吴恩达《深度学习》-课后测验-第二门课 (Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization)-Week 2 - Optimization algorithms(第二周测验-优化算法)
Week 2 Quiz - Optimization algorithms(第二周测验-优化算法)
\1. Which notation would you use to denote the 3rd layer’s activations when the input is the 7th example from the 8th minibatch?(当输入从第八个 mini-batch 的第七个的样本的时候,你会用哪种符号表示第三层的激活?)
【 】\(𝑎^{[3]\{8\}(7)}\)
答案
Note: [𝑖]{𝑗}(𝑘)superscript means 𝑖-th layer, 𝑗-th minibatch, 𝑘-th example(注意:[𝑖]{𝑗}(𝑘)上标表示 第 𝑖层,第𝑗小块,第𝑘个样本)
\2. Which of these statements about mini-batch gradient descent do you agree with?(关于 minibatch 的说法哪个是正确的?)
【 】You should implement mini-batch gradient descent without an explicit for-loop over different mini-batches, so that the algorithm processes all mini-batches at the same time (vectorization).(在不同的 mini-batch 下,不需要显式地进行循环,就可以实现 mini-batch 梯度下降,从而使算法同时处理所有的数据(向量化))
【 】 Training one epoch (one pass through the training set) using mini-batch gradient descent is faster than training one epoch using batch gradient descent.(使用 mini-batch 梯度下降训练的 时间(一次训练完整个训练集)比使用梯度下降训练的时间要快。)
【 】One iteration of mini-batch gradient descent (computing on a single mini-batch) is faster than one iteration of batch gradient descent.(mini-batch 梯度下降(在单个 mini-batch 上计算)的一次迭代快于梯度下降的迭代。)
答案
【★】One iteration of mini-batch gradient descent (computing on a single mini-batch) is faster than one iteration of batch gradient descent.(mini-batch 梯度下降(在单个 mini-batch 上计 算)的一次迭代快于梯度下降的迭代。)
Note: Vectorization is not for computing several mini-batches in the same time.(注意:向量化不适用 于同时计算多个 mini-batch。)
\3. Why is the best mini-batch size usually not 1 and not m, but instead something inbetween?(为什么最好的 mini-batch 的大小通常不是 1 也不是 m,而是介于两者之间?)
【 】If the mini-batch size is 1, you lose the benefits of vectorization across examples in the mini-batch.(如果 mini-batch 大小为 1,则会失去 mini-batch 示例中向量化带来的的好处。)
【 】If the mini-batch size is m, you end up with batch gradient descent, which has to process the whole training set before making progress.(如果 mini-batch 的大小是 m,那么你会得到批量梯度下降,这需要在进行训练之前对整个训练集进行处理)
答案
全对
\4. Suppose your learning algorithm’s cost J, plotted as a function of the number of iterations, looks like this:(如果你的模型的成本𝑱随着迭代次数的增加,绘制出来的图如下,那么: )
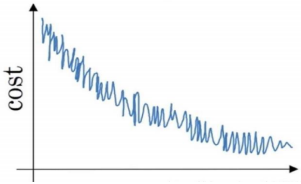
【 】If you’re using mini-batch gradient descent, this looks acceptable. But if you’re using batch gradient descent, something is wrong.(如果你使用的是 mini-batch 梯度下降,这看起来 是可以接受的。但是如果你使用的是批量梯度下降,那么你的模型就有问题。)
答案
对
Note: There will be some oscillations when you’re using mini-batch gradient descent since there could be some noisy data example in batches. However batch gradient descent always guarantees a lower 𝐽 before reaching the optimal.(注:使用 mini-batch 梯度下降会有一些振荡,因为 mini-batch 中可能会有一些噪音数据。 然而,批量梯度下降总是保证在到达最优值之前达到较低的𝐽。)
\5. Suppose the temperature in Casablanca over the first three days of January are the same:(假 设一月的前三天卡萨布兰卡的气温是一样的: )
Jan 1st: \(𝜃_1\) = 10(一月第一天: \(𝜃_1\) = 10)
Jan 2nd: \(𝜃_2\) ∗ 10(一月第二天: \(𝜃_2\) ∗ 10)
Say you use an exponentially weighted average with 𝜷 = 𝟎. 𝟓 to track the temperature: \(𝒗_𝟎\) = 𝟎, \(𝒗_𝒕 = 𝜷𝒗_𝒕 − 𝟏 + (𝟏 − 𝜷)𝜽_𝒕\) . If \(𝒗_𝟐\) is the value computed after day 2 without bias correction, and \(𝒗_𝟐\) 𝒄𝒐𝒓𝒓𝒆𝒄𝒕𝒆𝒅 is the value you compute with bias correction. What are these values?(假设您使用𝜷 = 𝟎. 𝟓的指数加权平均来跟踪温度:\(𝒗_𝟎 = 𝟎, 𝒗_𝒕 = 𝜷𝒗_𝒕 − 𝟏 + (𝟏 − 𝜷)𝜽_𝒕\)。 如果𝒗𝟐是在没有偏差修 正的情况下计算第 2 天后的值,并且\(𝒗_𝟐\) 𝒄𝒐𝒓𝒓𝒆𝒄𝒕𝒆𝒅是您使用偏差修正计算的值。 这些下面的值)
【 】\(𝑣_2 = 7.5, 𝑣_2 𝑐𝑜𝑟𝑟𝑒𝑐𝑡𝑒𝑑 = 10\)
答案
对
\6. Which of these is NOT a good learning rate decay scheme? Here, t is the epoch number.(下面哪一个不是比较好的学习率衰减方法?)
