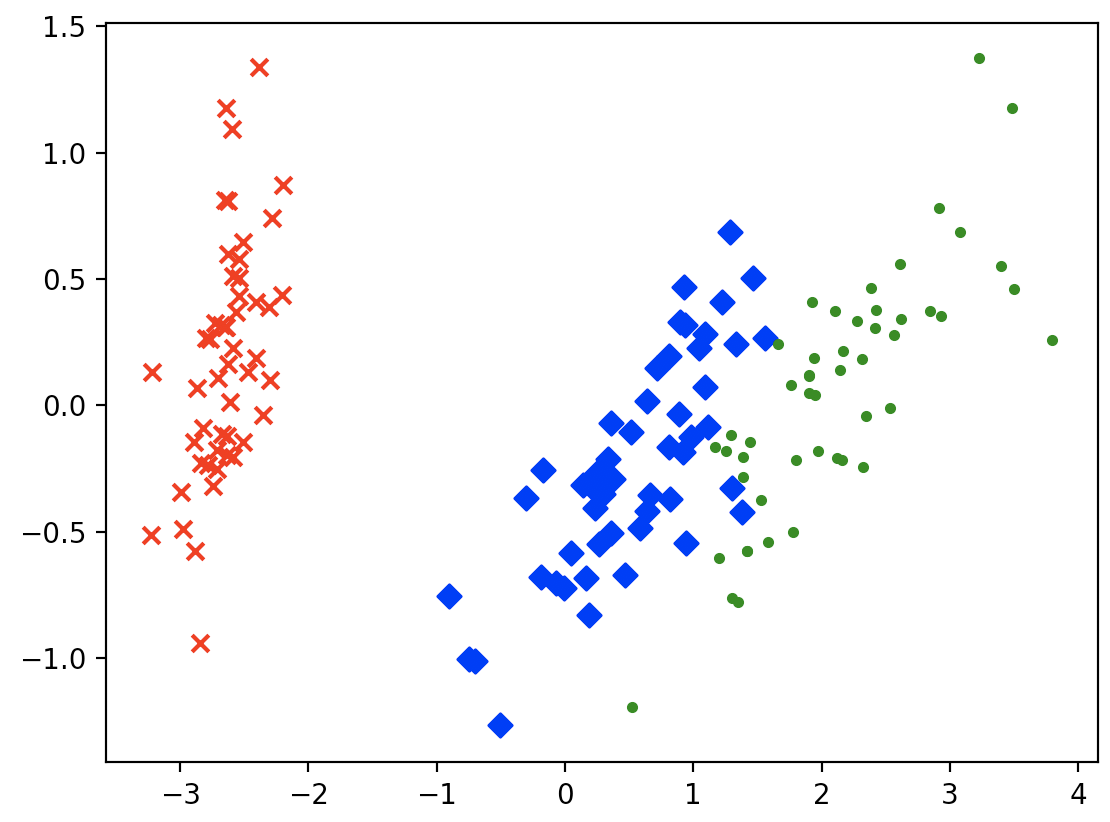
运行结果:
参考资料
[1] 鸢尾花数据集

 浙公网安备 33010602011771号
浙公网安备 33010602011771号