介绍
特点
- 底层原理:用于表示链接的对象
Node<E>,其中存放着上下链接对象以及对象E。此链表是双向链表。
- 优点:插入和删除元素快;
- 缺点:查找元素慢。修改元素的速度由查找速度决定,本质上修改即等同于查找后替换。
- 如果是通过索引
index查找值,代码底层只都会从链表的一半中查找;
- 如果需要通过值
value来查找值,代码底层会对链表进行迭代。
链表结构
- 数组
Array和数组列表ArrayList有一个重大的缺陷:从数组中间删除一个元素的开销很大,如果删除一个元素,那么对应的数组中位于被删元素之后的所有元素都要向数组前端移动。同样的,向数组中插入一个元素也是如此。
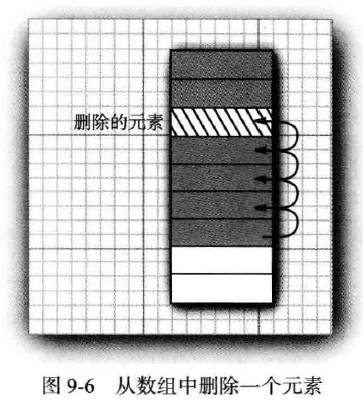
- 对于大部分的业务情况而言,我们使用集合是因为要用来保存数据。当取用数据的时候,往往需要同时从存储媒介中剔除该已取用的数据。这个时候无论使用
Array还是ArrayList都会影响程序的性能。
- 除了数组结构外,
Java也提供了另一种数据结构链表的实现LinkedList,链表结构可以实现元素的快速增删。
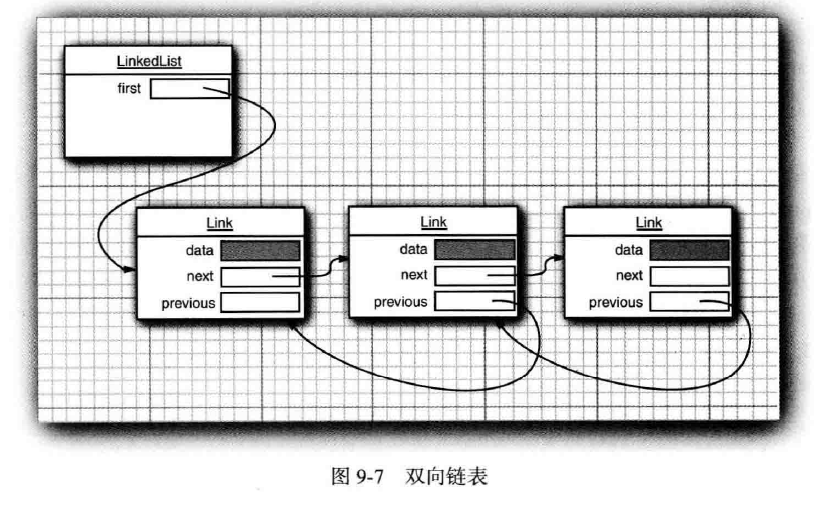
- 数组是在连续的存储位置上存放对象引用,而链表则是将每个对象存放在单独的链接
link中。
- 每个链接
link还存放着序列中的下一个链接link的引用。如下图结构所示:
- 在
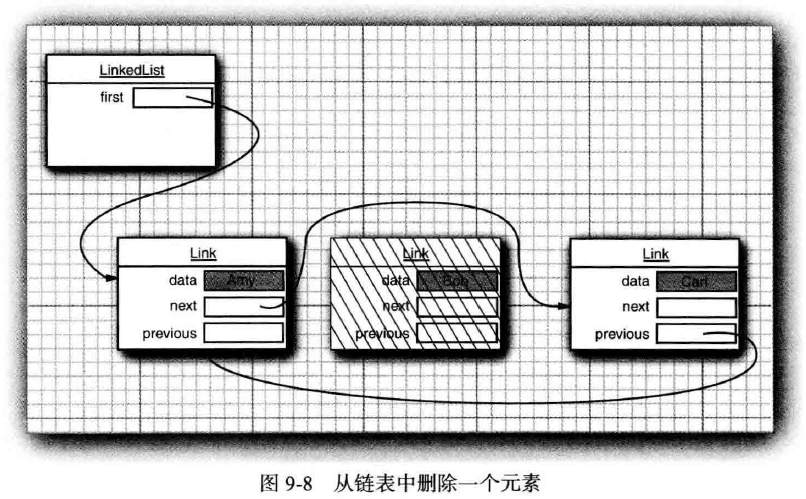
Java程序设计语言中,所有链表LinkedList实际上都是双向链接doubly linked,即每个链接link还存放着其前驱的引用。链表是一个有序集合ordered collection,每个对象的位置十分重要。
- 通过
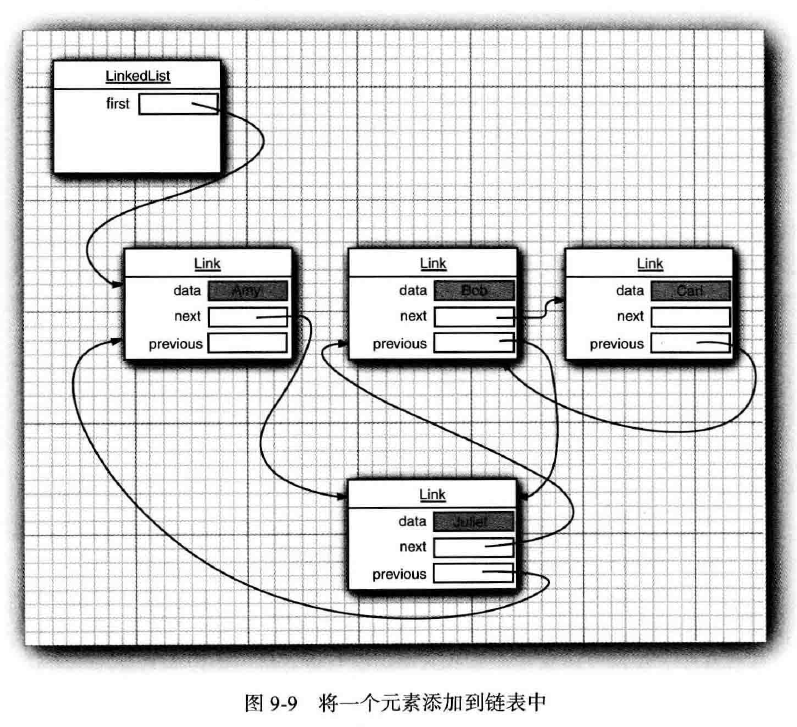
LinkedList.add方法,可以将对象添加到链表的尾部。但是通常需要将元素添加到链表的中间。由于迭代器描述了集合中的位置,所以这种依赖于位置的add方法将由迭代器负责。只有对自然有序的集合使用迭代器添加元素才有实际意义。
Iterator接口中包含了四个方法:
hasNext():等待实现;next():等待实现;remove():抛出UnsupportedOperationException("remove")异常;forEachRemaining:用于迭代当前Iterator对象并取用其中元素的方法,类似于forEach()。
package java.util;
import java.util.function.Consumer;
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
- 集合类库则提供了一个
Iterator接口的子类接口ListIterator,其中增加了一些方法:
hasPrevious()previous()nextIndex()previousIndex()set(E e)add(E e)
package java.util;
