


Hue 之 SparkSql interpreters的配置及使用
1、环境说明:
HDP 2.4 V3 sandbox
hue 4.0.0
2、hue 4.0.0 编译及安装
地址:https://github.com/cloudera/hue/releases/tag/release-4.1.0(也许是发版这弄错了吧,连接是4.1.0,内容版本是4.0.0)
2.1 修改%HUE_CODE_HOME%/hue/maven/pom.xml版本,如下:
<hadoop-mr1.version>2.7.1</hadoop-mr1.version> <hadoop.version>2.7.1</hadoop.version> <spark.version>1.6.0</spark.version>
2.2 将hadoop-core修改为hadoop-common(core会报错找不到)
<artifactId>hadoop-common</artifactId>
2.3 将hadoop-test的版本改为1.2.1:
<artifactId>hadoop-test</artifactId><version>1.2.1</version>
2.4 删除多余文件,否则编译时会报错
将两个ThriftJobTrackerPlugin.java文件删除,分别在如下两个目录:
%HUE_CODE_HOME%/hue/desktop/libs/hadoop/java/src/main/java/org/apache/hadoop/thriftfs/ThriftJobTrackerPlugin.java
%HUE_CODE_HOME%/hue/desktop/libs/hadoop/java/src/main/java/org/apache/hadoop/mapred/ThriftJobTrackerPlugin.java
2.5 编译安装
PREFIX=/usr/local/hue-4.0.0-release/ make clean //指定要安装的目录
rm -rf /usr/local/hue-4.0.0-release/*
PREFIX=/usr/local/hue-4.0.0-release/ make install
3. spark thrift server 配置及启动
hdp 2.4 V3 的 spark thrift server 默认端口是10015,我们将此信息配置到 /usr/hdp/current/spark-thriftserver/conf/hive-site.xml中,如下:(我没找到在ambari启动spark thrift-server的入口,只能手动启动)
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://sandbox.hortonworks.com:9083</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10015</value> <description> Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT </description> </property> <!-- <property> <name>hive.server2.thrift.bind.host</name> <value>localhost</value> <description> Bind host on which to run the HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST </description> </property> --> </configuration>
配置完之后,启动thrift-server。
cd /usr/hdp/current/spark-thriftserver/ sbin/start-thriftserver.sh --master yarn --deploy-mode client
4 配置hue.ini (/usr/local/hue-4.0.0-release/hue/desktop/conf/hue.ini)
4.1 反注释 [[interpreters]] 下的 sparksql,如下:
[[interpreters]]
# Define the name and how to connect and execute the language.
[[[hive]]]
# The name of the snippet.
name=Hive
# The backend connection to use to communicate with the server.
interface=hiveserver2
[[[impala]]]
name=Impala
interface=hiveserver2
[[[sparksql]]]
name=SparkSql
interface=hiveserver2
[[[spark]]]
name=Scala
interface=livy
[[[pyspark]]]
name=PySpark
interface=livy
[[[r]]]
name=R
interface=livy
[[[jar]]]
name=Spark Submit Jar
interface=livy-batch
4.2 配置spark 的livy server 如下:
###########################################################################
# Settings to configure the Spark application.
###########################################################################
[spark]
# Host address of the Livy Server.
livy_server_host=localhost
# Port of the Livy Server.
livy_server_port=8998
# Configure Livy to start in local 'process' mode, or 'yarn' workers.
livy_server_session_kind=yarn
# Whether Livy requires client to perform Kerberos authentication.
security_enabled=false
# Host of the Sql Server
sql_server_host=localhost
# Port of the Sql Server
sql_server_port=10015
注意:端口配置为spark-thrift server 端口10015
5 验证结果
5.1 确保spark-thrift server已经启动
cd /usr/hdp/current/spark-thriftserver/
sbin/start-thriftserver.sh --master yarn --deploy-mode client
5.2 启动hue
cd /usr/local/hue-4.0.0-release/hue/ build/env/bin/supervisor
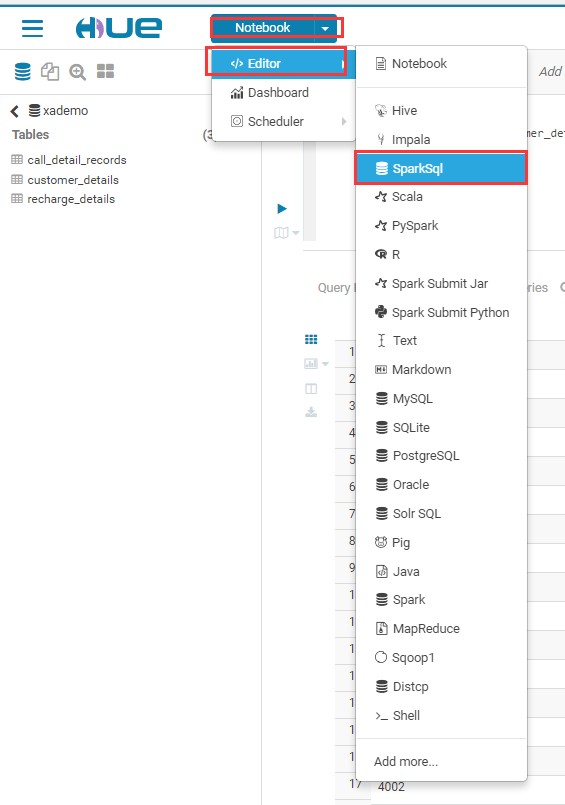
5.3 登录hue,选择notebook-editor-sparksql,录入sql
5.4 打开yarn页面,可以看到当前有一个spark thrift server 的job。

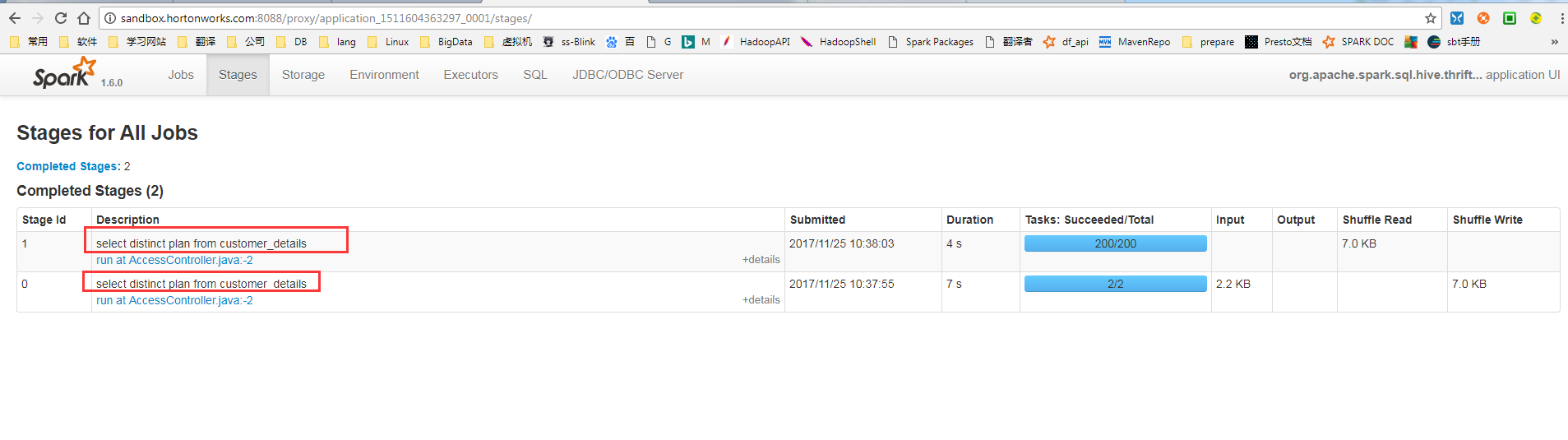
5.5 执行5.3 的sql,点击5.4 job 右侧的applicationMaster ,进入spark页面,可以看到如下spark job。在stages页面,我们可以看到执行的sql,
5.6 待执行完成之后,查看hue页面,可以看到查到的数据如下:
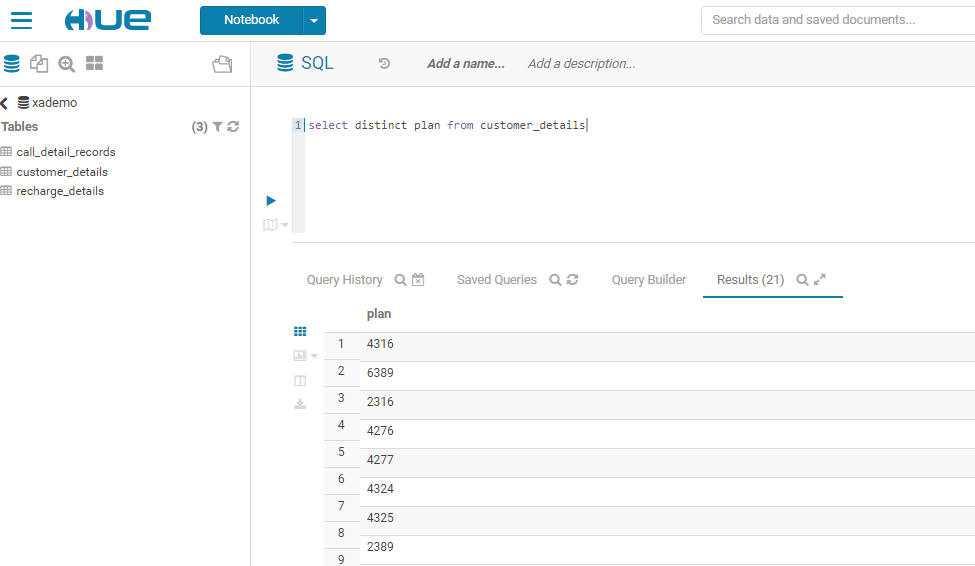
至此,说明 hue发起的请求,spark thrift server 已经接收到,且能够正常执行。
6 额外说明:
细心的读者可能发现了,我们配置了livy server,但是却没有启动livy-server。
在此说明:spark sql 执行(使用 spark sql [[interpreters]] )的时候,不使用livy server。直接把sql 提交到了 spark 的thrift server 上,但是要读取livy server中的sql_server_port变量
只有在使用spark scala 这些interpreters的时候,才会用到 livy-server
附hue.ini
# Hue configuration file
# ===================================
#
# For complete documentation about the contents of this file, run
# $ <hue_root>/build/env/bin/hue config_help
#
# All .ini files under the current directory are treated equally. Their
# contents are merged to form the Hue configuration, which can
# can be viewed on the Hue at
# http://<hue_host>:<port>/dump_config
###########################################################################
# General configuration for core Desktop features (authentication, etc)
###########################################################################
[desktop]
# Set this to a random string, the longer the better.
# This is used for secure hashing in the session store.
secret_key=asjlkajfslajflalfj
