逻辑回归(Logistic Regression)以及python实现
逻辑回归的原理是用逻辑函数把线性回归的结果(-∞,∞)映射到(0,1),因此本文先介绍线性回归和逻辑函数,然后介绍逻辑回归模型,再介绍如何优化逻辑函数的权重参数,最后用python实现一个简单的逻辑回归模型。
1. 线性回归
线性回归的数学表达式是:
$z = {{\bf{w}}^T}{\bf{x}} = {w_1}{x_1} + {w_2}{x_2} + ... + {w_n}{x_n}$
其中$x_i$是自变量,z是因变量,z的值域为(-∞,∞),$w_i (i=1,2,...,n)$是待求系数,不同的权重$w_i$反映了自变量对因变量不同的贡献程度。这里我省略了$w_0$,因为$w_0$可以看做是$w_0 * 1$,也就是$x_0=1$的情况,所以$w_0$实际上也包含到${{\bf{w}}^T}{\bf{x}}$里面了。
2. 逻辑函数 (logistics函数, sigmoid函数)
Logistic的分布函数的数学表达式是 (逻辑回归- 知乎):
$\sigma (z) = \frac{1}{{1 + {e^{ - (z-\mu)/\gamma}}}}$
sigmoid函数是Logistic的分布函数在$\mu=0, \gamma=1$的特殊形式,也就是
$\sigma (z) = \frac{1}{{1 + {e^{ - z}}}}$ (或者$\sigma (z) = \frac{e^z}{{1 + {e^{ z}}}}$)
在这里我们不做区分,直接把sigmoid函数称为逻辑函数。
sigmoid函数图像:
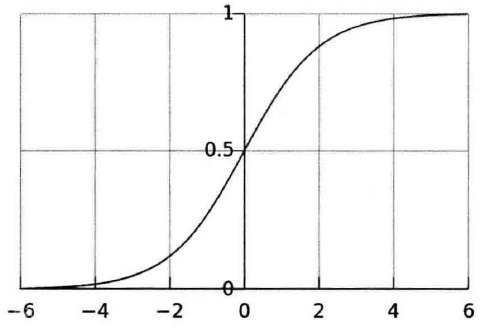
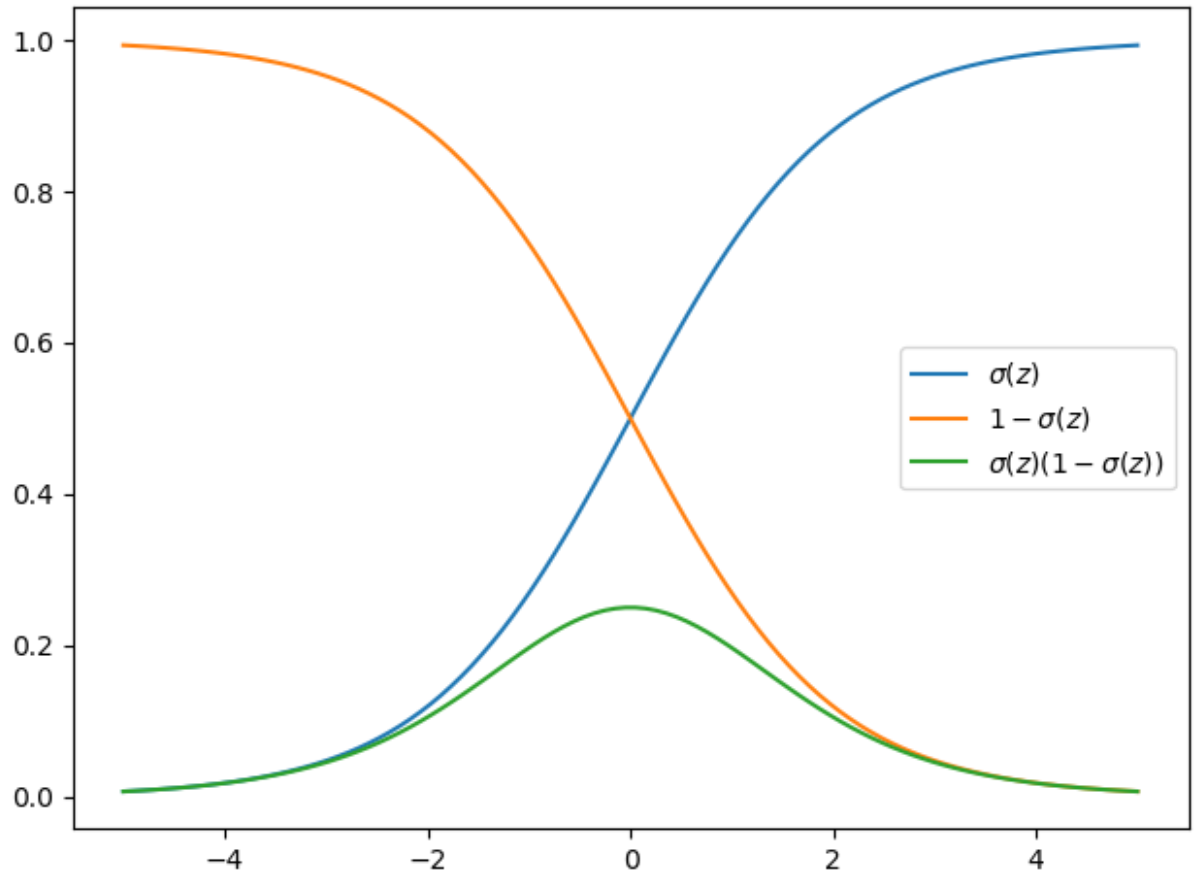
sigmoid函数有个很有用的特征,就是它的导数很容易用它的输出表示,即
$\frac{{\partial \sigma (z)}}{{\partial z}} = \frac{{{e^{ - z}}}}{{{{(1 + {e^{ - z}})}^2}}} = \frac{1}{{1 + {e^{ - z}}}} \cdot \frac{{{e^{ - z}}}}{{1 + {e^{ - z}}}} = \frac{1}{{1 + {e^{ - z}}}} \cdot (1 - \frac{1}{{1 + {e^{ - z}}}}) = \sigma (z)(1 - \sigma (z))\begin{array}{*{20}{c}}
{} & {} & {} & {(1)} \\
\end{array}$
这个结果也可以从下图中看出来,蓝色那条线代表$\sigma(a)$,在x=0时导数最大,当x处于两头时,导数较小。