【 】$𝛼 = 𝑒^𝑡 ∗ 𝛼_0 $
答案
dei
Note: This will explode the learning rate rather than decay it.(注:这会使得学习率出现爆炸,而没 有衰减。)
\7. You use an exponentially weighted average on the London temperature dataset. You use the following to track the temperature: $𝒗_𝒕 = 𝜷𝒗_𝒕 − 𝟏 + (𝟏 − 𝜷)𝜽_𝒕 \(. The red line below was computed using 𝜷 = 𝟎. 𝟗. What would happen to your red curve as you vary 𝜷? (Check the two that apply)(您在伦敦温度数据集上使用指数加权平均值, 您可以使用以下公式来追踪 温度:\)𝒗_𝒕 = 𝜷𝒗_𝒕 − 𝟏 + (𝟏 − 𝜷)𝜽_𝒕$。 下面的红线使用的是𝜷 = 𝟎. 𝟗来计算的。 当你改变𝜷时, 你的红色曲线会怎样变化? )
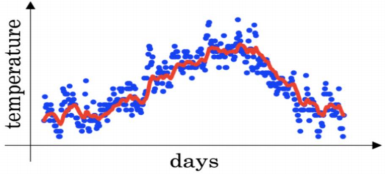
【 】Increasing 𝛽 will shift the red line slightly to the right.(增加𝛽会使红线稍微向右移动。)
【 】Decreasing 𝛽 will create more oscillation within the red line.(减少𝛽会在红线内产生更多 的振荡。)
答案
全对
\8. Consider this figure:(看一下这个图: )These plots were generated with gradient descent; with gradient descent with momentum (𝜷 = 𝟎. 𝟓) and gradient descent with momentum (𝜷 = 𝟎.𝟗). Which curve corresponds to which algorithm?(这些图是由梯度下降产生的; 具有动量梯 度下降(𝜷 = 𝟎. 𝟓)和动量梯度下降(𝜷 = 𝟎. 𝟗)。 哪条曲线对应哪种算法? )
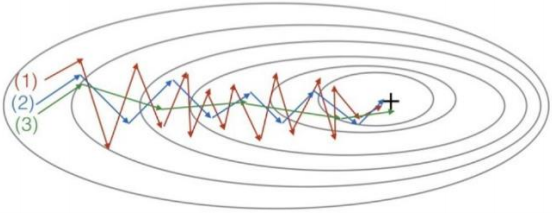
【 】 (1) is gradient descent. (2) is gradient descent with momentum (small 𝛽). (3) is gradient descent with momentum (large 𝛽)((1)是梯度下降。 (2)是动量梯度下降(𝛽值比较小)。 (3)是动量梯度下降(𝛽比较大))
答案
对
\9. Suppose batch gradient descent in a deep network is taking excessively long to find a value of the parameters that achieves a small value for the cost function$ 𝑱(𝑾^{[𝟏]} ,𝒃 ^{[𝟏]} ,… ,𝑾^{[𝑳]} , 𝒃^{[𝑳]} )\(. Which of the following techniques could help find parameter values that attain a small value for 𝑱? (Check all that apply)(假设在一个深度学习网络中批处理梯度下降花费了太多的时间来 找到一个值的参数值,该值对于成本函数\) 𝑱(𝑾^{[𝟏]} ,𝒃 ^{[𝟏]} ,… ,𝑾^{[𝑳]} , 𝒃^{[𝑳]} )$来说是很小的值。 以下哪些方法可以帮助找到𝑱值较小的参数值?)
【 】 Try using Adam(尝试使用 Adam 算法)
【 】 Try better random initialization for the weights(尝试对权重进行更好的随机初始化)
【 】 Try tuning the learning rate 𝛼(尝试调整学习率𝛼)
【 】Try mini-batch gradient descent(尝试 mini-batch 梯度下降)
【 】Try initializing all the weights to zero(尝试把权值初始化为 0)
答案
最后一个错误,其余全对
\10. Which of the following statements about Adam is False?(关于 Adam 算法,下列哪一个陈 述是错误的?)
【 】Adam should be used with batch gradient computations, not with mini-batches.(Adam 应该用于批梯度计算,而不是用于 mini-batch。)
答案
错误
Note: Adam could be used with both.(注: Adam 可以同时使用。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号