# Execute this script to produce the Django secret key. This will be used when
# 'secret_key' is not set.
## secret_key_script=
# Webserver listens on this address and port
http_host=0.0.0.0
http_port=8890
# Choose whether to enable the new Hue 4 interface.
is_hue_4=true
# A comma-separated list of available Hue load balancers
## hue_load_balancer=
# Time zone name
# time_zone=America/Los_Angeles
time_zone=Asia/Shanghai
# Enable or disable Django debug mode.
django_debug_mode=false
# Enable or disable database debug mode.
## database_logging=false
# Whether to send debug messages from JavaScript to the server logs.
## send_dbug_messages=false
# Enable or disable backtrace for server error
http_500_debug_mode=false
# Enable or disable memory profiling.
## memory_profiler=false
# Server email for internal error messages
## django_server_email='hue@localhost.localdomain'
# Email backend
## django_email_backend=django.core.mail.backends.smtp.EmailBackend
# Webserver runs as this user
server_user=root
server_group=root
# This should be the Hue admin and proxy user
default_user=root
# This should be the hadoop cluster admin
default_hdfs_superuser=hdfs
# If set to false, runcpserver will not actually start the web server.
# Used if Apache is being used as a WSGI container.
## enable_server=yes
# Number of threads used by the CherryPy web server
## cherrypy_server_threads=40
# This property specifies the maximum size of the receive buffer in bytes in thrift sasl communication (default 2 MB).
## sasl_max_buffer=2 * 1024 * 1024
# Filename of SSL Certificate
## ssl_certificate=
# Filename of SSL RSA Private Key
## ssl_private_key=
# Filename of SSL Certificate Chain
## ssl_certificate_chain=
# SSL certificate password
## ssl_password=
# Execute this script to produce the SSL password. This will be used when 'ssl_password' is not set.
## ssl_password_script=
# X-Content-Type-Options: nosniff This is a HTTP response header feature that helps prevent attacks based on MIME-type confusion.
## secure_content_type_nosniff=true
# X-Xss-Protection: \"1; mode=block\" This is a HTTP response header feature to force XSS protection.
## secure_browser_xss_filter=true
# X-Content-Type-Options: nosniff This is a HTTP response header feature that helps prevent attacks based on MIME-type confusion.
## secure_content_security_policy="script-src 'self' 'unsafe-inline' 'unsafe-eval' *.google-analytics.com *.doubleclick.net data:;img-src 'self' *.google-analytics.com *.doubleclick.net http://*.tile.osm.org *.tile.osm.org *.gstatic.com data:;style-src 'self' 'unsafe-inline' fonts.googleapis.com;connect-src 'self';frame-src *;child-src 'self' data: *.vimeo.com;object-src 'none'"
# Strict-Transport-Security HTTP Strict Transport Security(HSTS) is a policy which is communicated by the server to the user agent via HTTP response header field name “Strict-Transport-Security”. HSTS policy specifies a period of time during which the user agent(browser) should only access the server in a secure fashion(https).
## secure_ssl_redirect=False
## secure_redirect_host=0.0.0.0
## secure_redirect_exempt=[]
## secure_hsts_seconds=31536000
## secure_hsts_include_subdomains=true
# List of allowed and disallowed ciphers in cipher list format.
# See http://www.openssl.org/docs/apps/ciphers.html for more information on
# cipher list format. This list is from
# https://wiki.mozilla.org/Security/Server_Side_TLS v3.7 intermediate
# recommendation, which should be compatible with Firefox 1, Chrome 1, IE 7,
# Opera 5 and Safari 1.
## ssl_cipher_list=ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS:!DH:!ADH
# Path to default Certificate Authority certificates.
## ssl_cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## validate=true
# Default LDAP/PAM/.. username and password of the hue user used for authentications with other services.
# Inactive if password is empty.
# e.g. LDAP pass-through authentication for HiveServer2 or Impala. Apps can override them individually.
## auth_username=hue
## auth_password=
# Default encoding for site data
## default_site_encoding=utf-8
# Help improve Hue with anonymous usage analytics.
# Use Google Analytics to see how many times an application or specific section of an application is used, nothing more.
## collect_usage=true
# Tile layer server URL for the Leaflet map charts
# Read more on http://leafletjs.com/reference.html#tilelayer
# Make sure you add the tile domain to the img-src section of the 'secure_content_security_policy' configuration parameter as well.
