java代码审计中不能忽略的思路-持续更新
1.反射和动态加载
1.在java反序列化中,反射被频繁使用,使用反射修改,提取
2.动态代理的特性非常强大,java框架的过滤器就使用了动态加载这个特性
动态代理:https://juejin.cn/post/6844903591501627405
不仅在开发上,在安全领域,也广泛受用。
动态代理它的特点就是:被代理的类,调用任意方法,都会调用代理类的invoke方法。
利用这个tricks,我们可以寻找一些rce的利用链
详细说下反射:
反射里面有两个函数,非常容易记混
1.newInstance 类似于new Class->实例化对象
2.invoke 从类中获取一个方法后,可以使用invoke() 来调用这个方法
参考:https://juejin.cn/post/6975888597865988127
一个个来,先看newInstance函数
newInstance和new创建实例化,虽然效果相同,但是原理差很多:
new是实例对象而newInstance是实用类的加载机制
new不用加载过就可用而newInstance需要加载并且有连接才可用
通过反射调用构造函数有两种方法:
调用无参构造函数:Class.newInstance()
调用带参数的构造函数:
通过 Class 类获取 Constructor
调用 Constructor 中的 newInstance(Object ... initarges) 方法
2.作用域和try catch细节点
理解java中的作用域非常重要,对代码审计,写代码都很有重要。
以一段代码为例子:
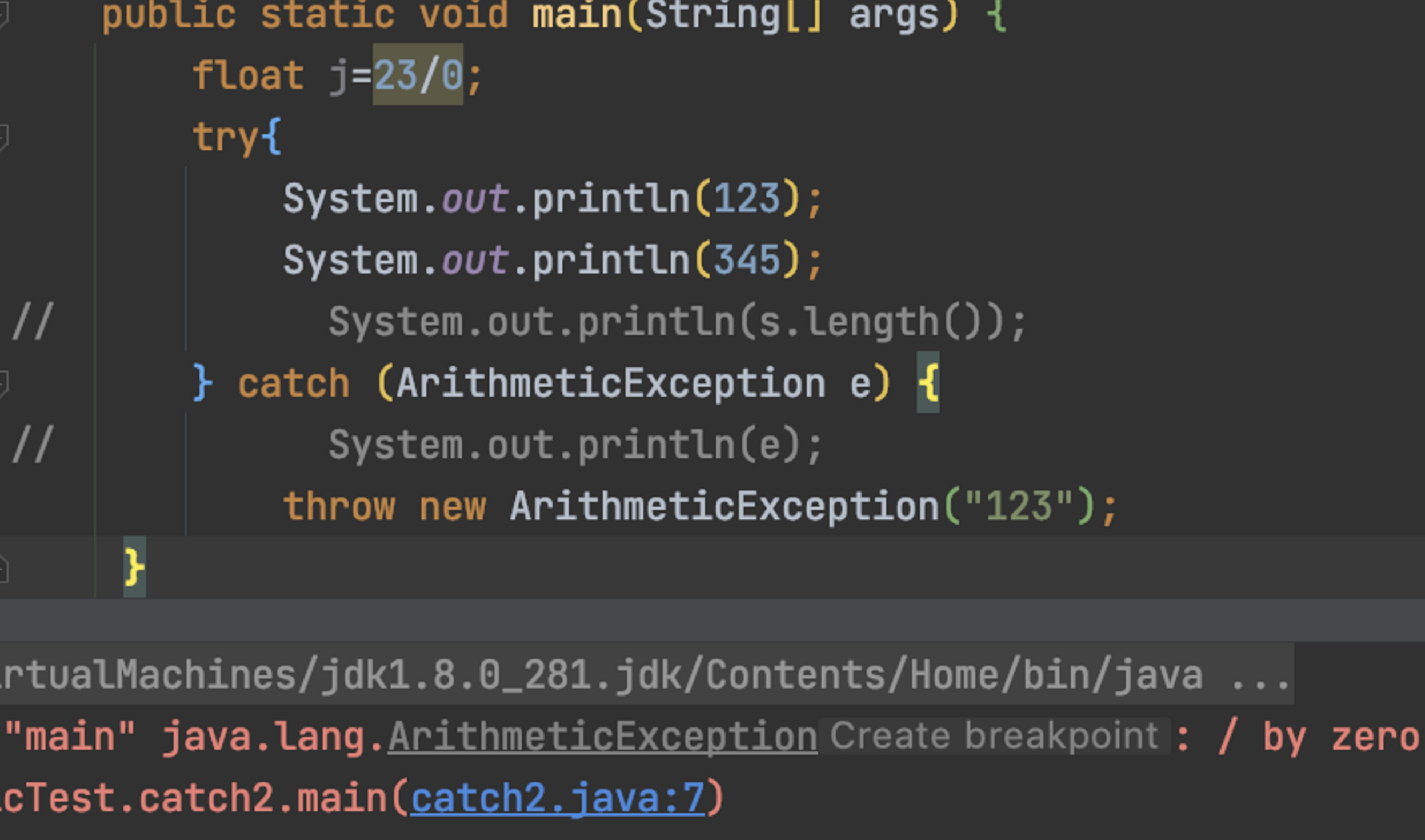
public static void main(String[] args) { try{ float j=23/0; System.out.println(123); System.out.println(345); // System.out.println(s.length()); } catch (ArithmeticException e) { // System.out.println(e); throw new ArithmeticException("123"); } // System.out.println(s.length()); System.out.println(123); }
这时候的报错是123,因为抛出了异常。因为 变量j在try这个异常处理作用域下。

拿出,把变量移出异常处理作用:
这时候报的就不是作用域中抛出的异常,而是自身的23/0的异常
再看个demo:
