细说mysql replace into
replace语句在一般的情况下和insert差不多,但是如果表中存在primary 或者unique索引的时候,如果插入的数据和原来的primary key或者unique相同的时候,会删除原来的数据,然后增加一条新的数据,所以有的时候执行一条replace语句相当于执行了一条delete和insert语句。直接上实例吧:
新建一个test表,三个字段,id,title,uid, id是自增的主键,uid是唯一索引;
CREATE TABLE `test` ( `Id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(25) DEFAULT NULL COMMENT '标题', `uid` int(11) DEFAULT NULL COMMENT 'uid', PRIMARY KEY (`Id`), UNIQUE KEY `uid` (`uid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
insert into test(title,uid) VALUES ('你好','1'); insert into test(title,uid) VALUES ('国庆节','2');
结果如下: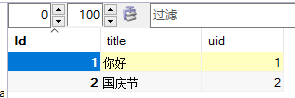
使用 replace into插入数据时:
REPLACE INTO test(title,uid) VALUES ('这次是8天假哦','3');
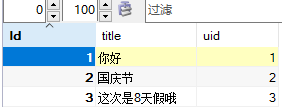
当uid存在时,使用replace into 语句
REPLACE INTO test(title,uid) VALUES ('这是Uid=1的第一条数据哦','1');
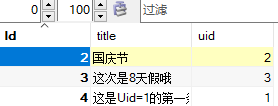
没有预料到 MySQL 在数据冲突时(也就是uid发生重复数据时)实际上是删掉了旧记录,再写入新记录,。通过以上实例,相信博友们可以看出:
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中,
1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
MySQL replace into 有三种形式:
1. replace into tbl_name(col_name, ...) values(...)
2. replace into tbl_name(col_name, ...) select ...
3. replace into tbl_name set col_name=value, ...
第一种形式类似于insert into的用法,
第二种replace select的用法也类似于insert select,这种用法并不一定要求列名匹配,事实上,MYSQL甚至不关心select返回的列名,它需要的是列的位置。例如,replace into tb1( name, title, mood) select rname, rtitle, rmood from tb2;?这个例子使用replace into从?tb2中将所有数据导入tb1中。
第三种replace set用法类似于update set用法,使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
前两种形式用的多些。其中 “into” 关键字可以省略,不过最好加上 “into”,这样意思更加直观。另外,对于那些没有给予值的列,MySQL 将自动为这些列赋上默认值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号