## leaflet_tile_layer=http://{s}.tile.osm.org/{z}/{x}/{y}.png
# The copyright message for the specified Leaflet maps Tile Layer
## leaflet_tile_layer_attribution='© <a href="http://osm.org/copyright">OpenStreetMap</a> contributors'
# X-Frame-Options HTTP header value. Use 'DENY' to deny framing completely
## http_x_frame_options=SAMEORIGIN
# Enable X-Forwarded-Host header if the load balancer requires it.
## use_x_forwarded_host=true
# Support for HTTPS termination at the load-balancer level with SECURE_PROXY_SSL_HEADER.
## secure_proxy_ssl_header=false
# Comma-separated list of Django middleware classes to use.
# See https://docs.djangoproject.com/en/1.4/ref/middleware/ for more details on middlewares in Django.
## middleware=desktop.auth.backend.LdapSynchronizationBackend
# Comma-separated list of regular expressions, which match the redirect URL.
# For example, to restrict to your local domain and FQDN, the following value can be used:
# ^\/.*$,^http:\/\/www.mydomain.com\/.*$
## redirect_whitelist=^(\/[a-zA-Z0-9]+.*|\/)$
# Comma separated list of apps to not load at server startup.
# e.g.: pig,zookeeper
app_blacklist=impala,security
# Id of the cluster where Hue is located.
## cluster_id='default'
# Choose whether to show the new SQL editor.
## use_new_editor=true
# Choose whether to show the improved assist panel and the right context panel
## use_new_side_panels=false
# Editor autocomplete timeout (ms) when fetching columns, fields, tables etc.
# To disable this type of autocompletion set the value to 0.
## editor_autocomplete_timeout=30000
# Enable saved default configurations for Hive, Impala, Spark, and Oozie.
## use_default_configuration=false
# The directory where to store the auditing logs. Auditing is disable if the value is empty.
# e.g. /var/log/hue/audit.log
## audit_event_log_dir=
# Size in KB/MB/GB for audit log to rollover.
## audit_log_max_file_size=100MB
# A json file containing a list of log redaction rules for cleaning sensitive data
# from log files. It is defined as:
#
# {
# "version": 1,
# "rules": [
# {
# "description": "This is the first rule",
# "trigger": "triggerstring 1",
# "search": "regex 1",
# "replace": "replace 1"
# },
# {
# "description": "This is the second rule",
# "trigger": "triggerstring 2",
# "search": "regex 2",
# "replace": "replace 2"
# }
# ]
# }
#
# Redaction works by searching a string for the [TRIGGER] string. If found,
# the [REGEX] is used to replace sensitive information with the
# [REDACTION_MASK]. If specified with 'log_redaction_string', the
# 'log_redaction_string' rules will be executed after the
# 'log_redaction_file' rules.
#
# For example, here is a file that would redact passwords and social security numbers:
# {
# "version": 1,
# "rules": [
# {
# "description": "Redact passwords",
# "trigger": "password",
# "search": "password=\".*\"",
# "replace": "password=\"???\""
# },
# {
# "description": "Redact social security numbers",
# "trigger": "",
# "search": "\d{3}-\d{2}-\d{4}",
# "replace": "XXX-XX-XXXX"
# }
# ]
# }
## log_redaction_file=
# Comma separated list of strings representing the host/domain names that the Hue server can serve.
# e.g.: localhost,domain1,*
## allowed_hosts="*"
# Administrators
# ----------------
[[django_admins]]
## [[[admin1]]]
## name=john
## email=john@doe.com
# UI customizations
# -------------------
[[custom]]
# Top banner HTML code
# e.g. <H4>Test Lab A2 Hue Services</H4>
## banner_top_html='<div style="padding: 4px; text-align: center; background-color: #003F6C; color: #DBE8F1">This is Hue 4 Beta! - Please feel free to email any feedback / questions to <a href="mailto:team@gethue.com" target="_blank" style="color: #FFF; font-weight: bold">team@gethue.com</a> or <a href="https://twitter.com/gethue" target="_blank" style="color: #FFF; font-weight: bold">@gethue</a>.</div>'
# Login splash HTML code
# e.g. WARNING: You are required to have authorization before you proceed
## login_splash_html=<h4>GetHue.com</h4><br/><br/>WARNING: You have accessed a computer managed by GetHue. You are required to have authorization from GetHue before you proceed.
# Cache timeout in milliseconds for the assist, autocomplete, etc.
# defaults to 86400000 (1 day), set to 0 to disable caching
## cacheable_ttl=86400000
# SVG code to replace the default Hue logo in the top bar and sign in screen
# e.g. <image xlink:href="/static/desktop/art/hue-logo-mini-white.png" x="0" y="0" height="40" width="160" />
## logo_svg=
# Configuration options for user authentication into the web application
# ------------------------------------------------------------------------
[[auth]]