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
- 在
ListIterator<E>中一个较为有趣的地方是,该接口重新定义了一个remove()方法,那么所有实现该接口的类就必须要覆写remove()方法,同时该接口的父类接口Iterator<E>中的默认方法remove()也等同于被废弃。
- 在进行相关方法比较前,需要了解一下链表
LinkedList的构成,链表中有一个私有静态内部类Node<E>,这个类就相当于链表中的链接link,源码如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- 链接
link中除了封装当前对象元素element之后,还封装了上一个链接的对象引用prev与下一个链接的对象引用next。
- 众所周知,外部类是可以随意访问其成员内部类中的成员变量、成员方法而不受任何权限修饰符的限制。因此在
LinkedList中可以使用Node<E>.filed的格式,获取到链表中当前位置对象、上一个对象的链接及下一个对象的链接。
- 链表
LinkedList中还包含了一个方法node(int index),源码如下:
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
- 其中
size为成员变量,记录了当前链表长度,链表方法size()的调用将返回size。
- 方法
node(int index)接收一个int类型作为参数,它将返回指定索引位index上的Node对象。注意,它每次只会从当前链表中的前半部分或后半部分去找。
- 有符号右移位运算符
>>右移1位等同于(int) Math.floor(size / 2),即node(int index)会首先计算出index处于当前链表的前半部还是后半部,之后才会根据计算结果分别进行正序或倒序遍历。
- 关于位移运算符的计算,可以参考以下代码:
package cn.dylanphang;
/**
* @author dylan
*/
public class BitOperator2 {
public static void main(String[] args) {
// m进行有符号右移n位相当于(int) Math.floor(m / Math.pow(2, n))
// 关于-7,采用8位解释,运算前需要求出反码和补码,对补码进行有符号右移,高位补1,之后得到原码,结算得到结果:
// 十进制-7的原码为:1000 0111,计算其补码为:1111 1001,右移一位:1111 1100,计算原码:1000 0100
// 因此十进制结果为:-4
System.out.println(7 >> 1);
System.out.println(-7 >> 1);
}
}
关于add方法
- 在
LinkedList的API中,提供了一个方法add(int index, E element),而ListIterator对象中的add方法也可以向链表中添加元素,那么其本质是否一致呢?
