正则表达式相关知识总结
一、正则的创建
- 字面量创建
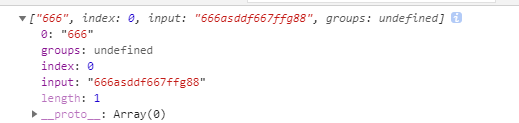
let str = "666asddf667ffg88"; let reg = /\d+/; let res = str.match(reg); console.log(res);
- 通过构造函数
let str = "666asddf667ffg88"; let a = "df"; let reg = new RegExp(a,"g"); let res = str.match(reg); console.log(res);
通过字面量的方式创建性能更好,但是需要使用变量匹配时须采用构造函数的形式
二、正则的匹配方法
字符串方法
- match
- search :匹配第一个符合结果的索引值位置;如果找不到 就返还-1;
- replace
let res = str.replace(reg,"*"); // 多个字符只会显示一个*
let res = str.replace(reg,function(arg){ // *的数量与字符数相等
return "*".repeat(arg.length);
})
- split
正则对象下的方法
- test:返回 Boolean,查找对应的字符串中是否存在模式。test常用在if语句中
- exec:查找并返回当前的匹配结果,并以数组的形式返回
var str = "1a1b1c";
var reg = new RegExp("1.", "");
var arr = reg.exec(str);
如果不存在模式,则 arr 为 null,否则 arr 总是一个长度为 1 的数组,其值就是当前匹配项,所以在全局模式下(/g)需要多次执行exec方法才能得到后面匹配的值。arr 还有三个属性:index 当前匹配项的位置;lastIndex 当前匹配项结束的位置(index + 当前匹配项的长度);input 如上示例中 input 就是 str。
var re = /^[1-9]\d{4,10}$/gi;
var str = "123456789";
console.log(re.test(str)); //返回true
console.log(re.lastIndex); // 9
console.log(re.test(str)); //返回false
console.log(re.lastIndex); // 9
每个正则表达式都有一个 lastIndex 属性,用于记录上一次匹配结束的位置。
想要结果一致,可以将正则表达式的 lastIndex 属性设置为0,或者去掉全局模式g,g就是继续往下的意思
三、元字符与字符集合
元字符: 正则表达式中有特殊含义的非字母字符;
字符类别(Character Classes)
.匹配行结束符(\n \r \u2028 或 \u2029)以外的任意单个字符, 在 `字符集合(Character Sets)` 中,. 将失去其特殊含义,表示的是原始值
\ 转义符,它有两层含义
- 表示下一个具有特殊含义的字符为字面值
- 表示下一个字符具有特殊含义(转义后的结果是元字符内约定的)
- \d 匹配任意一个阿拉伯数字的字符 - \D 匹配任意一个非阿拉伯数字的字符 - \w 匹配任意一个(字母、数字、下划线)的字符 - \W 匹配任意一个非(字母、数字、下划线)的字符 - \s 匹配一个空白符,包括空格、制表符、换页符、换行符和其他 Unicode 空格 - \S 匹配一个非空白符 - \t 匹配一个水平制表符(tab) - \r 匹配一个回车符(carriage return) - \n 匹配一个换行符(linefeed) - \v 匹配一个垂直制表符(vertical tab) - \f 匹配一个换页符(form-feed)
字符集合也叫字符组。匹配集合中的任意一个字符。你可以使用连字符'-'指定一个范围
- `[xyz]` 是一个反义或补充字符集,也叫反义字符组。也就是说,它匹配任意不在括号内的字符。你也可以通过使用连字符 '-' 指定一个范围内的字符
菜鸟教程详细元字符:https://www.runoob.com/regexp/regexp-metachar.html
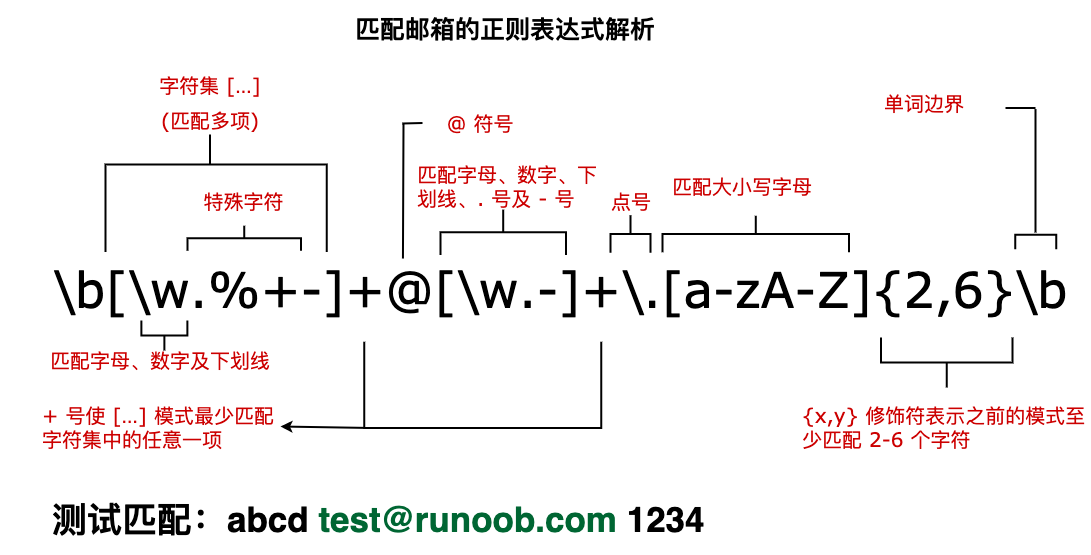
四、边界
零宽: 只匹配位置, 不匹配字符,
在JS中, 单词的定义就是\w, 非单词的定义就是\W
- ^ - 匹配输入开始。如果多行(multiline)标志被设为 true,该字符也会匹配一个断行(line break)符后的开始处 - $ - 匹配输入结尾。如果多行(multiline)标志被设为 true,该字符也会匹配一个断行(line break)符的前的结尾处 - \b - 匹配一个零宽单词边界(zero-width word boundary),单词边界就是单词和符号之间的边界,非 \w 都被称为边界
- \B - 匹配一个非零宽单词边界(zero-width word boundary) \B=[^\b]
五、分组与零宽断言
- (子项)
- 可以使用 () 对表达式进行分组,类似数学中分组,也称为子项
let str = "abbfdababljljab";
let reg1 = /ab{2}/g; //abb
let res1 = str.replace(reg1,"*");
console.log(res1); // *fdababljljab
let reg2 = /(ab){2}/g; //abab
let res2 = str.replace(reg2,"*");
console.log(res2); // abbfd*ljljab
索引分组
命名分组: (?<name>...)
