
| 这个作业属于哪个课程 | <至诚软工实践F班> |
|---|---|
| 这个作业要求在哪里 | <第二次作业:个人编程> |
| 这个作业的目标 | <熟悉fiddler抓包工具,并掌握其使用方法> |
| Github 地址 | <PhoebeLana的GitHub地址> |
*任务
【必做】基础:使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息(具体如下图所示)。控制台输出即可。
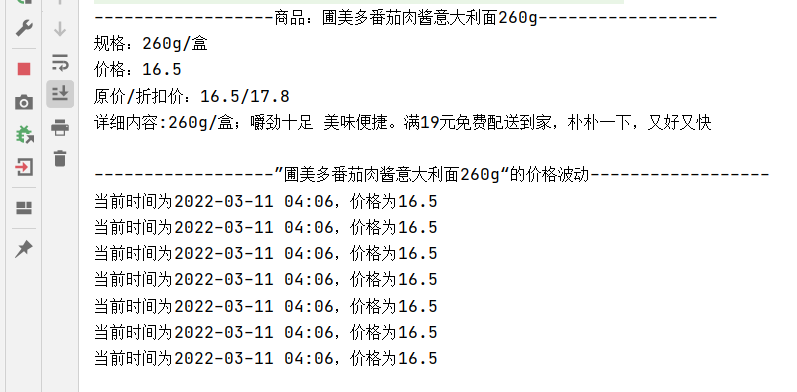
1、解题思路
- 刚开始看到题目的时候,就先下载安装了fiddler软件,上网搜索配置教程,并尝试寻找类似例子开始爬取。发现朴朴没有网页版,尝试是否能连接手机APP,进行爬取数据信息。发现难度对我本人来说有些太大了,参考了一些已提交同学的方法,爬取微信小程序PC端中的朴朴小程序。
- 思路:
①先配置好fiddle,进入微信PC端朴朴小程序;
②打开"潮福前味网红草莓慕斯盒子150g"产品页面,实行监控;
③从fiddler中获取网页信息,用浏览器打开URL地址;