# Authentication backend. Common settings are:
# - django.contrib.auth.backends.ModelBackend (entirely Django backend)
# - desktop.auth.backend.AllowAllBackend (allows everyone)
# - desktop.auth.backend.AllowFirstUserDjangoBackend
# (Default. Relies on Django and user manager, after the first login)
# - desktop.auth.backend.LdapBackend
# - desktop.auth.backend.PamBackend
# - desktop.auth.backend.SpnegoDjangoBackend
# - desktop.auth.backend.RemoteUserDjangoBackend
# - libsaml.backend.SAML2Backend
# - libopenid.backend.OpenIDBackend
# - liboauth.backend.OAuthBackend
# (New oauth, support Twitter, Facebook, Google+ and Linkedin
# Multiple Authentication backends are supported by specifying a comma-separated list in order of priority.
# However, in order to enable OAuthBackend, it must be the ONLY backend configured.
## backend=desktop.auth.backend.AllowFirstUserDjangoBackend
# Class which defines extra accessor methods for User objects.
## user_aug=desktop.auth.backend.DefaultUserAugmentor
# The service to use when querying PAM.
## pam_service=login
# When using the desktop.auth.backend.RemoteUserDjangoBackend, this sets
# the normalized name of the header that contains the remote user.
# The HTTP header in the request is converted to a key by converting
# all characters to uppercase, replacing any hyphens with underscores
# and adding an HTTP_ prefix to the name. So, for example, if the header
# is called Remote-User that would be configured as HTTP_REMOTE_USER
#
# Defaults to HTTP_REMOTE_USER
## remote_user_header=HTTP_REMOTE_USER
# Ignore the case of usernames when searching for existing users.
# Supported in remoteUserDjangoBackend and SpnegoDjangoBackend
## ignore_username_case=true
# Forcibly cast usernames to lowercase, takes precedence over force_username_uppercase
# Supported in remoteUserDjangoBackend and SpnegoDjangoBackend
## force_username_lowercase=true
# Forcibly cast usernames to uppercase, cannot be combined with force_username_lowercase
## force_username_uppercase=false
# Users will expire after they have not logged in for 'n' amount of seconds.
# A negative number means that users will never expire.
## expires_after=-1
# Apply 'expires_after' to superusers.
## expire_superusers=true
# Users will automatically be logged out after 'n' seconds of inactivity.
# A negative number means that idle sessions will not be timed out.
idle_session_timeout=-1
# Force users to change password on first login with desktop.auth.backend.AllowFirstUserDjangoBackend
## change_default_password=false
# Number of login attempts allowed before a record is created for failed logins
## login_failure_limit=3
# After number of allowed login attempts are exceeded, do we lock out this IP and optionally user agent?
## login_lock_out_at_failure=false
# If set, defines period of inactivity in hours after which failed logins will be forgotten.
# A value of 0 or None will disable this check. Default: None
## login_cooloff_time=None
# If True, lock out based on an IP address AND a user agent.
# This means requests from different user agents but from the same IP are treated differently.
## login_lock_out_use_user_agent=false
# If True, lock out based on IP and user
## login_lock_out_by_combination_user_and_ip=false
# If True, it will look for the IP address from the header defined at reverse_proxy_header.
## behind_reverse_proxy=false
# If behind_reverse_proxy is True, it will look for the IP address from this header. Default: HTTP_X_FORWARDED_FOR
## reverse_proxy_header=HTTP_X_FORWARDED_FOR
# Configuration options for connecting to LDAP and Active Directory
# -------------------------------------------------------------------
[[ldap]]
# The search base for finding users and groups
## base_dn="DC=mycompany,DC=com"
# URL of the LDAP server
## ldap_url=ldap://auth.mycompany.com
# The NT domain used for LDAP authentication
## nt_domain=mycompany.com
# A PEM-format file containing certificates for the CA's that
# Hue will trust for authentication over TLS.
# The certificate for the CA that signed the
# LDAP server certificate must be included among these certificates.
# See more here http://www.openldap.org/doc/admin24/tls.html.
## ldap_cert=
## use_start_tls=true
# Distinguished name of the user to bind as -- not necessary if the LDAP server
# supports anonymous searches
## bind_dn="CN=ServiceAccount,DC=mycompany,DC=com"
# Password of the bind user -- not necessary if the LDAP server supports
# anonymous searches
## bind_password=
# Execute this script to produce the bind user password. This will be used
# when 'bind_password' is not set.
## bind_password_script=
# Pattern for searching for usernames -- Use <username> for the parameter
# For use when using LdapBackend for Hue authentication
## ldap_username_pattern="uid=<username>,ou=People,dc=mycompany,dc=com"
# Create users in Hue when they try to login with their LDAP credentials
# For use when using LdapBackend for Hue authentication
## create_users_on_login = true
# Synchronize a users groups when they login
## sync_groups_on_login=false
# Ignore the case of usernames when searching for existing users in Hue.
## ignore_username_case=true
# Force usernames to lowercase when creating new users from LDAP.
# Takes precedence over force_username_uppercase
## force_username_lowercase=true
# Force usernames to uppercase, cannot be combined with force_username_lowercase
## force_username_uppercase=false
# Use search bind authentication.
## search_bind_authentication=true
# Choose which kind of subgrouping to use: nested or suboordinate (deprecated).
## subgroups=suboordinate
# Define the number of levels to search for nested members.
## nested_members_search_depth=10
# Whether or not to follow referrals
## follow_referrals=false
# Enable python-ldap debugging.
## debug=false
# Sets the debug level within the underlying LDAP C lib.
## debug_level=255
# Possible values for trace_level are 0 for no logging, 1 for only logging the method calls with arguments,
# 2 for logging the method calls with arguments and the complete results and 9 for also logging the traceback of method calls.
## trace_level=0
[[[users]]]
# Base filter for searching for users
## user_filter="objectclass=*"
# The username attribute in the LDAP schema
## user_name_attr=sAMAccountName
[[[groups]]]
# Base filter for searching for groups
## group_filter="objectclass=*"
# The group name attribute in the LDAP schema
## group_name_attr=cn
# The attribute of the group object which identifies the members of the group
## group_member_attr=members
[[[ldap_servers]]]
## [[[[mycompany]]]]
# The search base for finding users and groups
## base_dn="DC=mycompany,DC=com"
# URL of the LDAP server
## ldap_url=ldap://auth.mycompany.com
# The NT domain used for LDAP authentication
## nt_domain=mycompany.com
# A PEM-format file containing certificates for the CA's that
# Hue will trust for authentication over TLS.
# The certificate for the CA that signed the
# LDAP server certificate must be included among these certificates.
# See more here http://www.openldap.org/doc/admin24/tls.html.
## ldap_cert=
## use_start_tls=true
# Distinguished name of the user to bind as -- not necessary if the LDAP server
# supports anonymous searches
## bind_dn="CN=ServiceAccount,DC=mycompany,DC=com"
# Password of the bind user -- not necessary if the LDAP server supports
# anonymous searches
## bind_password=
# Execute this script to produce the bind user password. This will be used
# when 'bind_password' is not set.
## bind_password_script=
# Pattern for searching for usernames -- Use <username> for the parameter
# For use when using LdapBackend for Hue authentication
## ldap_username_pattern="uid=<username>,ou=People,dc=mycompany,dc=com"
## Use search bind authentication.
## search_bind_authentication=true
# Whether or not to follow referrals
## follow_referrals=false
# Enable python-ldap debugging.
## debug=false
# Sets the debug level within the underlying LDAP C lib.
## debug_level=255
# Possible values for trace_level are 0 for no logging, 1 for only logging the method calls with arguments,
# 2 for logging the method calls with arguments and the complete results and 9 for also logging the traceback of method calls.
## trace_level=0
## [[[[[users]]]]]
# Base filter for searching for users
## user_filter="objectclass=Person"
# The username attribute in the LDAP schema
## user_name_attr=sAMAccountName
## [[[[[groups]]]]]
# Base filter for searching for groups
## group_filter="objectclass=groupOfNames"
# The username attribute in the LDAP schema
## group_name_attr=cn
# Configuration options for specifying the Source Version Control.
# ----------------------------------------------------------------
[[vcs]]
## [[[git-read-only]]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
## [[[github]]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
# These will be necessary when you want to write back to the repository.
## Client ID for Authorized Application
# client_id=
## Client Secret for Authorized Application
# client_secret=
## [[[svn]]
## Base URL to Remote Server
# remote_url=https://github.com/cloudera/hue/tree/master
## Base URL to Version Control API
# api_url=https://api.github.com
# These will be necessary when you want to write back to the repository.
## Client ID for Authorized Application
# client_id=
## Client Secret for Authorized Application
# client_secret=
# Configuration options for specifying the Desktop Database. For more info,
# see http://docs.djangoproject.com/en/1.4/ref/settings/#database-engine
# ------------------------------------------------------------------------
[[database]]
# Database engine is typically one of:
# postgresql_psycopg2, mysql, sqlite3 or oracle.
#
# Note that for sqlite3, 'name', below is a path to the filename. For other backends, it is the database name
# Note for Oracle, options={"threaded":true} must be set in order to avoid crashes.
# Note for Oracle, you can use the Oracle Service Name by setting "host=" and "port=" and then "name=<host>:<port>/<service_name>".
