从Java的角度修复文件下载漏洞
从Java的角度谈下文件下载漏洞的产生,然后到他的修复方案。这里我的修复方案是白名单,而没有采用黑名单的方式。
首先先看一段存在文件下载漏洞的代码code:
HTML视图页面 download.html
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Insert title here</title> </head> <body> <h1>使用a标签直接指向服务器上的资源</h1> <a href="/WEB14/download/a.flv">a.flv</a><br> <a href="/WEB14/download/a.jpg">a.jpg</a><br> <a href="/WEB14/download/a.mp3">a.mp3</a><br> <a href="/WEB14/download/a.mp4">a.mp4</a><br> <a href="/WEB14/download/a.txt">a.txt</a><br> <a href="/WEB14/download/a.zip">a.zip</a><br> <h1>使用服务器端编码的方式实现文件下载</h1> <a href="/WEB14/downloadServlet2?filename=a.flv">a.flv</a><br> <a href="/WEB14/downloadServlet2?filename=a.jpg">a.jpg</a><br> <a href="/WEB14/downloadServlet2?filename=a.mp3">a.mp3</a><br> <a href="/WEB14/downloadServlet2?filename=a.mp4">a.mp4</a><br> <a href="/WEB14/downloadServlet2?filename=a.txt">a.txt</a><br> <a href="/WEB14/downloadServlet2?filename=a.zip">a.zip</a><br> <a href="/WEB14/downloadServlet2?filename=美女.jpg">美女.jpg</a><br> </body> </html>
服务器端验证文件下载代码:
downloadServlet2.java代码如下:
package cn.downloadServlet; import java.io.*; import java.io.IOException; import java.net.URLEncoder; import java.util.ArrayList; import java.util.Base64; import javax.servlet.ServletException; import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.xml.ws.RespectBinding; import