Window7 开发 Spark 应用(JAVA版本)
WordCount是大数据学习最好的入门demo,今天就一起开发java版本的WordCount,然后提交到Spark3.0.0环境运行;
版本信息
OS: Window7
JAVA:1.8.0_181
Hadoop:3.2.1
Spark: 3.0.0-preview2-bin-hadoop3.2
IDE: IntelliJ IDEA 2019.2.4 x64
服务器搭建
Hadoop:CentOS7 部署 Hadoop 3.2.1 (伪分布式)
Spark:CentOS7 安装 Spark3.0.0-preview2-bin-hadoop3.2
示例源码下载
应用开发
1. 本地新建一个Spark项目,POM.xml 内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.phpdragon</groupId> <artifactId>spark-example</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <spark.version>2.4.5</spark.version> <spark.scala.version>2.12</spark.scala.version> </properties> <dependencies> <!-- Spark dependency Start --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${spark.scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${spark.scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${spark.scala.version}</artifactId> <version>${spark.version}</version> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-graphx_${spark.scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>com.github.fommil.netlib</groupId> <artifactId>all</artifactId> <version>1.1.2</version> <type>pom</type> </dependency> <!-- Spark dependency End --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.47</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> <scope>provided</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.68</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/java</sourceDirectory> <testSourceDirectory>src/test/java</testSourceDirectory> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>1.2.1</version> <executions> <execution> <goals> <goal>exec</goal> </goals> </execution> </executions> <configuration> <executable>java</executable> <includeProjectDependencies>false</includeProjectDependencies> <includePluginDependencies>false</includePluginDependencies> <classpathScope>compile</classpathScope> <mainClass>com.phpragon.spark.WordCount</mainClass> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> </project>