public static void main(String[] args) { try{ float j=23/0; // System.out.println(s.length()); } catch (ArithmeticException e) { System.out.println(e); // throw new ArithmeticException("123"); } System.out.println(123); }
此时j变量在异常报错作用域内
此时会打印作用域外的内容,因为异常作用域处理了异常,会继续执行。

移除j变量到异常处理作用域外:
public static void main(String[] args) { float j=23/0; try // System.out.println(s.length()); } catch (ArithmeticException e) { System.out.println(e); // throw new ArithmeticException("123"); } System.out.println(123); }
因为报异常,所以最后没有输出123

只要throw抛出,就一定会走catch流:
某段cms测试代码:
package com.demo.testbug; public class catch_test { public static void main(String[] args) { try { String cls ="xxxx"; if(cls!=null) { try { Class.forName(cls).newInstance(); } catch (ClassNotFoundException classNotFoundException) { throw new Exception("123"); } } } catch (Throwable throwable2){ System.out.println(444); System.out.println(throwable2); } } }
这段代码,一定会走第二个catch流,因为第一个catch捕捉是抛出流,抛出必定要捕捉处理。
3.编译类型和运行类型:
定义变量左侧声明部分为编译类型,右侧运行类型是真实结果
运行属性,为编译类型。调用方法为运行类型
通常情况下,编译类型和运行类型一致。
使用多态的时候,编译类型和运行类型不一致
如:
Father f = new Son(); f.action(),调用函数是运行类型 f.属性 调用属性是看编译类型
牢记:调用方法走运行类型,调用属性走编译类型!!!