com.sun.org.apache.xerces.internal.util.SynchronizedSymbolTable; import com.sun.xml.internal.bind.v2.runtime.output.StAXExStreamWriterOutput; import sun.misc.BASE64Encoder; public class DownloadServlet2 extends HttpServlet { public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // 请求filename参数 String filename = request.getParameter("filename"); // System.out.println(filename); // 解决获得中文参数的乱码 filename = new String(filename.getBytes("ISO8859-1"), "UTF-8"); // 获得请求头中的User-Agent String agent = request.getHeader("User-Agent"); // 根据不同浏览器进行不同的编码 String filenameEncoder = ""; if (agent.contains("MSIE")) { // IE浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); filenameEncoder = filenameEncoder.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filenameEncoder = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes("utf-8")) + "?="; } else { // 其它浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); } String requestURI = request.getRequestURI(); System.out.println(requestURI); // 自动判断文件的数据类型 response.setContentType(this.getServletContext().getMimeType(filename)); // 告诉客户端该文件不是直接解析 而是以附件形式打开(下载) response.setHeader("Content-Disposition", "attachment;filename=" + filenameEncoder); //获取请求的文件路径名称 String realPath = this.getServletContext().getRealPath("/download/" + filename); ServletOutputStream outputStream = response.getOutputStream(); FileInputStream