python从数据库取数据后写入excel 使用pandas.ExcelWriter设置单元格格式
用python从数据库中取到数据后,写入excel中做成自动报表,ExcelWrite默认的格式一般来说都比较丑,但workbook提供可以设置自定义格式,简单记录个demo,供初次使用者参考。
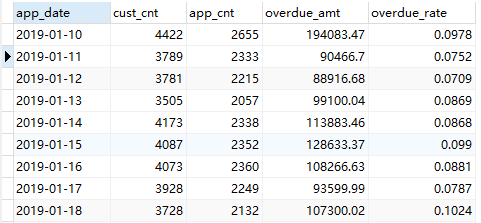
一、 取几列数据长下面这样,数字我随便编的,不用在意:
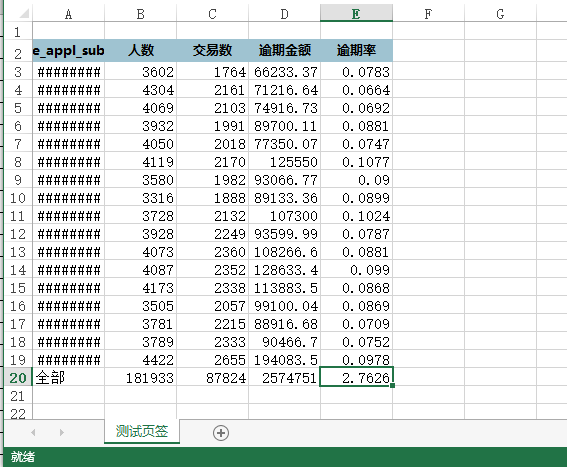
二、ExcelWriter写入后默认格式长下面这样,字体丑,宽度不够,没有百分比格式:
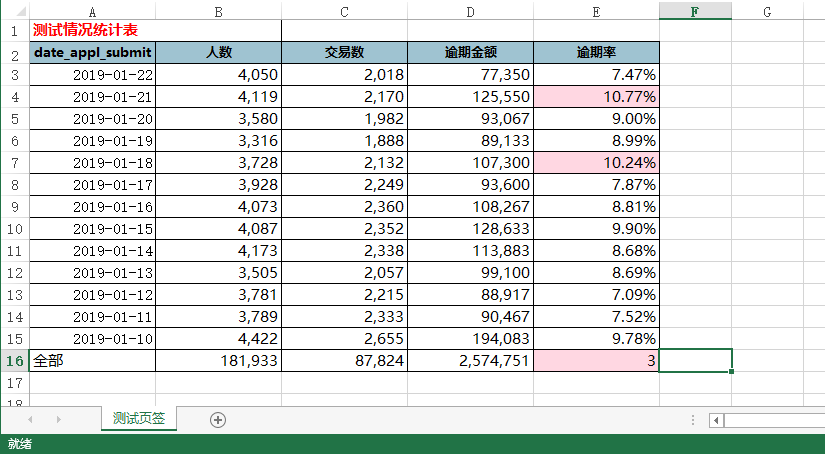
三、设置格式后保存结果,好看多了:
四、好了,实现在下面代码里有注释
# -*- coding: utf-8 -*-
import pandas as pd
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from mlutil.database import MySQLDB
from datetime import datetime, timedelta
def report():
# 1.取数据
m = MySQLDB('/data/wowo/password.p', 'mysql')
m.connect()
df1 = pd.DataFrame(m.query('select * from table1'))
df1 = df1[[u'app_date',
u'cust_cnt',
u'app_cnt',
u'overdue_amt',
u'overdue_rate',
]]
df1.sort_values(by='app_date', ascending=False, inplace=True)
df1 = df1.set_index(u'app_date')
df1.loc[u'全部'] = df1.apply(lambda x: x.sum())
df1.columns = [u'人数',
u'交易数',
u'逾期金额',
u'逾期率']
df1 = df1.reset_index()
# 2.保存至excel文件
t = datetime.now().date() - timedelta(days=1)
writer = pd.ExcelWriter(
u'/home/wowo/daily_report/测试_%d%02d%02d.xlsx' % (t.year, t.month, t.day))
workbook = writer.book
# 3.设置格式
fmt = workbook.add_format({"font_name": u"微软雅黑"})
percent_fmt = workbook.add_format({'num_format': '0.00%'})
amt_fmt = workbook.add_format({'num_format': '#,##0'})
border_format = workbook.add_format({'border': 1})
note_fmt = workbook.add_format(
{'bold': True, 'font_name': u'微软雅黑', 'font_color': 'red', 'align': 'left', 'valign': 'vcenter'})
date_fmt = workbook.add_format({'bold': False, 'font_name': u'微软雅黑', 'num_format': 'yyyy-mm-dd'})
date_fmt1 = workbook.add_format(
{'bold': True, 'font_size': 10, 'font_name': u'微软雅黑', 'num_format': 'yyyy-mm-dd', 'bg_color': '#9FC3D1',
'valign': 'vcenter', 'align': 'center'})
highlight_fmt = workbook.add_format({'bg_color': '#FFD7E2', 'num_format': '0.00%'})
# 4.写入excel
l_end = len(df1.index) + 2
df1.to_excel(writer, sheet_name=u'测试页签', encoding='utf8', header=False, index=False, startcol=0, startrow=2)
worksheet1 = writer.sheets[u'测试页签']
for col_num, value in enumerate(df1.columns.values):
worksheet1.write(1, col_num, value, date_fmt1)
# 5.生效单元格格式
# 增加个表格说明
worksheet1.merge_range('A1:B1', u'测试情况统计表', note_fmt)
# 设置列宽
worksheet1.set_column('A:E', 15, fmt)
# 有条件设定表格格式:金额列
worksheet1.conditional_format('B3:E%d' % l_end, {'type': 'cell', 'criteria': '>=', 'value': 1, 'format': amt_fmt})
# 有条件设定表格格式:百分比
worksheet1.conditional_format('E3:E%d' % l_end,
{'type': 'cell', 'criteria': '<=', 'value': 0.1, 'format': percent_fmt})
# 有条件设定表格格式:高亮百分比
worksheet1.conditional_format('E3:E%d' % l_end,
{'type': 'cell', 'criteria': '>', 'value': 0.1, 'format': highlight_fmt})
# 加边框
worksheet1.conditional_format('A1:E%d' % l_end, {'type': 'no_blanks', 'format': border_format})
# 设置日期格式
worksheet1.conditional_format('A3:A62', {'type': 'no_blanks', 'format': date_fmt})
# 6.保存
writer.save()
if __name__ == '__main__':
report()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号