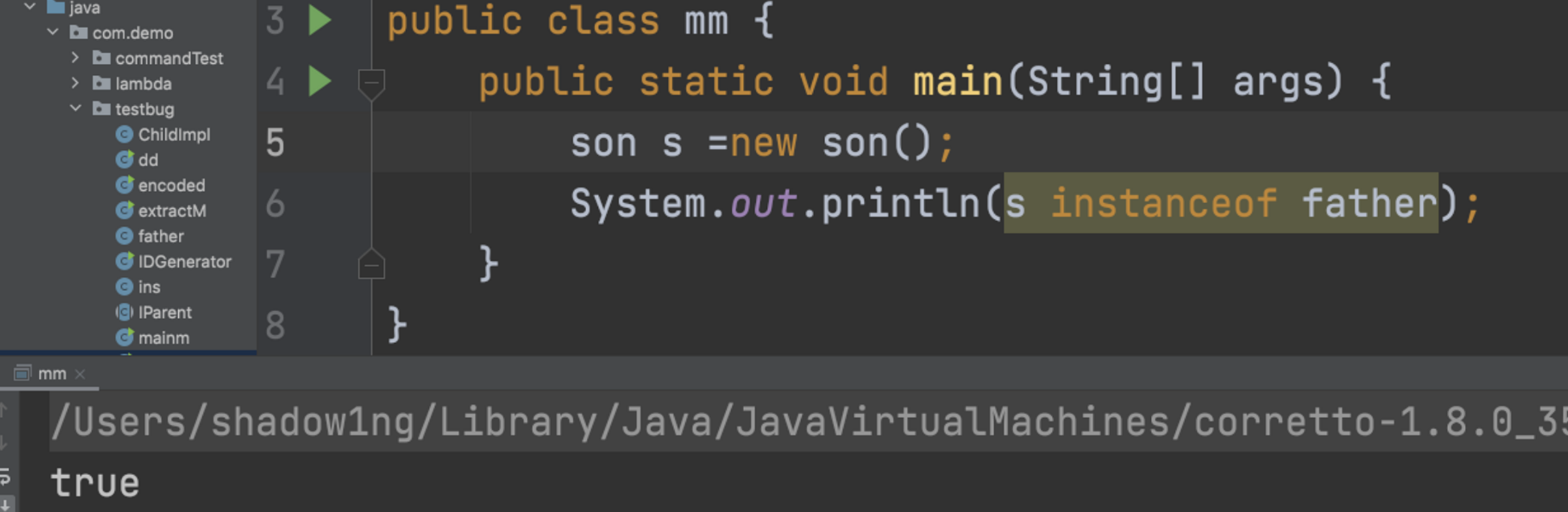
5.instanceof
tricks: 必须为引用类型,不能是基本类型 判断一个引用所指向的对象:instanceof 主要用来判断某个对象是不是某个类的实例。 son 和father有继承关系。此时s是子类,father是父类,是可以的。
6.request.getRequestDispatcher(
请求转发可以用来绕过过滤器,还可以读取包含文件


更多参考:
https://www.yuque.com/pmiaowu/gpy1q8/pkzfug6spzrezz7k
https://blog.51cto.com/1031627059/1681958
7.再谈java项目各个配置文件
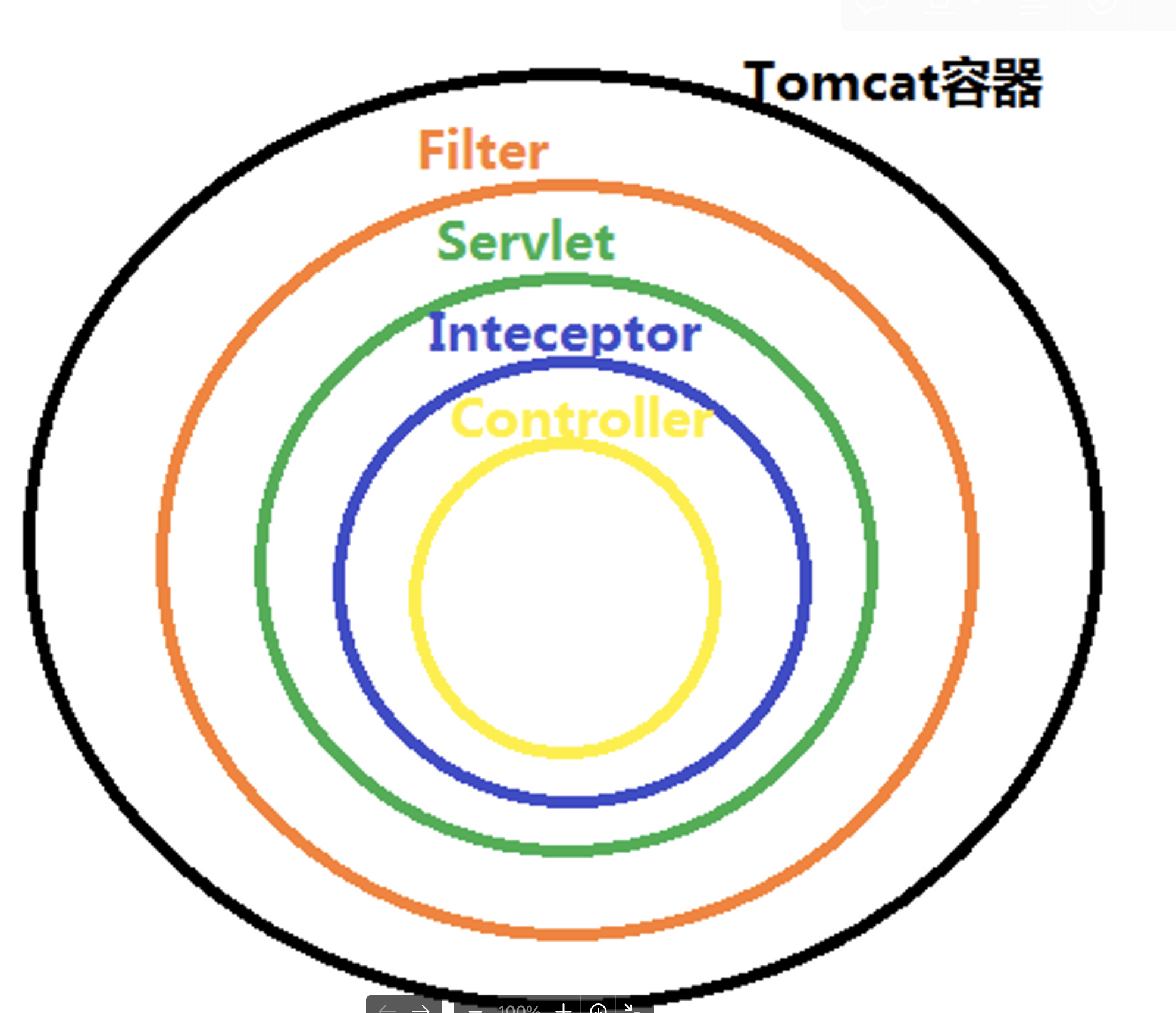
spring-mvc.xml:
sping-mvc.xml文件中主要的工作是:启动注解、扫描controller包注解;静态资源映射;视图解析(defaultViewResolver);文件上传(multipartResolver);返回消息json配置。
web.xml:
(1)web项目启动时,读取web.xml配置文件,首先解析的是applicationContext.xml文件,其次才是sping-mvc.xml文件
(2)web.xml中配置的加载优先级context-param -> listener -> filter -> servlet

1.upload Upload 2.<form action= 3.filename fileName 4.new File( 5.enctype="multipart/form-data" 6.MultipartHttpServletRequest multipartRequest 7.ServletFileUpload ....
2.登录bypass关键字:
1.setAttribute( 2.getRequestDispatcher( 3.new UserSession( new .*Session( 4.过滤器/拦截器bypass chain.doFilter( 5..setAuthent 6.authenticate( 7.setSessionId( 8.new User.* 9.session.setAttribute("
关注第三方组建druid等 Druid-Session监控-前端页面: /druid/websession.html
Druid-Session监控-api接口: /druid/websession.json?orderBy=&orderType=asc&page=1&perPageCount=1000000 ...