fileInputStream = new FileInputStream(realPath); int length = 0; byte[] buff = new byte[1024]; while ((length = fileInputStream.read(buff)) != -1) { outputStream.write(buff, 0, length); } } public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { doGet(request, response); } }
这段代码是是存在漏洞的,这里获取filename参数的时候未进行验证,导致可以任意文件下载。
正常的图片显示:
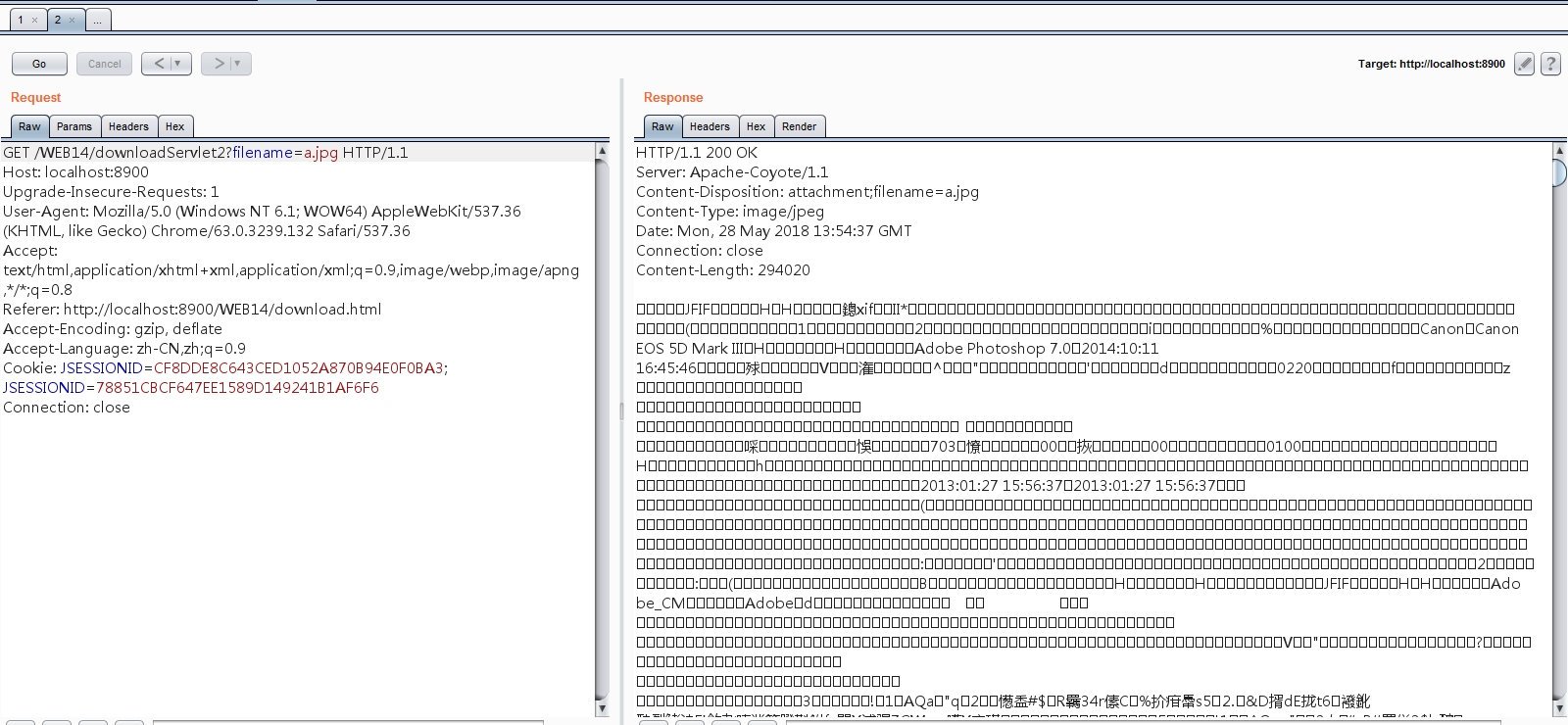
进行绕过下载显示文件内容:
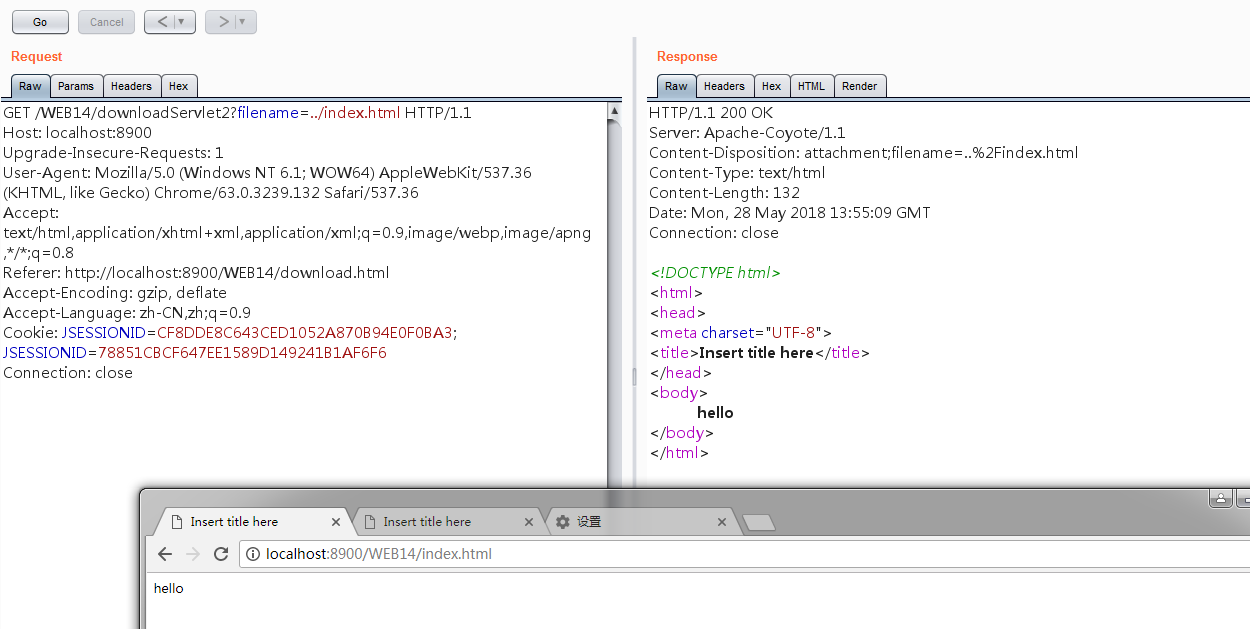
未深入利用,这里的修复方案有两种1.黑名单验证修复 2.白名单验证修复
这里我选择2的修复方案。
谈修复方案之前先讲解下何为黑名单,何为黑名单!
黑名单就是决定阻止的内容,比如我想要过滤一些特殊的字符,如果我的列表中存在这些特殊字符就拦截他们,这种属于黑名单
白名单就是决定放行的内容,比如我允许你输入a-z,如果用户输入的内容范围不在a-z以内,我就认为你的行为是非法的,这种属于白名单。
各自的优缺点:白名单比黑名单更安全,白名单不利于用户体验,为了用户体验大多数企业还是选择黑名单,黑名单容易被绕过!
这里的修复思路:允许用户下载的文件在我的某个列表中,如果用户下载的内容不在我的文件列表中,那么我认为你的行为是非法的!
具体修复代码如下:
首先如果需要下载的文件不存在那么将会302跳转到ErrorInfo.html页面,代码如下:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Insert title here</title> </head> <body> 未找到文件!请重试... </body> </html>
java部分文件下载实现代码:
package cn.downloadServlet; import java.io.*; import java.io.IOException; import java.net.URLEncoder; import java.util.ArrayList; import java.util.Base64; import javax.servlet.ServletException; import javax.servlet.ServletOutputStream; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import javax.xml.ws.RespectBinding; import com.sun.org.apache.xerces.internal.util.SynchronizedSymbolTable; import