吴恩达《深度学习》-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-第一周 机器学习(ML)策略(1)(ML strategy(1))-课程笔记
第一周 机器学习(ML)策略(1)(ML strategy(1))
1.1 为什么是 ML 策略?(Why ML Strategy?)
希望在这门课程中,可以教给一些策略,一些分析机器学习问题的方法,可以指引朝着最有希望的方向前进。这门课中,我会分享我在搭建和部署大量深度学习产品时学到的经验和教训。比如说,很多大学深度学习课程很少提到这些策略。事实上,机器学习策略在深度学习的时代也在变化,因为现在对于深度学习算法来说能够做到的事情,比上一代机器学习算法大不一样。
1.2 正交化(Orthogonalization)
所以正交化的概念是指,可以想出一个维度,这个维度你想做的是控制转向角,还有另一个维度来控制你的速度,那么你就需要一个旋钮尽量只控制转向角,另一个旋钮,在这个开车的例子里其实是油门和刹车控制了你的速度。但如果你有一个控制旋钮将两者混在一 起,比如说这样一个控制装置同时影响你的转向角和速度,同时改变了两个性质,那么就很难令你的车子以想要的速度和角度前进。然而正交化之后,正交意味着互成 90 度。设计出 正交化的控制装置,最理想的情况是和你实际想控制的性质一致,这样你调整参数时就容易得多。可以单独调整转向角,还有你的油门和刹车,令车子以你想要的方式运动。

在机器学习中,如果你可以观察你的系统,然后说这一部分是错的,它在训练集上做的不好、在开发集上做的不好、它在测试集上做的不好,或者它在测试集上做的不错,但如果说成在现实世界中不好,这就不是很好,因为它不是正交。必须弄清楚到底是什么地方出问题了,然后我们刚好有对应的旋钮,或者一组对应的旋钮,刚好可以解决那个问题,那个限制了机器学习系统性能的问题。 可以快速诊断出系统性能瓶颈到底在哪。还有找到你可以用的一组特定的旋钮来调整你的系统,来改善它特定方面的性能。
1.3 单一数字评估指标(Single number evaluation metric)
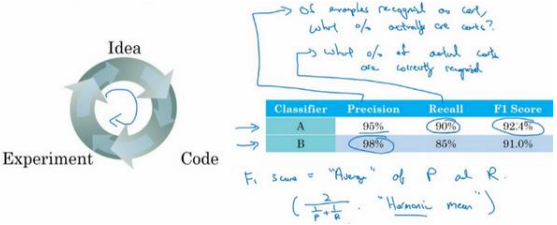
查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫。
查全率就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比。
使用查准率和查全率作为评估指标的时候,有个问题,如果分类器𝐴在查全率上表现更好,分类器𝐵在查准率上表现更好,你就无法判断哪个分类器更好。
所以并不推荐使用两个评估指标,查准率和查全率来选择一个分类器。
在机器学习文献中,结合查准率和查全率的标准方法是所谓的\(𝐹_1\)分数,\(𝐹_1\)分数的细节并不重要。但非正式的,可以认为这是查准率𝑃和查全率𝑅的平均值。这个指标在权衡查准率和查全率时有一些优势。
我发现很多机器学习团队就是有一个定义明确的开发集用来测量查准率和查全率, 再加上这样一个单一数值评估指标,有时叫单实数评估指标,能让你快速判断分类器𝐴或 者分类器𝐵更好。所以有这样一个开发集,加上单实数评估指标,你的迭代速度肯定会很快, 它可以加速改进您的机器学习算法的迭代过程。
1.4 满足和优化指标(Satisficing and optimizing metrics)
有时候设立满足和优化指标很重要:
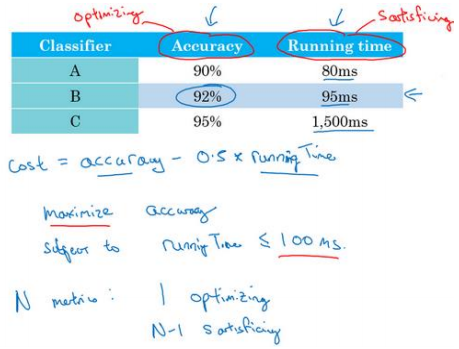
还可以做其他事情,可能选择一个分类器,能够最大限度提高准确度,但必须满足运行时间要求,就是对图像进行分类所需的时间必须小于等于 100 毫秒。在这种情 况下,想做的尽可能准确, 但是运行时间就是我们所说的满足指标,它必须足够好,它只需要小于 100 毫秒,达到之后,不在乎这指标有多好,或者至少不会那么在乎。
通过定义优化和满足指标,就可以给你提供一个明确的方式,去选择“最好的”分类器。
所以更一般地说,如果你要考虑𝑁个指标,有时候选择其中一个指标做为优化指标是合理的。所以你想尽量优化那个指标,然后剩下𝑁 − 1个指标都是满足指标,意味着只要它们达到一定阈值。

