结对作业二
结对作业二
| 这个作业属于哪个课程 | 软件工程2021春软件工程W班(福州大学) |
|---|---|
| 结对学号 | 221801427、221801413 |
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 1.对论文信息进行分析与展示 2.服务器部署 |
| 其他参考文献 | Yii2.0中文指南,php爬虫参考,服务器配置教程 |
git仓库链接和代码规范链接
远程访问链接
PSP表格
| PSP2.1(Pair Programming) | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 3320 | 3760 |
| Analysis | 需求分析(包括结对讨论) | 60 | 80 |
| Learning Tools | 学习框架、服务器部署 | 30 | 60 |
| Design | 总体设计 | 80 | 100 |
| Prototyping | 代码编写 | 2880 | 3180 |
| Deployment | 网站部署 | 180 | 240 |
| Test | 测试(自我测试,修改页面,提交修改) | 60 | 60 |
| Code Review | 代码复审 | 30 | 40 |
| Reporting | 报告 | 45 | 66 |
| Size Measurement | 计算工作量 | 15 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并分享心得 | 30 | 33 |
| Total | 合计 | 3395 | 3856 |
成品展示
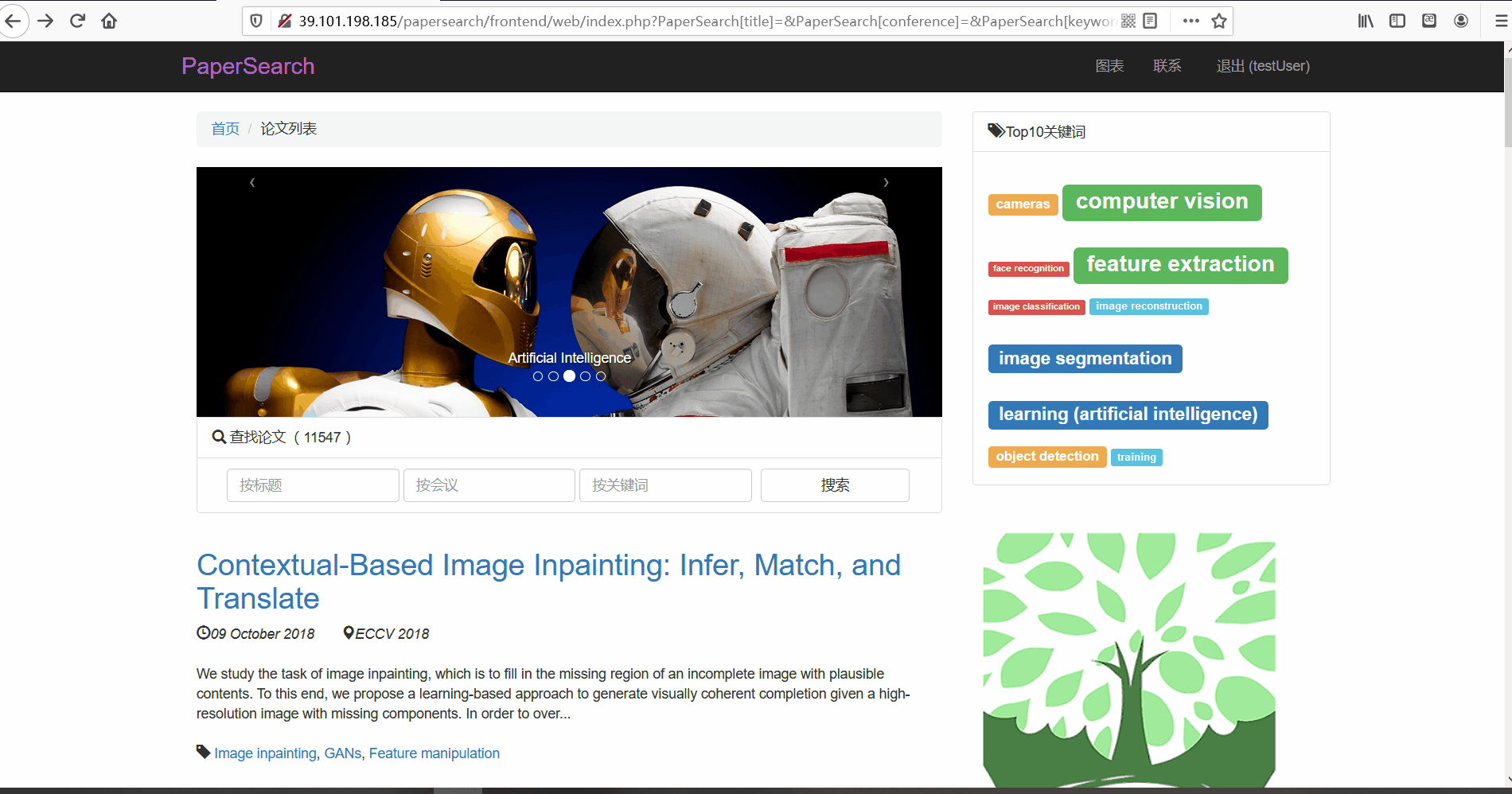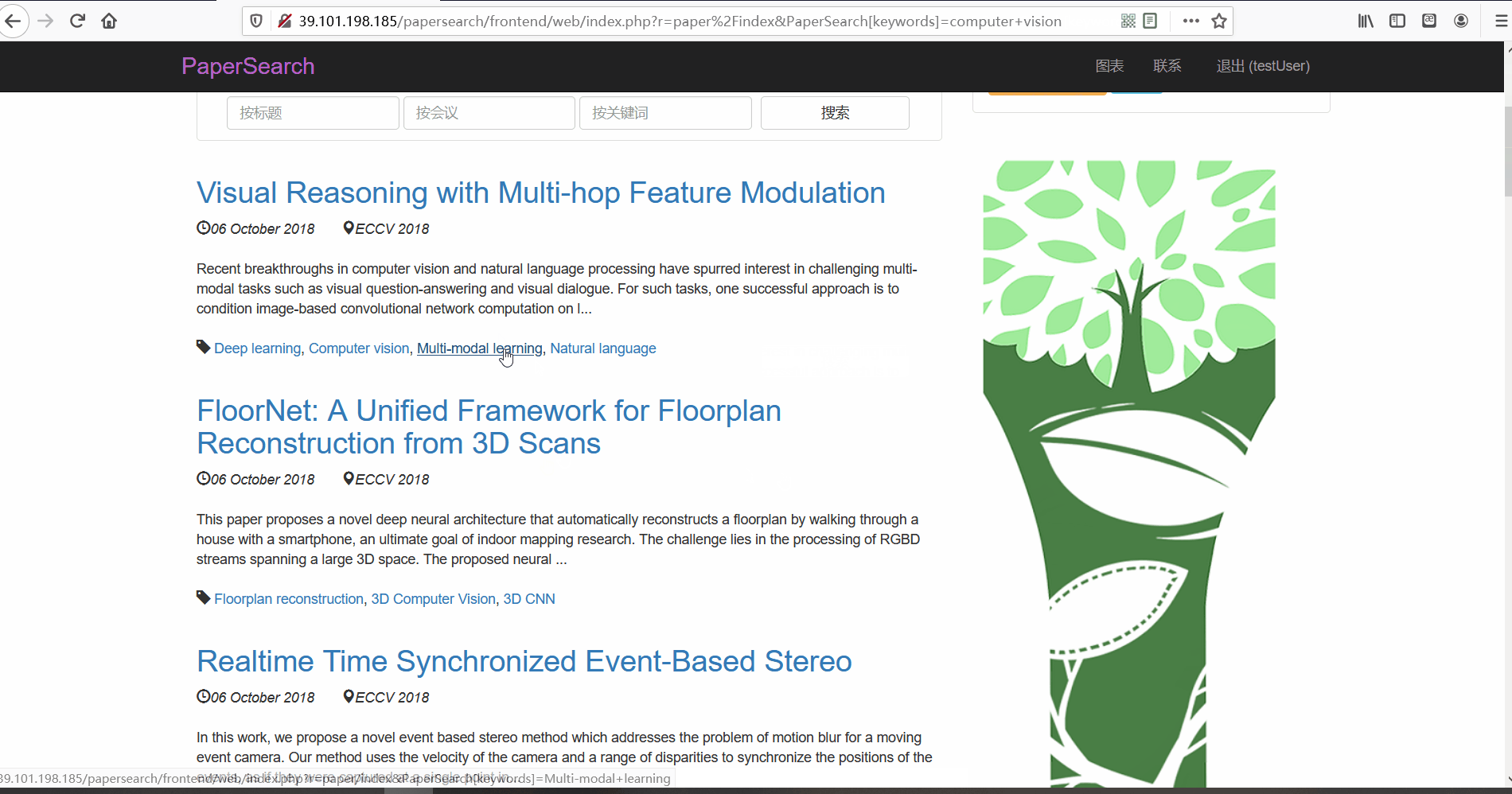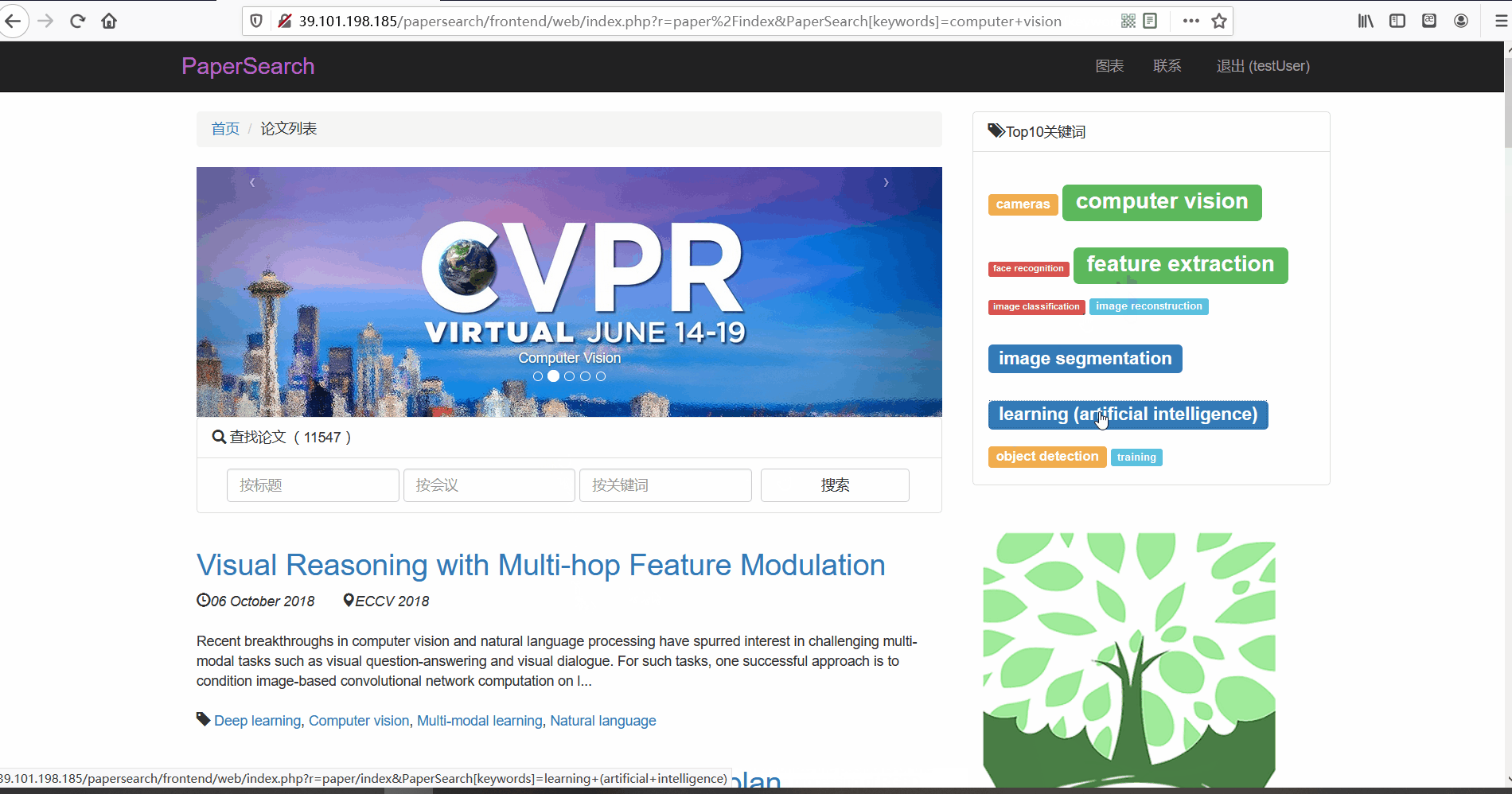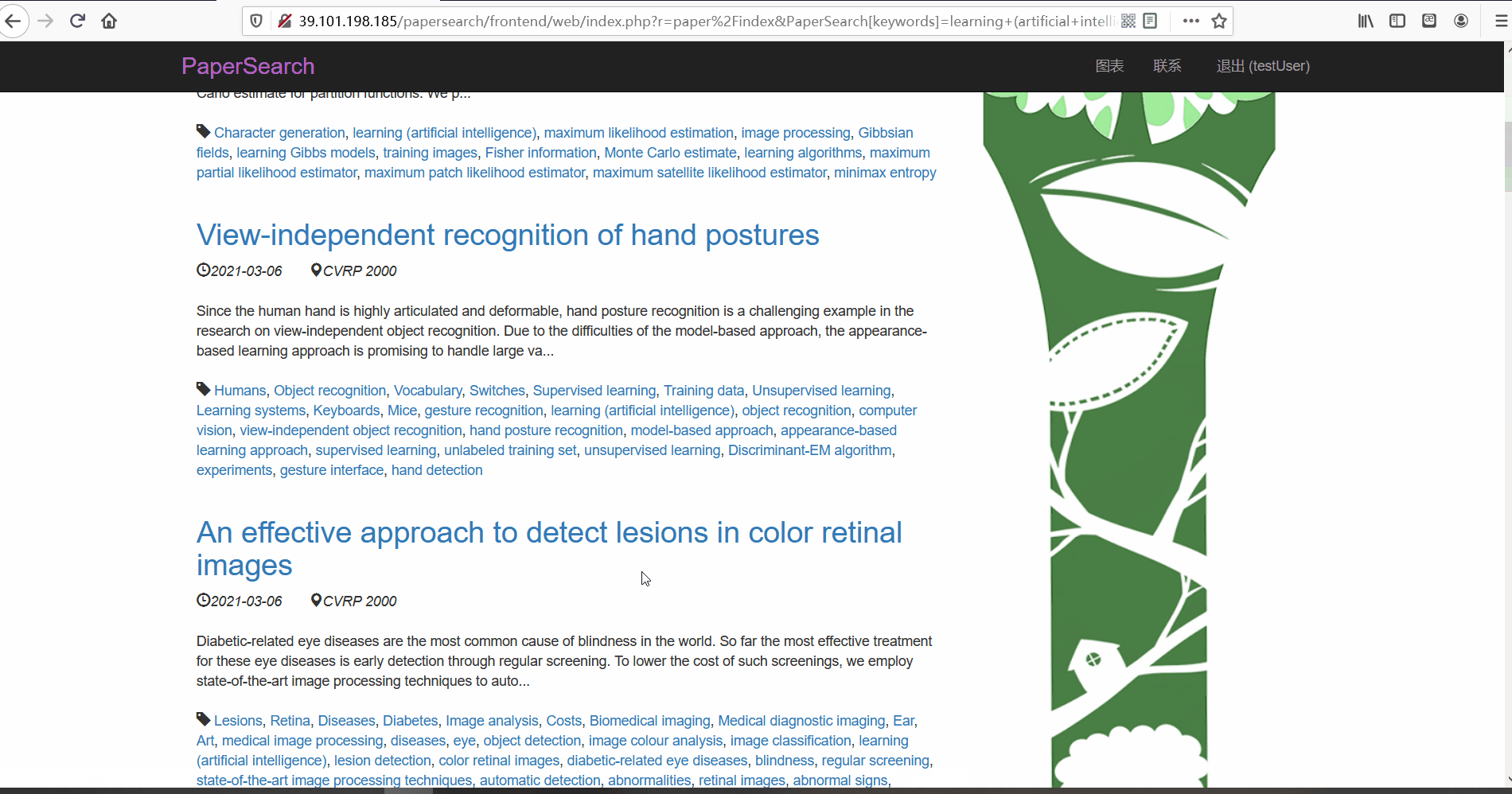
1. 前台功能展示
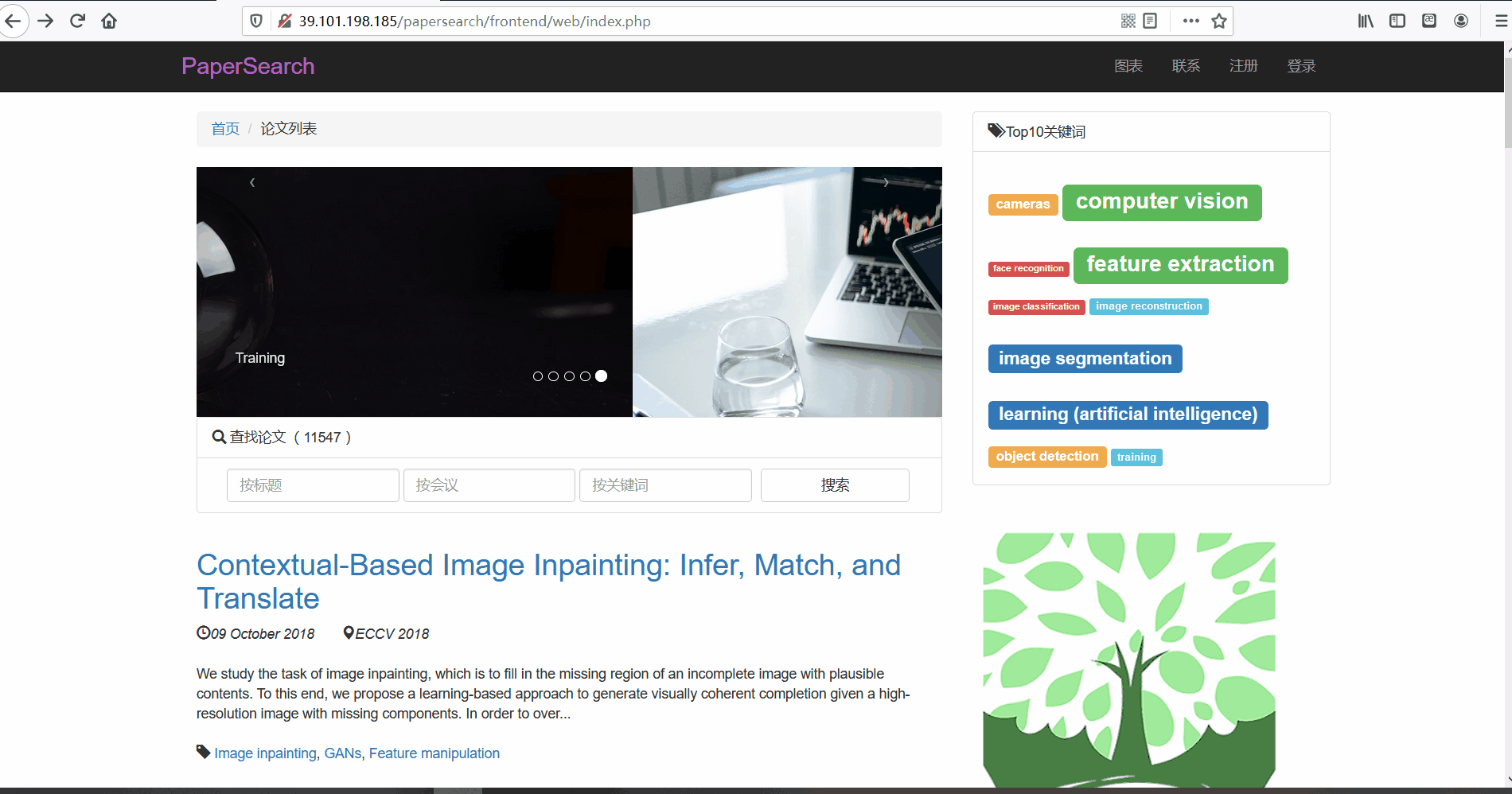