

mmocr 训练自己的数据集
电脑配置 我这边是windows 10,显卡
NVIDIA GeForce GTX 1660 Ti 6G
1、拉取源代码
https://github.com/open-mmlab/mmocr.git
我这边拉的是master
2、环境配置
最好采用全新的环境
安装 组件如果慢的话,可以 指定国内源
国内常见包源清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
在指定命令 后 加 "-i 地址"
conda create --name openmmlab python=3.8 -y
切换到环境 conda activate openmmlab
安装pytorch
conda install pytorch torchvision -c pytorch
安装mmcv-full, 不要安装mmcv 这个里面不全
mim install mmcv-full -i https://pypi.tuna.tsinghua.edu.cn/simple
安装分割插件
pip install mmdet
具体可以参考官方文档:
https://mmocr.readthedocs.io/zh_CN/latest/install.html#id3
3、代码配置
先配置一个你要训练的模型生成配置代码,我这边用的是abinet (configs/textrecog/abinet/abinet_academic.py)这个模型:

在 tools/work_dirs/abinet_vision_only_academic/abinet_vision_only_academic.py 下生成了完整的配置文件(为了方便调整,原始文件是多个文件分块写的),把abinet_vision_only_academic.py 改一下名字放到
configs/textrecog/abinet/ 文件夹下,我这名字是 my_abinet_vision_only_academic.py

修改配置 为
my_abinet_vision_only_academic.py
准备数据集,我这采用公用数据集:
icdar_2015 下载地址:https://rrc.cvc.uab.es/?ch=4&com=downloads
也可以在百度网盘下载:
链接:https://pan.baidu.com/s/1et-BtES7FbvK-Z4wtkLuvw
提取码:kshx
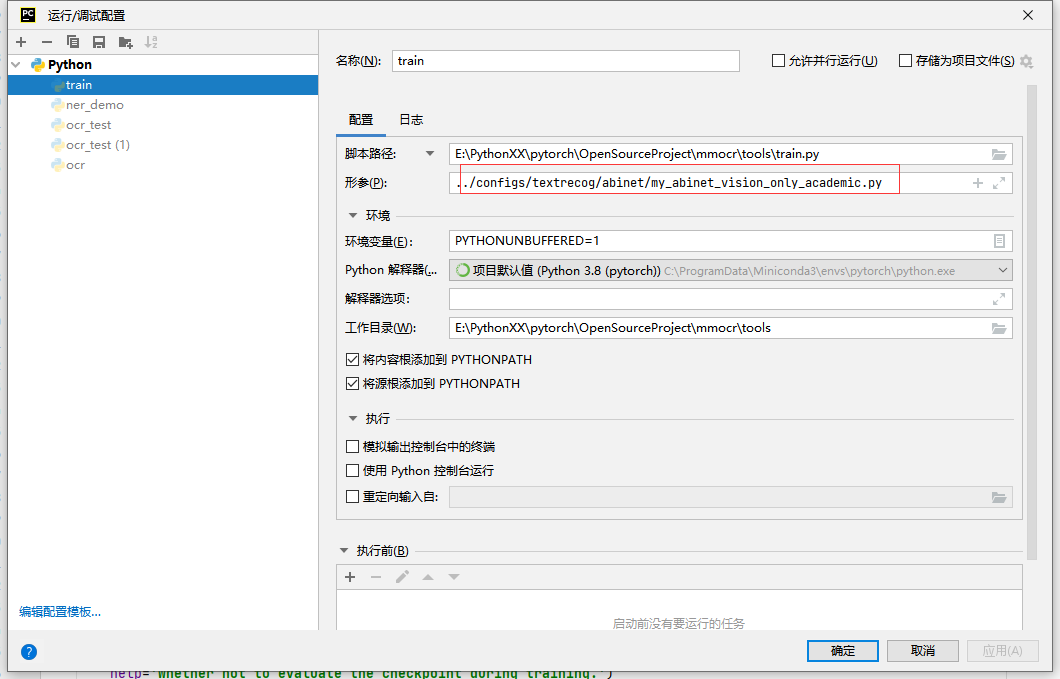
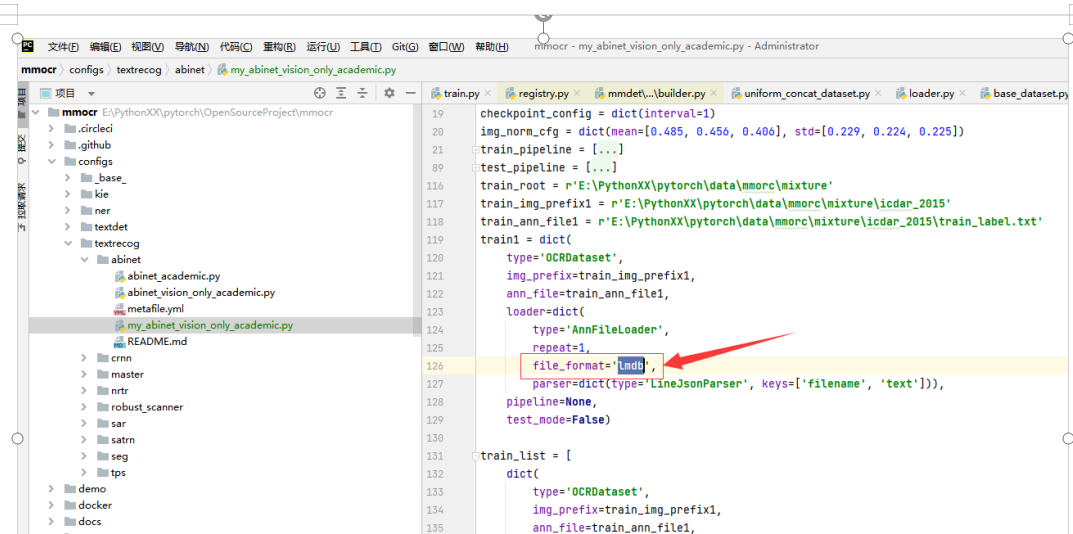
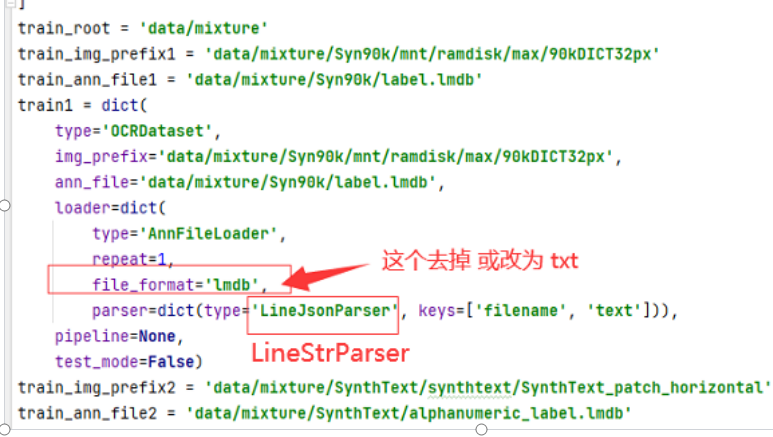
修改配置文件:my_abinet_vision_only_academic.py
我这直接上代码吧 注意点我标红了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 | # 多少打印日志log_config = dict(interval=30, hooks=[dict(type='TextLoggerHook')])dist_params = dict(backend='nccl')log_level = 'INFO'load_from = Noneresume_from = Noneworkflow = [('train', 1)]opencv_num_threads = 0mp_start_method = 'fork'optimizer = dict(type='Adam', lr=0.0001)optimizer_config = dict(grad_clip=None)lr_config = dict( policy='step', step=[16, 18], warmup='linear', warmup_iters=1, warmup_ratio=0.001, warmup_by_epoch=True)runner = dict(type='EpochBasedRunner', max_epochs=20)checkpoint_config = dict(interval=1)img_norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])train_pipeline = [ dict(type='LoadImageFromFile'), dict( type='ResizeOCR', height=32, min_width=128, max_width=128, keep_aspect_ratio=False, width_downsample_ratio=0.25), dict( type='RandomWrapper', p=0.5, transforms=[ dict( type='OneOfWrapper', transforms=[ dict(type='RandomRotateTextDet', max_angle=15), dict( type='TorchVisionWrapper', op='RandomAffine', degrees=15, translate=(0.3, 0.3), scale=(0.5, 2.0), shear=(-45, 45)), dict( type='TorchVisionWrapper', op='RandomPerspective', distortion_scale=0.5, p=1) ]) ]), dict( type='RandomWrapper', p=0.25, transforms=[ dict(type='PyramidRescale'), dict( type='Albu', transforms=[ dict(type='GaussNoise', var_limit=(20, 20), p=0.5), dict(type='MotionBlur', blur_limit=6, p=0.5) ]) ]), dict( type='RandomWrapper', p=0.25, transforms=[ dict( type='TorchVisionWrapper', op='ColorJitter', brightness=0.5, saturation=0.5, contrast=0.5, hue=0.1) ]), dict(type='ToTensorOCR'), dict( type='NormalizeOCR', mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), dict( type='Collect', keys=['img'], meta_keys=[ 'filename', 'ori_shape', 'img_shape', 'text', 'valid_ratio', 'resize_shape' ])]test_pipeline = [ dict(type='LoadImageFromFile'), dict( type='MultiRotateAugOCR', rotate_degrees=[0, 90, 270], transforms=[ dict( type='ResizeOCR', height=32, min_width=128, max_width=128, keep_aspect_ratio=False, width_downsample_ratio=0.25), dict(type='ToTensorOCR'), dict( type='NormalizeOCR', mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), dict( type='Collect', keys=['img'], meta_keys=[ 'filename', 'ori_shape', 'img_shape', 'valid_ratio', 'resize_shape', 'img_norm_cfg', 'ori_filename' ]) ])]# 数据集路径 由于我这边只有1个数据集 其他的删除,默认有很多train_root = r'E:\PythonXX\pytorch\data\mmorc\mixture'train_img_prefix1 = r'E:\PythonXX\pytorch\data\mmorc\mixture\icdar_2015'train_ann_file1 = r'E:\PythonXX\pytorch\data\mmorc\mixture\icdar_2015\train_label.txt'train1 = dict( type='OCRDataset', img_prefix=train_img_prefix1, ann_file=train_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, parser=dict(type='LineStrParser', keys=['filename', 'text'])), pipeline=None, test_mode=False)# 这个LineStrParser 默认是 LineJsonParser 因为我这边标签是文本文件# file_format='lmdb' 这个要去掉或者改成“txt” 因为我们不是这个格式 