3.关注jdbc:
.getConnection(
DriverManager.getConnection(
4.关注命令执行,命令拼接注入:
/bin/sh /bin/bash cmd exec excute eval等
5.反序列化漏洞关键字:
Java有多种反序列化的方法,下面列举一些常用的方法: 1. 使用ObjectInputStream类:最常用的反序列化方法是使用Java的ObjectInputStream类。这个类可以将一个序列化的对象转换回原始的Java对象。 2. 使用XMLDecoder类:XMLDecoder类可以将XML格式的序列化对象转换回原始的Java对象。这个类通常用于在Java和其他语言之间进行数据交换。 3. 使用JSON工具库:如果序列化的数据是以JSON格式存储的,可以使用Java的JSON工具库(如Jackson、Gson等)将其转换回Java对象。 4. 使用自定义的反序列化方法:如果需要更精细的控制反序列化过程,可以使用Java的反射机制来自定义反序列化方法。 是的,除了Java自带的反序列化方法,还有许多第三方库和框架提供了自己的反序列化实现,下面列举一些常用的第三方反序列化方法: 1. Kryo:Kryo是一个快速、高效的Java序列化和反序列化库,它可以比Java自带的序列化和反序列化更快、更紧凑。Kryo支持许多数据类型,包括Java原始数据类型、集合、Map、甚至是自定义的POJO对象。 2. Protobuf:Protobuf是Google开发的一种高效的序列化和反序列化格式,它可以将数据转换为紧凑的二进制格式,并支持多种语言。在Java中,可以使用Google提供的protobuf-java库来实现序列化和反序列化功能。 3. FST:FST是一个快速的Java序列化和反序列化库,它可以比Java自带的序列化和反序列化更快、更紧凑。FST支持许多数据类型,包括Java原始数据类型、集合、Map、甚至是自定义的POJO对象。 4. Hessian:Hessian是一个轻量级的Java RPC框架,它可以将Java对象序列化为二进制格式,并通过网络传输。Hessian支持许多数据类型,包括Java原始数据类型、集合、Map、甚至是自定义的POJO对象。 需要注意的是,不同的反序列化方法可能有不同的性能、安全和兼容性特点,需要根据实际情况选择合适的反序列化方法。同时,反序列化可能存在安全风险,因此需要谨慎处理数据来源和数据内容,以避免安全漏洞。 