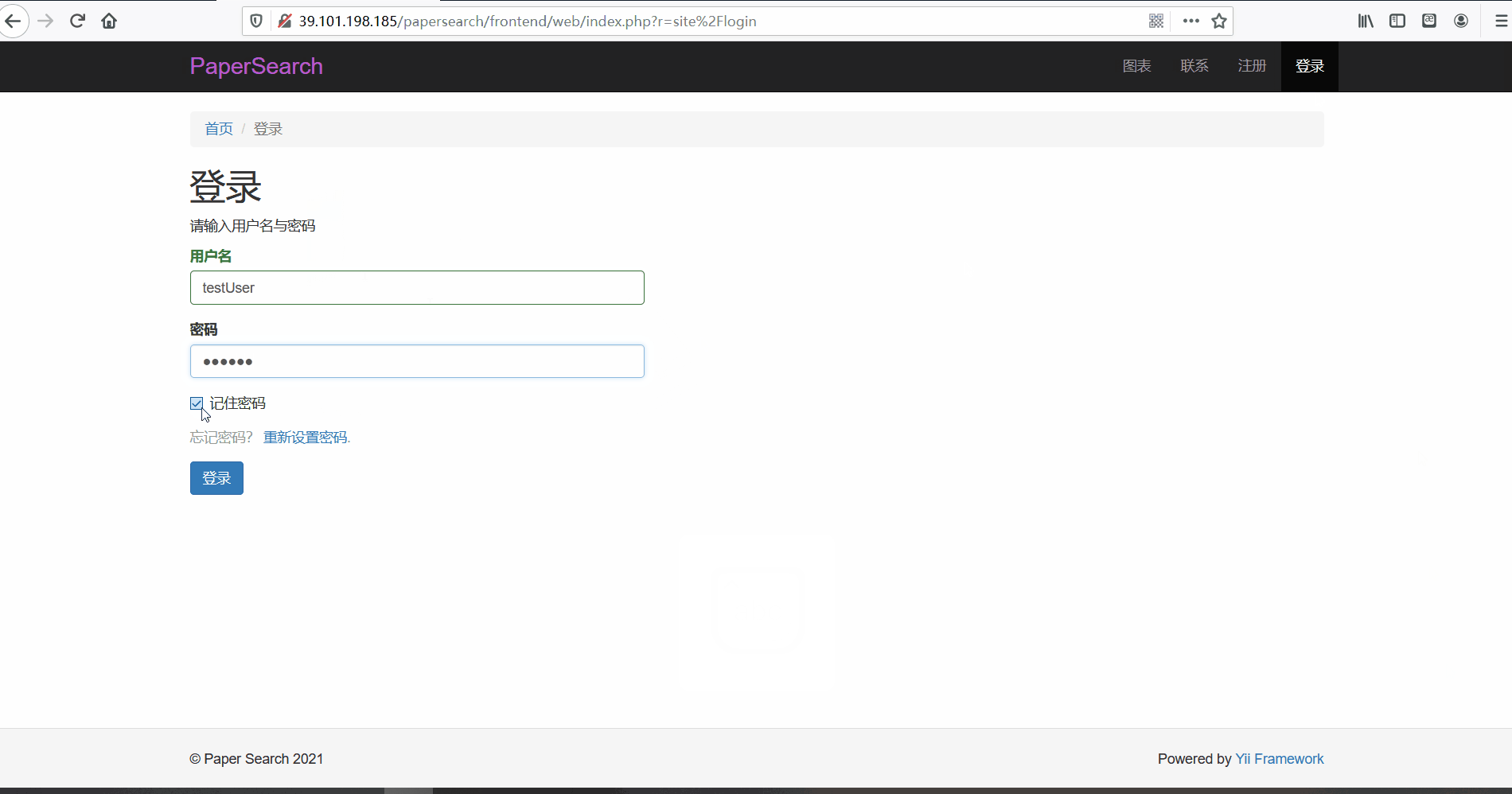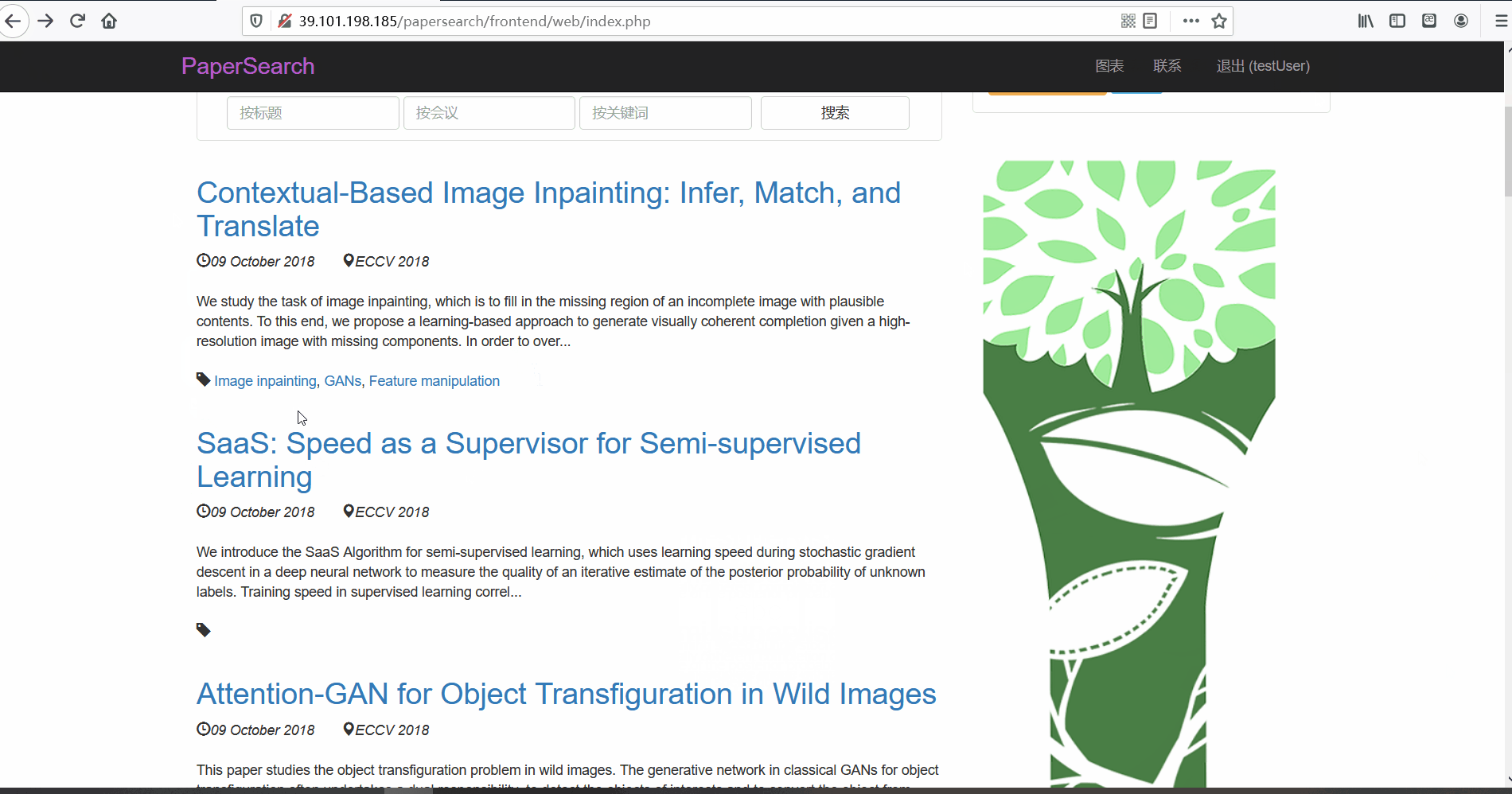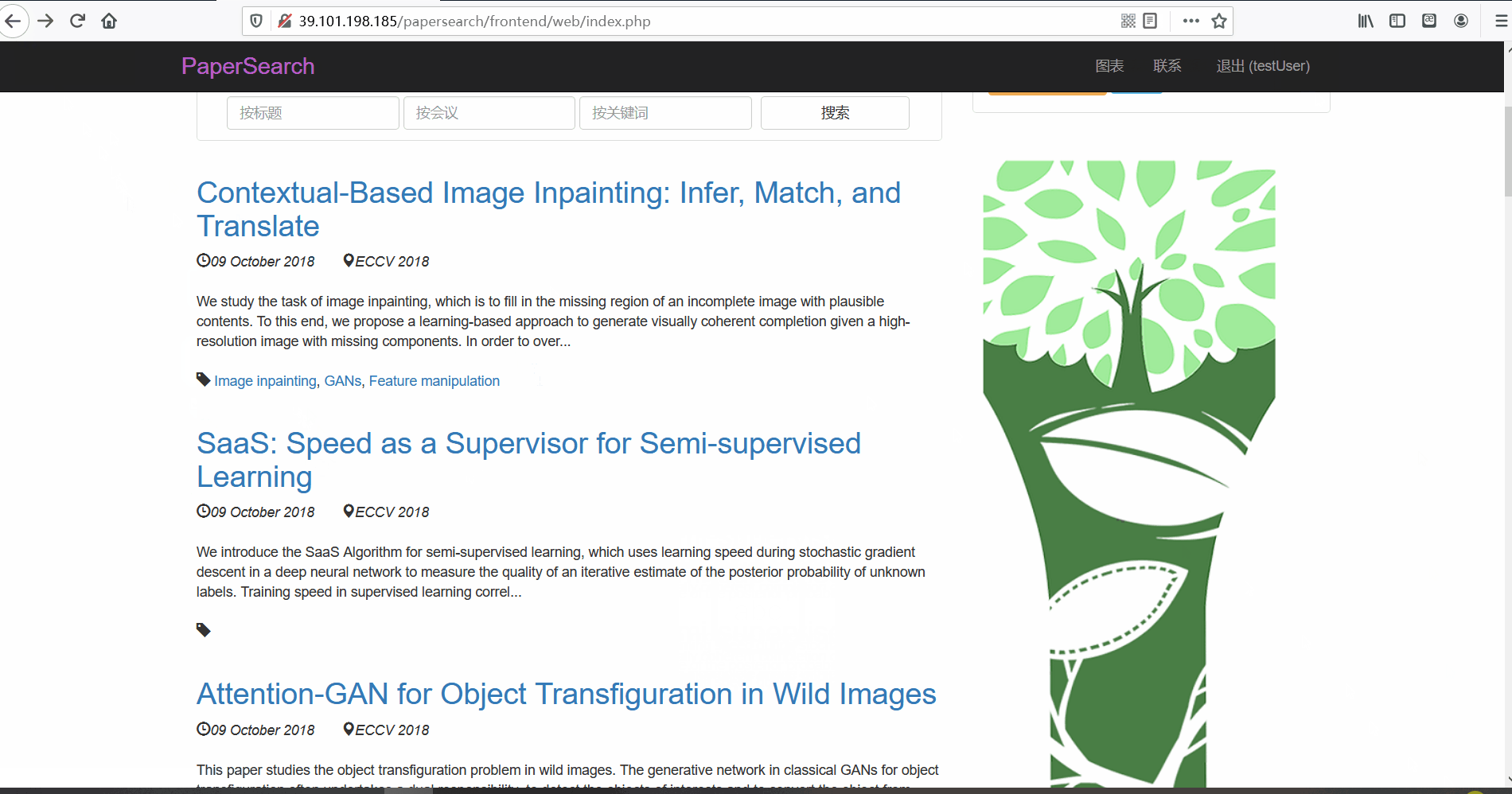
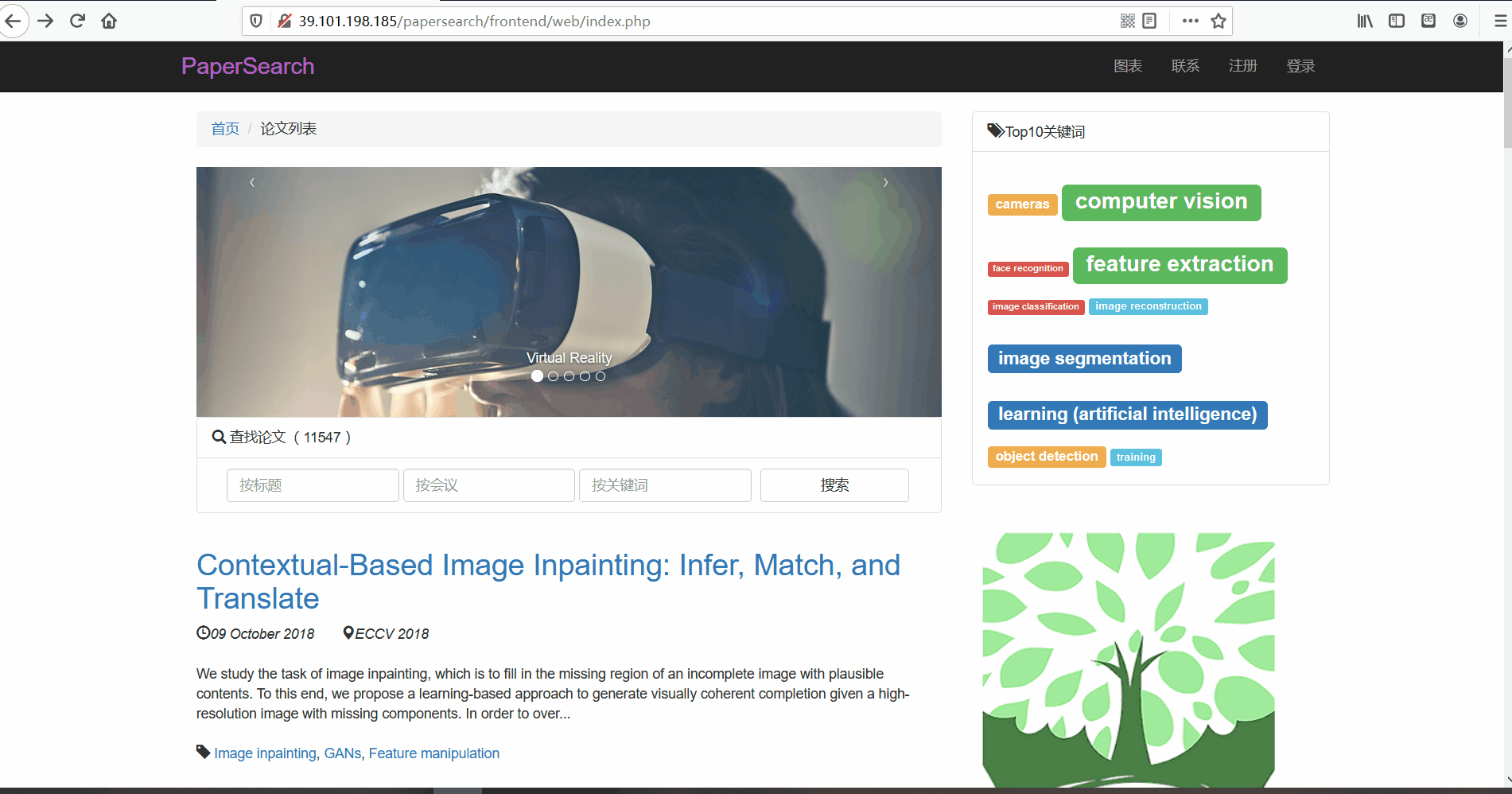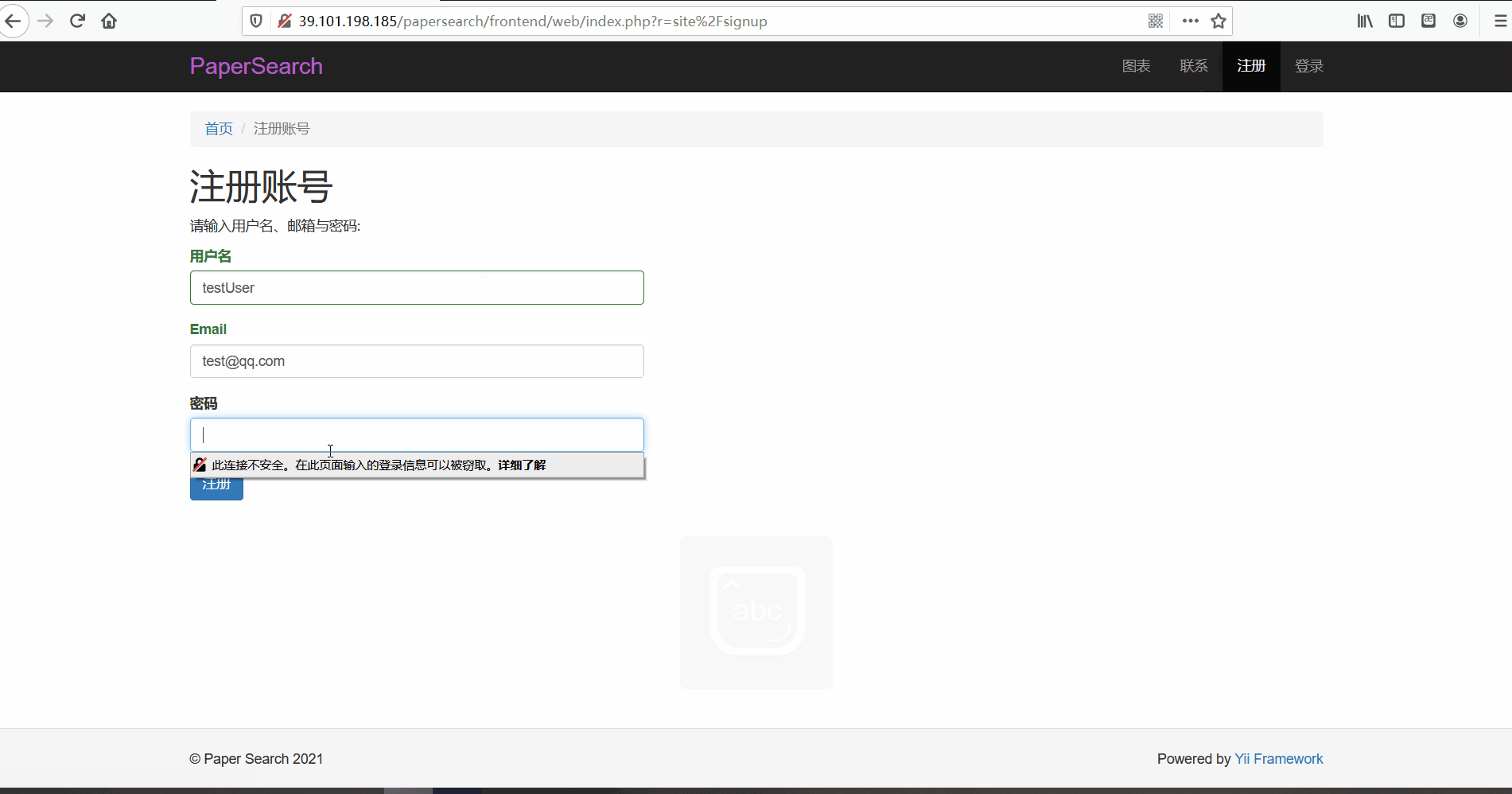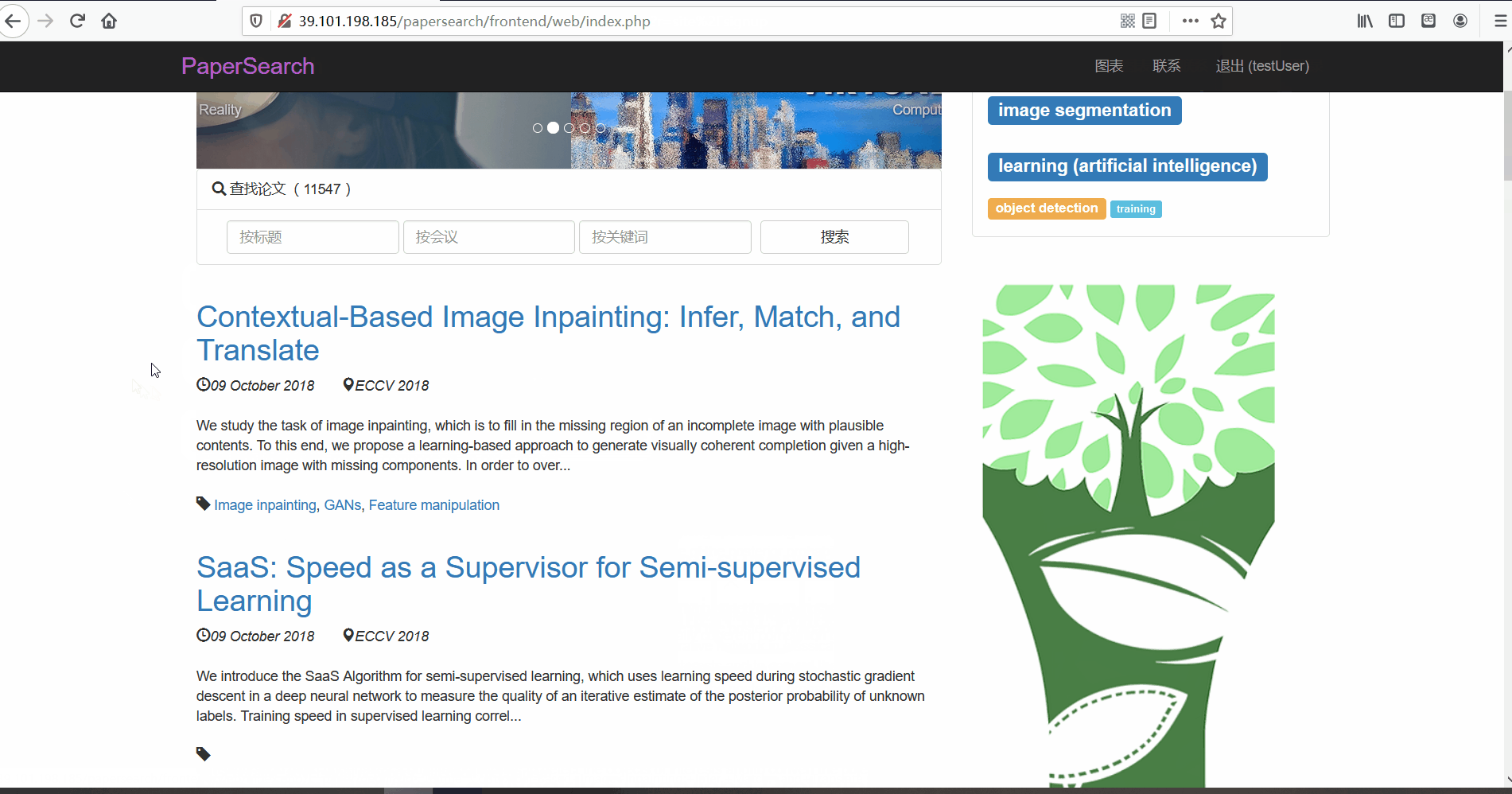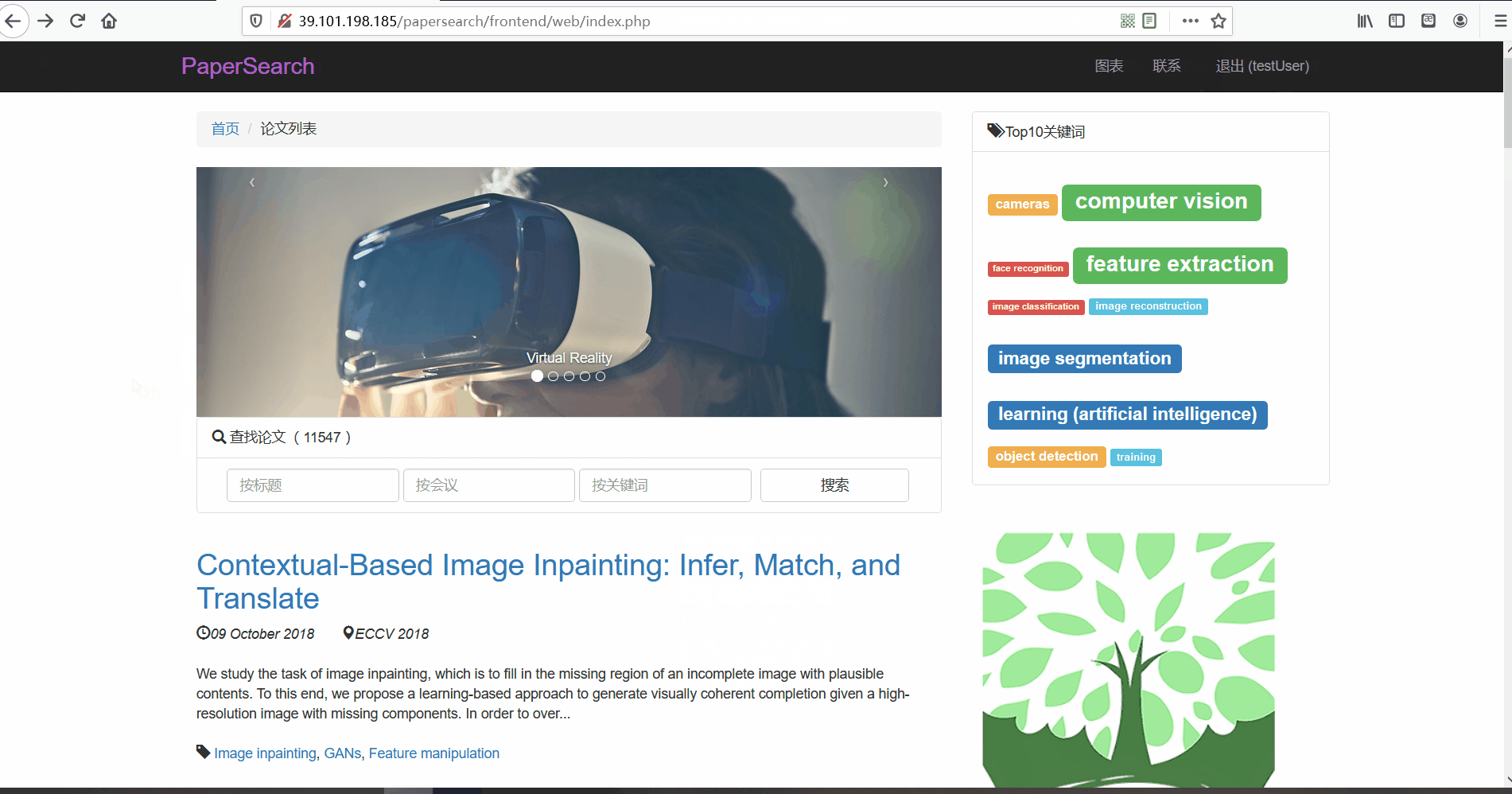