④使用下载好的PyCharm编写代码,控制台输出实时监控结果;
⑤使用Git Bash将文件上传至GitHub; - 之前有学习过Python,但是没有接触过爬虫,所以对爬虫这块是比较陌生的,刚开始有些迷茫,找不到方向,不知道要从哪里下手。通过同学的指导帮助、自己在网络上搜索查找相关教程,磕磕绊绊地完成了任务。
2、设计实现
-
1)因为校园网和fiddler冲突,关闭校园网,使用手机热点

-
2)配置fiddler,隐藏通道包和一些304包

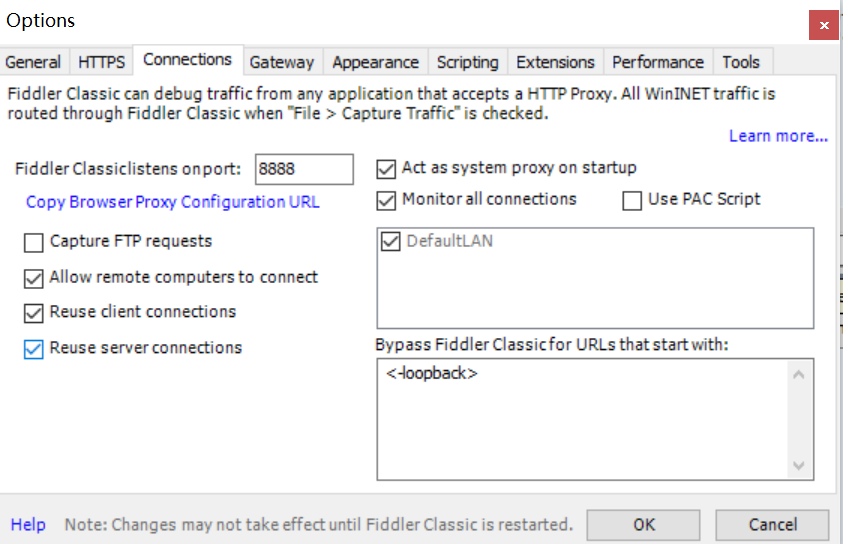
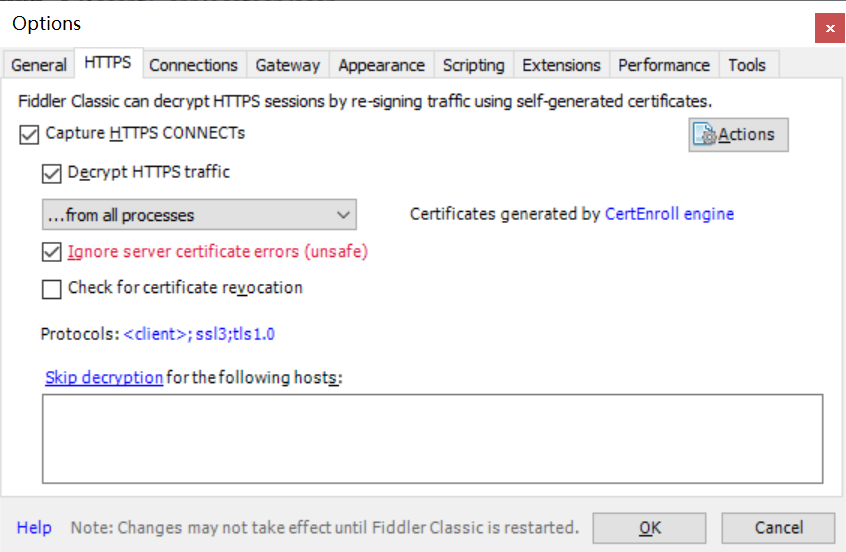
-
3)打开fiddler软件,进入微信PC端的朴朴小程序,对"潮福前味网红草莓慕斯盒子150g"产品进行监控

-
4)获取需要的信息
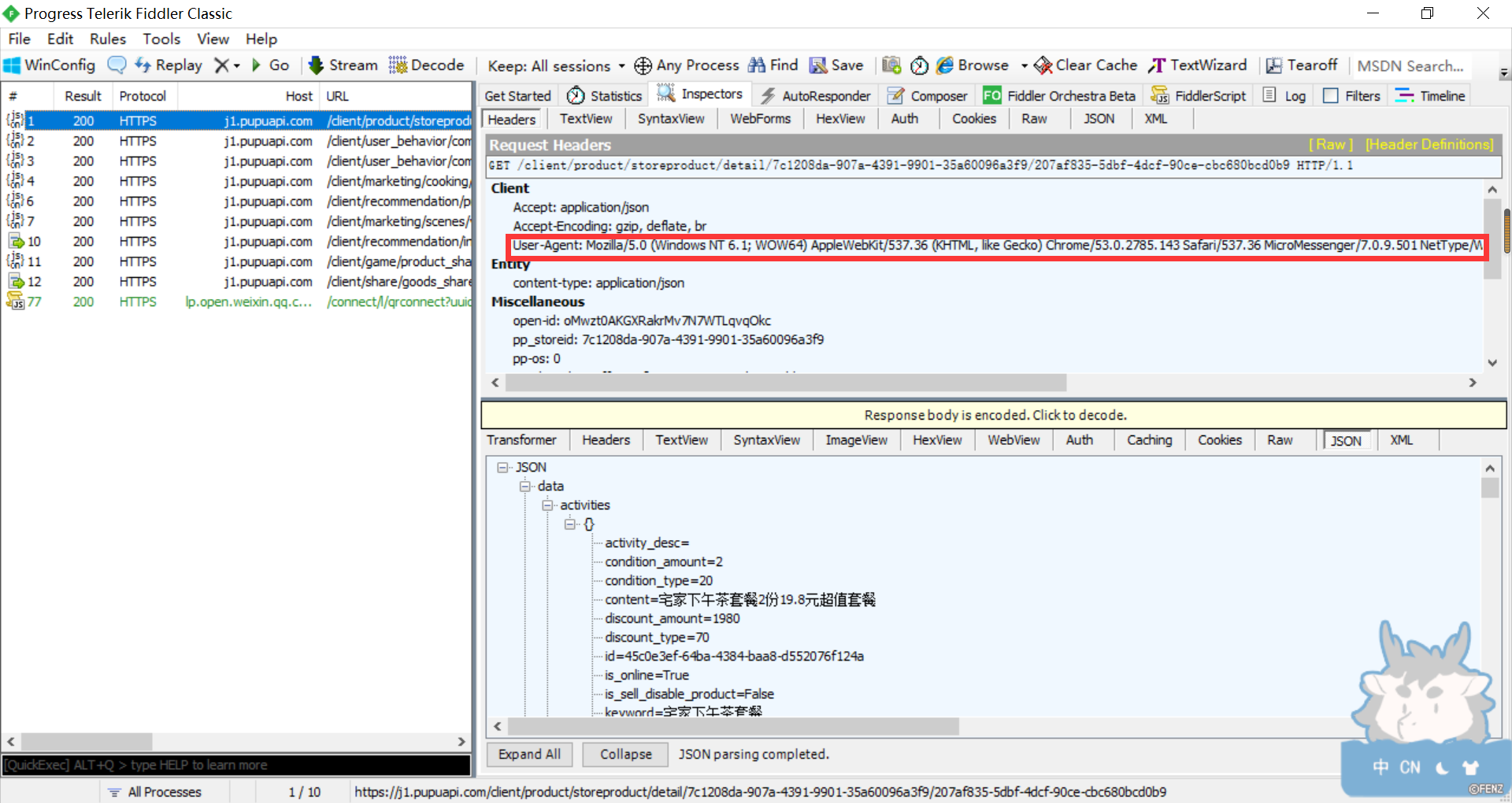
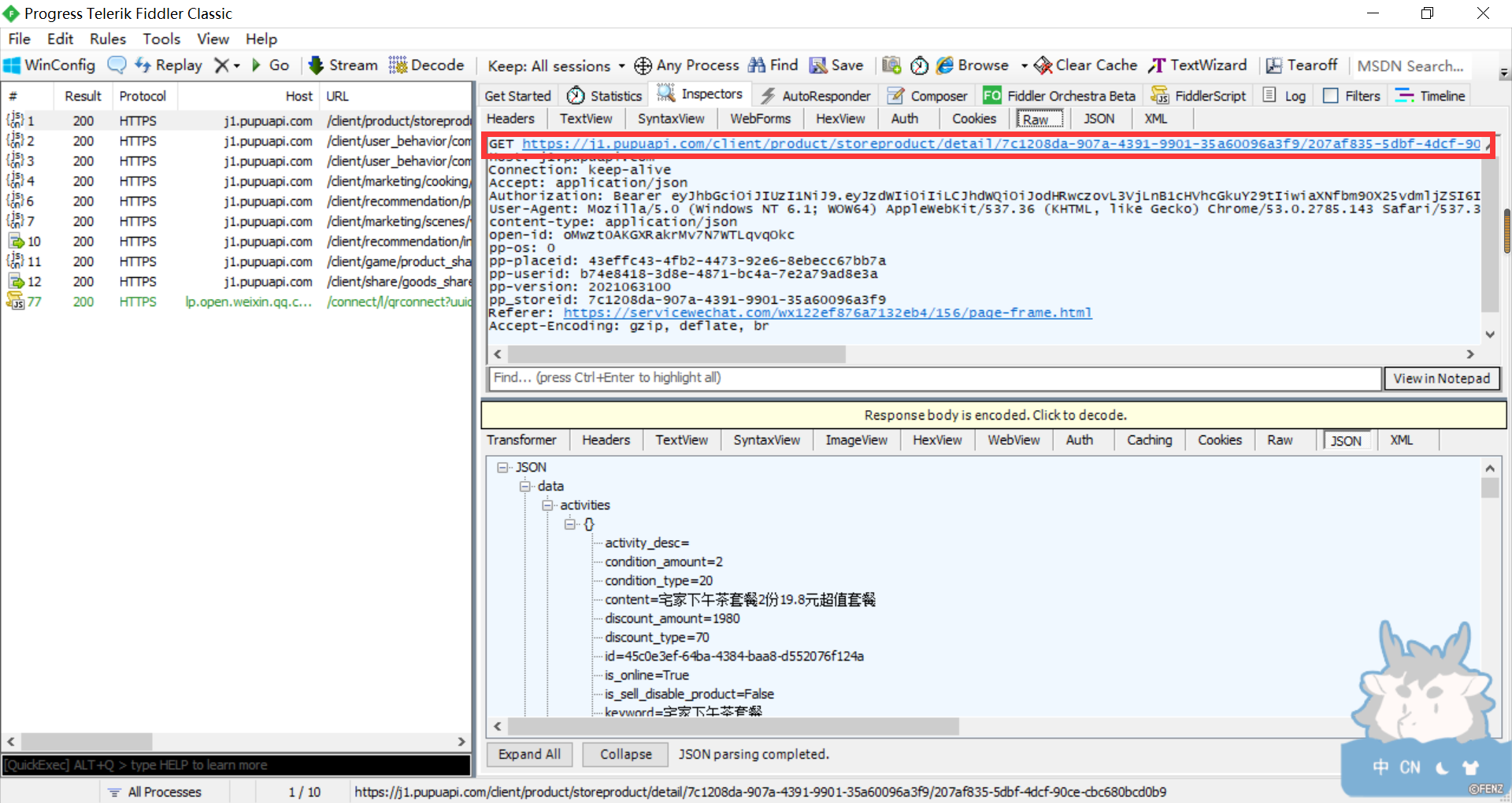
-
5)使用火狐浏览器打开URL地址
-
JSON:

-
原始数据:
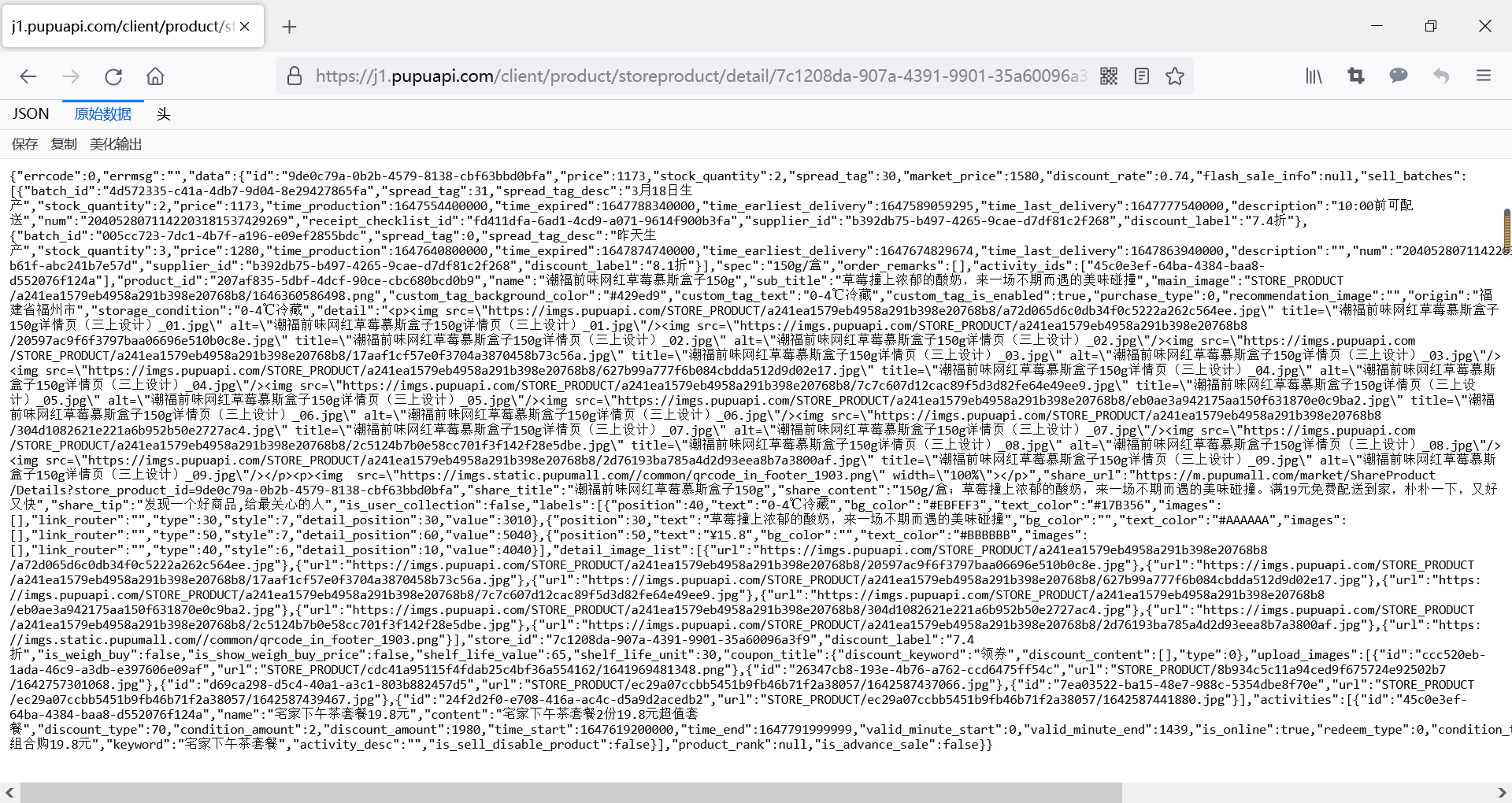