- 关于方法
add(int index, E element),源码如下:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
- 方法
linkLast()会在当前链表末尾追加一个元素element,而linkBefore(E element, Node<E> succ)会在链接succ对象之前添加element元素,以下为linkLast()与linkBefore()的源码:
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* Inserts element e before non-null Node succ.
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
- 实际中使用最多的获取
ListIterator对象的方法,是linkedList.listIterator()。但LinkedList中并没有找到该方法的空参形式,仅有以下方法被定义在LinkedList中用于返回ListIterator<E>对象:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
- 无疑该方法是通过继承或实现的方式,从父类或接口处获取的。通过阅读源码,可以发现无参的
listIterator()方法被定义在接口List<E>中,而该方法被接口AbstractList<E>覆写为以下形式:
public ListIterator<E> listIterator() {
return listIterator(0);
}
- 以下为
LinkedList<E>、AbstractSequentialList<E>、AbstractList<E>及List<E>的部分源码:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator<E> { ... }
}
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
public Iterator<E> iterator() {
return listIterator();
}
public abstract ListIterator<E> listIterator(int index);
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
public Iterator<E> iterator() {
return new Itr();
}
public ListIterator<E> listIterator() {
return listIterator(0);
}
public ListIterator<E> listIterator(final int index) {
rangeCheckForAdd(index);
return new ListItr(index);
}
private class Itr implements Iterator<E> { ... }
private class ListItr extends Itr implements ListIterator<E> { ... }
}
public interface List<E> extends Collection<E> {
Iterator<E> iterator();
ListIterator<E> listIterator();
ListIterator<E> listIterator(int index);
}
- 那么一个完整的调用流程是:
linkedList.listIterator() -> AbstractList.listIterator() -> this.listIterator(0)
- 即使用
linkedList.listIterator()等同于使用了linkedList.listIterator(0)。
- 那么
listIterator中如何实现add(E element)方法呢?源码如下:
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned; // 这个成员变量将记录最后一次cursor跳过的那个链接Node,remove()方法依赖于它来删除链接Node
private Node<E> next; // 从构造器方法可以看出,这个就是等于index为0的链接Node或者链表为空的时候它等于null
private int nextIndex; // 记录当前cursor所指向位置后的那个索引
private int expectedModCount = modCount; // 记录当前链表被操作的次数,调用此类中的大部分方法会使此操作数+1
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
- 重新贴一下
LinkedList中的add(int index, E element)方法的源码:
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
- 比较两者,可以知道其中的大部分逻辑是一样的。
- 其中不太相同的只有判断是否到达链表末尾的逻辑:前者通过判断下一个链接对象引用
next是否为null,来判定此时迭代器是否位于链表的尾部;而后者通过判断当前索引是否等于链表的长度,来判定此时迭代器是否位于链表的尾部。
线程不安全
- 使用
add(int index, E element)向链表末尾添加元素即等同于调用linkLast(E e)方法,而链表提供的add(E e)方法也是调用linkLast(E e)方法用于添加元素。以下将使用add(E e)作一个线程不安全的测试。
- 总所周知,
LinkedList是线程不安全的,即允许多个线程同时对它进行操作,那么想象以下场景:
- 假设有两个线程同时对长度大于
2的链表A进行添加元素的操作,使用add(E element)方法;
- 此时两个线程都需要在链表末尾添加一个元素,假如两个线程一前一后进入
linkBefore(E e)。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- 此时添加操作不会出现任何异常。但这可能会导致一个严重问题:插入链表的两个元素的下一个链接
next都会指向null,而上一个链接则均会指向last。而last中所指向的下一个链接则指向线程较慢时所插入的元素。
- 虽然看似没有异常,但对于链表来说却是灾难性的错误。链表元素中的链接指向出错,将直接导致迭代器无法工作。
- 以下测试中,会开启