用户登录与注册
-
功能描述:在前台页面,用户可以进行账号的注册与登录。用户在注册时会,网页会检测用户名是否已经存在以及邮箱格式是否正确的问题,如果无误表单格会显示为绿色。而登录时,同样会会判断用户名与密码正确性。并且用户只有在登录后才可以查看论文详情页面。
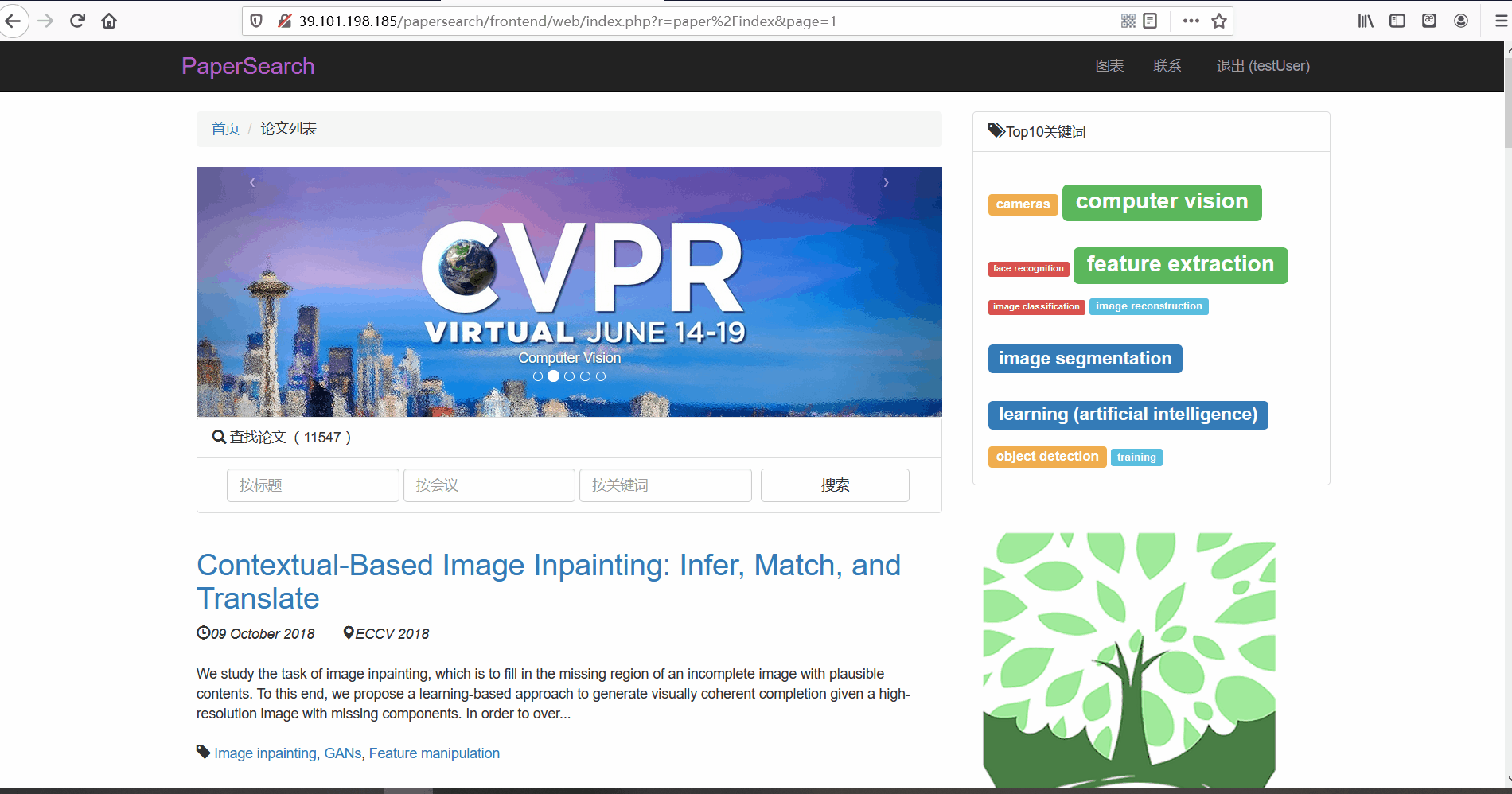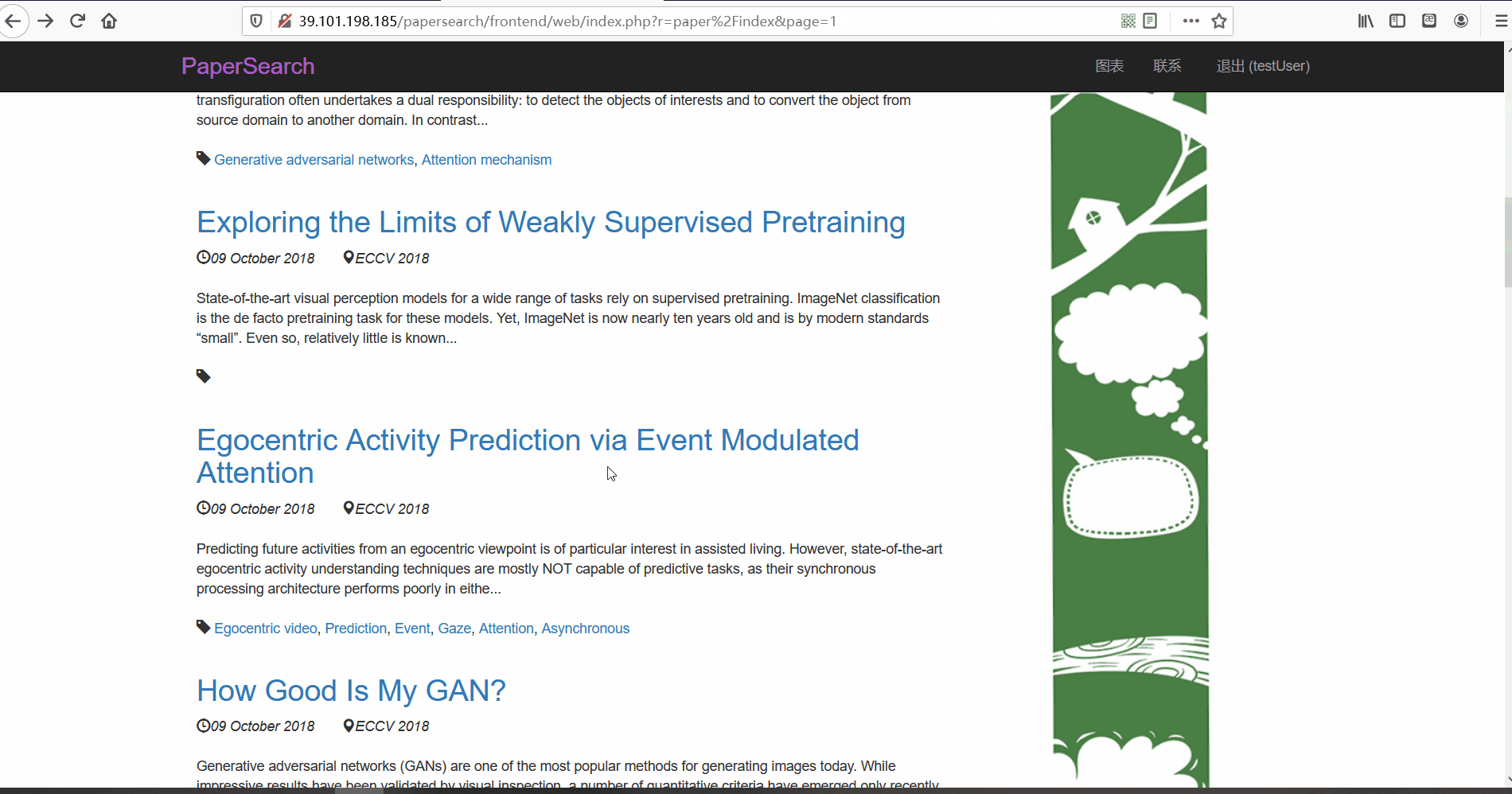