3. 逻辑回归模型
在逻辑回归模型中,对于二分类问题,该模型定义的条件概率是 (可以认为是该模型的一个假设):
这两个式子可以合并表示:
$p(y|\bf{x}, \bf{w})=p(y=1|\bf{x}, \bf{w})^y p(y=0|\bf{x}, \bf{w})^{1-y}$
或者:
$p(y|\bf{x}, \bf{w})={{{[\sigma ({{\bf{w}}^T}{{\bf{x}}})]}^{{y}}}} {[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}})]^{1 - {y}}}$
一个事件的几率($odds$)是指该事件发生的概率和该事件不发生的概率的比值。如果事件发生的概率是$p$,那么该事件的几率是$\frac{p}{1-p}$,该事件的对数几率($log$ $odds$)或$logit$函数是$logit(p)=ln\frac{p}{1-p}$。在逻辑回归二分类模型中,事件的对数几率是
$\ln \frac{{p(y=1|\bf{x}) }}{{p(y=0|\bf{x}) }}=\ln ({e^{{{\bf{w}}^T}\bf{x}}}) = {{\bf{w}}^T}\bf{x}$
上式表明,在逻辑回归中,对于二分类问题,输出$y=1$的对数几率是输入$\bf{x}$的线性函数。
逻辑回归是线性分类器还是非线性分类器?判断一个模型是线性分类器还是非线性分类器,要根据这个模型的决策边界是否是线性的来判断。对于二分类问题,在决策边界上,模型的输出0类和1类的概率相等,也就是
$\frac{{p(y=1|\bf{x}) }}{{p(y=0|\bf{x}) }}={e^{{{\bf{w}}^T}\bf{x}}}=1 \rightarrow {{\bf{w}}^T}\bf{x}=0$
因此,逻辑回归的决策边界是一个高维平面,因此逻辑回归是线性分类器。
4. 逻辑回归模型的参数优化
在逻辑回归模型中,对于给定的数据集$T = \{ ({{\bf{x}}_1},{y_1}),({{\bf{x}}_2},{y_2}),...,({{\bf{x}}_n},{y_n})\}$,可以应用极大似然的思想得到模型训练目标,根据这个训练目标去优化模型参数${{\bf{w}}^T} = ({w_1},{w_2},...,{w_n})$。
优化目标是最大化所有训练样本出现的联合概率,即:
$\bf{w}^* = argmax_w \prod\limits_{i = 1}^n {{{[\sigma ({{\bf{w}}^T}{{\bf{x}}_i})]}^{{y_i}}}} {[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})]^{1 - {y_i}}}$
