第三次作业
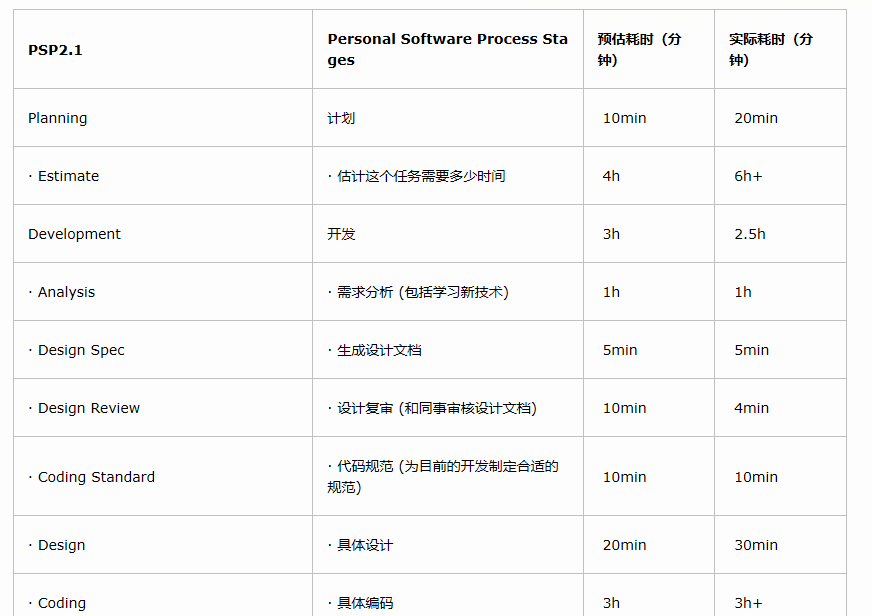
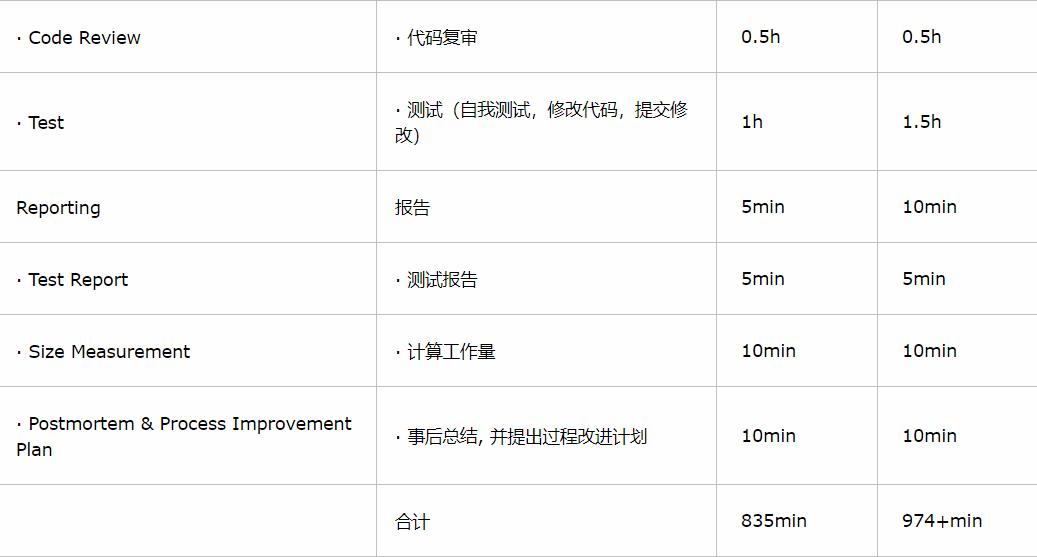
一、PSP表格
二、结对编程

