PyTorch实现简单的生成对抗网络GAN
生成对抗网络是一个关于数据的生成模型:即给定训练数据,GANs能够估计数据的概率分布,基于这个概率分布产生数据样本(这些样本可能并没有出现在训练集中)。
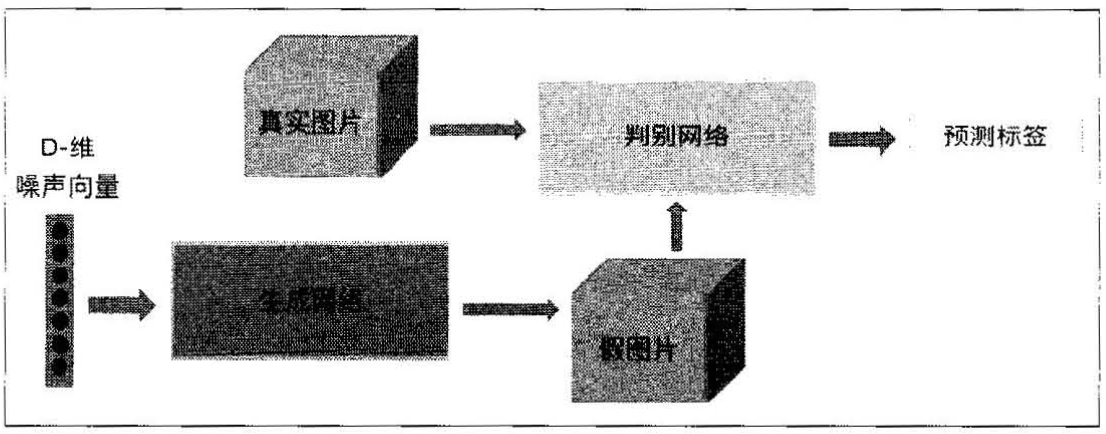
GAN中,两个神经网络互相竞争。给定训练集X,假设是几千张猫的图片。将一个随机向量输入给生成器G(x),让G(x)生成和训练集类似的图片。判别器D(x)是一个二分类器,其试图区分真实的猫图片和生成器生成的假猫图片。总的来说,生成器的目的是学习训练数据的分布,生成尽可能真实的猫图片,以确保判别器无法区分。判别器需要不断地学习生成器的“造假图片”,以防止自己被欺骗。
判别器与生成器不断“斗智斗勇”的过程中,生成器或多或少地学习到了训练数据的真实分布,已经能生成一些以假乱真的图片了;而判别器最终已经无法判断猫的图片是真实的,还是来自于生成器。从某种意义上来说,生成器和判别器都希望对方“失败”。
从另外一个角度来说,判别器实际上是在指导生成器,告诉生成器: 真的猫图片到底什么样?模型训练的最终结果是生成器能够学习到数据的分布,最终可以生成近似真的猫图片。GANs的训练方法类似于博弈论中的MinMax算法,生成器和判别器最终达到了纳什均衡。(摘自https://zhuanlan.zhihu.com/p/74663048)
生成对抗网络(Generative Adversarial Network, GAN)包括生成网络和对抗网络两部分。生成网络像自动编码器的解码器,能够生成数据,比如生成一张图片。对抗网络用来判断数据的真假,比如是真图片还是假图片,真图片是拍摄得到的,假图片是生成网络生成的。
以下程序主要来自廖星宇的《深度学习之PyTorch》的第六章,本文对原代码进行了改进:
import torch
from torch import nn
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
import numpy as np
import matplotlib.pyplot as plt
def preprocess_img(x):
x = tfs.ToTensor()(x) # x (0., 1.)
return (x - 0.5) / 0.5 # x (-1., 1.)
def deprocess_img(x): # x (-1., 1.)
return (x + 1.0) / 2.0 # x (0., 1.)
def discriminator():
net = nn.Sequential(
nn.Linear(784, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
)
return net
def generator(noise_dim):
net = nn.Sequential(
nn.Linear(noise_dim, 1024),
nn.ReLU(True),
nn.Linear(1024, 1024),
nn.ReLU(True),
nn.Linear(1024, 784),
nn.Tanh(),
)
return net
def discriminator_loss(logits_real, logits_fake): # 判别器的loss
size = logits_real.shape[0]
true_labels = torch.ones(size, 1).float()
false_labels = torch.zeros(size, 1).float()
bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(logits_real, true_labels) + bce_loss(logits_fake, false_labels)
return loss
def generator_loss(logits_fake): # 生成器的 loss
size = logits_fake.shape[0]
true_labels = torch.ones(size, 1).float()
bce_loss = nn.BCEWithLogitsLoss()
loss = bce_loss(logits_fake, true_labels) # 假图与真图的误差。训练的目的是减小误差,即让假图接近真图。
return loss
# 使用 adam 来进行训练,beta1 是 0.5, beta2 是 0.999
def get_optimizer(net, LearningRate):
optimizer = torch.optim.Adam(net.parameters(), lr=LearningRate, betas=(0.5, 0.999))
return optimizer
def train_a_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss,
noise_size, num_epochs, num_img):
f, a = plt.subplots(num_img, num_img, figsize=(num_img, num_img))
plt.ion() # Turn the interactive mode on, continuously plot
for epoch in range(num_epochs):
for iteration, (x, _)in enumerate(train_data):
bs = x.shape[0]
# 训练判别网络
real_data = x.view(bs, -1) # 真实数据
logits_real = D_net(real_data) # 判别网络得分
rand_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
fake_images = G_net(rand_noise) # 生成的假的数据
logits_fake = D_net(fake_images) # 判别网络得分
d_total_error = discriminator_loss(logits_real, logits_fake) # 判别器的 loss
D_optimizer.zero_grad()
d_total_error.backward()
D_optimizer.step() # 优化判别网络
# 训练生成网络
rand_noise = (torch.rand(bs, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布
fake_images = G_net(rand_noise) # 生成的假的数据
gen_logits_fake = D_net(fake_images)
g_error = generator_loss(gen_logits_fake) # 生成网络的 loss
G_optimizer.zero_grad()
g_error.backward()
G_optimizer.step() # 优化生成网络
if iteration % 20 == 0:
print('Epoch: {:2d} | Iter: {:<4d} | D: {:.4f} | G:{:.4f}'.format(epoch,
iteration,
d_total_error.data.numpy(),
g_error.data.numpy()))
imgs_numpy = deprocess_img(fake_images.data.cpu().numpy())
for i in range(num_img ** 2):
a[i // num_img][i % num_img].imshow(np.reshape(imgs_numpy[i], (28, 28)), cmap='gray')
a[i // num_img][i % num_img].set_xticks(())
a[i // num_img][i % num_img].set_yticks(())
plt.suptitle('epoch: {} iteration: {}'.format(epoch, iteration))
plt.pause(0.01)
plt.ioff()
plt.show()
if __name__ == '__main__':
EPOCH = 5
BATCH_SIZE = 128
LR = 5e-4
NOISE_DIM = 96
NUM_IMAGE = 4 # for showing images when training
train_set = MNIST(root='/Users/wangpeng/Desktop/all/CS/Courses/Deep Learning/mofan_PyTorch/mnist/',
train=True,
download=False,
transform=preprocess_img)
train_data = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
D = discriminator()
G = generator(NOISE_DIM)
D_optim = get_optimizer(D, LR)
G_optim = get_optimizer(G, LR)
train_a_gan(D, G, D_optim, G_optim, discriminator_loss, generator_loss, NOISE_DIM, EPOCH, NUM_IMAGE)
效果:

程序的理解:
训练Discriminator:

训练Generatord:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号