com.sun.xml.internal.bind.v2.runtime.output.StAXExStreamWriterOutput; import sun.misc.BASE64Encoder; public class DownloadServlet2 extends HttpServlet { static String[] arr =null; //获取文件夹下所有文件名称 public static void getFileName() { String path = "D:\\JavaWeb\\.metadata\\.plugins\\org.eclipse.wst.server.core\\tmp2\\wtpwebapps\\WEB14\\download"; File f = new File(path); ArrayList<String> arrayList=new ArrayList<>(); if (!f.exists()) { System.out.println(path + " not exists"); return; } File fa[] = f.listFiles(); for (int i = 0; i < fa.length; i++) { File fs = fa[i]; if (fs.isDirectory()) { arrayList.add(fs.getName()); } else { arrayList.add(fs.getName()); } } arr= new String[arrayList.size()]; for (int i = 0; i <arr.length; i++) { arr[i]=arrayList.get(i); } } public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { // 请求filename参数 String filename = request.getParameter("filename"); // System.out.println(filename); // 解决获得中文参数的乱码 filename = new String(filename.getBytes("ISO8859-1"), "UTF-8"); // 获得请求头中的User-Agent String agent = request.getHeader("User-Agent"); // 根据不同浏览器进行不同的编码 String filenameEncoder = ""; if (agent.contains("MSIE")) { // IE浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); filenameEncoder = filenameEncoder.replace("+", " "); } else if (agent.contains("Firefox")) { // 火狐浏览器 BASE64Encoder base64Encoder = new BASE64Encoder(); filenameEncoder = "=?utf-8?B?" + base64Encoder.encode(filename.getBytes ("utf-8")) + "?