可能也需要顾及假阳性(false positive)的数量,就是在对智能音箱唤醒时,没有人在说这个触发词时,它被随机唤醒的概率有多大。
1.5 训练/开发/测试集划分(Train/dev/test distributions)
讨论如何设立开发集和测试集,开发(dev)集也叫做 (development set),有时称为保留交叉验证集(hold out cross validation set)。
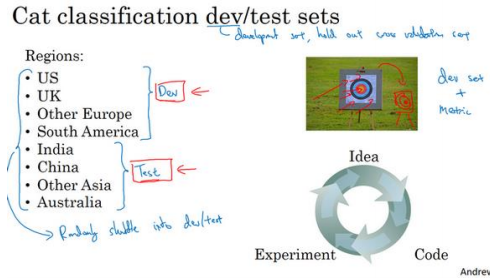
实际发生的事情是,这个团队花了三个月瞄准一个目标,三个月之后经理突然问" 你们试试瞄准那个目标如何?",这新目标位置完全不同,所以这件事对于这个团队来说非常崩溃。
为了避免图中情况,建议的是你将所有数据随机洗牌,放入开发集和测试集, 所以开发集和测试集都有来自八个地区的数据,并且开发集和测试集都来自同一分布,这分布就是你的所有数据混在一起。
希望通过在 同一分布中设立开发集和测试集,就可以瞄准你所希望的机器学习团队瞄准的目标。
1.6 开发集和测试集的大小(Size of dev and test sets)

总结一下,在大数据时代旧的经验规则,这个 70/30 不再适用了。现在流行的是把大量数据分到训练集,然后少量数据分到开发集和测试集,特别是当你有一个非常大的数据集时。
1.7 什么时候该改变开发/测试集和指标?(When to change dev/test sets and metrics)

算法𝐴由于某些原因,把很多色情 图像分类成猫了。从用户接受的角度来看,算法𝐵实 际上是一个更好的算法,因为它不让任何色情图像通过。在这种情况下,原来的指标错误地预测算法 A 是更好的算法这就发出了信号,你应该改变评估指标了,或者要改变开发集或测试集:
在这种情况下,你用的分类错误率指标可以写成这样:
其中一个修改评估指标的方法是加个权重项:
我们将这个称为\(𝑤^{ (𝑖)}\),其中如果图片𝑥 (𝑖)不是色情图片,则\(𝑤^{ (𝑖)}\)= 1。如果\(x^{ (𝑖)}\)是色情图 片,\(𝑤^{ (𝑖)}\)可能就是 10 甚至 100,这样你赋予了色情图片更大的权重,让算法将色情图分类为猫图时,错误率这个项快速变大。这个例子里,你把色情图片分类成猫这一错误的惩罚权重加大 10 倍。