5000个线程,同时对成员变量linkedList进行插入操作,程序将输出以下日志信息:
this.counter:计算向linkedList中添加元素的有效次数,确保不是因为异常导致添加元素失败;this.linkedList.size():链表长度;e.getClass().getSimpleName():迭代如果出现异常,则打印异常的名字;currentIndex:异常出现在哪个链接之后。
package cn.dylanphang;
import cn.dylanphang.util.ThreadUtils;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.util.LinkedList;
import java.util.ListIterator;
import java.util.concurrent.CountDownLatch;
/**
* @author dylan
* @date 2021/01/01
*/
@Slf4j
public class LinkedListTest {
private static final int CONCURRENT_TIMES = 5000;
private final CountDownLatch cdl = new CountDownLatch(CONCURRENT_TIMES);
private final CountDownLatch testCdl = new CountDownLatch(CONCURRENT_TIMES);
private final LinkedList<String> linkedList = new LinkedList<>();
private int counter = 0;
/**
* 由于无法控制LinkedList中的程序流程,采用高并发插入数据的方式去为同一个LinkedList添加元素。
*/
@Test
public void test() throws InterruptedException {
for (int i = 0; i < CONCURRENT_TIMES; i++) {
final String content = i + "";
ThreadUtils.create(() -> {
try {
this.cdl.await();
Thread.sleep(1000);
this.linkedList.add(content);
count();
} catch (InterruptedException e) {
e.printStackTrace();
}
this.testCdl.countDown();
});
this.cdl.countDown();
}
this.testCdl.await();
log.info("Successful write into LinkedList times is: {}", this.counter);
log.info("Current insert operation finish. LinkedList's size is: {}", this.linkedList.size());
int currentIndex = -1;
final ListIterator<String> listIterator = this.linkedList.listIterator();
while (listIterator.hasNext()) {
try {
listIterator.next();
currentIndex++;
} catch (Exception e) {
log.error("Exception is: {}", e.getClass().getSimpleName());
break;
}
}
log.info("Mistake element index is: {}", currentIndex);
}
synchronized private void count() {
this.counter++;
}
}
- 计算成功添加元素次数的
count()方法,必须使用synchronized关键字修饰,此时不能使用以下代码进行替换:
- 测试运行次数为
3次,得到以下结果:



- 三次测试表明,添加元素
add()操作本身不会出现任何异常,但最终链表长度则表明其内部出现添加失败的操作。
- 而三次获取的迭代器对象,在进行迭代时均出现
NullPointerException,在不进行异常抓取的情况下,可以清晰看到异常出现的位置位于next()方法中的next = next.next行,不难推敲是由于当前链接的前置链接中next字段值为null引起。
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
- 以上结论,可以知道在多线程的情况下使用
linkLast(E e)方法,是可能会造成链表结构错误。那么对于使用该方法的其他方法add(int index, E element)或add(E e)来说,即同样有可能造成结构错误。
- 遗憾的是,在多线程情况下使用成员变量或类变量
LinkedList时,该错误是不可避免的。
操作数modCount
- 在
LinkedList中大部分对链表操作的方法,都会记录操作数,而这个操作数成员变量是modCount,其初始值为0。操作数需要与ListIterator中的expectedModCount配合使用,某些特殊情况下可以避免添加元素失败的情况。
ListIterator中对操作数进行记录的字段为expectedModCount,该字段在获取ListIterator对象时,被初始化为当前链表的操作数字段modCount的值。- 使用
ListIterator对链表进行add或remove操作时,其会调用LinkedList中的增删方法,此时modCount会自增或自减的情况。而ListIterator的add和remove方法也会同步让expectedModCount进行自增或自减的操作。
- 其中关键点是
ListIterator的add()方法中调用的checkForComodification()方法:
- 该方法检查
modCount是否与expectedModCount的值一致。一致则无事发生,否则抛出异常。
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
- 如果此时有两个线程获取了同一个
LinkedList的ListIterator对象,此时它们获取到的expectedModCount都为0。其中一个线程如果调用了ListIterator.add(),此时假设另一个线程为调用任何的方法。
- 则