deserialize( xmlrpc依赖包: https://github.com/orangecertcc/security-research/security/advisories/GHSA-x2r6-4m45-m4jp java反序列化备忘录: https://github.com/GrrrDog/Java-Deserialization-Cheat-Sheet
6.关注解压缩漏洞:
ZipInputStream
unzip等
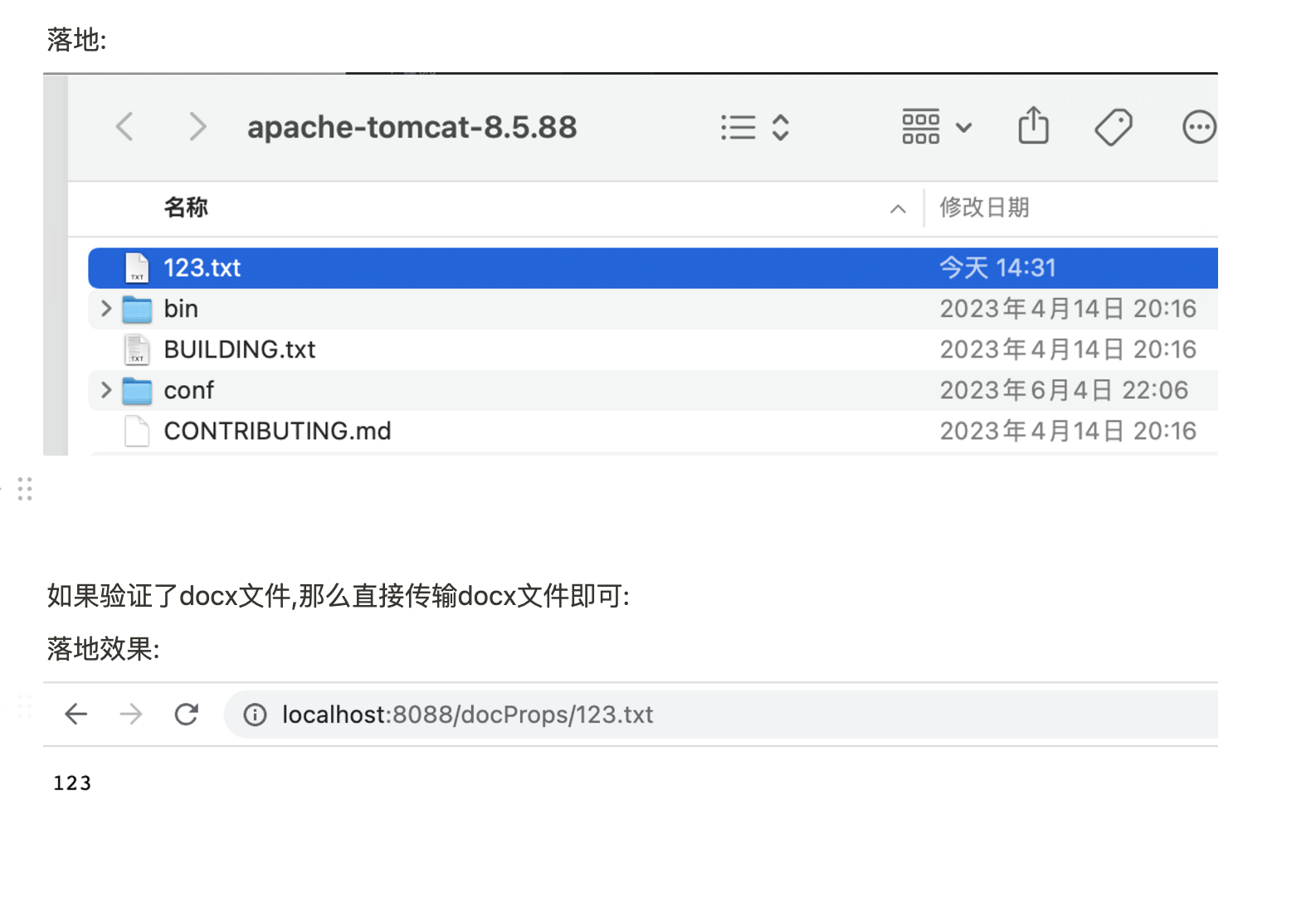
7.java文件操作(内容参考了phpoop博客):
jar包class: org.apache.commons.io.FileUtils 读文件: readFileToString() readFileToByteArray() readFileToString() readLines() 写文件: writeLines() writeStringToFile() writeByteArrayToFile() 删除文件: deleteDirectory() deleteQuietly() cleanDirectory() forceDelete() 复制文件: copyFile() copyFileToDirectory() copyDirectoryToDirectory() copyDirectory() copyURLToFile() 移动文件: moveDirectory() moveDirectoryToDirectory() moveFile() moveFileToDirectory() jar包class: org.apache.commons.io.IOUtils 读文件: toString() toByteArray() readLines() read() readFully() 写文件: copy() copyLarge() write()
8.不常见的ssrf利用方式:
1.docx ssrf
关键字:
document.xml
docx
docxFile.getEntry(
getEntry(
9.关注lib中的jar包:
1.如某hr oa hessian漏洞 2.如很多oa都会使用的金格组建,金格文件上传 3.低版本的fastjson/shiro等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号