re库和正则表达式
1. 什么是正则表达式
正则表达式是用来简洁表达一组字符串的表达式,常用于检查文本中是否含有指定的特征词、找出文中匹配特征词的位置、从文本中提取信息。Python中的re库是用来实现正则表达式操作的,并且该库采用raw string来表达正则表达式。
1.1. re.findall()将符合规则的字符串以列表形式返回
import re s = 'python123pythonpython' r = re.findall(r'python', s) print(r) # ['python', 'python', 'python']
2. 元字符、分组、贪婪模式和懒惰模式
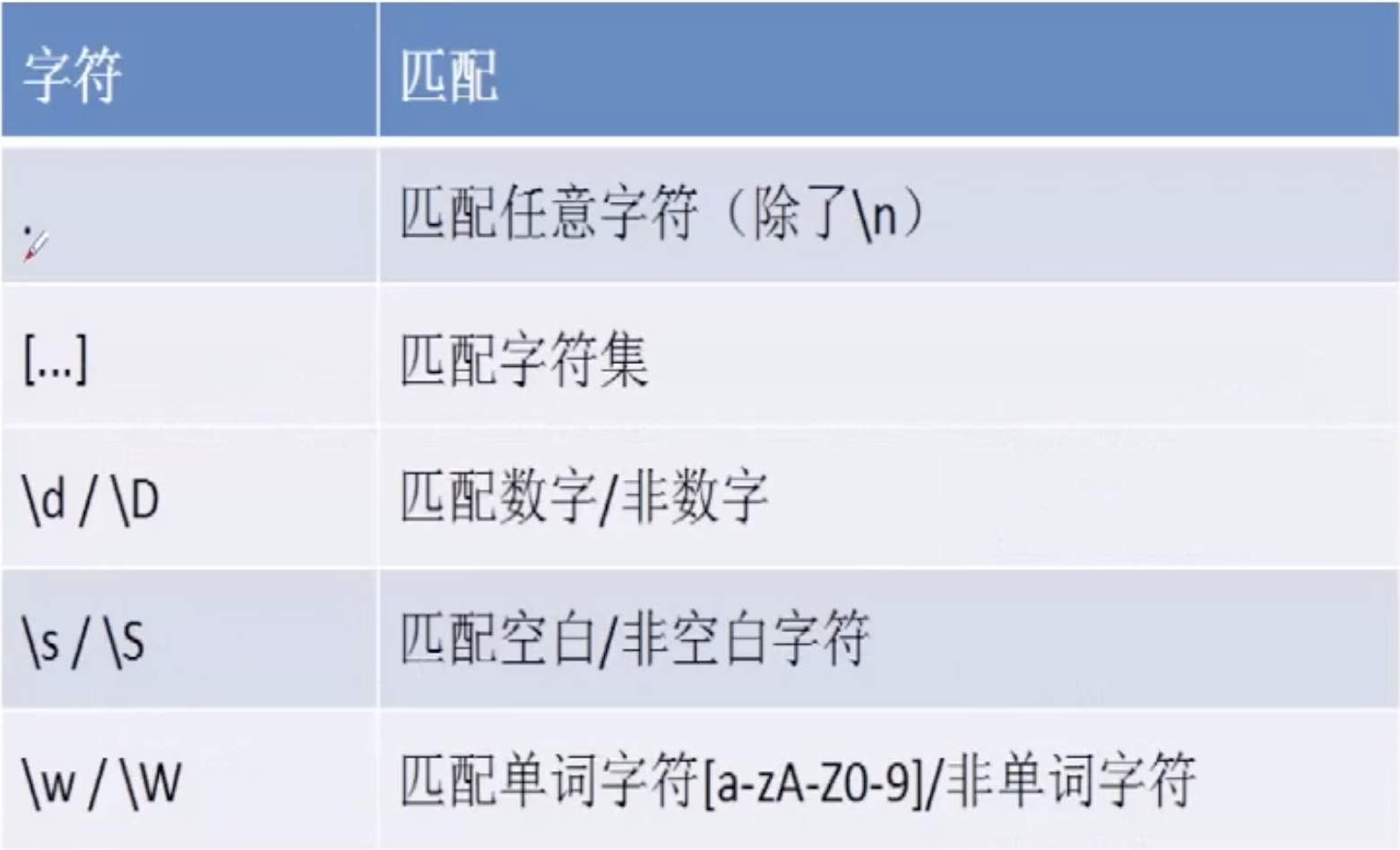
2.1. 通配符. 除\n
s1 = 'python123' s2 = 'python123\n' s3 = 'python123\r' r1 = re.findall(r'.', s1) print(r1) # ['p', 'y', 't', 'h', 'o', 'n', '1', '2', '3'] r2 = re.findall(r'.', s2) print(r2) # ['p', 'y', 't', 'h', 'o', 'n', '1', '2', '3'] r3 = re.findall(r'.', s3) print(r3) # ['p', 'y', 't', 'h', 'o', 'n', '1', '2', '3', '\r'] r4 = re.findall(r'.', s2, re.S) # 修饰符re.S可以使.匹配包括\n在内的所有字符 print(r4) # ['p', 'y', 't', 'h', 'o', 'n', '1', '2', '3', '\n']
2.2. ^ 表示匹配行的开始位置
s = 'love123\nloveyou\npython' r1 = re.findall(r'^love', s) print(r1) # ['love'] r2 = re.findall(r'^love', s, re.M) # 修饰符re.M表示可以匹配多行 print(r2) # ['love', 'love']
2.3. $ 表示匹配行的结束位置
s = 'xxxyyy\nabc\nflyy'
r1 = re.findall(r'yy$', s)
print(r1) # ['yy']
r2 = re.findall(r'yy$', s, re.M)
print('r2:', r2) # ['yy', 'yy']
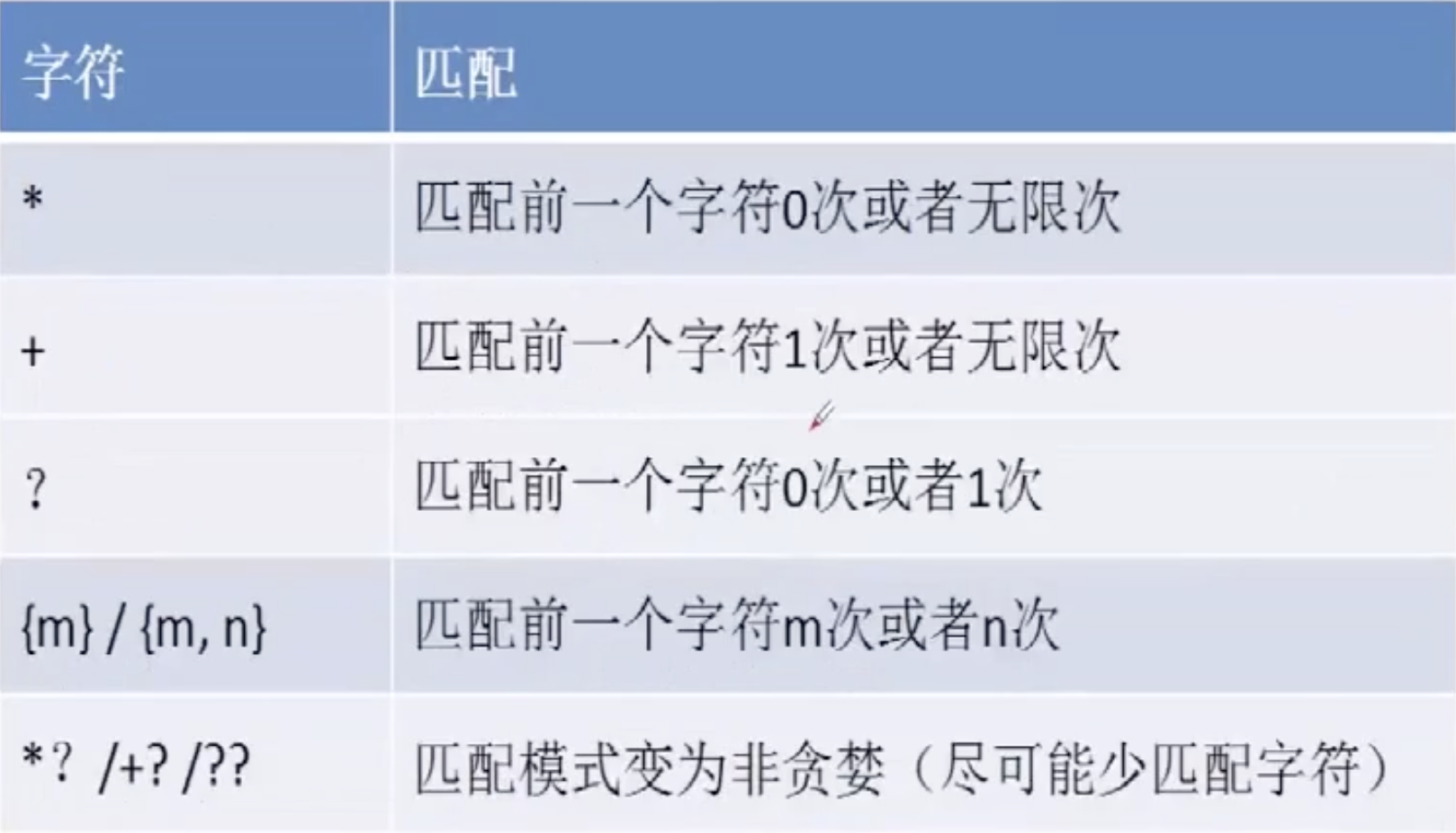
2.4. *+? 匹配前面的表达式次数分别为(0-无穷) (1-无穷) (0-1)