我们通常把argmax的问题转化为argmin的问题,即有:
$\bf{w}^* = argmin_w \prod\limits_{i = 1}^n -{{{[\sigma ({{\bf{w}}^T}{{\bf{x}}_i})]}^{{y_i}}}} {[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})]^{1 - {y_i}}}$
记
$G({\bf{w}})=\prod\limits_{i = 1}^n -{{{[\sigma ({{\bf{w}}^T}{{\bf{x}}_i})]}^{{y_i}}}} {[1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})]^{1 - {y_i}}}$
$G({\bf{w}})$的对数似然函数为:
$L({\bf{w}}) = \sum\limits_{i = 1}^n -{[{y_i}\log } \sigma ({{\bf{w}}^T}{{\bf{x}}_i}) + (1 - {y_i})\log (1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i}))]$
对$L({\bf{w}})$取极小值,即对各个参数求偏导:
$\frac{{\partial L({\bf{w}})}}{{\partial{w_j}}} = -\sum\limits_{i = 1}^n {[\frac{{{y_i}}}{{\sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}} - \frac{{1 - {y_i}}}{{1 - \sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}]\frac{{\partial \sigma ({{\bf{w}}^T}{{\bf{x}}_i})}}{{\partial ({{\bf{w}}^T}{{\bf{x}}_i})}}\frac{{\partial ({{\bf{w}}^T}{{\bf{x}}_i})}}{{\partial {w_j}}}$
应用式(1),有
有了梯度之后,我们就可以利用梯度下降法去一步步优化参数$\bf{W}$:
-----------------------------------------------------------------------------------
首先初始化$\bf{W}$;
for t = 1, 2, ......