和室友周小东一起,完成本次结对编程任务。
三、解题思路
拿到题目后,我们先进行了分工,我负责统计单词总数以及各单词出现的次数。于是我首先想到的便是如何读取文件,因为读取文件是本次所有作业的前提。在上网了解IO的相关用法后,开始尝试对单词总数进行统计并且统计各单词出现的次数。这里由于没有了解清楚题目,造成在前期规划时,没有考虑判断字符串是否为单词的这一条件。在后面的改动中,所幸自己使用的是用数组分类。于是新建了一个数组把满足条件的单词放进新数组再重新开始排序分类。但是这也暴露了自己审题不仔细的问题,希望自己能够引以为戒,不要再犯同样的错误。
关于这一点,首先要先了解如何读取文件,于是我上网查阅了相关资料,了解了IO的相关用法。最后成功读取了文件内容。在之后判断一个字符串是否为单词时遇到了一些问题,我一开始计划是把每个单词拆开,判断前四个的ASCII码是为A-Z,a-z的ASCII码,但是在这一块也遇到了string与char的转换,以及提取ASCII码的许多问题。但是在队友的提醒下采用了更为简便的方法 if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) 。在最后的完成分类统计后,队友发现了我的排序的问题,于是我又再次上网查阅,了解了OrderByDescending().thenby()的相关用法,最后问题得以解决。
四、设计实现过程

我们一共设计了五个函数,后面的四个函数都会调用第一个函数。五个函数的作用在后面的注释都有备注,但是我觉得第四个函数countword还能够再分解一下,因为这一个函数内容有点多,比较长,如果能够分成两到三个函数的话,可能给别人读起来能更轻松一点。
五、代码规范
六、性能分析

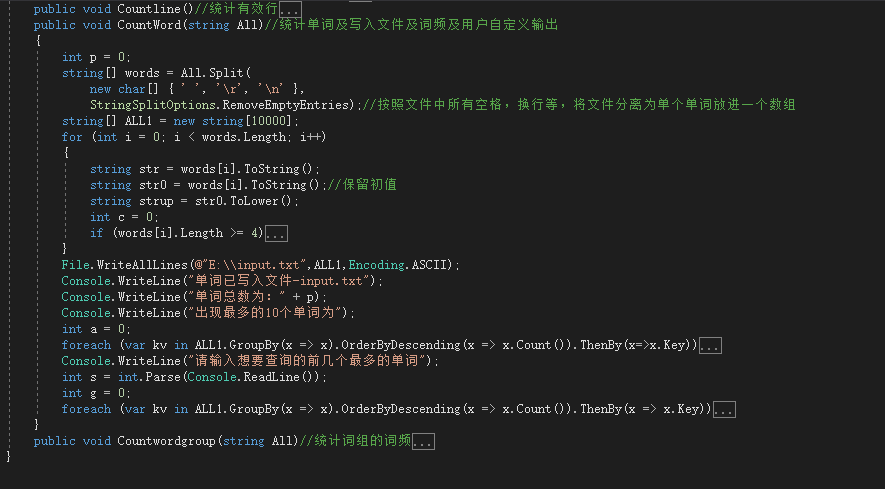
通过性能分析,发现统计单词数目以及用户自定义输入这一块花费的最多。这也是我意料之内的情况。因为可能由于自己的经验不多,导致能够想到的方法很有限,于是采用了这种特别笨的方法。将数组复制了一两次。而且这块函数中,我定义了一个大小为10000的数组,为了防止超出索引界限。但实际上后面很多都是空的,但是由于想不出更好的方法来替代,所以目前只能采用这样的方法。,导致这个函数花费非常大。
七、代码说明
详见我的队友博客https://www.cnblogs.com/zhouxiao123/p/10658903.html
八、总结
在本次结对编程中,我意识到同伴的重要性。仅仅是做自己的一部分都让自己的心态有点崩,好在有队友合作,使得自己的工作量减少了不少,也让我意识到了团队协作的重要性,这是在以前的学习中没有体会到过的。但是自己同样也意识到了许多问题,每个人的代码风格都有差异,因此需要添加注释让互相能够理解,不论是现在还是以后的工作这都是非常重要的一点。但是总的来说,本次协作还是比较满意,达到了1+1>2的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号