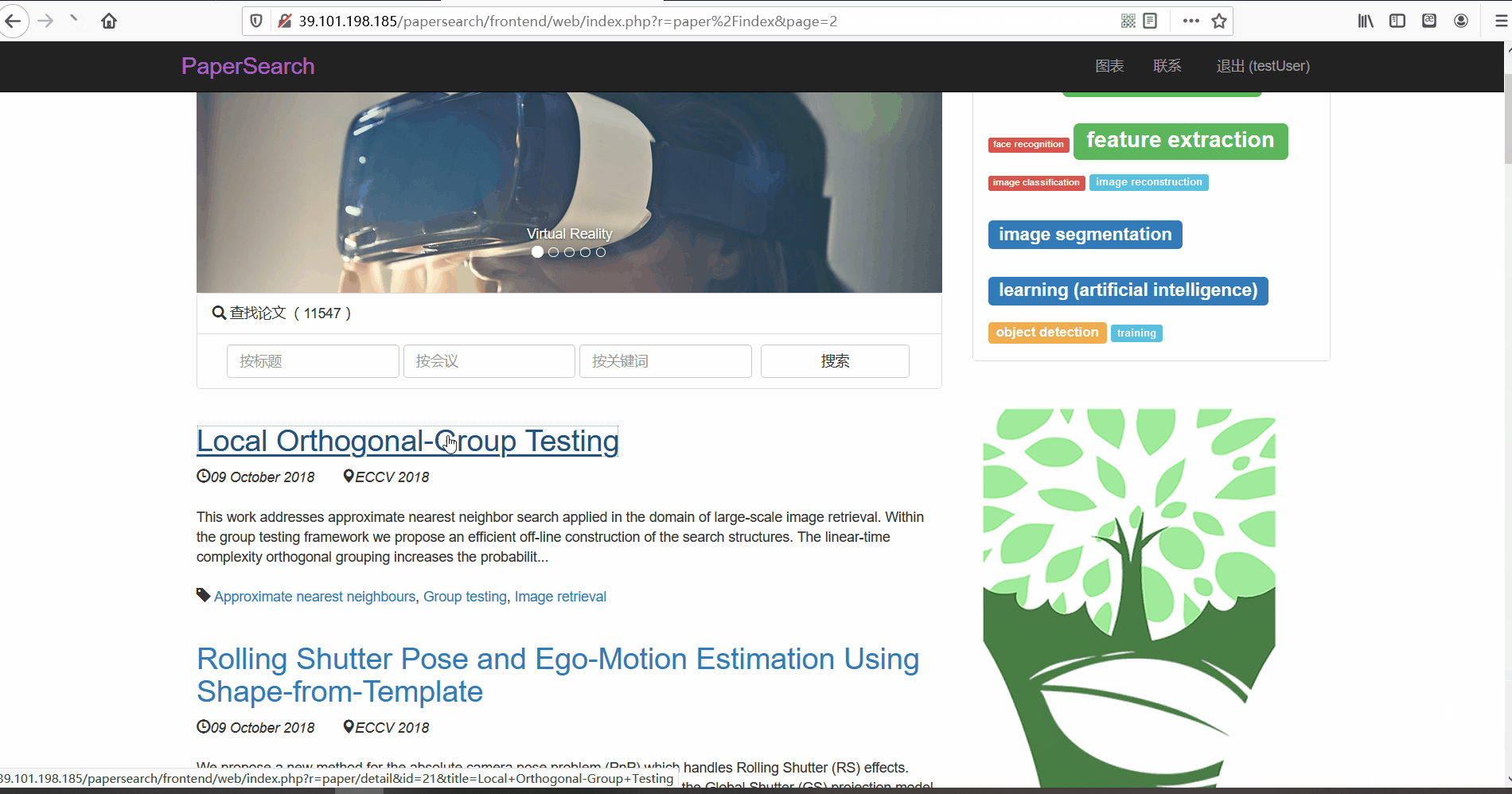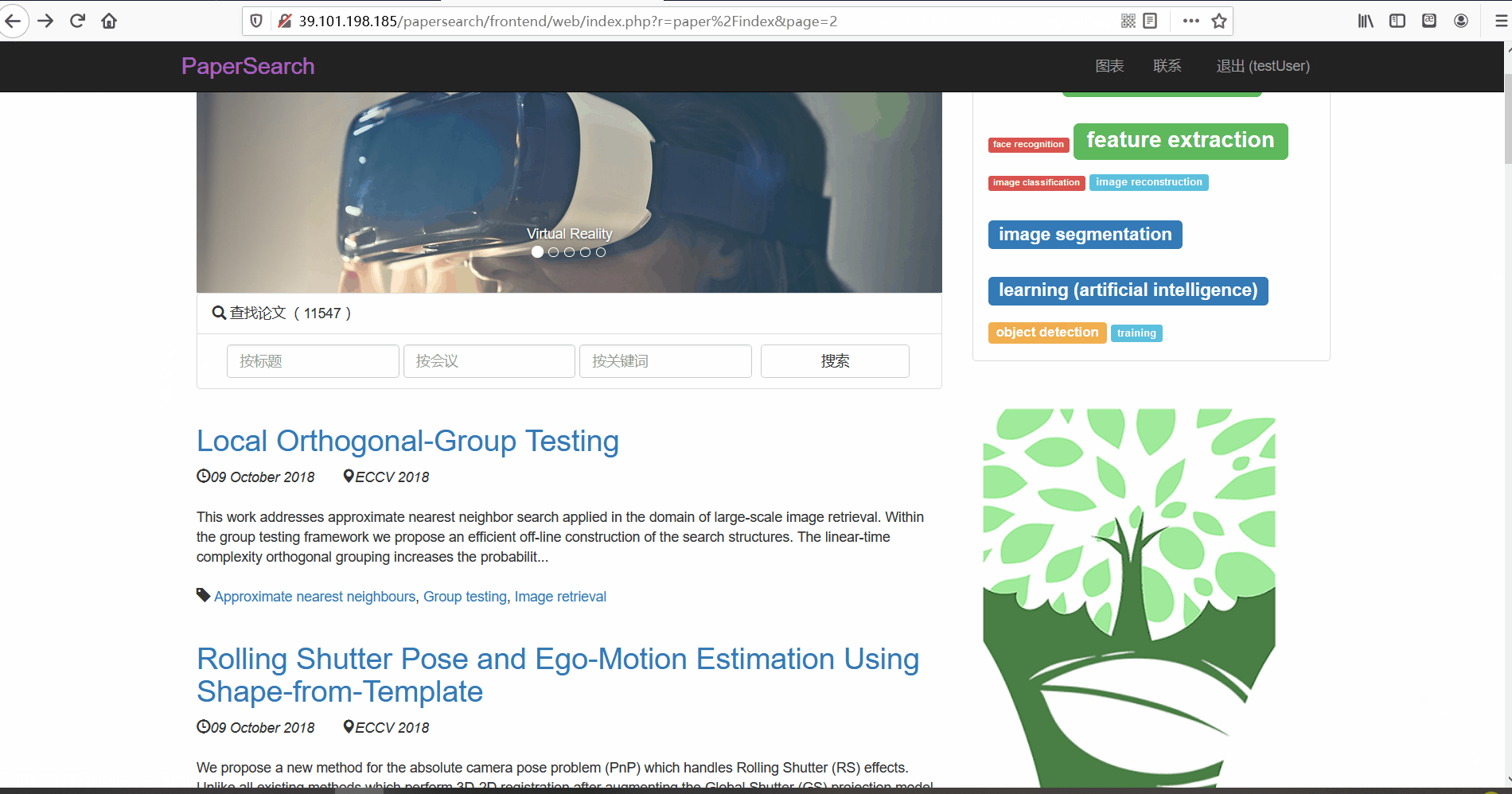
论文列表与论文详情 -
功能描述:在论文列表页,用户可以查看论文的标题、摘要、发布时间、论文所属的会议以及关键词。并且用户可以点击论文标题对论文详情进行查看。
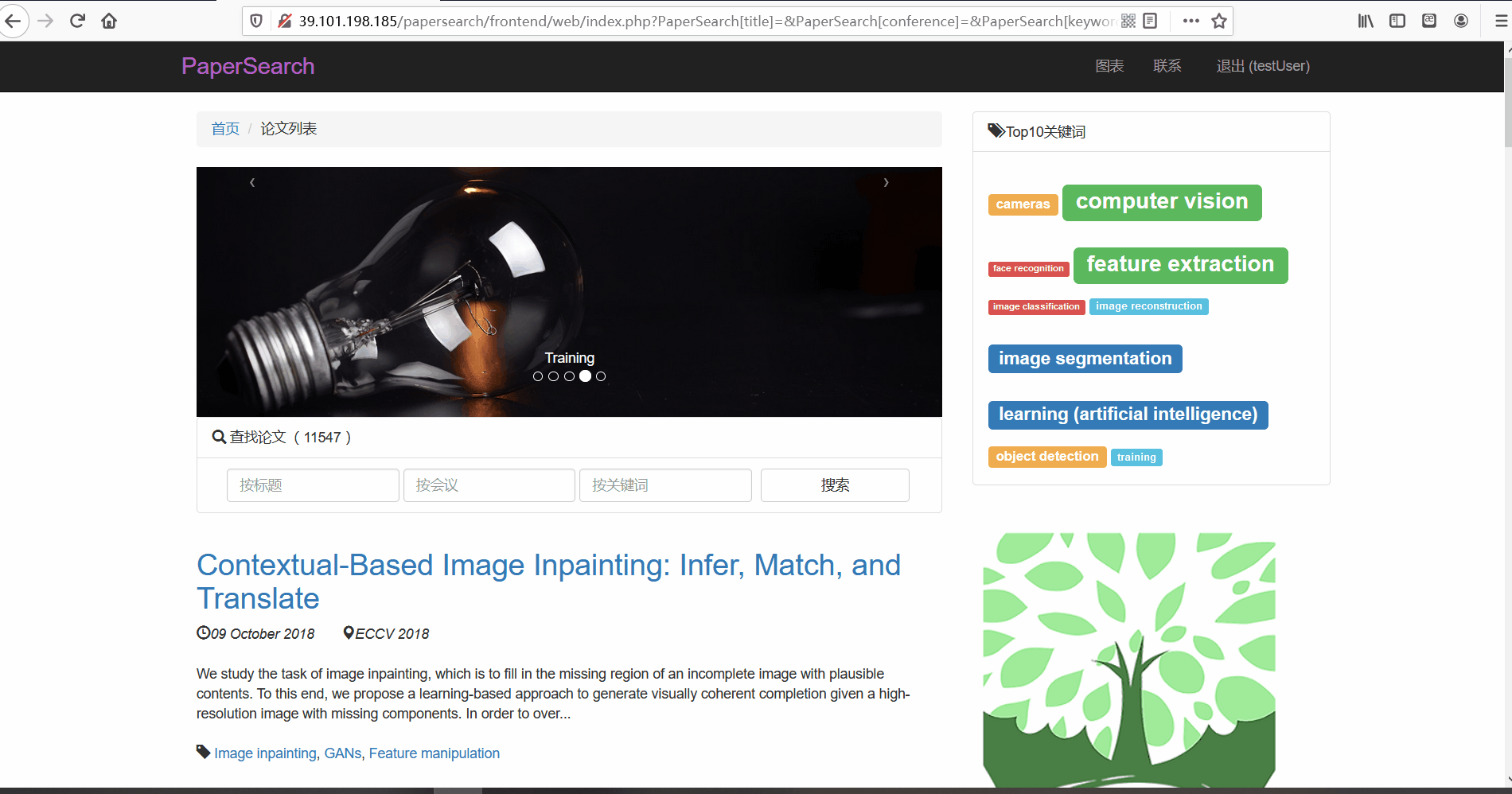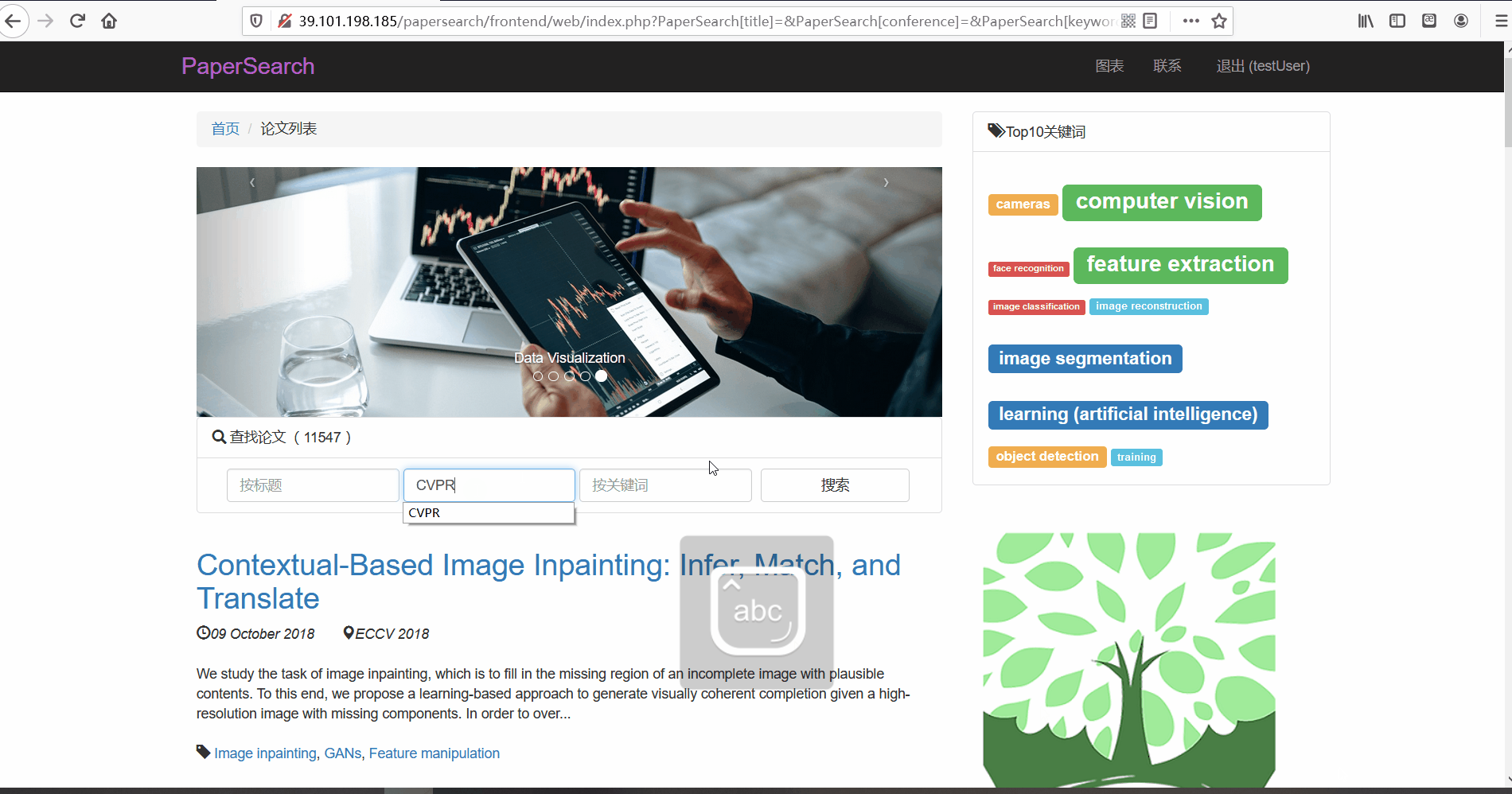