="; } else { // 其它浏览器 filenameEncoder = URLEncoder.encode(filename, "utf-8"); } getFileName(); String requestURI = request.getRequestURI(); System.out.println(requestURI); // 自动判断文件的数据类型 response.setContentType(this.getServletContext().getMimeType(filename)); // 告诉客户端该文件不是直接解析 而是以附件形式打开(下载) response.setHeader("Content-Disposition", "attachment;filename=" + filenameEncoder); //获取请求的文件路径名称 String realPath = this.getServletContext().getRealPath("/download/" + filename); boolean key = false; //函数调用 getFileName(); String arrs=null; for (int i = 0; i < arr.length; i++) { arrs=arr[i]; //文件判断 if (arrs.equals(filename)) { key = true; } } if (key == true) { ServletOutputStream outputStream = response.getOutputStream(); FileInputStream fileInputStream = new FileInputStream(realPath); int length = 0; byte[] buff = new byte[1024]; while ((length = fileInputStream.read(buff)) != -1) { outputStream.write(buff, 0, length); } } else { response.sendRedirect("/WEB14/ErrorInfo.html"); } } public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { doGet(request, response); } }
我们再次实验下是否存在文件下载漏洞了。
正常的图片下载:
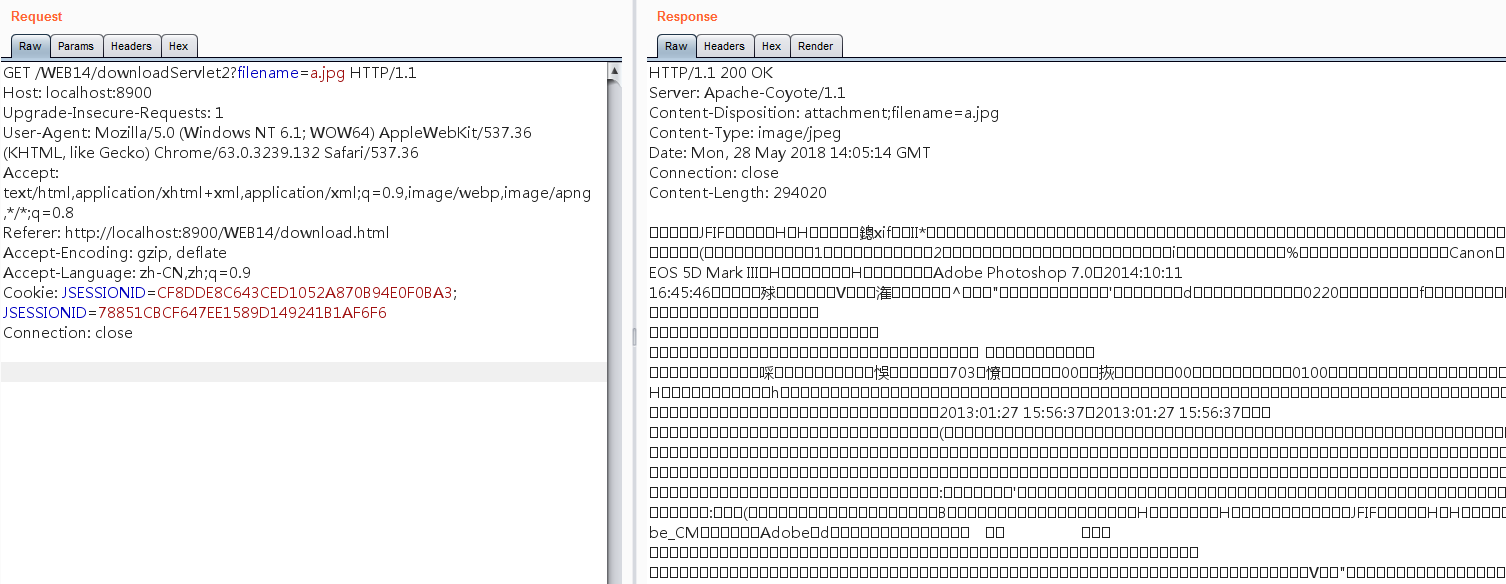
尝试读取其他文件内容:
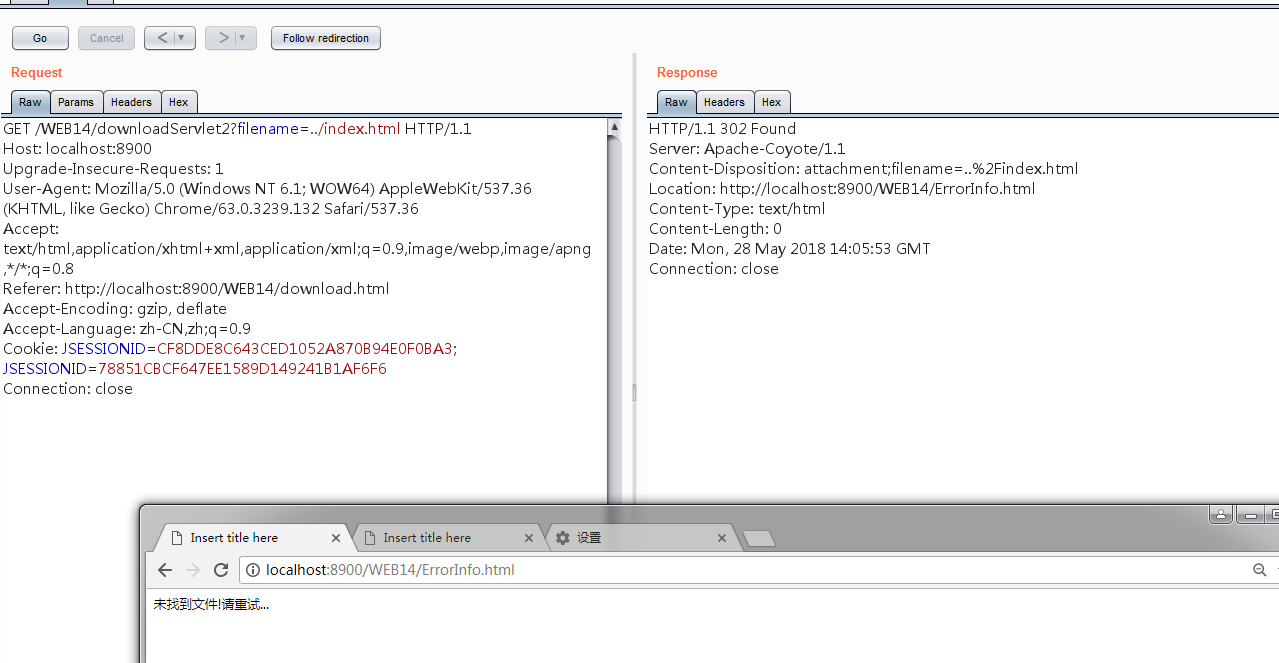
说明我们利用这种方法是可以有效防止文件下载漏洞的!
不忘初心,方得始终。

