触类旁通
目的:
- 自己所了解的东西太过于少,太太少了,再深入学习(看书)一个东西同时,我想先通过广泛阅读好的文章来去扩宽我对计算机知识的了解,就弄了个这个博客去搞。
- 记录下来,很多好的文章再想起来可能就容易忘记,我会贴上链接,并且如果可以会用自己的话去概括一下我了解到的部分新东西,不在于通透,在于大量。
准备分成三个部分,一个是文章,一个是个人博主推荐,一个是书,不过主要是文章了,博主和书太少了。新看的文章放在最前边,这样也好找一些。
文章
END TO END
论文:https://groups.csail.mit.edu/ana/Publications/PubPDFs/End-to-End%20Arguments%20in%20System%20Design.pdf
OSPF
RIP路由协议4个问题:
- 根据跳数选路,不合理,比如跳数少,带宽很小
- 15跳的限制
- 每30S向相邻发送所有自己的路由表,浪费带宽
- 收敛速度慢,当网络节点时常更新,难以稳定
OSPF的4个关键点:
- 通过组播发hello包找邻居,建立链接关系:选个主DR,备BDR节点,这两个点和所有其他点建立邻接关系,其他的不建立。
- 发送链路信息,每个节点有个LS(link state)DB,两种情况会发送,有节点变化会触发更新,或者30分钟就会发送一次。收敛之后,所有点的LSDB是一样的。
- 每个点自己算一个最短路。
OSPF分区域管理里的区域边界路由器ABR:
- ABR拥有相连的区域里的LSDB。相邻节点不是一个区域内的节点,就是区域边界路由器。还有个自治系统边界路由器ASBR,连接两个不同路由协议区域的节点。
- 骨干区域:每个区域有个ID,骨干区域ID=0,网络里存在多个OSPF区域,必然有个骨干区域。
- 所有非骨干区域通信都需要通过骨干区域0转发,就算两个非骨干区域之间有ABR,也不能直接交换路由信息,还是需要通过区域0,这样设计为了防环。
VLAN:三种模式trunk、access、hybrid
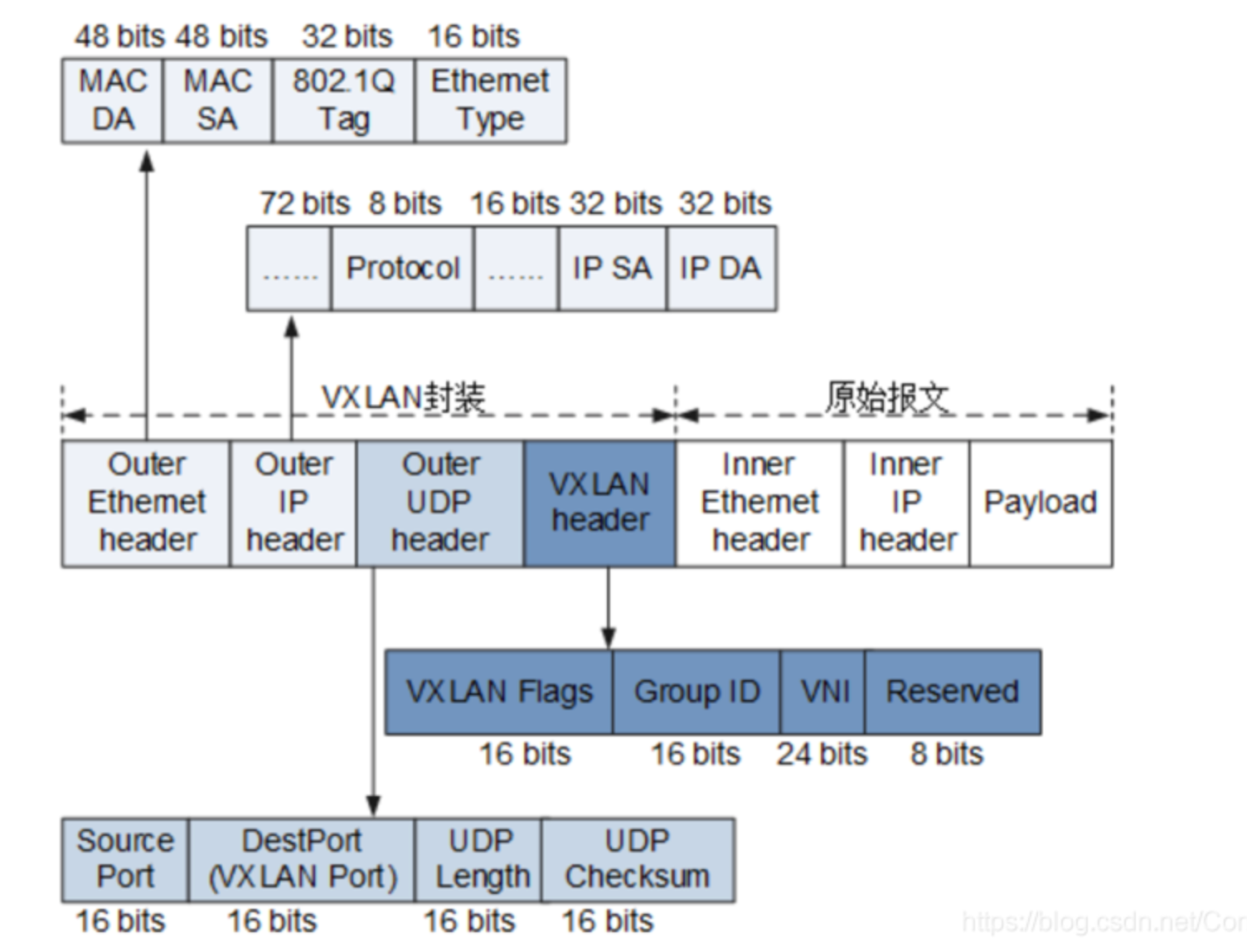
这三种链路模式就是vlan如何转发的,这里没说vtep。首先知道vlan所处的报文位置,下图是vxlan的,都一样,首先是UDP报文,所以这里传输层是UDP header,并且端口是4789,如果收到个发往4789端口的包,就知道是vlan包了。
acess:连接机器
交换机有个默认的pvid。可以在端口上配vid。
- 收口:收到包没有vid加上pvid。收到包有vid,对比一下和端口的vid、默认的pvid相同吗,不同就丢弃。根据vid发到对应的端口
- 发口:发出去的话,把vid给摘掉。
trunk:连接交换机
交换机有个默认的pvid。可以在端口上配vid。