# Note for MariaDB use the 'mysql' engine.
## engine=sqlite3
## host=
## port=
## user=
## password=
engine=mysql
host=localhost
port=3306
user=hive
password=hive
name=hive
# conn_max_age option to make database connection persistent value in seconds
# https://docs.djangoproject.com/en/1.9/ref/databases/#persistent-connections
## conn_max_age=0
# Execute this script to produce the database password. This will be used when 'password' is not set.
## password_script=/path/script
## name=desktop/desktop.db
## options={}
# Database schema, to be used only when public schema is revoked in postgres
## schema=public
# Configuration options for specifying the Desktop session.
# For more info, see https://docs.djangoproject.com/en/1.4/topics/http/sessions/
# ------------------------------------------------------------------------
[[session]]
# The cookie containing the users' session ID will expire after this amount of time in seconds.
# Default is 2 weeks.
## ttl=1209600
# The cookie containing the users' session ID and csrf cookie will be secure.
# Should only be enabled with HTTPS.
## secure=false
# The cookie containing the users' session ID and csrf cookie will use the HTTP only flag.
## http_only=true
# Use session-length cookies. Logs out the user when she closes the browser window.
## expire_at_browser_close=false
# Configuration options for connecting to an external SMTP server
# ------------------------------------------------------------------------
[[smtp]]
# The SMTP server information for email notification delivery
host=localhost
port=25
user=
password=
# Whether to use a TLS (secure) connection when talking to the SMTP server
tls=no
# Default email address to use for various automated notification from Hue
## default_from_email=hue@localhost
# Configuration options for Kerberos integration for secured Hadoop clusters
# ------------------------------------------------------------------------
[[kerberos]]
# Path to Hue's Kerberos keytab file
## hue_keytab=
# Kerberos principal name for Hue
## hue_principal=hue/hostname.foo.com
# Path to kinit
## kinit_path=/path/to/kinit
# Configuration options for using OAuthBackend (Core) login
# ------------------------------------------------------------------------
[[oauth]]
# The Consumer key of the application
## consumer_key=XXXXXXXXXXXXXXXXXXXXX
# The Consumer secret of the application
## consumer_secret=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
# The Request token URL
## request_token_url=https://api.twitter.com/oauth/request_token
# The Access token URL
## access_token_url=https://api.twitter.com/oauth/access_token
# The Authorize URL
## authenticate_url=https://api.twitter.com/oauth/authorize
# Configuration options for Metrics
# ------------------------------------------------------------------------
[[metrics]]
# Enable the metrics URL "/desktop/metrics"
## enable_web_metrics=True
# If specified, Hue will write metrics to this file.
## location=/var/log/hue/metrics.json
# Time in milliseconds on how frequently to collect metrics
## collection_interval=30000
###########################################################################
# Settings to configure the snippets available in the Notebook
###########################################################################
[notebook]
## Show the notebook menu or not
# show_notebooks=true
## Flag to enable the selection of queries from files, saved queries into the editor or as snippet.
# enable_external_statements=true
## Flag to enable the bulk submission of queries as a background task through Oozie.
# enable_batch_execute=true
## Flag to enable the SQL query builder of the table assist.
# enable_query_builder=true
## Flag to enable the creation of a coordinator for the current SQL query.
# enable_query_scheduling=false
## Main flag to override the automatic starting of the DBProxy server.
# enable_dbproxy_server=true
## Classpath to be appended to the default DBProxy server classpath.
# dbproxy_extra_classpath=
## Comma separated list of interpreters that should be shown on the wheel. This list takes precedence over the
## order in which the interpreter entries appear. Only the first 5 interpreters will appear on the wheel.
# interpreters_shown_on_wheel=
# One entry for each type of snippet.
[[interpreters]]
# Define the name and how to connect and execute the language.
[[[hive]]]
# The name of the snippet.
name=Hive
# The backend connection to use to communicate with the server.
interface=hiveserver2
[[[impala]]]
name=Impala
interface=hiveserver2
[[[sparksql]]]
name=SparkSql
interface=hiveserver2
[[[spark]]]
name=Scala
interface=livy
[[[pyspark]]]
name=PySpark
interface=livy
[[[r]]]
name=R
interface=livy
[[[jar]]]
name=Spark Submit Jar
interface=livy-batch
[[[py]]]
name=Spark Submit Python
interface=livy-batch
[[[text]]]
name=Text
interface=text
[[[markdown]]]
name=Markdown
interface=text
[[[mysql]]]
name = MySQL
interface=rdbms
[[[sqlite]]]
name = SQLite
interface=rdbms
[[[postgresql]]]
name = PostgreSQL
interface=rdbms
[[[oracle]]]
name = Oracle
interface=rdbms
[[[solr]]]
name = Solr SQL
interface=solr
## Name of the collection handler
# options='{"collection": "default"}'
[[[pig]]]
name=Pig
interface=oozie
[[[java]]]
name=Java
interface=oozie
[[[spark2]]]
name=Spark
interface=oozie
[[[mapreduce]]]
name=MapReduce
interface=oozie
[[[sqoop1]]]
name=Sqoop1
interface=oozie
[[[distcp]]]
name=Distcp
interface=oozie
[[[shell]]]
name=Shell
interface=oozie
#[[[mysql]]]
# name=MySql JDBC
# interface=jdbc
# ## Specific options for connecting to the server.
# ## The JDBC connectors, e.g. mysql.jar, need to be in the CLASSPATH environment variable.
# ## If 'user' and 'password' are omitted, they will be prompted in the UI.
# options='{"url": "jdbc:mysql://localhost:3306/hue", "driver": "com.mysql.jdbc.Driver", "user": "root", "password": "root"}'
###########################################################################
# Settings to configure your Analytics Dashboards
###########################################################################
[dashboard]
## Activate the Dashboard link in the menu.
# is_enabled=true
## Activate the SQL Dashboard (beta).
# has_sql_enabled=false
[[engines]]
# [[[solr]]]
## Requires Solr 6+
# analytics=false
# nesting=false
# [[[sql]]]
# analytics=true
# nesting=false
###########################################################################
# Settings to configure your Hadoop cluster.
###########################################################################
[hadoop]
# Configuration for HDFS NameNode
# ------------------------------------------------------------------------
[[hdfs_clusters]]
# HA support by using HttpFs
[[[default]]]
# Enter the filesystem uri
fs_defaultfs=hdfs://localhost:8020
# NameNode logical name.
## logical_name=
# Use WebHdfs/HttpFs as the communication mechanism.
# Domain should be the NameNode or HttpFs host.
# Default port is 14000 for HttpFs.
webhdfs_url=http://localhost:50070/webhdfs/v1
# Change this if your HDFS cluster is Kerberos-secured
## security_enabled=false
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True
# Directory of the Hadoop configuration
hadoop_conf_dir='/etc/hadoop/conf'
# Configuration for YARN (MR2)
# ------------------------------------------------------------------------
[[yarn_clusters]]
[[[default]]]
