期望,方差,协方差,相关系数,协方差矩阵,相关系数矩阵,以及numpy实现
1. 期望

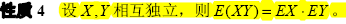
2. 方差
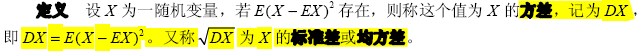


3. 协方差和相关系数
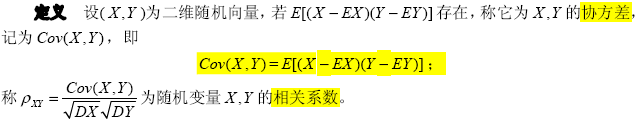
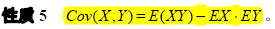
协方差(或者相关系数)如果是正的,表明X和Y之间同时增加或减小;如果是负的,表明X和Y之间有一个增加而另一个减小;如果它的值为0,则表明X和Y之间是独立的。
4. 协方差矩阵
在机器学习中,计算两个特征X、Y(都是向量)的协方差公式为
![]() 式中n表示n个样本。两个特征X、Y之间的协方差矩阵为
式中n表示n个样本。两个特征X、Y之间的协方差矩阵为
![]()
如果有多个特征(特征1, 特征2, 特征3,...,特征N),它们的协方差矩阵:

下面以两个特征为例计算协方差矩阵:
import numpy as np
m = 8 # 8个样本
n = 2 # 2个特征
featuremat = np.random.randint(1, 100, [m, n])
mean0 = np.mean(featuremat[:, 0]) # 求第一个特征列的均值,用于数据中心化
mean1 = np.mean(featuremat[:, 1]) # 求第二个特征列的均值,用于数据中心化
cov = np.sum((featuremat[:, 0] - mean0) * (featuremat[:, 1] - mean1))/(m-1)
print('cov: ', cov)
print('cov matrix: ')
print(np.cov(featuremat.T)) # 计算特征列之间的协方差矩阵
运行结果:
cov: 316.0357142857143 cov matrix: [[646.26785714 316.03571429] [316.03571429 883.92857143]]
在样本数据矩阵X(注意上文中我用X表示一个特征,这里我用X表示整个样本数据矩阵)中,如果数据是按行排列的,即一行是一个样本,一列是一个特征,那么协方差矩阵计算公式为
![]()
如果数据是按列排列的,即一列是一个样本,一行是一个特征,那么协方差矩阵计算公式为
![]()
在机器学习中,理解协方差矩阵的关键在于牢记它计算的是同一个样本不同特征维度之间的协方差,而不是不同样本之间。拿到样本矩阵之后,我们首先要明确一行是样本还是特征维度。下图可帮助理解:

此外,在统计学与概率论中,协方差矩阵的计算好像有所不同(存疑),其每个元素是各个向量元素之间的协方差,这是从标量随机变量到高维度随机向量的自然推广:

5.相关系数矩阵
相关系数矩阵的计算原理和协方差矩阵的差不多,只不过前者计算的是相关系数,后者计算的是协方差,而相关系数和协方差的关系,在前面的第3小节介绍过了。下面用python-numpy实现一个简单的求相关系数矩阵的例子,例子中一行表示一个样本,一列表示一个特征:
import numpy as np
featuremat = np.random.rand(8, 2) # 8个样本,2个特征
# compute mean
mean0 = np.mean(featuremat[:, 0]) # 求第一个特征列的均值
mean1 = np.mean(featuremat[:, 1]) # 求第二个特征列的均值
# comupte standard deviation
std0 = np.std(featuremat[:, 0])
std1 = np.std(featuremat[:, 1])
corref = np.mean((featuremat[:, 0]-mean0)*(featuremat[:, 1]-mean1)) / (std0*std1)
print('corref: ', corref)
print('corref matrix: ')
print(np.corrcoef(featuremat.T)) # 计算特征之间的相关系数矩阵
运行结果:
corref: -0.11352065914068718 corref matrix: [[ 1. -0.11352066] [-0.11352066 1. ]]
参考文献
[1] 概率论与数理统计,黄清龙等,北京大学出版社
[2]《机器学习算法原理与编程实践》郑捷,第一章第三节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号