-
头:

-
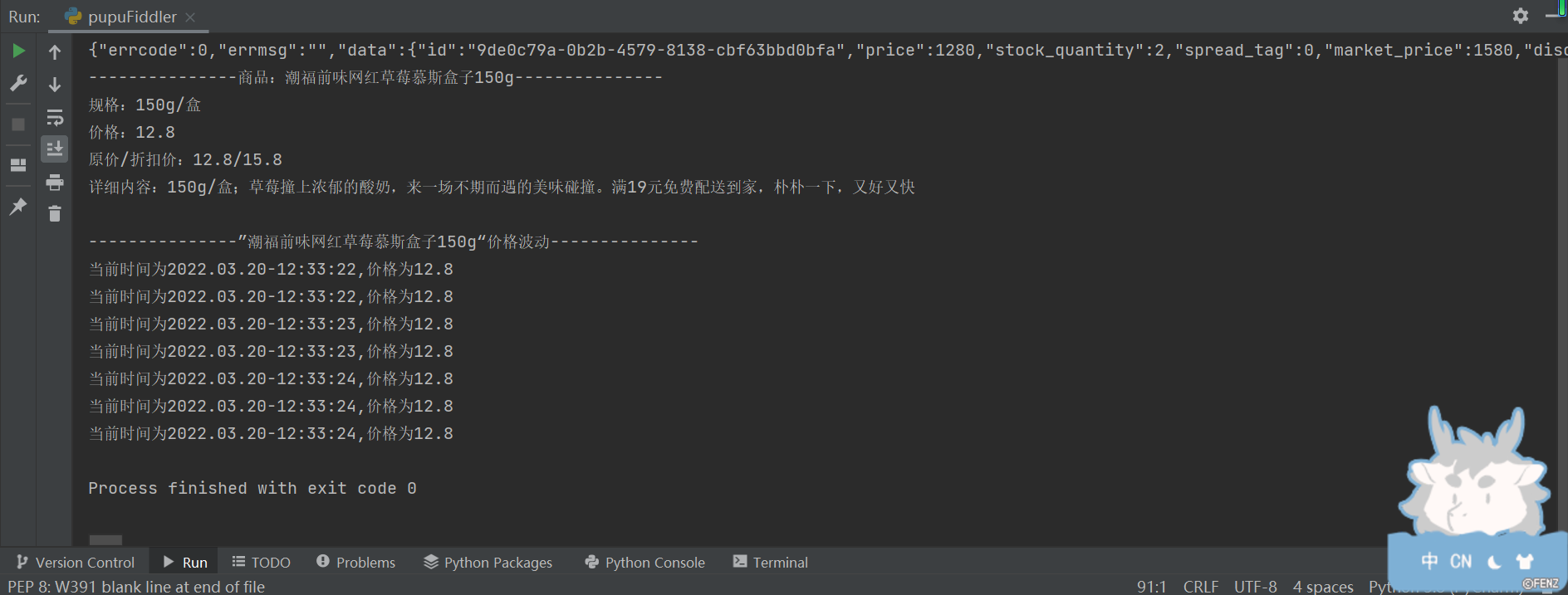
3、运行结果
4、代码展示
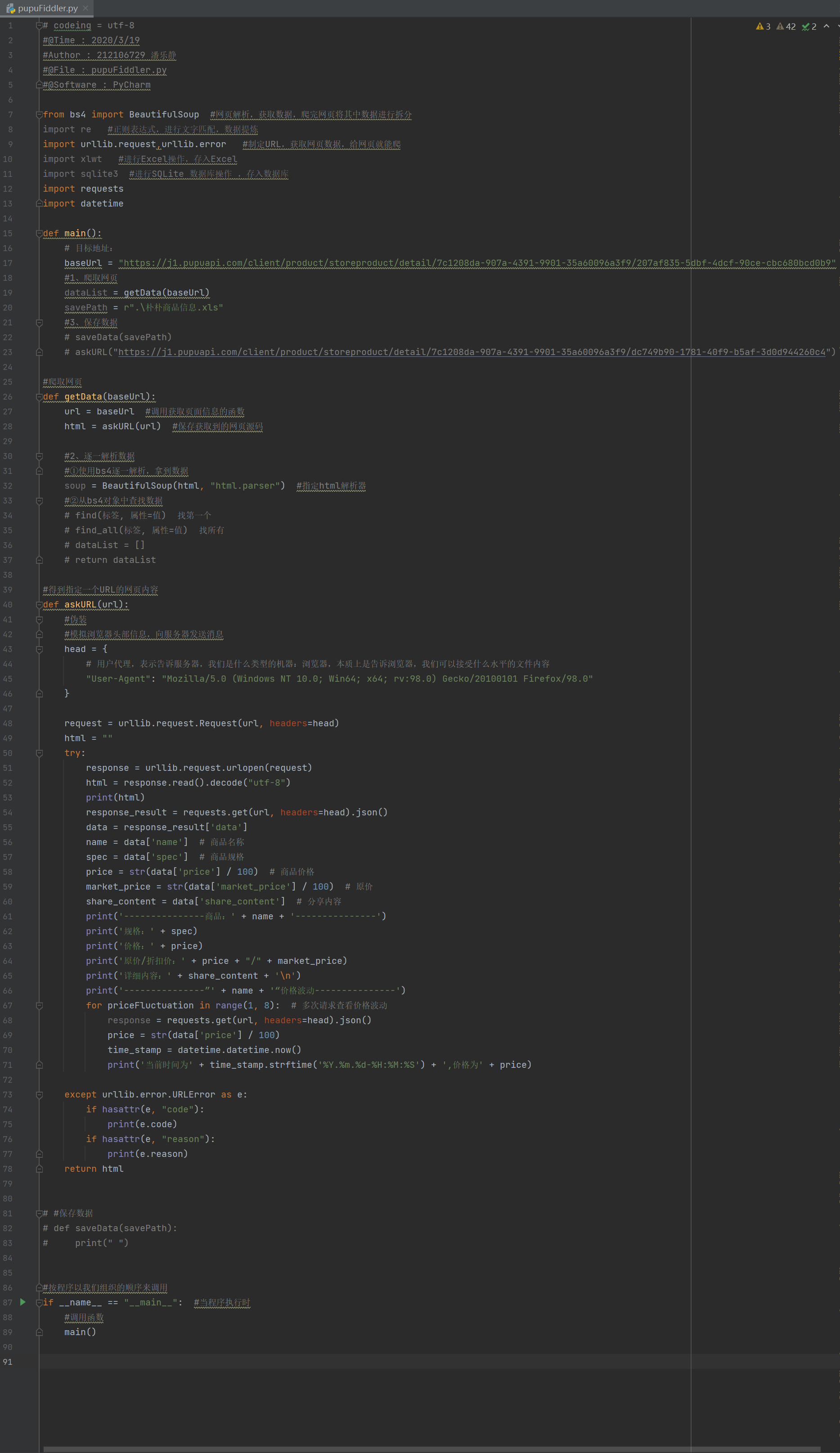
# codeing = utf-8
#@Time : 2020/3/19
#Author : 212106729 潘乐静
#@File : pupuFiddler.py
#@Software : PyCharm
from bs4 import BeautifulSoup #网页解析,获取数据,爬完网页将其中数据进行拆分
import re #正则表达式,进行文字匹配,数据提炼
import urllib.request,urllib.error #制定URL,获取网页数据,给网页就能爬
import xlwt #进行Excel操作,存入Excel
import sqlite3 #进行SQLite 数据库操作 ,存入数据库
import requests
import datetime
def main():