2. 编写分词统计代码:
import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import scala.Tuple2; import java.text.SimpleDateFormat; import java.util.Arrays; import java.util.Date; import java.util.List; /** * @Description: Spark的分词统计 * @author: phpdragon@qq.com * @date: 2020/03/30 17:21 */ @Slf4j public class WordCount { public static void main(String[] args) { if(null==args || args.length<3 || StringUtils.isEmpty(args[0]) || StringUtils.isEmpty(args[1]) || StringUtils.isEmpty(args[2])) { log.error("invalid params!"); } String hdfsHost = args[0]; String hdfsPort = args[1]; String textFileName = args[2]; // String hdfsHost = "172.16.1.126"; // String hdfsPort = "9000"; // String textFileName = "test.txt"; SparkConf sparkConf = new SparkConf().setAppName("Spark WordCount Application(Java)"); JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf); String hdfsBasePath = "hdfs://" + hdfsHost + ":" + hdfsPort; //文本文件的hdfs路径 String inputPath = hdfsBasePath + "/input/" + textFileName; //输出结果文件的hdfs路径 String outputPath = hdfsBasePath + "/output/" + new SimpleDateFormat("yyyyMMdd_HHmmss").format(new Date()); log.info("input path : {}", inputPath); log.info("output path : {}", outputPath); log.info("import text"); //导入文件 JavaRDD<String> textFile = javaSparkContext.textFile(inputPath); log.info("do map operation"); JavaPairRDD<String, Integer> counts = textFile //每一行都分割成单词,返回后组成一个大集合 .flatMap(s -> Arrays.asList(s.split(" ")).iterator()) //key是单词,value是1 .mapToPair(word -> new Tuple2<>(word, 1)) //基于key进行reduce,逻辑是将value累加 .reduceByKey((a, b) -> a + b); log.info("do convert"); //先将key和value倒过来,再按照key排序 