$\bf{W}^{t+1} = \bf{W}^{t}+\eta·\sum\limits_{i = 1}^n [\sigma ({{\bf{w}}^T}{{\bf{x}}_i})- {y_i}] \cdot {x_{i}}$
-----------------------------------------------------------------------------------
逻辑回归一般用于二分类,对于多分类的情况,常常采用one-vs-all的策略。
【参考文献】
- 逻辑回归的常见面试点总结 (推荐)
- 哔哩哔哩:南开大学李文哲-机器学习基础课程 (视频讲解的很好,推荐)
- 逻辑回归(logistics regression)原理-让你彻底读懂逻辑回归
- 知乎【机器学习】逻辑回归
- 《机器学习算法原理与编程实践》郑捷,第五章第二节
- Neural Network and Deep Learning,Michael Nielsen,chapter 3
- 《机器学习》Mitshell,第四章
5.Python实现逻辑回归模型
训练数据:总共500个训练样本,链接https://pan.baidu.com/s/1qWugzIzdN9qZUnEw4kWcww,提取码:ncuj
代码如下:
import numpy as np
import matplotlib.pyplot as plt
class Logister():
def __init__(self, path):
self.path = path
def file2matrix(self, delimiter):
fp = open(self.path, 'r')
content = fp.read() # content现在是一行字符串,该字符串包含文件所有内容
fp.close()
rowlist = content.splitlines() # 按行转换为一维表
# 逐行遍历
# 结果按分隔符分割为行向量
recordlist = [list(map(float, row.split(delimiter))) for row in rowlist if row.strip()]
return np.mat(recordlist)
def drawScatterbyLabel(self, dataSet):
m, n = dataSet.shape
target = np.array(dataSet[:, -1])
target = target.squeeze() # 把二维数据变为一维数据
for i in range(m):
if target[i] == 0:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='blue', marker='o')
if target[i] == 1:
plt.scatter(dataSet[i, 0], dataSet[i, 1], c='red', marker='o')
def buildMat(self, dataSet):
m, n = dataSet.shape
dataMat = np.zeros((m, n))
dataMat[:, 0] = 1
dataMat[:, 1:] = dataSet[:, :-1]
return dataMat
def logistic(self, wTx):
return 1.0/(1.0 + np.exp(-wTx))
def classfier(self, testData, weights):
prob = self.logistic(sum(testData*weights)) # 求取概率--判别算法
if prob > 0.5:
return 1
else:
return 0
if __name__ == '__main__':
logis = Logister('testSet.txt')
print('1. 导入数据')
inputData = logis.file2matrix('\t')
target = inputData[:, -1]
m, n = inputData.shape
print('size of input data: {} * {}'.format(m, n))
print('2. 按分类绘制散点图')
logis.drawScatterbyLabel(inputData)
print('3. 构建系数矩阵')
dataMat = logis.buildMat(inputData)
alpha = 0.1 # learning rate
steps = 600 # total iterations
weights = np.ones((n, 1)) # initialize weights
weightlist = []
print('4. 训练模型')
for k in range(steps):
output = logis.logistic(dataMat * np.mat(weights))
errors = target - output
print('iteration: {} error_norm: {}'.format(k, np.linalg.norm(errors)))
weights = weights + alpha*dataMat.T*errors # 梯度下降
weightlist.append(weights)
print('5. 画出训练过程')
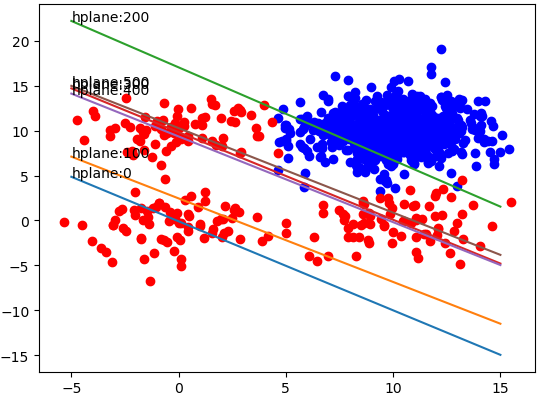
X = np.linspace(-5, 15, 301)
weights = np.array(weights)
length = len(weightlist)
for idx in range(length):
if idx % 100 == 0:
weight = np.array(weightlist[idx])
Y = -(weight[0] + X * weight[1]) / weight[2]
plt.plot(X, Y)
plt.annotate('hplane:' + str(idx), xy=(X[0], Y[0]))
plt.show()
print('6. 应用模型到测试数据中')
testdata = np.mat([-0.147324, 2.874846]) # 测试数据
m, n = testdata.shape
testmat = np.zeros((m, n+1))
testmat[:, 0] = 1
testmat[:, 1:] = testdata
print(logis.classfier(testmat, np.mat(weights))) # weights为前面训练得出的
训练600个iterations,每100个iterations输出一次训练结果,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号