是文本格式标签train_list = [ dict( type='OCRDataset', img_prefix=train_img_prefix1, ann_file=train_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, parser=dict(type='LineStrParser', keys=['filename', 'text'])), pipeline=None, test_mode=False) ]# 测试数据集test_root = r'E:\PythonXX\pytorch\data\mmorc\mixture'test_img_prefix1 = r'E:\PythonXX\pytorch\data\mmorc\mixture\icdar_2015'test_ann_file1 = r'E:\PythonXX\pytorch\data\mmorc\mixture\icdar_2015\test_label.txt'test1 = dict( type='OCRDataset', img_prefix=test_img_prefix1, ann_file=test_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, file_format='txt', parser=dict( type='LineStrParser', keys=['filename', 'text'], keys_idx=[0, 1], separator=' ')), pipeline=None, test_mode=True)test_list = [ dict( type='OCRDataset', img_prefix=test_img_prefix1, ann_file=test_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, file_format='txt', parser=dict( type='LineStrParser', keys=['filename', 'text'], keys_idx=[0, 1], separator=' ')), pipeline=None, test_mode=True)]num_chars = 38 #字符分类数量max_seq_len = 10 #识别字符最大长度label_convertor = dict( type='ABIConvertor', dict_type='DICT36',#识别字符类型 10个数字+26字母 with_unknown=True, #如果报这个错就改 with_padding=False, lower=True)model = dict( type='ABINet', backbone=dict(type='ResNetABI'), encoder=dict( type='ABIVisionModel', encoder=dict( type='TransformerEncoder', n_layers=3, n_head=8, d_model=512, d_inner=2048, dropout=0.1, max_len=256), decoder=dict( type='ABIVisionDecoder', in_channels=512, num_channels=64, attn_height=8, attn_width=32, attn_mode='nearest', use_result='feature', num_chars=num_chars, max_seq_len=max_seq_len, init_cfg=dict(type='Xavier', layer='Conv2d'))), loss=dict( type='ABILoss', enc_weight=1.0, dec_weight=1.0, fusion_weight=1.0, num_classes=num_chars), label_convertor=dict( type='ABIConvertor', dict_type='DICT36', with_unknown=True, with_padding=False, lower=True), max_seq_len=max_seq_len, iter_size=1)data = dict( samples_per_gpu=40, # 批次每一批次训练多少张图片 workers_per_gpu=1, # 几个GUP训练 