加权的细节并不重要,粗略的结论是,如果你的评估指标无法正确评估好算法的排名,那么就需要花时间定义一个新的评估指标。这是定义评估指标的其中一种可能方式(上述加权法)。评估指标的 意义在于,准确告诉你已知两个分类器,哪一个更适合你的应用。
总体方针就是,如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大,那就应该更改你的指标或者你的开发测试集,让它们能更够好地反映你的算法需要处理好的数据。
1.8 为什么是人的表现?(Why human-level performance?)
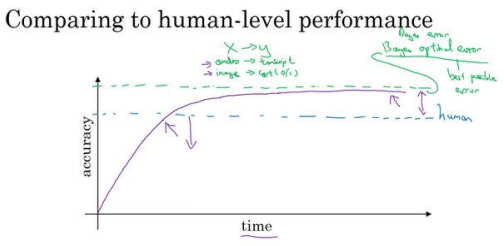
贝叶斯最优错误率有时写作 Bayesian,即省略 optimal,就是从𝑥到𝑦映射的理论最优 函数,永远不会被超越。所以你们应该不会感到意外,这紫色线,无论你在一个问题上工作多少年,你永远不会超越贝叶斯错误率,贝叶斯最佳错误率。

事实证明,机器学习的进展往往相当快,直到你超越人类的表现之前一直很快,当你超越人类的表现时,有时进展会变慢。我认为有两个原因,为什么当你超越人类的表现时,进 展会慢下来。一个原因是人类水平在很多任务中离贝叶斯最优错误率已经不远了,人们非常 擅长看图像,分辨里面有没有猫或者听写音频。所以,当你超越人类的表现之后也许没有太 多的空间继续改善了。但第二个原因是,只要你的表现比人类的表现更差,那么实际上可以 使用某些工具来提高性能。一旦你超越了人类的表现,这些工具就没那么好用了。
基础整理(一)贝叶斯决策论;二次判别函数;贝叶斯错误率;生成式模型的参数方法
1.9 可避免偏差(Avoidable bias)
在这个例子中,当你理解人类水平错误率,理解你对贝叶斯错误率的估计,你就可 以在不同的场景中专注于不同的策略,使用避免偏差策略还是避免方差策略。

1.10 理解人的表现(Understanding human-level performance)
“人类水平错误率”用来估计贝叶斯误差,那就是理论最低的错误率, 任何函数不管是现在还是将来,能够到达的最低值。
在定义人类水平错误率时,要弄清楚你的目标所在,如果要表明你可以超越单个人类,那么就有理由在某些场合部署你的系统,也许这个定义是合适的。但是如果您的目标是替代贝叶斯错误率,那么这个定义(经验丰富的医生团队——0.5%)才合适。
总结一下我们讲到的,如果你想理解偏差和方差,那么在人类可以做得很好的任务中, 你可以估计人类水平的错误率,你可以使用人类水平错误率来估计贝叶斯错误率。所以你到 贝叶斯错误率估计值的差距,告诉你可避免偏差问题有多大,可避免偏差问题有多严重,而 训练错误率和开发错误率之间的差值告诉你方差上的问题有多大,你的算法是否能够从训练 集泛化推广到开发集。

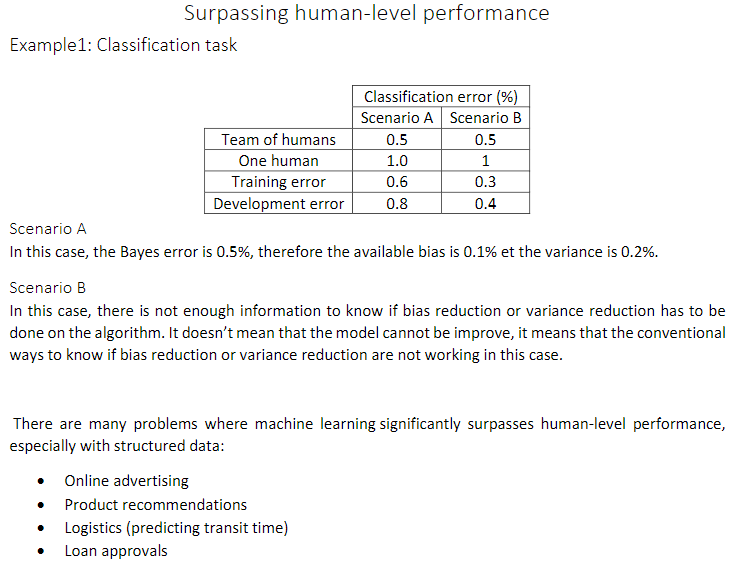
1.11 超过人的表现(Surpassing human- level performance)
1.12 改善你的模型的表现( Improving your model performance)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号