# 目标地址:
baseUrl = "https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/207af835-5dbf-4dcf-90ce-cbc680bcd0b9"
#1、爬取网页
dataList = getData(baseUrl)
savePath = r".\朴朴商品信息.xls"
#3、保存数据
# saveData(savePath)
# askURL("https://j1.pupuapi.com/client/product/storeproduct/detail/7c1208da-907a-4391-9901-35a60096a3f9/dc749b90-1781-40f9-b5af-3d0d944260c4")
#爬取网页
def getData(baseUrl):
url = baseUrl #调用获取页面信息的函数
html = askURL(url) #保存获取到的网页源码
#2、逐一解析数据
#①使用bs4逐一解析,拿到数据
soup = BeautifulSoup(html, "html.parser") #指定html解析器
#②从bs4对象中查找数据
# find(标签, 属性=值) 找第一个
# find_all(标签, 属性=值) 找所有
# dataList = []
# return dataList
#得到指定一个URL的网页内容
def askURL(url):
#伪装
#模拟浏览器头部信息,向服务器发送消息
head = {
# 用户代理,表示告诉服务器,我们是什么类型的机器:浏览器,本质上是告诉浏览器,我们可以接受什么水平的文件内容
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0"
}
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)
response_result = requests.get(url, headers=head).json()
data = response_result['data']
name = data['name'] # 商品名称
spec = data['spec'] # 商品规格
price = str(data['price'] / 100) # 商品价格
market_price = str(data['market_price'] / 100) # 原价
