【Python】urllib模块_url编解码 ,编码格式类似“%xxxx”
urlencode()、quote()、unquote()
urlencode 的参数是词典,它可以将key-value这样的键值对转换成我们想要的格式
urlencode 对字典或由两元素元组组成的列表进行码编码,将其转换为符合url规范的查询字符串
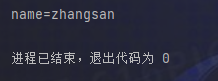
s = {"name": "zhangsan"} print(urllib.parse.urlencode(s))
执行结果
quote() 对string进行编码(只对一个字符串进行urlencode转换)
quote 对非ASCII编码的字符进行编码,默认进行UTF-8编码,不对“/”进行编码;(,errors=‘strict’(如果不能对string进行编码,rasie 引发一个 UnicodeEncodeErrort 错误)) 一般对请求url路径中非ASCII编码的字符(string)进行编码
url 请求链接不能包含非ASCII编码的字符,非ASCII编码的字符被认为是不安全的,所以进行编码。
safe = “/”,说明“/”是安全的,不用进行编码.。
url 中保留的字符:在url 中都认为是安全的可以不进行编码,safe包含的字符都不会被编码。
注意:dict格式转换为dict 编码与字符串编码不一致
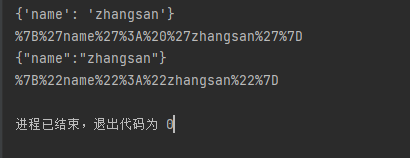
a = {"name":"zhangsan"}
b = quote(str(a))
c = '{"name":"zhangsan"}'
d = quote(c)
print(a)
print(b)
print(c)
print(d)
运行结果
java中标准url编码 空格为+
python中 quote_plus 将空格编码为 +, quote 将空格编码为 %20
示例
# -*- coding:utf-8 -*- import json import urllib.parse if __name__ == "__main__": text = {"name": "zhansan", "addr": "beijing", "remark": "备注"} text = json.dumps(text, ensure_ascii=False) print("quote 编码:", urllib.parse.quote(text)) print("quote_plus 编码:", urllib.parse.quote_plus(text))
执行结果

unquote() 对url进行解码,把类似"%xx"的字符替换成单个字符
data_dict = {"name": "wangjia", "address": "北京市西城区", "url": "https://www.baidu.com"}
undata_dict = "%7B%27name%27%3A%20%27wangjia%27%2C%20%27address%27%3A%20%27%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A5%BF%E5%9F%8E%E5%8C%BA%27%2C%20%27url%27%3A%20%27https%3A//www.baidu.com%27%7D"
# 对url进行编码
data_q = urllib.parse.quote(str(data_dict))
print("编码:", data_q)
# 对url进行解码
unresult = urllib.parse.unquote(undata_dict)
print("解码: ", unresult)
# 将URL中的键值对以连接符&划分
key_value_data = urllib.parse.urlencode(data_dict)
print("编码:", key_value_data)
编码: %7B%27name%27%3A%20%27wangjia%27%2C%20%27address%27%3A%20%27%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A5%BF%E5%9F%8E%E5%8C%BA%27%2C%20%27url%27%3A%20%27https%3A//www.baidu.com%27%7D
解码: {'name': 'wangjia', 'address': '北京市西城区', 'url': 'https://www.baidu.com'}
编码: name=wangjia&address=%E5%8C%97%E4%BA%AC%E5%B8%82%E8%A5%BF%E5%9F%8E%E5%8C%BA&url=https%3A%2F%2Fwww.baidu.com
进程已结束,退出代码为 0
拓展:from urllib.parse import urlparse, urlsplit
urlparse()
可以将 URL 解析成 ParseResult 对象。对象中包含了六个元素
urlsplit()
urlsplit() 函数也能对 URL 进行拆分,urlsplit() 并不会把 路径参数(params) 从 路径(path) 中分离出来。在不能使用urlparse()时 使用此函数。
如果万事开头难 那请结局一定圆满 @ Phoenixy
-------------------------------------------------------------------------------------
 浙公网安备 33010602011771号
浙公网安备 33010602011771号