数据库三范式的理解
参考
参考文章:https://zhuanlan.zhihu.com/p/20028672
本文的例子以及叙述思路来源于上文。
定义
三范式是对关系型数据库表结构设计的一种规范制约,设计出的数据表如果满足范式的标准,则称某数据库表满足第一(二、三)范式。数字越大,标准越严格。且第一范式、第二范式、第三范式是一个递进的过程,满足第一范式后,才能去
评价是否满足第二范式。
第一范式
每一个属性都是不可再分割的,这是构成数据库表的必要条件。换句话说,能放进数据库里的表,都满足第一范式。
摘一个图过来

这种就不满足第一范式。进货不能作为属性,需要拆分成进货表,销售也同样如此。
第二范式
满足一范式后,就可以将你抽象的设计具体化,可以将你的想法付诸实践,形成具体的表结构,存进数据库了。现有表结构:学生表,学生表的内容为
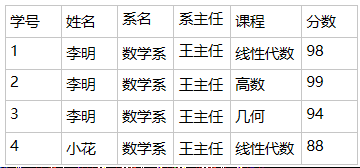
可以发现,每人每门课的成绩,都会不厌倦地带上系名、系主任等信息,很累赘、很繁琐。
这样设计表结构会给业务带来什么影响呢?
1、数据冗余
2、插入异常——现在学校决定新建一个系了,还没来及的招收学生,便无法将系信息单独的插进去。
3、删除异常——如果此时决定将一批学生的成绩信息全部删除,那么同时也将会删除该学生所在系的相关信息,这不是我们想看到的。
4、修改异常——如果此时,李明想要转系了,那么只要是关于李明的成绩记录。都需要修改系信息。
这个时候,我们就需要引入第二范式的概念了。
在第一范式的基础上,清除了非主属性对于码的部分函数依赖。
- 函数依赖
如果A属性的值确定,那么B属性的值也确定,称作B依赖于A。这样来看可能有点绕,按照我们思维习惯,可以这么理解,A决定了B,所以A有主导权,B就依赖A。
上述表有哪些函数依赖呢?
姓名 依赖于 学号 (学号知道了,姓名也就知道了)
系主任 依赖于 学号 (学号知道了,系主任自然知道了)
分数 依赖于 (学号、课名) (知道课名,学号,必然知道分数了)
- 完全函数依赖
分数依赖于(学号、课名),只要在知道学号和具体哪一门课的前提下,才能知道分数,缺一不可,这就是完全依赖。
- 部分函数依赖
表面上姓名部分依赖于(学号,课名),但其实姓名只依赖于学号,这就叫部份依赖。
- 传递函数依赖
X 依赖于Y, Y依赖于 Z,在 Y不依赖于X的前提下, X依赖于Z
- 码
码可能是一个属性,也可能是一个属性组(多个属性的组合)。如果码确定了,那么属性也确定了。哎~,这不就是主键吗?
并不能这么说,比如一张表里有身份证、学号, 学号和身份证都能表示唯一性,知道任意一个,就可以锁定到这个学生。
我们在选择主键的时候,身份证和学号并不会都用,只会选择其一。所以我们所说的主键其实是码的一个子集。
- 主属性
码的一个成员
- 非主属性
不是码的成员。
现在可以来理解第二范式的定义了:是否存在非主属性对码的部分函数依赖。
判断是否满足第二范式,需要经过一下几个步骤:
- 第一步骤
找到表中的码,(学号、课名)
- 第二步骤
主属性:学号、课名
- 第三步骤
非主属性:姓名、系名、系主任、分数
- 第四步骤
分析非主属性是否对码有部份依赖
姓名,只依赖于学号,有部分依赖
系名,只依赖于学号,有部份依赖
系主任,只依赖于学号,有部份依赖
分数,依赖于学号、课程,没有部份依赖
- 结论
目前的表结构,并不满足第二范式,姓名、系名、系主任,这些非主属性居然对码有部分依赖,注定是要被踢出来的。
改造
分数表

学生表

分析:
我们从第二范式的定义入手,分析表属性,将一张表拆分成了两张表。仔细一看,从业务上将,无非就是将学生信息与学生成绩拆分下来。
可是拆分的并不彻底,还是存在一些问题。
如果删除了某个系所有学生信息,那么这个系的信息也会消失。系信息与学生信息耦合在一起。我们将一步改造这张表,使其满足第三范式。
第三范式
第三范式在第二范式的基础上,消除了非主属性对于码的传递函数依赖。
成绩表已经没有耦合,除了主码,就剩一个分数字段了,且对码没有部份依赖,不需要改造。那我们重点分析一下成绩表
分析
主码:学号
主属性:学号
非主属性:姓名、系名、系主任
学号知道了,系名就知道了;系名知道了,系主任就知道了。
系主任依赖系名,系名依赖学号。存在非主属性对于码的传递依赖。
因此学生表不符合第三范式,进一步拆分:
学生表
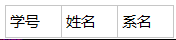
系表

在经过多次拆分后,现有的三张表分别是:成绩表、学生表、系表。解决了冗余、插入一场、修改异常、删除异常等多种问题。
BCNF范式
BCNF范式的目的在于,消除主属性对于码的部分和传递函数依赖。
举例:
某公司有若干仓库,需要派人管理,一个管理员只能管理一个仓库,各个仓库可以存放相同的物品。(原文中用的是管理员名,但是名字可能会重复,所以把它换成工号。)
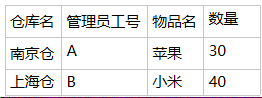
码:(管理员工号,物品名)、(物品名,仓库名)
主属性:仓库、管理员工号、物品名
非主属性:数量
不存在非主属性对码的传递依赖、部份依赖,满足第三范式。但是依然存在问题:
虽说一个仓库只有一个管理员,且一个管理员只能管理一个仓库,但是这个管理员可能会有变动,如果哪一天某个仓库换了个管理员,那么这个仓库有几条物品记录,就需要修改多少条数据。究其根本,还是因为耦合的问题。
BCNF范式,要求消除主属性对于码的部份依赖和传递依赖。仓库名是一个主属性,依赖于管理员工号,也依赖于物品名。那么就将仓库和仓库管理员拆分出来。
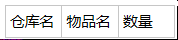
仓库表

库存表
总结
范式是一种规范,一种约束。但是在实际项目中,可能会出现各种各样的情况,我们不必死守规范,而应当灵活变通。
按照范式来设计数据表,本质上就是一种解耦的过程。范式的好处就是,明确定义了这个耦合的程度,以及我们如何降低这个耦合。一范式,二范式、三范式是解耦的过程。BCNF范式是第二、第三范式的一种补充。
多说几句,如果在工作中,我可能不会从范式的角度入手,而是从业务本身来设计数据表,例如第一个例子,有哪些是很少变化的,有哪些是经常变化的。系名、系主任这是绑定在一起的,是一个整体的概念,代表“系”,且很少变化。其次就是学生,学生除非跨年级、毕业,一般也不会变化,是一个整体的概念。最后是成绩,学生可能有好几门课,每门课都可以被多个人选,是多对多的概念,所以抽象出成绩表,将学生与课程关联起来。
不管是学习还是工作中,设计数据库的时候可能会从常识的角度,或者从业务需求的角度入手。在我们设计出表后,需要进一步考虑其合理性,这个时候就可以换一个思维,从范式的角度来看这些表,结合实际情况做优化。
如有错误,恳请指出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号