JavaPairRDD<Integer, String> sorts = counts //key和value颠倒,生成新的map .mapToPair(tuple2 -> new Tuple2<>(tuple2._2(), tuple2._1())) //按照key倒排序 .sortByKey(false); log.info("take top 10"); //取前10个 List<Tuple2<Integer, String>> top10 = sorts.take(10); StringBuilder sbud = new StringBuilder("top 10 word :\n"); //打印出来 for(Tuple2<Integer, String> tuple2 : top10){ sbud.append(tuple2._2()) .append("\t") .append(tuple2._1()) .append("\n"); } log.info(sbud.toString()); System.out.println(sbud.toString()); log.info("merge and save as file"); //分区合并成一个,再导出为一个txt保存在hdfs javaSparkContext.parallelize(top10).coalesce(1).saveAsTextFile(outputPath); log.info("close context"); //关闭context javaSparkContext.close(); } }
3. 调整日志显示级别
log4j.properties内如如下:
log4j.rootLogger=${root.logger} root.logger=WARN,console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n shell.log.level=WARN log4j.logger.org.eclipse.jetty=WARN log4j.logger.org.spark-project.jetty=WARN log4j.logger.org.spark-project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR log4j.logger.org.apache.spark.repl.Main=${shell.log.level} log4j.logger.org.apache.spark.api.python.PythonGatewayServer=${shell.log.level}
这个文件需要放到程序能自动读取加载的地方,比如resources目录下:
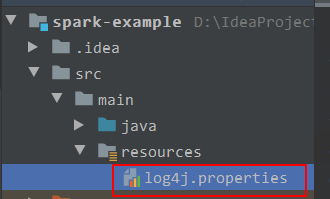
服务端调试
1. 在Hadoop服务器上新建目录 input、output、spark/history
/data/server/hadoop/3.2.1/bin/hdfs dfs -mkdir /input /data/server/hadoop/3.2.1/bin/hdfs dfs -mkdir /output /data/server/hadoop/3.2.1/bin/hdfs dfs -mkdir /spark /data/server/hadoop/3.2.1/bin/hdfs dfs -mkdir /spark/history
2.上传测试文本至Hadoop服务上:
/data/server/hadoop/3.2.1/bin/hdfs dfs -put ~/data/server/hadoop/3.2.1/LICENSE.txt /input/test.txt
3.编译打包后代码,上传 spark-example-1.0-SNAPSHOT.jar 文件至Spark服务。执行下面的命令,命令的最后三个参数,是java的main方法的入参,具体的使用请参照WordCount类的源码:
/home/data/server/spark/3.0.0-preview2-bin-hadoop3.2/bin/spark-submit \ --master spark://172.16.1.126:7077 \ --class com.phpragon.spark.WordCount \ --executor-memory 512m \ --total-executor-cores 2 \ ./spark-example-1.0-SNAPSHOT.jar \ 172.16.1.126 \ 9000 \ test.txt
执行结果:

4.在hadoop服务器执行查看文件的命令,可见/output下新建了子目录 20200330_172721:
[root@localhost spark]# hdfs dfs -ls /output Found 1 items drwxr-xr-x - Administrator supergroup 0 2020-03-30 05:27 /output/20200330_172721
5.查看子目录,发现里面有两个文件:
[root@localhost spark]# hdfs dfs -ls /output/20200330_172721 Found 2 items -rw-r--r-- 3 Administrator supergroup 0 2020-03-30 05:27 /output/20200330_172721/_SUCCESS -rw-r--r-- 3 Administrator supergroup 93 2020-03-30 05:27 /output/20200330_172721/part-00000
上面看到的 /output/20200330_172721/part-00000就是输出结果,用cat命令查看其内容:
[root@localhost spark]# hdfs dfs -cat /output/20200330_172721/part-00000 (4149,) (1208,the) (702,of) (512,or) (481,to) (409,and) (308,this) (305,in) (277,a) (251,OR)
可见与前面控制台输出的一致;
6. 在Spark的web页面,可见刚刚执行的任务信息:
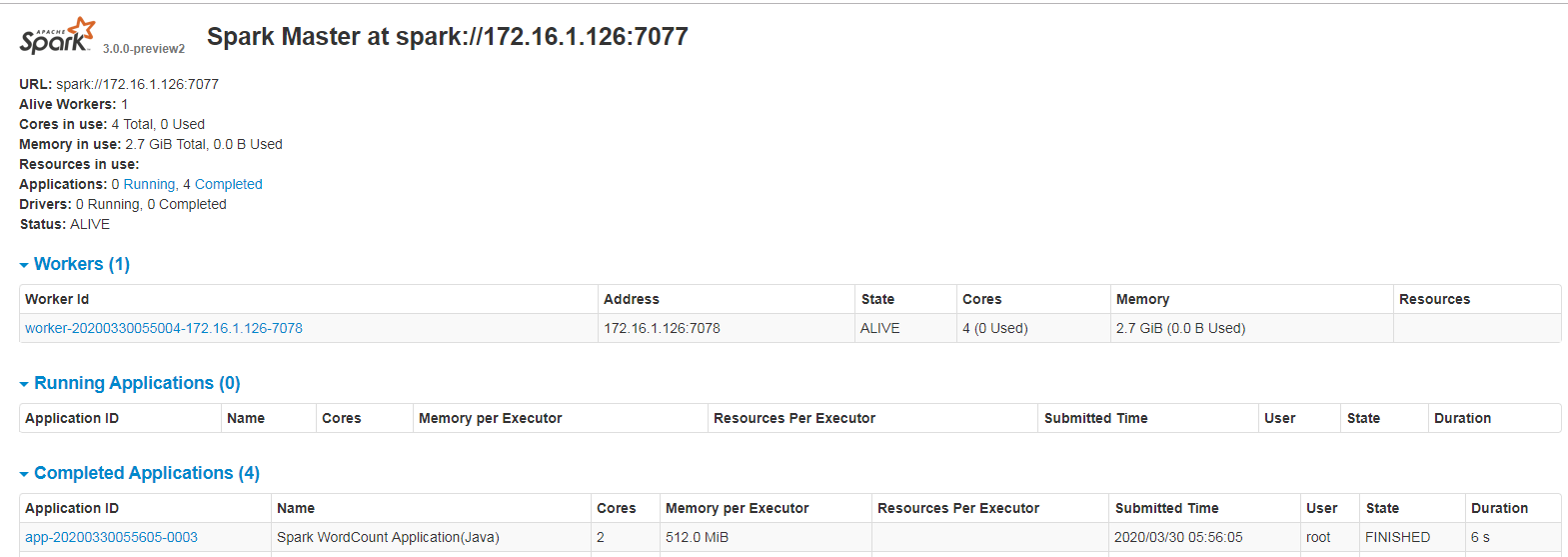
至此,第一个spark应用的开发和运行就完成了。但时间开发情况下不可能每次都编译打包提交运行,这样效率太低,不建议这样开发程序。
本地调试
1.增加红色部分代码,设置为本地模式 。
SparkConf sparkConf = new SparkConf().setMaster("local[*]").setAppName("Spark WordCount Application(Java)");
2. 右键执行后报错:
20/03/30 16:35:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 20/03/30 16:35:57 ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
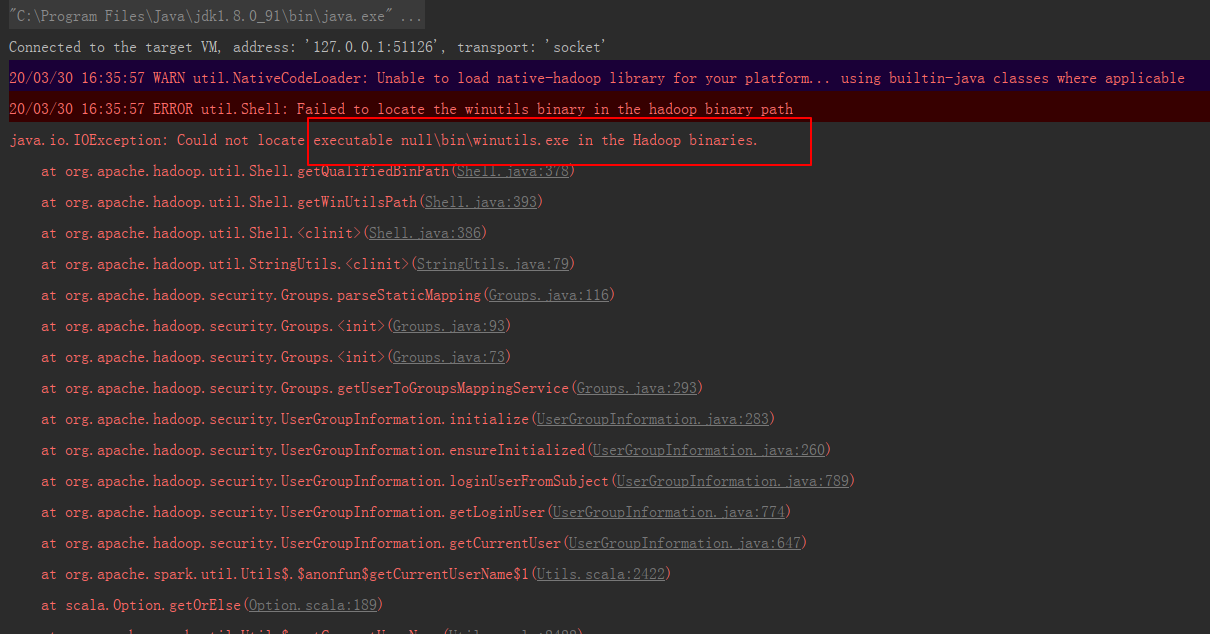
出现这个问题的原因是我们在windows上模拟开发环境,但并没有真正的搭建hadoop和spark
解决办法:当然也并不需要我们真的去搭建hadoop,其实不用理它也是可以运行下去的。winutils.exe下载,链接:https://pan.baidu.com/s/1YZDqd_MkOgnfQT3YM-V3aQ 提取码:xi44
放到任意的目录下,我这里是放到了D:\Server\hadoop\3.2.1\bin 目录下:
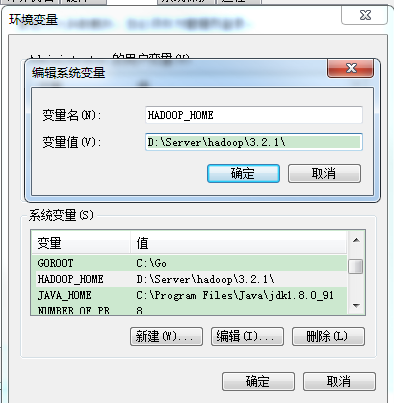
重启电脑后,右键执行main方法:
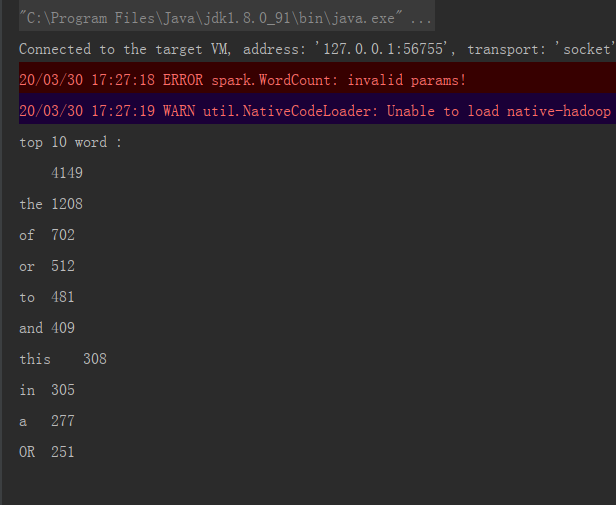
PS:
https://www.cnblogs.com/dhName/p/10579045.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号