# Enter the host on which you are running the ResourceManager
resourcemanager_host=localhost
# The port where the ResourceManager IPC listens on
resourcemanager_port=8032
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
## security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://localhost:8088
# URL of the ProxyServer API
proxy_api_url=http://localhost:8088
# URL of the HistoryServer API
history_server_api_url=http://localhost:19888
# URL of the Spark History Server
spark_history_server_url=http://localhost:18088
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
## ssl_cert_ca_verify=True
# HA support by specifying multiple clusters.
# Redefine different properties there.
# e.g.
# [[[ha]]]
# Resource Manager logical name (required for HA)
## logical_name=my-rm-name
# Un-comment to enable
## submit_to=True
# URL of the ResourceManager API
## resourcemanager_api_url=http://localhost:8088
# ...
# Configuration for MapReduce (MR1)
# ------------------------------------------------------------------------
[[mapred_clusters]]
[[[default]]]
# Enter the host on which you are running the Hadoop JobTracker
jobtracker_host=localhost
# The port where the JobTracker IPC listens on
## jobtracker_port=8021
# JobTracker logical name for HA
## logical_name=
# Thrift plug-in port for the JobTracker
## thrift_port=9290
# Whether to submit jobs to this cluster
submit_to=False
# Change this if your MapReduce cluster is Kerberos-secured
## security_enabled=false
# HA support by specifying multiple clusters
# e.g.
# [[[ha]]]
# Enter the logical name of the JobTrackers
## logical_name=my-jt-name
###########################################################################
# Settings to configure Beeswax with Hive
###########################################################################
[beeswax]
# Host where HiveServer2 is running.
# If Kerberos security is enabled, use fully-qualified domain name (FQDN).
hive_server_host=localhost
# Port where HiveServer2 Thrift server runs on.
hive_server_port=10000
# Hive configuration directory, where hive-site.xml is located
hive_conf_dir=/etc/hive/conf
# Timeout in seconds for thrift calls to Hive service
## server_conn_timeout=120
# Choose whether to use the old GetLog() thrift call from before Hive 0.14 to retrieve the logs.
# If false, use the FetchResults() thrift call from Hive 1.0 or more instead.
## use_get_log_api=false
# Limit the number of partitions that can be listed.
## list_partitions_limit=10000
# The maximum number of partitions that will be included in the SELECT * LIMIT sample query for partitioned tables.
## query_partitions_limit=10
# A limit to the number of rows that can be downloaded from a query before it is truncated.
# A value of -1 means there will be no limit.
## download_row_limit=100000
# Hue will try to close the Hive query when the user leaves the editor page.
# This will free all the query resources in HiveServer2, but also make its results inaccessible.
## close_queries=false
# Hue will use at most this many HiveServer2 sessions per user at a time.
## max_number_of_sessions=1
# Thrift version to use when communicating with HiveServer2.
# New column format is from version 7.
## thrift_version=7
# A comma-separated list of white-listed Hive configuration properties that users are authorized to set.
## config_whitelist=hive.map.aggr,hive.exec.compress.output,hive.exec.parallel,hive.execution.engine,mapreduce.job.queuename
# Override the default desktop username and password of the hue user used for authentications with other services.
# e.g. Used for LDAP/PAM pass-through authentication.
## auth_username=hue
## auth_password=
[[ssl]]
# Path to Certificate Authority certificates.
## cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## validate=true
###########################################################################
# Settings to configure Metastore
###########################################################################
[metastore]
# Flag to turn on the new version of the create table wizard.
## enable_new_create_table=true
###########################################################################
# Settings to configure Impala
###########################################################################
[impala]
# Host of the Impala Server (one of the Impalad)
## server_host=localhost
# Port of the Impala Server
## server_port=21050
# Kerberos principal
## impala_principal=impala/hostname.foo.com
# Turn on/off impersonation mechanism when talking to Impala
## impersonation_enabled=False
# Number of initial rows of a result set to ask Impala to cache in order
# to support re-fetching them for downloading them.
# Set to 0 for disabling the option and backward compatibility.
## querycache_rows=50000
# Timeout in seconds for thrift calls
## server_conn_timeout=120
# Hue will try to close the Impala query when the user leaves the editor page.
# This will free all the query resources in Impala, but also make its results inaccessible.
## close_queries=true
# If > 0, the query will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that query within QUERY_TIMEOUT_S seconds.
## query_timeout_s=600
# If > 0, the session will be timed out (i.e. cancelled) if Impala does not do any work
# (compute or send back results) for that session within QUERY_TIMEOUT_S seconds (default 1 hour).
## session_timeout_s=3600
# Override the desktop default username and password of the hue user used for authentications with other services.
# e.g. Used for LDAP/PAM pass-through authentication.
## auth_username=hue
## auth_password=
# A comma-separated list of white-listed Impala configuration properties that users are authorized to set.
# config_whitelist=debug_action,explain_level,mem_limit,optimize_partition_key_scans,query_timeout_s,request_pool
# Path to the impala configuration dir which has impalad_flags file
## impala_conf_dir=${HUE_CONF_DIR}/impala-conf
[[ssl]]
# SSL communication enabled for this server.
## enabled=false
# Path to Certificate Authority certificates.
## cacerts=/etc/hue/cacerts.pem
# Choose whether Hue should validate certificates received from the server.
## validate=true
###########################################################################
# Settings to configure the Spark application.
###########################################################################
[spark]
# Host address of the Livy Server.
livy_server_host=localhost
# Port of the Livy Server.
livy_server_port=8998
# Configure Livy to start in local 'process' mode, or 'yarn' workers.
livy_server_session_kind=yarn
# Whether Livy requires client to perform Kerberos authentication.
security_enabled=false
# Host of the Sql Server
sql_server_host=localhost
# Port of the Sql Server
sql_server_port=10015
###########################################################################
# Settings to configure the Oozie app
###########################################################################
[oozie]
# Location on local FS where the examples are stored.
## local_data_dir=..../examples
# Location on local FS where the data for the examples is stored.
## sample_data_dir=...thirdparty/sample_data
# Location on HDFS where the oozie examples and workflows are stored.
# Parameters are $TIME and $USER, e.g. /user/$USER/hue/workspaces/workflow-$TIME
## remote_data_dir=/user/hue/oozie/workspaces
# Maximum of Oozie workflows or coodinators to retrieve in one API call.
## oozie_jobs_count=100
# Use Cron format for defining the frequency of a Coordinator instead of the old frequency number/unit.
## enable_cron_scheduling=true
# Flag to enable the saved Editor queries to be dragged and dropped into a workflow.
## enable_document_action=true
# Flag to enable Oozie backend filtering instead of doing it at the page level in Javascript. Requires Oozie 4.3+.
## enable_oozie_backend_filtering=true
# Flag to enable the Impala action.
## enable_impala_action=false
###########################################################################
# Settings to configure the Filebrowser app
###########################################################################
[filebrowser]
# Location on local filesystem where the uploaded archives are temporary stored.
## archive_upload_tempdir=/tmp
# Show Download Button for HDFS file browser.
## show_download_button=false
# Show Upload Button for HDFS file browser.
## show_upload_button=false
# Flag to enable the extraction of a uploaded archive in HDFS.
## enable_extract_uploaded_archive=false
###########################################################################
# Settings to configure Pig
###########################################################################
[pig]
# Location of piggybank.jar on local filesystem.
## local_sample_dir=/usr/share/hue/apps/pig/examples
# Location piggybank.jar will be copied to in HDFS.
## remote_data_dir=/user/hue/pig/examples
###########################################################################
# Settings to configure Sqoop2
###########################################################################
[sqoop]
# For autocompletion, fill out the librdbms section.
# Sqoop server URL
server_url=http://localhost:12000/sqoop
# Path to configuration directory
sqoop_conf_dir=/etc/sqoop2/conf
###########################################################################
# Settings to configure Proxy
###########################################################################
[proxy]
# Comma-separated list of regular expressions,
# which match 'host:port' of requested proxy target.
whitelist=(localhost|127\.0\.0\.1):(50030|50070|50060|50075)
# Comma-separated list of regular expressions,
# which match any prefix of 'host:port/path' of requested proxy target.
# This does not support matching GET parameters.
## blacklist=
###########################################################################
# Settings to configure HBase Browser
###########################################################################
[hbase]