// 命名分组;?<分组名> ES2018新增特性; let str = "$name=zhangsan&age=20"; let reg = /\$(?<str>\w+)/; let res = str.match(reg); console.log(res.groups.str);
groups属性:
- 捕获匹配
- 具有捕获(capturing)特性,即会把匹配结果保存到(子项结果)中
- (x)
- 非捕获匹配
- 不具有捕获(capturing)特性,即不会把匹配结果保存到(子项结果)中
- (?:x)
零宽断言/预查(Assertions):零正向(后面) 负向(前面) ---》 肯定断言、否定断言 ;
用于指定查找在某些内容(但并不包括这些内容)之前或之后的内容
// es2018
// 正向肯定断言;
let str = "iphone3iphone4iphone11iphoneNumber";
// iphone 换成“苹果”;
let reg = /iphone(?=\d{1,2})/g;
let res = str.replace(reg,"苹果");
console.log(res); //苹果3苹果4苹果11iphoneNumber
// 正向否定断言;
let str = "iphone3iphone4iphone11iphoneNumber";
// iphone 换成“苹果”;
let reg = /iphone(?!\d{1,2})/g;
let res = str.replace(reg,"苹果");
console.log(res); // iphone3iphone4iphone11苹果Number
// 负向肯定断言;
let str = "10px20px30pxipx";
// px-->像素;
let reg = /(?<=\d{2})px/g;
let res = str.replace(reg,"像素");
console.log(res); // 10像素20像素30像素ipx
// 负向否定断言;
let str = "10px20px30pxipx";
// px-->像素;
let reg = /(?<!\d{2})px/g;
let res = str.replace(reg,"像素");
console.log(res); // 10px20px30pxi像素
- 捕获与零宽断言的区别
- 捕获:匹配的内容出现在结果中但不出现在子项结果中
- 零宽断言:完全不会出现在结果
六、反向引用
- \n
- 这里的 n 表示的是一个变量,值为一个数字,指向正则表达式中第 n 个括号(从左开始数)中匹配的子字符串
$1,$2表达的是小括号分组里面的内容:$1是第一个小括号里的内容,$2是第二个小括号里面的内容,依此类推。
// 转换时间格式:2019-10-19 ----> 19/10/2019;
// 反向引用;
let mytime = "2019-10-19";
let reg = /(\d{4})-(\d{1,2})-(\d{1,2})/g;
let res = mytime.replace(reg,"$3/$2/$1");
console.log( RegExp.$1 ); // 2019
console.log(res); // 19/10/2019
七、数量词汇
- x{n}
- n 是一个正整数。前面的模式 x 连续出现 n 次时匹配
- x{n,m}
- n 和 m 为正整数。前面的模式 x 连续出现至少 n 次,至多 m 次时匹配
- x{n,}
- n 是一个正整数。前面的模式 x 连续出现至少 n 次时匹配
- x*
- 匹配前面的模式 x 0 或多次
- x+
- 匹配前面的模式 x 1 或多次。等价于 {1,}
- x?
- 匹配前面的模式 x 0 或 1 次
- x|y
- 匹配 x 或 y
八、匹配模式
- g
- global,全局模式:找到所有匹配,而不是在第一个匹配后停止
- i
- ignore,忽略大小写模式:匹配不区分大小写
- m
- multiple,多行模式:将开始和结束字符(^和$)视为在多行上工作,而不只是匹配整个输入字符串的最开始和最末尾处
- s
- dotAll / singleline模式:. 可以匹配换行符
- u
- unicode,unicode模式:匹配unicode字符集
```js
console.log(/^.$/.test("\uD842\uDFB7"));
console.log(/^.$/u.test("\uD842\uDFB7"));
```
- y
- sticky,粘性模式:匹配正则中lastIndex属性指定位置的字符,并且如果没有匹配也不尝试从任何后续的索引中进行匹配
-正则工具 http://regexper.com