- 收口:收到包没有vid加上pvid。收到包有vid,对比一下和端口的vid或者,默认的pvid相同吗,不同就丢弃。
- 发口:发出去的话,如果是pvid把vid给摘掉,不是的话就不摘,这种就送到了下一个交换机了。
hybrid:都可以
交换机有个默认的pvid。可以在端口上配vid,和trunk不同的是,出口时每个vid可以自己配置需不需要摘掉。
TOP显示的状态
DMA
https://www.jianshu.com/p/3a26e8c9f402
首先传统IO是单个字节就要中断,DMA可以读取一个块,也可以读取连续的块;其次是DMA控制器可以绕过cpu进行数据传输,从而和cpu并行。
有三种模式:死循环轮训,io中断,DMA控制器。
转发技术风雨三十年,你经历过……
这个文章太好,网络一步步发展,各个技术都是在需求中落地生根。
- SDN:谷歌那么大规模的服务器,高峰流量是平均流量的2~3倍,广域网带宽只有30%~40%,然后发现其中只是又部分流量对延迟要求比较高,那么就可以分优先级,对延迟要求高的先发送,剩下的再去把空余流量挤满,这就引入了Software Defined Networking (SDN)/OpenFlow,把分散的路由集中控制起来,控制层可以离中整个网络的拓扑信息和业务的需求信息,计算出一个全局最优的路由规则,谷歌宣称平均带宽利用率已经达到了95%。
- NFV:但是SDN、openflow无法满足,NFV问世,核心在于通过使用x86的IT设备,大大降低运营商投资成本,扩展的API让运营商可以又更灵活的网络能力。
- DPDK:当NFV这套方法一路高歌猛进的时候,发现linux内核体统的socket收发包提供的带宽远不能跟得上CPU的处理速度,空有一身能力却无法施展,intel为此设计开发了DPDK并且为所有用户免费提供,NFV+DPDK,从网络IO到计算CPU,Intel公司打下了自己的天下!DPDK通过抛弃中断,无锁队列,DDIO,内存大页,SSE、AVX指令等优化,大大提高了网络IO性能。虽然cache机制对dpdk影响巨大,当流表规模大于L3cache时,性能可能腰斩,但在当前的虚拟化大行其道的今天,其地位已无可撼动。
TCP那些事
- 对于SYN FLOOD,不能先使用tcp_syncookies,cookies解决,而应该先设置tcp_synack_retries减少重传次数,tcp_max_syn_backlog增大连接数,tcp_abort_on_overflow处理不过来就丢掉。
- Selective Acknowledgment:有个SACK和D(Duplicate)-SACK,前者表示我缺少那些范围的包,后者表示重复收到了某些范围的包。但是也是有缺点的。对于SACK也是有缺点的,给客户端发送大量已经收到过的SACK,欺骗客户端没有收到,那么客户端也会发送。
