
本文只讨论KMP的实现,原理可从以下网站自行阅读理解,写的非常好
http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
阮一峰大神写的
理解后可知实现KMP最重要的是部分匹配表PML(Partial match list)的构建及调用
从上面的链接引用一下:
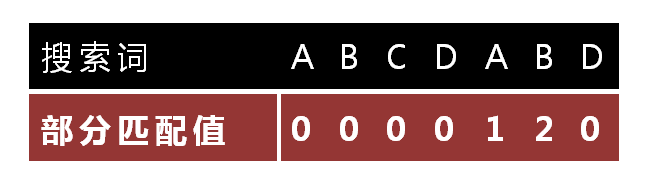
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
PML表的功能应包含:
标出对应单个字符所在位置的最大部分匹配值PMV(Partial match value)
本质上就是动态规划的实现,因此设一个DP表,每一个位置代表对应INDEX字符的部分匹配值
构建思路:
DP[i]的值实际上与DP[i-1]的值有关联,匹配时可能出现下面几种情况:
1.如果DP[i-1]存在值
说明与前面的字符串已经开始匹配了,
- 如果对应字符s[i]等于下一个应该轮到匹配的前面的字符,则PMV继续增加一个单位
如:将ABCAB 中的第二个B与第一个B进行匹配。
则DP[i] = DP[i-1]+1 【情况一】
- 如果对应字符s[1]不等于下一个应该轮到匹配的前面的字符,此时又有三个情况分支:
1.如果s[i]等于字符串的第一个字符,则又可以在此开始新的一轮匹配,
如:ABCAA,在这里第三个A不等于B,但是它等于第一个A,所以DP[i]仍为1 【情况二】
2.如果s[i]不等于字符串的第一个字符,那DP[i]就为0 【情况三】
3.如果s[i]与往前【连续匹配次数】格的字符串连续相等,那DP[i]就为DP[i-1] 【情况四】如AABAAAAA的匹配值为01012222
2.如果DP[i-1]不存在值
说明之前一个单位也没有匹配的情况,
- 如果对应字符s[i]等于字符串第一个字符,则DP[i] = 1,在此开始新的匹配 【情况五】
- 如果对应字符s[i]不等于字符串第一个字符,则DP[i] = 0 【情况六】
仔细一看,【情况二三】和【情况五六】其实可以放在一起讨论,【情况四】独立:
把【情况一】的实现条件整合一下:
条件一:DP[i-1]存在值
条件二:s[i] 等于轮到匹配的前字符
实现上述两个条件则DP[i] = DP[i-1]+1
【情况四】的实现条件:
条件一: DP[i-1]大于1
条件二:往前【连续匹配次数】格的字符串连续相等
实现上述两个条件则DP[i] = DP[i-1]
不符合上述条件的直接分类到【情况二三五六】:
- 如果对应字符s[i]等于字符串第一个字符,则DP[i] = 1,在此开始新的匹配 【情况二/四】
- 如果对应字符s[i]不等于字符串第一个字符,则DP[i] = 0 【情况三/五】
上PML的构建代码:
def Partial_match_list(lst): #建立部分匹配表
dp = [-1] + [0 for i in range(len(lst))] #留个-1,避免范围溢出
lst = '_'+lst #个人习惯,为了dp与lst下标相等
r = 1 #记录连续值
for i in range(1,len(dp)):#跳过0
if lst[i] == lst[r] and dp[i-1]: #判断1:上一个DP点存在值 #判断2:str当前值与记录值相同
dp[i] = dp[i-1]+1 #条件通过:当前dp值为上个dp值+1
r += 1 #连续记录值+1
elif dp[i-1] > 1 and len(set(lst[1:i+1][-r:])) == 1: #判断1:上一个DP点值大于1(连续两个以上记录),判断2:往前【连续匹配次数】格的字符串连续相等
dp[i] = dp[i-1] #条件通过:当前dp值与上一个dp值相等,但是r不增加,因为连续记录数不变
else:#如果不符合上述条件
dp[i] = 1 if lst[i] == lst[1] else 0 #如果str当前值与首值相等,则当前dp为1,否则为0
r = 2 if dp[i] else 1 #如果当前dp为1,则记录值也为2,否则为1
if dp[i-1] and lst[i-1] == lst[r]: #判断1:如果上一个点存在值 #判断2:如果str当前值与记录值相同
dp[i] = dp[i-1]+1 #条件通过:当前dp值为上个dp值+1
r = dp[i] #记录值与DP值相同
else:#如果不符合上述条件
dp[i] = 1 if lst[i-1] == lst[0] else 0 #如果str当前值与首值相等,则当前dp为1,否则为0
r = 1 if dp[i] else 0 #如果当前dp为1,则记录值也为1,否则为0
return dp[1:] #由于0号是建表初期拿来避免范围溢出的,后续用不到,所以不输出
有了PML后,KMP的实现就相对简单很多了
def KMP(text, match): #text为原文,match为匹配文本
s, m = text, match
if len(m) > len(s): #如果查询字符大于文本,直接退出
return -1
dp = Partial_match_list(m) #使用先前代码制作PML
index,dp_index = 0,0 #设定文本index与dp_index:文本index用于标注检测中的文本字符位置;dp_index用于标注检测中的匹配字符位置
l,dp_l = len(s), len(dp) #计算文本长度与dp长度:文本长度用于检测循环是否到末尾;dp长度用于检测是否达成检索目标
while index < l: #当文本index仍在合理值内,便继续循环
if s[index] == m[dp_index]: #情况一:当前文本字符与对应匹配字符相等
if dp_index == dp_l-1: # 如果dp_index达到了最大理论长度,说明匹配字符全部通过匹配,程序完成
return index - dp_index #程序完成,进行反馈,返回发生匹配时最开始的序列
index += 1 #如果还未匹配完毕,则增加index与dp_index,继续匹配
dp_index += 1
elif s[index] != m[dp_index] and dp_index:#情况二:当前文本字符与对应匹配字符不相等;但是前段已经匹配了一部分字符
dp_index = dp[dp_index-1] #将dp_index重新定位到目前dp_part中最后一个值,这是下一步要比较的dp_index——KMP的关键思路,相当于前面dp_index的字符已经通过匹配,直接从+1的位置和原文index位置进行匹配。
else: #情况三:当前文本字符与对应匹配字符不相等;且前端无匹配字符
index += 1 #直接增加index比较下一组。
return -1 #原文中并没有出现匹配字符 返回-1
for i in range(1,len(dp)):
if lst[i] == lst[r] and dp[i-1]:
dp[i] = dp[i-1]+1
r += 1
elif dp[i-1] > 1 and len(set(lst[1:i+1][-r:])) == 1:
dp[i] = dp[i-1]
else:
dp[i] = 1 if lst[i] == lst[1] else 0
r = 2 if dp[i] else 1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号