s = 'z\nzo\nzoo' r1 = re.findall(r'zo*', s) # *表示o可以出现(0-无穷)次 print(r1) # ['z', 'zo', 'zoo'] r2 = re.findall(r'zo+', s) # *表示o可以出现(1-无穷)次 print(r2) # ['zo', 'zoo'] r3 = re.findall(r'zo?', s) # *表示o可以出现0或1次。需要注意的是,'zoo'中包含'zo' print(r3) # ['z', 'zo', 'zo']
2.5. {}控制表达式次数
s = 'z\nzo\nzoo'
r = re.findall(r'zo{2}', s) # 表示o出现两次
print(r) # ['zoo']
2.6. [] 控制匹配内容
s = 'test\nTesting\nzoo\nhij' r1 = re.findall(r'[eio]', s) # []表达或的关系,[eio]表示匹配e或i或o print(r1) # ['e', 'e', 'i', 'o', 'o', 'i'] r2 = re.findall(r'[e-o]', s) # 匹配e到o之间的任意字符 print(r2) # ['e', 'e', 'i', 'n', 'g', 'o', 'o', 'h', 'i', 'j'] r3 = re.findall(r'^[e-o]', s, re.M) # 匹配行的开头是否有e到o之间的任意字符,多行匹配 print(r3) # ['h'] r4 = re.findall(r'^[e-o]', s) # 匹配行的开头是否有e到o之间的任意字符,只匹配第一行 print(r4) # [] r5 = re.findall(r'[^e-o]', s) # 这里的^表示'非'。匹配除了e到o之外字符 print(r5) # ['t', 's', 't', '\n', 'T', 's', 't', '\n', 'z', '\n']
2.7. | 表示或
s = 'test\nTesting\nzoo\nhij' r = re.findall(r'e|i|o', s) # |表达或的关系,和[eio]一样,并且[eio]匹配更快 print(r) # ['e', 'e', 'i', 'o', 'o', 'i']
2.8. () 表示分组,主要应用在限制多选结构的范围/分组/捕获文本/环视/特殊模式处理
s1 = 'a3da3ha3' r1 = re.findall(r'(a3)+', s1) # ()里面的为一个组也可以理解成一个整体 print(r1) # ['a3', 'a3', 'a3'] s2 = 'p\npoo\nhoook' r2 = re.findall(r'[p|h]o*', s2) # o前面可以是p或h,o的个数可以是零到无穷多个 print(r2) # ['p', 'poo', 'hooo'] r3 = re.findall(r'[p|h](o*)', s2) # 先匹配'[p|h]o*',在匹配到的所有字符串中再匹配(o*) print(r3) # ['', 'oo', 'ooo'] s3 = 'h and w and t' r4 = re.findall(r' and ', s3) print(r4) # [' and ', ' and '] r5 = re.findall(r' (and) ', s3) # 先匹配' and ',在匹配到的所有字符串中再匹配'and'
print(r5) # ['and', 'and']
分组还可参考这篇博客,讲的比较详细。
需注意的是,()表示捕获分组,()会把每个分组里的匹配的值保存起来,使用\n(n是一个数字,表示第n个捕获组的内容) ,(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来。
# 前瞻: exp1(?=exp2) #后边是exp2就匹配 # 后顾: (?<=exp2)exp1 #前边是exp2就匹配 # 负前瞻: exp1(?!exp2) #后边不是exp2就匹配 # 负后顾: (?<!exp2)exp1 #前边不是exp2就匹配 # 例如 s = '''char *a="hello"; char b='c'; /* this is comment */ int c=1; /* this is multiline comment */''' r = re.findall(r'(?<=/\*).+?(?=\*/)', s, re.M | re.S) # 查找开头是/*结尾是*/的字符串 print(r) # [' this is comment ', ' this is multiline comment ']
下面举5个例子:
1、(abc|bcd|cde),表示这一段是abc、bcd、cde三者之一,顺序也必须一致
2、(abc)? 表示这一组要么一起出现,要么不出现,出现那则按顺序出现
3、(?:abc)表示找到一样abc的一组,但是不记录,不保存到变量中,否则可以通过变量中,否则可以通过x取第几个括号所匹配道德项,比如:
(aaa)(bbb)(ccc)(?:ddd)(eee)可以用1获取(𝑎𝑎𝑎)匹配到的内容,而1获取(aaa)匹配到的内容,而3则获取到了(ccc)匹配到的内容,而\4则获取的是由(eee)匹配到的内容,因为前一对括号没有保存变量
4、a(?=bbb)表示a后面必须紧跟3个连续的b
5、(?i:xxxx)不区分大小写 (?s:.*)跨行匹配,可以匹配回车符
2.9. 取消正则语法
s = 'xyz123.' r1 = re.findall(r'.', s) # 匹配所有字符 print(r1) # ['x', 'y', 'z', '1', '2', '3', '.'] r2 = re.findall(r'\.', s) # 匹配.它自己 print(r2) # ['.']