# Comma-separated list of HBase Thrift servers for clusters in the format of '(name|host:port)'.
# Use full hostname with security.
# If using Kerberos we assume GSSAPI SASL, not PLAIN.
hbase_clusters=(Cluster|localhost:9090)
# HBase configuration directory, where hbase-site.xml is located.
hbase_conf_dir=/etc/hbase/conf
# Hard limit of rows or columns per row fetched before truncating.
## truncate_limit = 500
# 'buffered' is the default of the HBase Thrift Server and supports security.
# 'framed' can be used to chunk up responses,
# which is useful when used in conjunction with the nonblocking server in Thrift.
## thrift_transport=buffered
###########################################################################
# Settings to configure Solr Search
###########################################################################
[search]
# URL of the Solr Server
## solr_url=http://localhost:8983/solr/
# Requires FQDN in solr_url if enabled
## security_enabled=false
## Query sent when no term is entered
## empty_query=*:*
###########################################################################
# Settings to configure Solr API lib
###########################################################################
[libsolr]
# Choose whether Hue should validate certificates received from the server.
## ssl_cert_ca_verify=true
# Default path to Solr in ZooKeeper.
## solr_zk_path=/solr
###########################################################################
# Settings to configure Solr Indexer
###########################################################################
[indexer]
# Location of the solrctl binary.
## solrctl_path=/usr/bin/solrctl
# Flag to turn on the morphline based Solr indexer.
## enable_new_indexer=false
# Oozie workspace template for indexing.
## config_indexer_libs_path=/tmp/smart_indexer_lib
# Flag to turn on the new metadata importer.
## enable_new_importer=false
###########################################################################
# Settings to configure Job Designer
###########################################################################
[jobsub]
# Location on local FS where examples and template are stored.
## local_data_dir=..../data
# Location on local FS where sample data is stored
## sample_data_dir=...thirdparty/sample_data
###########################################################################
# Settings to configure Job Browser.
###########################################################################
[jobbrowser]
# Share submitted jobs information with all users. If set to false,
# submitted jobs are visible only to the owner and administrators.
## share_jobs=true
# Whether to disalbe the job kill button for all users in the jobbrowser
## disable_killing_jobs=false
# Offset in bytes where a negative offset will fetch the last N bytes for the given log file (default 1MB).
## log_offset=-1000000
# Maximum number of jobs to fetch and display when pagination is not supported for the type.
## max_job_fetch=500
# Show the version 2 of app which unifies all the past browsers into one.
## enable_v2=false
###########################################################################
# Settings to configure Sentry / Security App.
###########################################################################
[security]
# Use Sentry API V1 for Hive.
## hive_v1=true
# Use Sentry API V2 for Hive.
## hive_v2=false
# Use Sentry API V2 for Solr.
## solr_v2=true
###########################################################################
# Settings to configure the Zookeeper application.
###########################################################################
[zookeeper]
[[clusters]]
[[[default]]]
# Zookeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
host_ports=localhost:2181
# The URL of the REST contrib service (required for znode browsing).
rest_url=http://localhost:9998
# Name of Kerberos principal when using security.
principal_name=zookeeper
###########################################################################
# Settings for the User Admin application
###########################################################################
[useradmin]
# Default home directory permissions
## home_dir_permissions=0755
# The name of the default user group that users will be a member of
## default_user_group=default
[[password_policy]]
# Set password policy to all users. The default policy requires password to be at least 8 characters long,
# and contain both uppercase and lowercase letters, numbers, and special characters.
## is_enabled=false
## pwd_regex="^(?=.*?[A-Z])(?=(.*[a-z]){1,})(?=(.*[\d]){1,})(?=(.*[\W_]){1,}).{8,}$"
## pwd_hint="The password must be at least 8 characters long, and must contain both uppercase and lowercase letters, at least one number, and at least one special character."
## pwd_error_message="The password must be at least 8 characters long, and must contain both uppercase and lowercase letters, at least one number, and at least one special character."
###########################################################################
# Settings to configure liboozie
###########################################################################
[liboozie]
# The URL where the Oozie service runs on. This is required in order for
# users to submit jobs. Empty value disables the config check.
## oozie_url=http://localhost:11000/oozie
# Requires FQDN in oozie_url if enabled
## security_enabled=false
# Location on HDFS where the workflows/coordinator are deployed when submitted.
## remote_deployement_dir=/user/hue/oozie/deployments
###########################################################################
# Settings for the AWS lib
###########################################################################
[aws]
[[aws_accounts]]
# Default AWS account
## [[[default]]]
# AWS credentials
## access_key_id=
## secret_access_key=
## security_token=
# Execute this script to produce the AWS access key ID.
## access_key_id_script=/path/access_key_id.sh
# Execute this script to produce the AWS secret access key.
## secret_access_key_script=/path/secret_access_key.sh
# Allow to use either environment variables or
# EC2 InstanceProfile to retrieve AWS credentials.
## allow_environment_credentials=yes
# AWS region to use, if no region is specified, will attempt to connect to standard s3.amazonaws.com endpoint
## region=us-east-1
# Endpoint overrides
## host=
# Proxy address and port
## proxy_address=
## proxy_port=8080
## proxy_user=
## proxy_pass=
# Secure connections are the default, but this can be explicitly overridden:
## is_secure=true
# The default calling format uses https://<bucket-name>.s3.amazonaws.com but
# this may not make sense if DNS is not configured in this way for custom endpoints.
# e.g. Use boto.s3.connection.OrdinaryCallingFormat for https://s3.amazonaws.com/<bucket-name>
## calling_format=boto.s3.connection.OrdinaryCallingFormat
###########################################################################
# Settings for the Sentry lib
###########################################################################
[libsentry]
# Hostname or IP of server.
## hostname=localhost
# Port the sentry service is running on.
## port=8038
# Sentry configuration directory, where sentry-site.xml is located.
## sentry_conf_dir=/etc/sentry/conf
# Number of seconds when the privilege list of a user is cached.
## privilege_checker_caching=30
###########################################################################
# Settings to configure the ZooKeeper Lib
###########################################################################
[libzookeeper]
# ZooKeeper ensemble. Comma separated list of Host/Port.
# e.g. localhost:2181,localhost:2182,localhost:2183
## ensemble=localhost:2181
# Name of Kerberos principal when using security.
## principal_name=zookeeper
###########################################################################
# Settings for the RDBMS application
###########################################################################
[librdbms]
# The RDBMS app can have any number of databases configured in the databases
# section. A database is known by its section name
# (IE sqlite, mysql, psql, and oracle in the list below).
[[databases]]
# sqlite configuration.
## [[[sqlite]]]
# Name to show in the UI.
## nice_name=SQLite
# For SQLite, name defines the path to the database.
## name=/tmp/sqlite.db
# Database backend to use.
## engine=sqlite
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
# mysql, oracle, or postgresql configuration.
## [[[mysql]]]
# Name to show in the UI.
## nice_name="My SQL DB"
# For MySQL and PostgreSQL, name is the name of the database.
# For Oracle, Name is instance of the Oracle server. For express edition
# this is 'xe' by default.
## name=mysqldb
# Database backend to use. This can be:
# 1. mysql
# 2. postgresql
# 3. oracle
## engine=mysql
# IP or hostname of the database to connect to.
## host=localhost
# Port the database server is listening to. Defaults are:
# 1. MySQL: 3306
# 2. PostgreSQL: 5432
# 3. Oracle Express Edition: 1521
## port=3306
# Username to authenticate with when connecting to the database.
## user=example
# Password matching the username to authenticate with when
# connecting to the database.
## password=example
# Database options to send to the server when connecting.
# https://docs.djangoproject.com/en/1.4/ref/databases/
## options={}
###########################################################################
# Settings to configure SAML
###########################################################################
[libsaml]
# Xmlsec1 binary path. This program should be executable by the user running Hue.
## xmlsec_binary=/usr/local/bin/xmlsec1
# Entity ID for Hue acting as service provider.
# Can also accept a pattern where '<base_url>' will be replaced with server URL base.
## entity_id="<base_url>/saml2/metadata/"
# Create users from SSO on login.
## create_users_on_login=true
# Required attributes to ask for from IdP.
# This requires a comma separated list.
## required_attributes=uid
# Optional attributes to ask for from IdP.
# This requires a comma separated list.
## optional_attributes=
# IdP metadata in the form of a file. This is generally an XML file containing metadata that the Identity Provider generates.