share_content = data['share_content'] # 分享内容
print('---------------商品:' + name + '---------------')
print('规格:' + spec)
print('价格:' + price)
print('原价/折扣价:' + price + "/" + market_price)
print('详细内容:' + share_content + '\n')
print('---------------”' + name + '“价格波动---------------')
for priceFluctuation in range(1, 8): # 多次请求查看价格波动
response = requests.get(url, headers=head).json()
price = str(data['price'] / 100)
time_stamp = datetime.datetime.now()
print('当前时间为' + time_stamp.strftime('%Y.%m.%d-%H:%M:%S') + ',价格为' + price)
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# #保存数据
# def saveData(savePath):
# print(" ")
#按程序以我们组织的顺序来调用
if __name__ == "__main__": #当程序执行时
#调用函数
main()
5、上传至GitHub
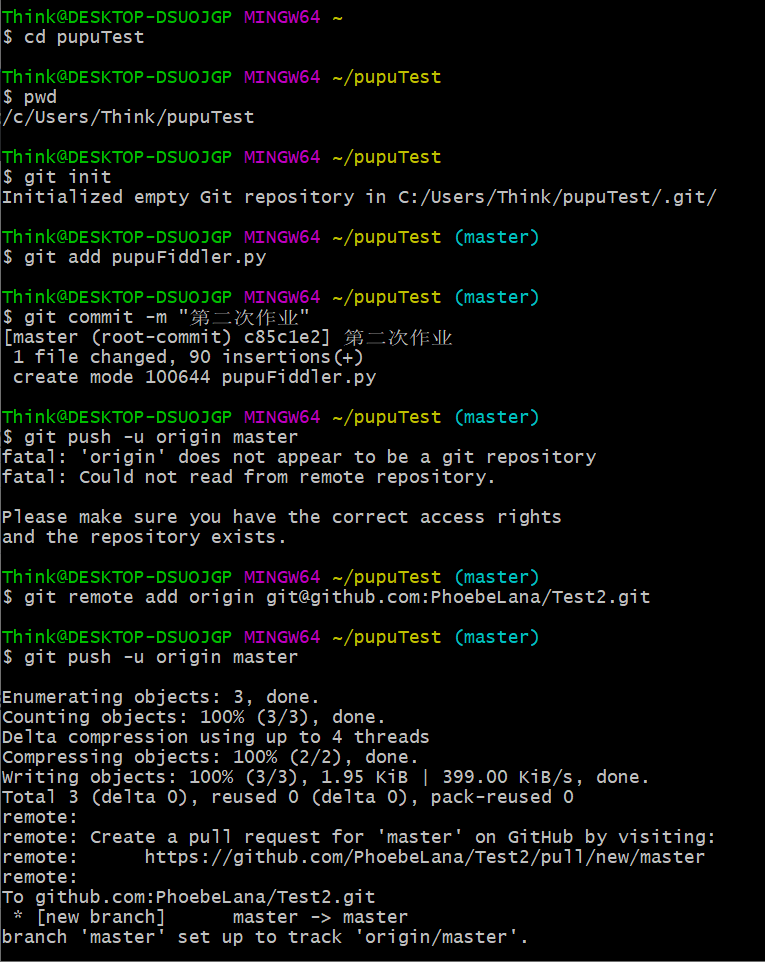
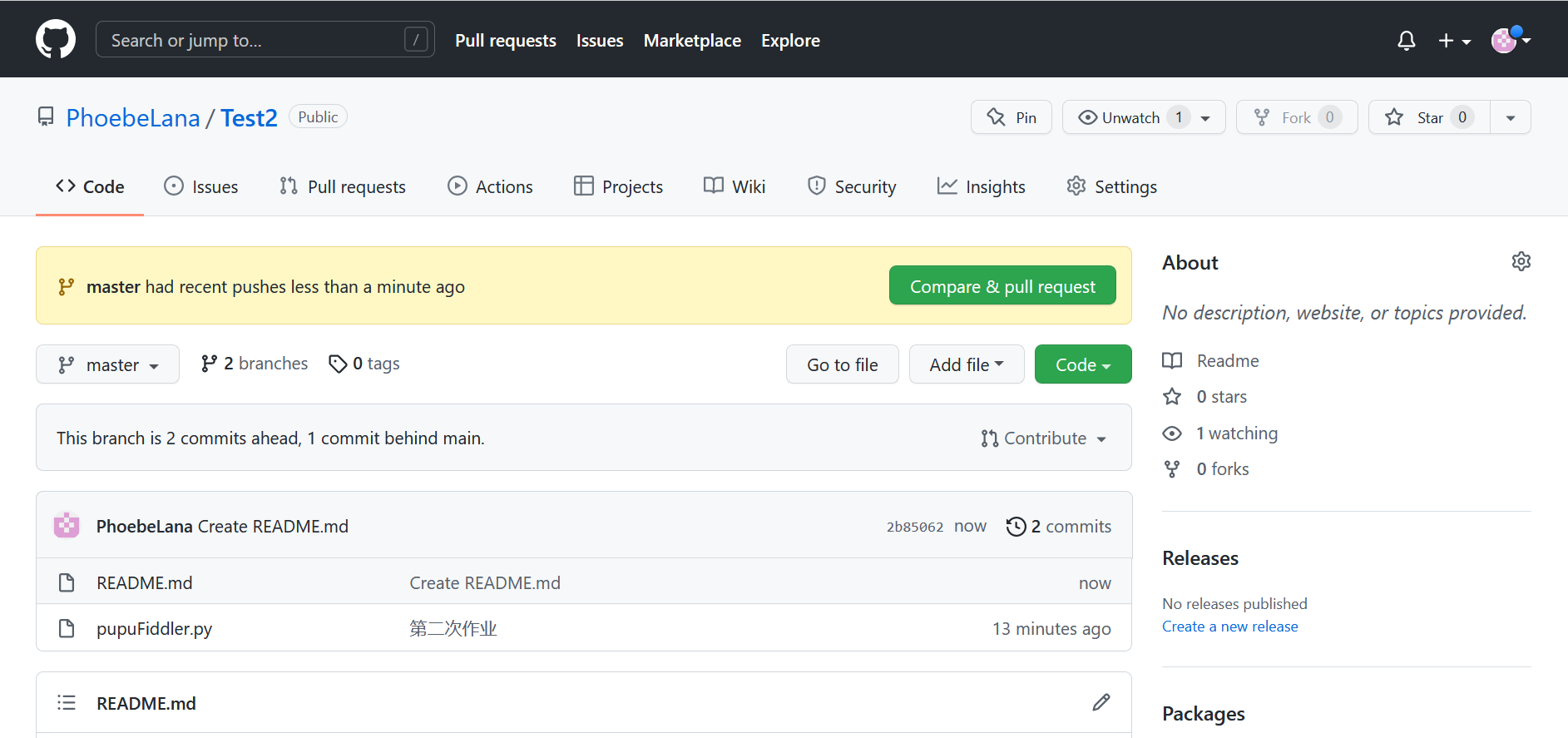
6、参考材料
- 云班课PPT
https://viewer.mosoteach.cn/viewer?token=1e9e8bd99a41d323b1f6a8810268808b&screenx=false&app_id=MTWEB&app_version=5.3.3&location=- 哔哩哔哩《全网最全Fiddler抓包教程,学完别去做坏事~》
https://www.bilibili.com/video/BV17X4y1P77P?p=2&spm_id_from=333.1007.top_right_bar_window_history.content.click- 哔哩哔哩《Python爬虫编程基础5天速成(2021全新合集)Python入门+数据分析》
https://www.bilibili.com/video/BV12E411A7ZQ?p=1- 哔哩哔哩《【2021年最新录制】Python 3 爬虫、数据清洗与可视化实战》
https://www.bilibili.com/video/BV1CX4y1374d?spm_id_from=333.880.my_history.page.click- 博客园《Python获取当前时间》
https://www.cnblogs.com/ziyuyue/p/13154772.html- 《廖雪峰git教程》
https://www.liaoxuefeng.com/wiki/896043488029600- 还参考了一下其他同学的作业、询问了一些同学的做题方法,为一头雾水的自己提供一些思路,十分感谢大家对我的帮助

 浙公网安备 33010602011771号
浙公网安备 33010602011771号