2.10. 贪婪模式和懒惰模式[5]

2.11. 简单的总结
3. python的re库
3.1. re.match(), re.search(), re.compile()
s = 'alsdkj89239anpa2345s'
r = re.match(r'a', s).group() # match匹配开头,group方法取出匹配到的结果,返回字符或字符串
print(r) # a
r1 = re.search(r'\d+', s).group() # search匹配第一个符合规则的字符串,返回字符或字符串
print(r1) # 89239
r2 = re.findall(r'\d+', s) # findall匹配所有符合规则的字符串,返回列表
print(r2) # ['89239', '2345']
rec = re.compile('\d+') # 根据字符串创建模式对象
r3 = re.findall(rec, s)
print(r3) # ['89239', '2345']
关于re.compile(),还可参考这篇博文。
3.2. re.sub()
r1 = re.sub(r'hello', 'i love the', 'hello world') print(r1) # i love the world r2 = re.sub(r'(\d+)', 'hello', 'my number is 400 and door num is 200') print(r2) # my number is hello and door num is hello r3 = re.sub(r'hello (\w+), nihao \1', r'emma', 'hello sherry, nihao sherry') # \1代表第一个分组的值即sherry print(r3) # emma
3.3. re.split()
s1 = 'aaa bbb ccc;ddd eee,fff' r1 = re.split(r'[;,\s]', s1) print(r1) # ['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff'] s2 = ';;;' r2 = re.split(r';', s2) print(r2) # ['', '', '', '']
参考资料:
[1].【文本分析】正则表达式
[2]. Python基础——正则表达式
[3]. 正则表达式分组
[4]. 史上最详细的正则表达式~你学会了吗? blibli
[5]. 正则表达式30分钟入门教程
[7]. 网络爬虫与信息提取课程第7单元

 浙公网安备 33010602011771号
浙公网安备 33010602011771号