## metadata_file=
# Private key to encrypt metadata with.
## key_file=
# Signed certificate to send along with encrypted metadata.
## cert_file=
# Path to a file containing the password private key.
## key_file_password=/path/key
# Execute this script to produce the private key password. This will be used when 'key_file_password' is not set.
## key_file_password_script=/path/pwd.sh
# A mapping from attributes in the response from the IdP to django user attributes.
## user_attribute_mapping={'uid': ('username', )}
# Have Hue initiated authn requests be signed and provide a certificate.
## authn_requests_signed=false
# Have Hue initiated logout requests be signed and provide a certificate.
## logout_requests_signed=false
# Username can be sourced from 'attributes' or 'nameid'.
## username_source=attributes
# Performs the logout or not.
## logout_enabled=true
###########################################################################
# Settings to configure OpenID
###########################################################################
[libopenid]
# (Required) OpenId SSO endpoint url.
## server_endpoint_url=https://www.google.com/accounts/o8/id
# OpenId 1.1 identity url prefix to be used instead of SSO endpoint url
# This is only supported if you are using an OpenId 1.1 endpoint
## identity_url_prefix=https://app.onelogin.com/openid/your_company.com/
# Create users from OPENID on login.
## create_users_on_login=true
# Use email for username
## use_email_for_username=true
###########################################################################
# Settings to configure OAuth
###########################################################################
[liboauth]
# NOTE:
# To work, each of the active (i.e. uncommented) service must have
# applications created on the social network.
# Then the "consumer key" and "consumer secret" must be provided here.
#
# The addresses where to do so are:
# Twitter: https://dev.twitter.com/apps
# Google+ : https://cloud.google.com/
# Facebook: https://developers.facebook.com/apps
# Linkedin: https://www.linkedin.com/secure/developer
#
# Additionnaly, the following must be set in the application settings:
# Twitter: Callback URL (aka Redirect URL) must be set to http://YOUR_HUE_IP_OR_DOMAIN_NAME/oauth/social_login/oauth_authenticated
# Google+ : CONSENT SCREEN must have email address
# Facebook: Sandbox Mode must be DISABLED
# Linkedin: "In OAuth User Agreement", r_emailaddress is REQUIRED
# The Consumer key of the application
## consumer_key_twitter=
## consumer_key_google=
## consumer_key_facebook=
## consumer_key_linkedin=
# The Consumer secret of the application
## consumer_secret_twitter=
## consumer_secret_google=
## consumer_secret_facebook=
## consumer_secret_linkedin=
# The Request token URL
## request_token_url_twitter=https://api.twitter.com/oauth/request_token
## request_token_url_google=https://accounts.google.com/o/oauth2/auth
## request_token_url_linkedin=https://www.linkedin.com/uas/oauth2/authorization
## request_token_url_facebook=https://graph.facebook.com/oauth/authorize
# The Access token URL
## access_token_url_twitter=https://api.twitter.com/oauth/access_token
## access_token_url_google=https://accounts.google.com/o/oauth2/token
## access_token_url_facebook=https://graph.facebook.com/oauth/access_token
## access_token_url_linkedin=https://api.linkedin.com/uas/oauth2/accessToken
# The Authenticate URL
## authenticate_url_twitter=https://api.twitter.com/oauth/authorize
## authenticate_url_google=https://www.googleapis.com/oauth2/v1/userinfo?access_token=
## authenticate_url_facebook=https://graph.facebook.com/me?access_token=
## authenticate_url_linkedin=https://api.linkedin.com/v1/people/~:(email-address)?format=json&oauth2_access_token=
# Username Map. Json Hash format.
# Replaces username parts in order to simplify usernames obtained
# Example: {"@sub1.domain.com":"_S1", "@sub2.domain.com":"_S2"}
# converts 'email@sub1.domain.com' to 'email_S1'
## username_map={}
# Whitelisted domains (only applies to Google OAuth). CSV format.
## whitelisted_domains_google=
###########################################################################
# Settings to configure Metadata
###########################################################################
[metadata]
[[optimizer]]
# Hostname to Optimizer API or compatible service.
## hostname=navoptapi.us-west-1.optimizer.altus.cloudera.com
# The name of the key of the service.
## auth_key_id=e0819f3a-1e6f-4904-be69-5b704bacd1245
# The private part of the key associated with the auth_key.
## auth_key_secret='-----BEGIN PRIVATE KEY....'
# Execute this script to produce the auth_key secret. This will be used when `auth_key_secret` is not set.
## auth_key_secret_script=/path/to/script.sh
# The name of the workload where queries are uploaded and optimizations are calculated from. Automatically guessed from auth_key and cluster_id if not specified.
## tenant_id=
# Perform Sentry privilege filtering.
# Default to true automatically if the cluster is secure.
## apply_sentry_permissions=False
# Cache timeout in milliseconds for the Optimizer metadata used in assist, autocomplete, etc.
# Defaults to 1 hour, set to 0 to disable caching.
## cacheable_ttl=3600000
# Automatically upload queries after their execution in order to improve recommendations.
## auto_upload_queries=true
# Allow admins to upload the last N executed queries in the quick start wizard. Use 0 to disable.
## query_history_upload_limit=10000
[[navigator]]
# Navigator API URL (without version suffix).
## api_url=http://localhost:7187/api
# Which authentication to use: CM or external via LDAP or SAML.
## navmetadataserver_auth_type=CMDB
# Username of the CM user used for authentication.
## navmetadataserver_cmdb_user=hue
# CM password of the user used for authentication.
## navmetadataserver_cmdb_password=
# Execute this script to produce the CM password. This will be used when the plain password is not set.
# navmetadataserver_cmdb_password_script=
# Username of the LDAP user used for authentication.
## navmetadataserver_ldap_user=hue
# LDAP password of the user used for authentication.
## navmetadataserver_ldap_ppassword=
# Execute this script to produce the LDAP password. This will be used when the plain password is not set.
## navmetadataserver_ldap_password_script=
# Username of the SAML user used for authentication.
## navmetadataserver_saml_user=hue
## SAML password of the user used for authentication.
# navmetadataserver_saml_password=
# Execute this script to produce the SAML password. This will be used when the plain password is not set.
## navmetadataserver_saml_password_script=
# Perform Sentry privilege filtering.
# Default to true automatically if the cluster is secure.
## apply_sentry_permissions=False
# Max number of items to fetch in one call in object search.
## fetch_size_search=450
# Max number of items to fetch in one call in object search autocomplete.
## fetch_size_search_interactive=450
# If metadata search is enabled, also show the search box in the left assist.
## enable_file_search=false