val_dataloader=dict(samples_per_gpu=1), test_dataloader=dict(samples_per_gpu=1), train=dict( type='UniformConcatDataset', datasets=[ dict( type='OCRDataset', img_prefix=train_img_prefix1, ann_file=train_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, parser=dict( type='LineStrParser', keys=['filename', 'text'])), pipeline=None, test_mode=False) ], pipeline=[ dict(type='LoadImageFromFile'), dict( type='ResizeOCR', height=32, min_width=128, max_width=128, keep_aspect_ratio=False, width_downsample_ratio=0.25), dict( type='RandomWrapper', p=0.5, transforms=[ dict( type='OneOfWrapper', transforms=[ dict(type='RandomRotateTextDet', max_angle=15), dict( type='TorchVisionWrapper', op='RandomAffine', degrees=15, translate=(0.3, 0.3), scale=(0.5, 2.0), shear=(-45, 45)), dict( type='TorchVisionWrapper', op='RandomPerspective', distortion_scale=0.5, p=1) ]) ]), dict( type='RandomWrapper', p=0.25, transforms=[ dict(type='PyramidRescale'), dict( type='Albu', transforms=[ dict(type='GaussNoise', var_limit=(20, 20), p=0.5), dict(type='MotionBlur', blur_limit=6, p=0.5) ]) ]), dict( type='RandomWrapper', p=0.25, transforms=[ dict( type='TorchVisionWrapper', op='ColorJitter', brightness=0.5, saturation=0.5, contrast=0.5, hue=0.1) ]), dict(type='ToTensorOCR'), dict( type='NormalizeOCR', mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), dict( type='Collect', keys=['img'], meta_keys=[ 'filename', 'ori_shape', 'img_shape', 'text', 'valid_ratio', 'resize_shape' ]) ]), val=dict( type='UniformConcatDataset', datasets=[ dict( type='OCRDataset', img_prefix=test_img_prefix1, ann_file=test_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, file_format='txt', parser=dict( type='LineStrParser', keys=['filename', 'text'], keys_idx=[0, 1], separator=' ')), pipeline=None, test_mode=True) ], pipeline=[ dict(type='LoadImageFromFile'), dict( type='MultiRotateAugOCR', rotate_degrees=[0, 90, 270], transforms=[ dict( type='ResizeOCR', height=32, min_width=128, max_width=128, keep_aspect_ratio=False, width_downsample_ratio=0.25), dict(type='ToTensorOCR'), dict( type='NormalizeOCR', mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), dict( type='Collect', keys=['img'], meta_keys=[ 