- 慢启动算法,收到一个ack就cwnd++(congestion window),经过一个RTT,cwnd *= 2,到达一个上线ssthresh时;进入拥塞避免,收到一个ack就cwnd += 1/cwnd,经过一个RTT,cwnt++;发生拥塞时候,进行快恢复,cwnd /=2,sshthresh = cwnd,直接进入用色避免。
二层网络三层网络理解
sriov
pf和vf,phyiscal function - virtual function
网卡ringbufer
网络包处理流程这个图非常好:https://www.51cto.com/article/715271.html
virtio协议1.0 -- 网络设备
很多网卡不支持UFO和ECN的TSO
UFO:和TOS对应,一个tcp一个udp
ECN:拥塞控制的标记:https://zhuanlan.zhihu.com/p/395200230
dpdk的vhost研究
C++异常
大概原理:https://zhuanlan.zhihu.com/p/406894769
虽然一搜网上都说多用异常,但是听了个同事的分享,一些公司比如google,明确禁止使用异常,为什么呢?
这里有几个归纳非常简单的:https://zhuanlan.zhihu.com/p/315789294
- 我印象里一个是性能,因为throw时候,是开了新的内存,代码的紧凑性很可能被破坏。
- 另一个是发生异常时有两次遍历,一次是遍历所有的栈,如果有捕捉到的异常,进入第二个循环,一直回退调用栈clean up。不过这个我觉得没有问题,貌似出现异常就直接挂了,都挂了还担心个啥这一点耗时。
- 一个项目里,可能有go c++ python c rust,那么如何异常如何可以运行呢?比如一个python函数调用了c函数。通过了一个LSDA(language specific data area) 的东西,就相当于每个编译器提供一个解析的东西,但是有个统一的格式,数据位置和方法本身都是编译起自己决定的。
怎样解决呢?
- C++11里面有个noexcept 关键字
- -fno-exceptions 编译选项
- -fno-asynchronous-unwind-tables 编译选项
别管!尽量别用异常!
构造不能抛异常,因为无法确认内存,没有构造完整,是undefined behavior.
博主
书籍PDF && 系统文章
《网络基本功》
https://wizardforcel.gitbooks.io/network-basic/content/30.html
《Clean Code》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号