数据库笔记
sql语句
连接:MySQL的join on和 where 的执行顺序和区别,以及各种连接说明
where是先生成表再过滤,on是先过滤在生成表,inner on更快。
练习题(全是LeetCode上的):
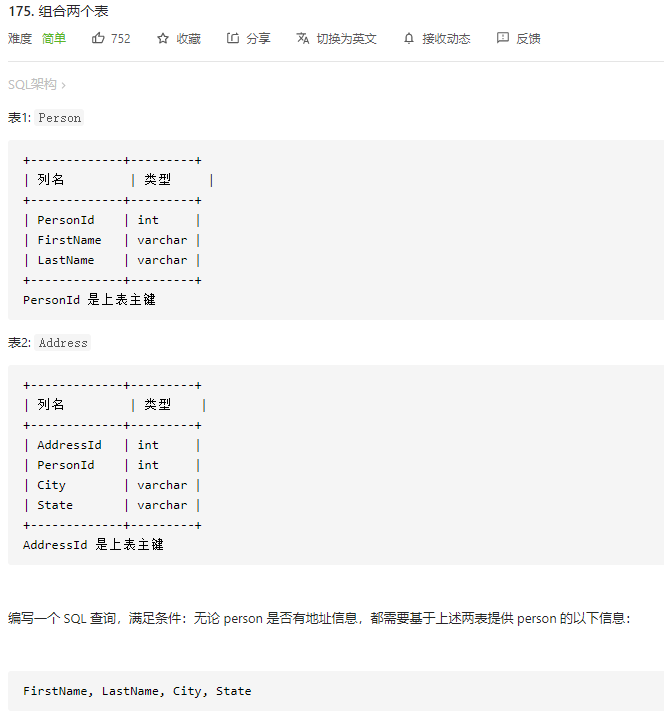
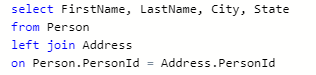
- 第二大薪水
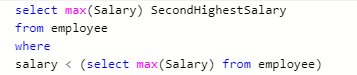
- 第N大薪水
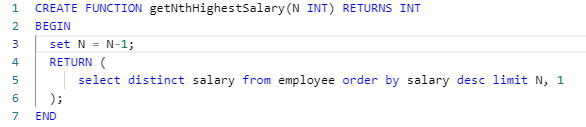
- 性别反转

- 查找有五名及以上 student 的 class。

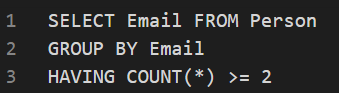
- 查找超过两次的邮件
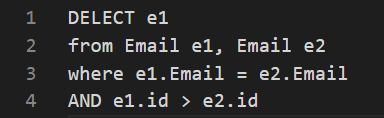
- 只保留相同 Email 中 Id 最小的那一个,然后删除其它的。
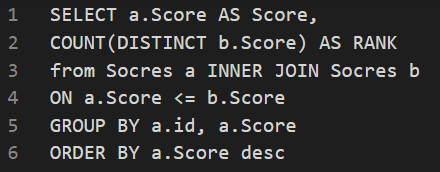
- 将得分排序,并统计排名。
更多看这:SQL 练习
数据库原理
事务
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
ACID
原子性:要么全部完成做要么全部不完成。
一致性:从一个正确的状态转换到另一个正确的状态。(修改工龄时也修改年龄)
隔离性:一个事务所做的修改在最终提交以前,对其它事务是不可见的。比如对于ab两个并发的事务,在a看来,要么b在a之前已经结束,要么b在a结束后才开始,这样每个事务都感受不到其他的事务。
持久性:一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
如何保证 ACID
保证原子性:是利用Innodb的undo log。 undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句,他需要记录你要回滚的相应日志信息。
保持一致性:原子性、隔离性、持久性以及应用层的保障
保持隔离性:通过锁机制和mvcc(多版本并发控制技术,通过行记录中的隐藏列和undo log实现)
保证持久性:innoDB通过缓存(Buffer Pool,定期刷盘)提高读写数据效率,但MySQL宕机时会导致数据丢失,于是引入redo log,当数据修改时,先在redo log中记录本次操作所有修改,之后修改Buffer Pool数据;事务提交时,会调用fsync接口对redo log进行刷盘,如果宕机,重启时可以读取redo log中的数据,对数据库进行恢复
并发一致性问题
丢失修改:AB对一个数据修改,A先修改,之后B又修改,覆盖了A的修改。
读脏数据:A修改了一个数据但并未提交,B读了这个数据,A撤销修改。
不可重复读:A读数据,B修改了这个数据,A再次读了这个数据。
幻读:A读某个范围数据,B在该范围内插入新数据,A再读该范围数据。比如size,本质是不可重复度。
封锁粒度
行级锁:行级锁是 MySQL 中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突,其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。
表级锁:表级锁是 MySQL 中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分 MySQL 引擎支持。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
封锁类型
- 互斥锁(Exclusive),简写为 X 锁,又称写锁。 一个事务给数据对象加了,可以读和修改,其他的不能加锁读写。
- 共享锁(Shared),简写为 S 锁,又称读锁。 一个事务给数据对象加了,可以读,不能修改,其他的也能加S锁读。
三级封锁
- 1级 事务修改数据对象时要加X锁,事务结束时释放。
- 2级 在1级条件基础上,读数据时也要加S锁,读完马上释放S锁。
- 3级 在2级条件基础上,事务结束时在释放。
两段锁协议
加锁和解锁分两个阶段进行,事务遵循两段锁协议一定是可串行化调度的。(通过并发控制,使得某个串行执行的事务结果与并发执行的事务结果相同)
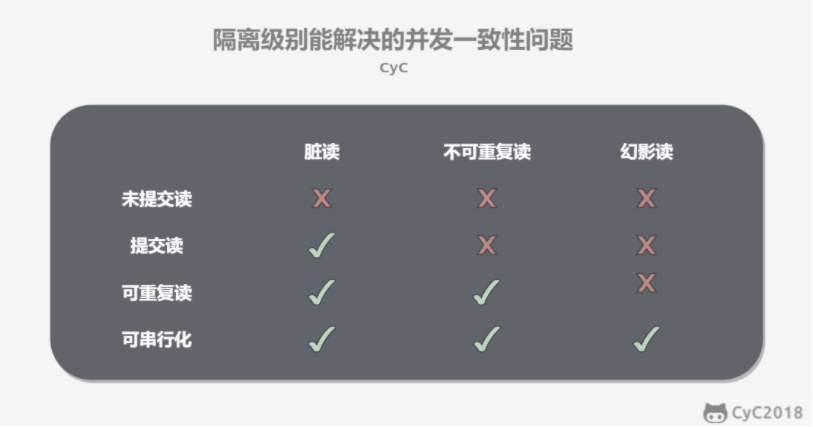
事务隔离级别
未提交读:未提交的事务对其他事务也有可见性
提交读:一个事务提交前对其他事务不可见
可重复读:保证在同一事务多次读取同一数据结果一致
可串行化:强制事务串行执行
索引
- MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提。
- 聚簇索引:很简单记住一句话:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。
- 非聚簇索引:索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号