'filename', 'ori_shape', 'img_shape', 'valid_ratio', 'resize_shape', 'img_norm_cfg', 'ori_filename' ]) ]) ]), test=dict( type='UniformConcatDataset', datasets=[ dict( type='OCRDataset', img_prefix=test_img_prefix1, ann_file=test_ann_file1, loader=dict( type='AnnFileLoader', repeat=1, file_format='txt', parser=dict( type='LineStrParser', keys=['filename', 'text'], keys_idx=[0, 1], separator=' ')), pipeline=None, test_mode=True) ], pipeline=[ dict(type='LoadImageFromFile'), dict( type='MultiRotateAugOCR', rotate_degrees=[0, 90, 270], transforms=[ dict( type='ResizeOCR', height=32, min_width=128, max_width=128, keep_aspect_ratio=False, width_downsample_ratio=0.25), dict(type='ToTensorOCR'), dict( type='NormalizeOCR', mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), dict( type='Collect', keys=['img'], meta_keys=[ 'filename', 'ori_shape', 'img_shape', 'valid_ratio', 'resize_shape', 'img_norm_cfg', 'ori_filename' ]) ]) ]))evaluation = dict(interval=1, metric='acc')work_dir = r'./work_dirs/abinet_vision_only_academic'gpu_ids = [0] |
4、常见报错处理
报错:
加载配置文件报错:

During handling of the above exception,another exception occurred:
Traceback (most recent call last):
File "c:\ProqramData\Winiconda\envs\pytorch\lib\site-packages(mcvutils(reqistry.py",line 72,in build.from_cfgraise type(e)(f'iobj_cls. __name__}: ie}')
1no.Envow : Jnifonwtonatiatoaset:0A就nAateset : AnmFileloder: E: ythrnXxX pytorch)datalmorcelmixturelicdarn.2815)train_label.txt:
python-BaseException
解决一个错还其他错
RuntimeError: albumentations is not installed
pip install albumentations -i https://pypi.doubanio.com/simple/
报:
OSError: [WinError 1455] 页面文件太小,无法完成操作。
报:
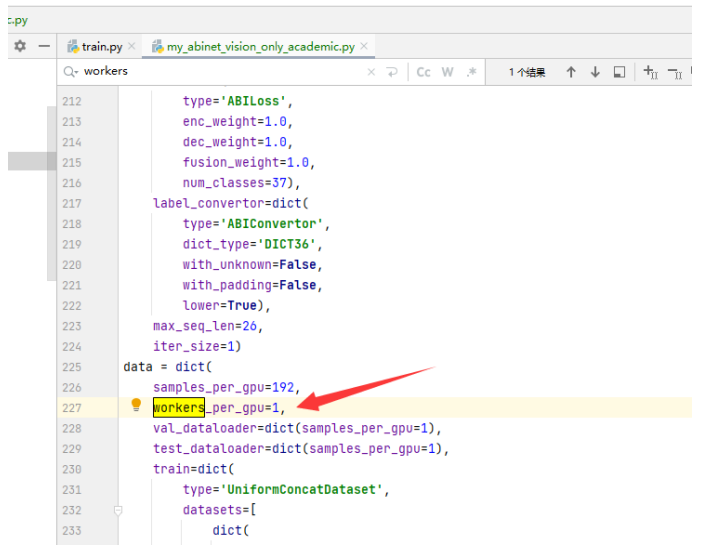
RuntimeError: CUDA out of memory. Tried to allocate 96.00 MiB

报:
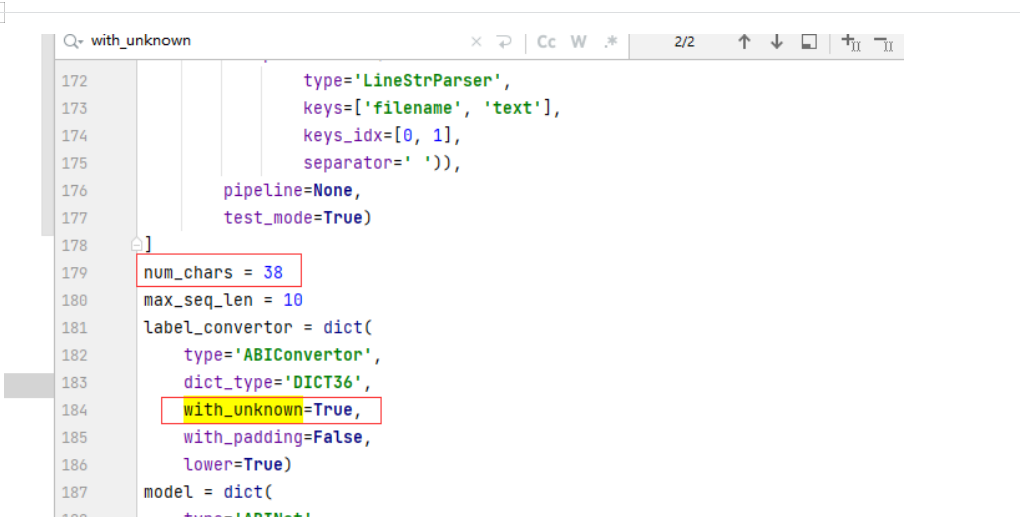
Exception: Chararcter: % not in dict, please check gt_label and use custom dict file, or set "with_unknown=True"


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律