LinkedList中的modCount就会被置为1。此时另一个线程开始调用ListIterator.add(),进入此方法会,程序会先进性校验操作,调用checkForComodification()。明显,此时modCount == 1而expectedModCount == 0。
modCount != expectedModCount的情况下,会抛出ConcurrentModificationException异常。- 为了方便理解,编写以下测试类:
package cn.dylanphang;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import java.lang.reflect.Field;
import java.util.AbstractList;
import java.util.ConcurrentModificationException;
import java.util.LinkedList;
import java.util.ListIterator;
/**
* @author dylan
*/
@Slf4j
@SuppressWarnings("all")
public class ListIteratorTest {
@Test
public void test() throws InterruptedException, IllegalAccessException, InstantiationException, NoSuchFieldException {
// 1.获取LinkedList对象
AbstractList<String> linkedList = new LinkedList<>();
// 2.线程一
new Thread(() -> {
try {
// 2.1.获取listIterator对象,modCount/expectedModCount均为0
ListIterator<String> listIterator = linkedList.listIterator();
// 2.2.线程休眠2秒
Thread.sleep(2000);
// 2.3.线程结束休眠后,添加元素前需要经过checkForComodification()
// *.此时线程二已经结束,modCount必然为1,checkForComodification()将抛出ConcurrentModificationException
listIterator.add("dylan");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ConcurrentModificationException e) {
log.error("{}", e.toString());
}
}).start();
// 3.线程二
new Thread(() -> {
try {
// 3.1.获取listIterator对象,modCount/expectedModCount均为0
ListIterator<String> listIterator = linkedList.listIterator();
// 3.2.线程休眠1秒
Thread.sleep(1000);
// 3.3.线程结束休眠后,添加元素完毕,modCount被更新为1
listIterator.add("sunny");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// 4.防止test线程结束
Thread.sleep(3000);
// 5.使用反射技术获取AbstractList中modCount的字段对象field
Class<AbstractList> abstractListClass = AbstractList.class;
Field field = abstractListClass.getDeclaredField("modCount");
// 6.取消Java权限控制检查
field.setAccessible(true);
// 7.断言modCount的值为1
log.info("modCount: {}", field.get(linkedList));
}
}
- 以上程序开启两个线程,在对
LinkedList进行add()操作前获取其ListIterator对象,并进行不通过长度的休眠,以确保获取的ListIterator对象中的expectedModCount值为0。线程二将先对链表进行操作,之后观察线程一及后续的输出。
- 运行测试:

- 没有意外,程序捕获到了
ConcurrentModificationException。
- 但纵使如此,仍没有消除
LinkedList中线程不安全的问题。多个线程是极有可能在modCount与expectedModCount相等的情况下进行checkForComodification()判断的,此时不会抛出任何的异常。对于以下代码:
ListIterator<String> listIterator = linkedList.listIterator();
listIterator.add("something.");
- 程序基本上在一瞬间就能获取到
ListIterator并使用add()让modCount++,此时另一个线程获取的ListIterator依然是新操作数modCount了。程序运行太快,使得在平常的程序中难以捕获异常,但并不代表线程安全。
linkedList.add与listIterator.add
- 综上所述,
LinkedList中的方法add(int index, E element),与ListIterator对象中的add(E element)同样可以向链表中插入元素,其实现原理其实也是一致的:
- 前者能带来更强的便利性,通过直接指定索引的方式,可以在链表的任意一个位置添加新的链接
link;
- 后者可以通过指定索引的方式
listIterator(int index)先获取到ListIterator对象引用,之后再调用该对象所提供的add(E element)方法添加元素,使用该对象也可以对链表进行增add、删remove、改set操作;
- 两者均为线程不安全的方法:
- 多线程操作
linkedList.add()可能会导致链表结构出错;
- 多线程操作
listIterator.add()则还可能会导致ConcurrentModificationException异常。
总结
LinkedList是线程不安全的。modCount与expectModCount的结合使用,在某些特殊情况下可以避免增删元素导致链表结构错误的情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号