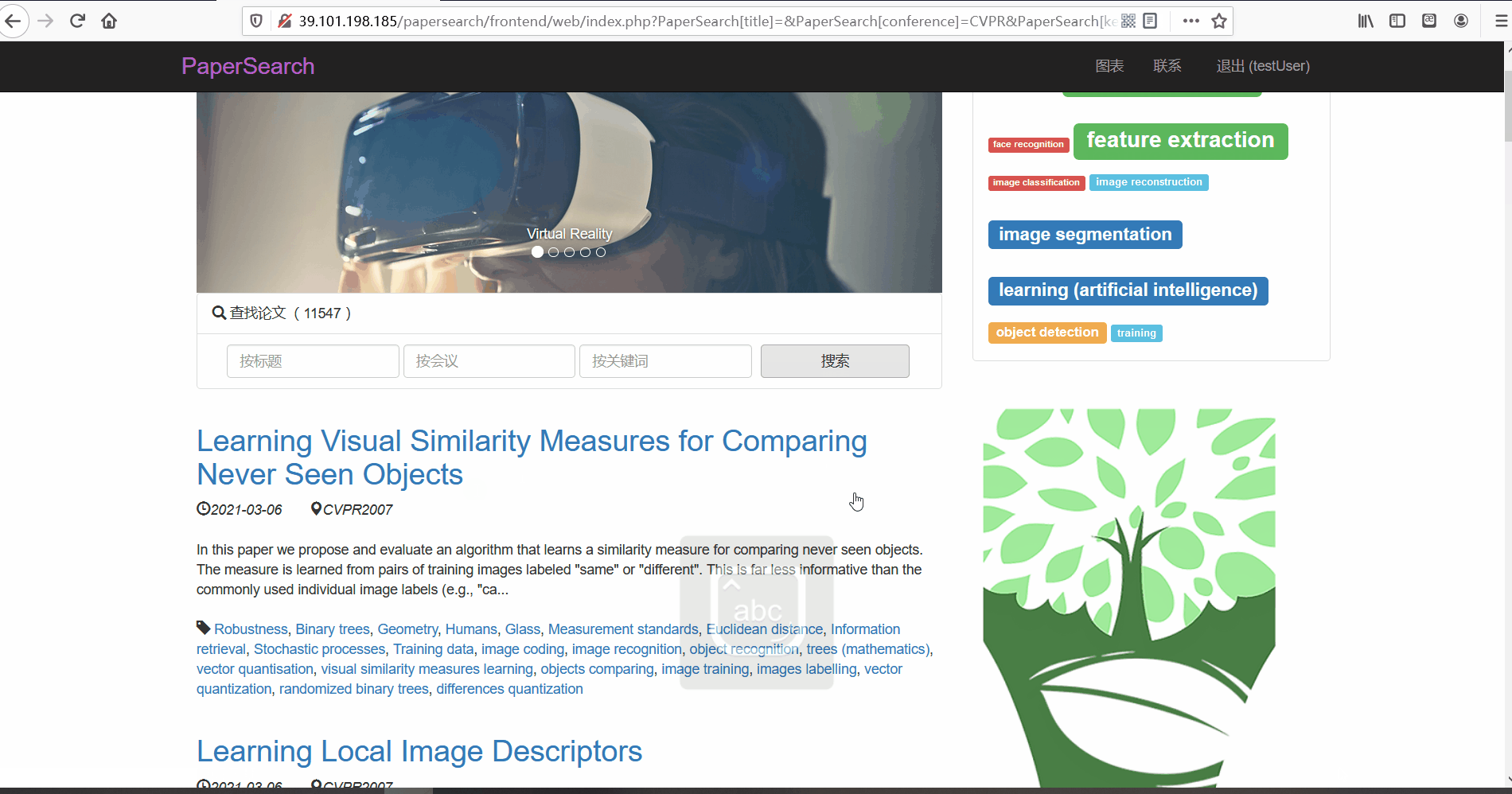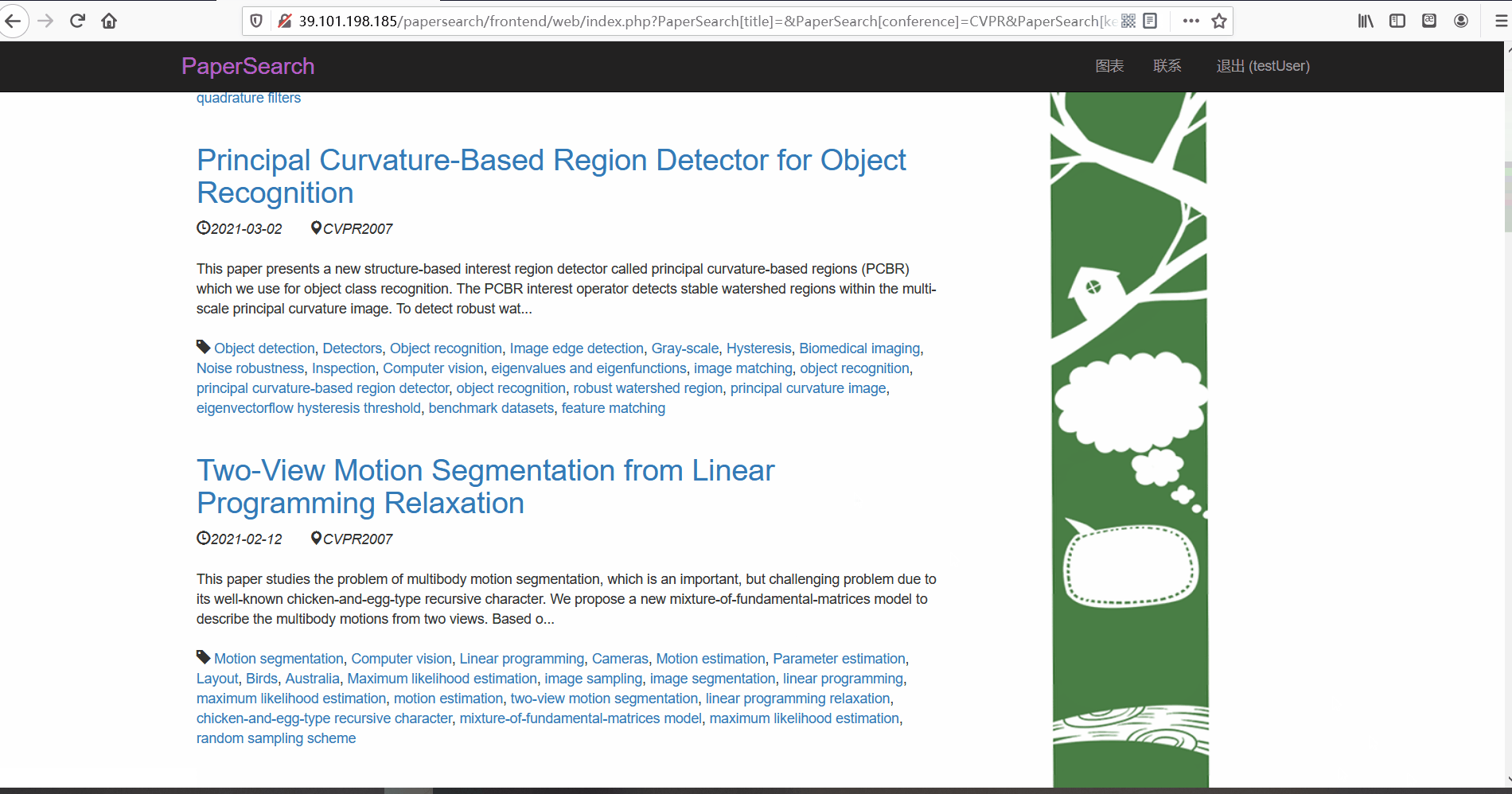
论文搜索
- 功能描述:在论文列表页,用户可以对论文进行搜索。用户可以使用顶部的论文搜索框按三种不同的方式进行搜索,分别可以根据论文的标题、所属会议以及关键词进行搜索。
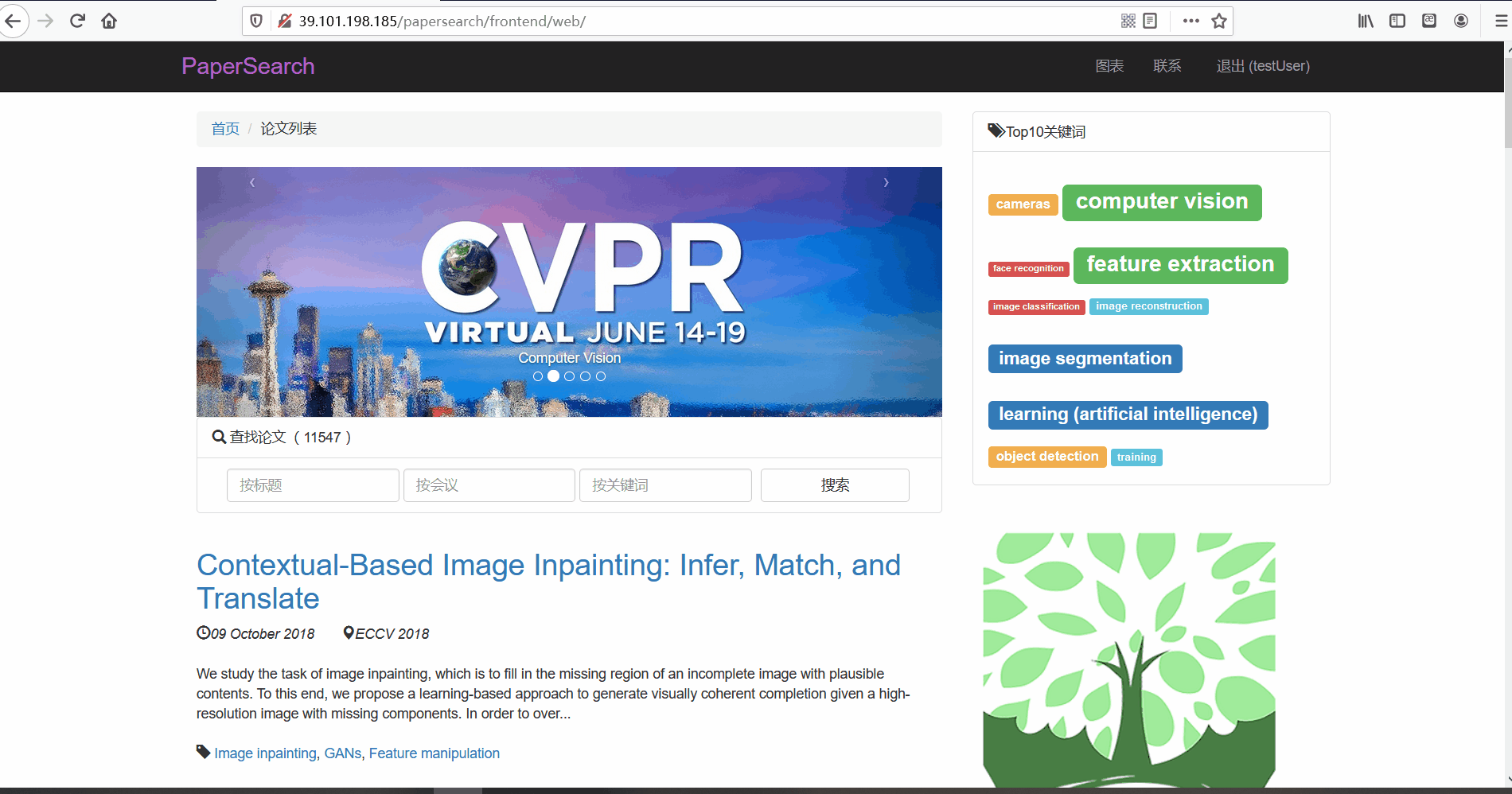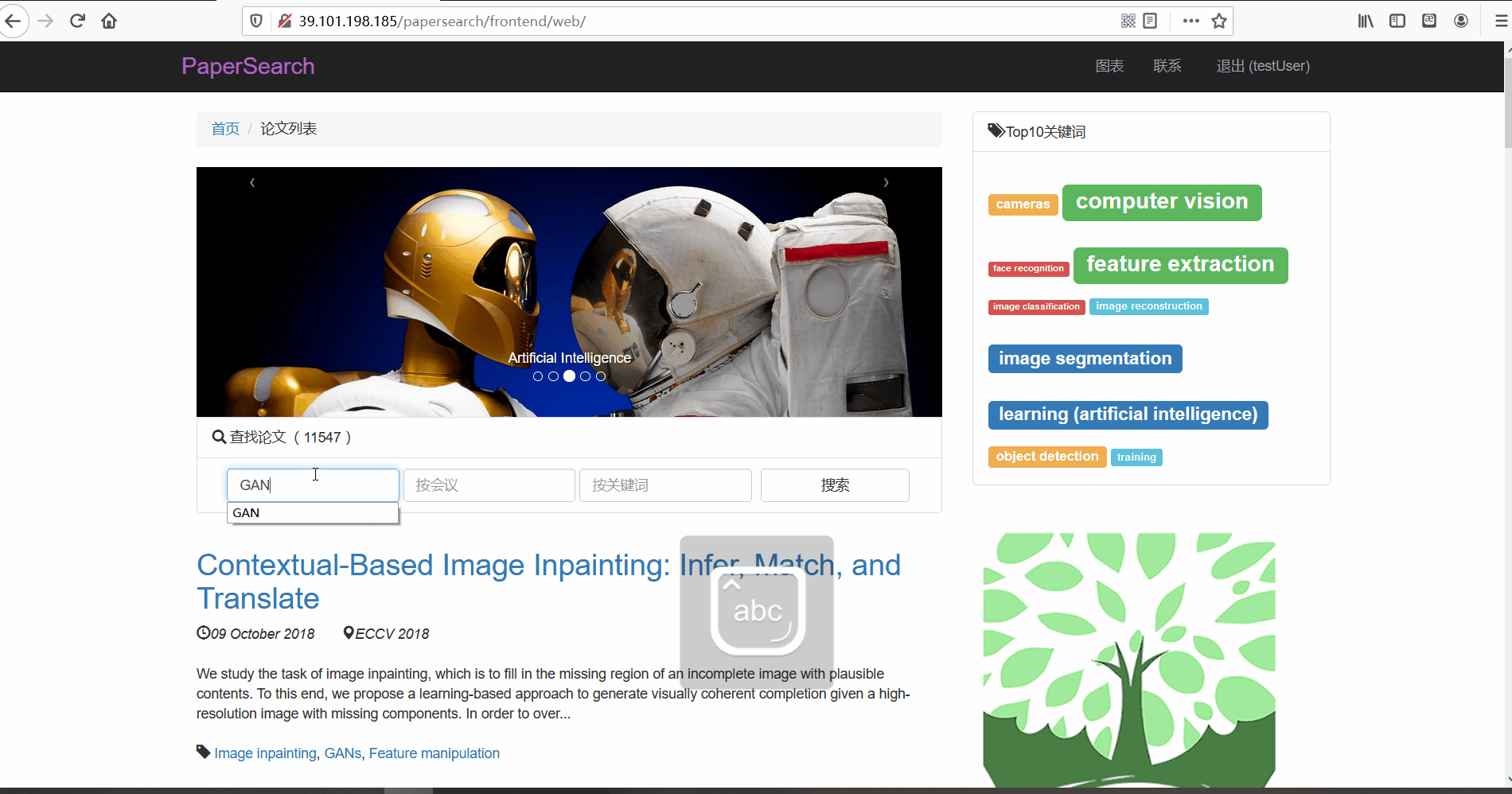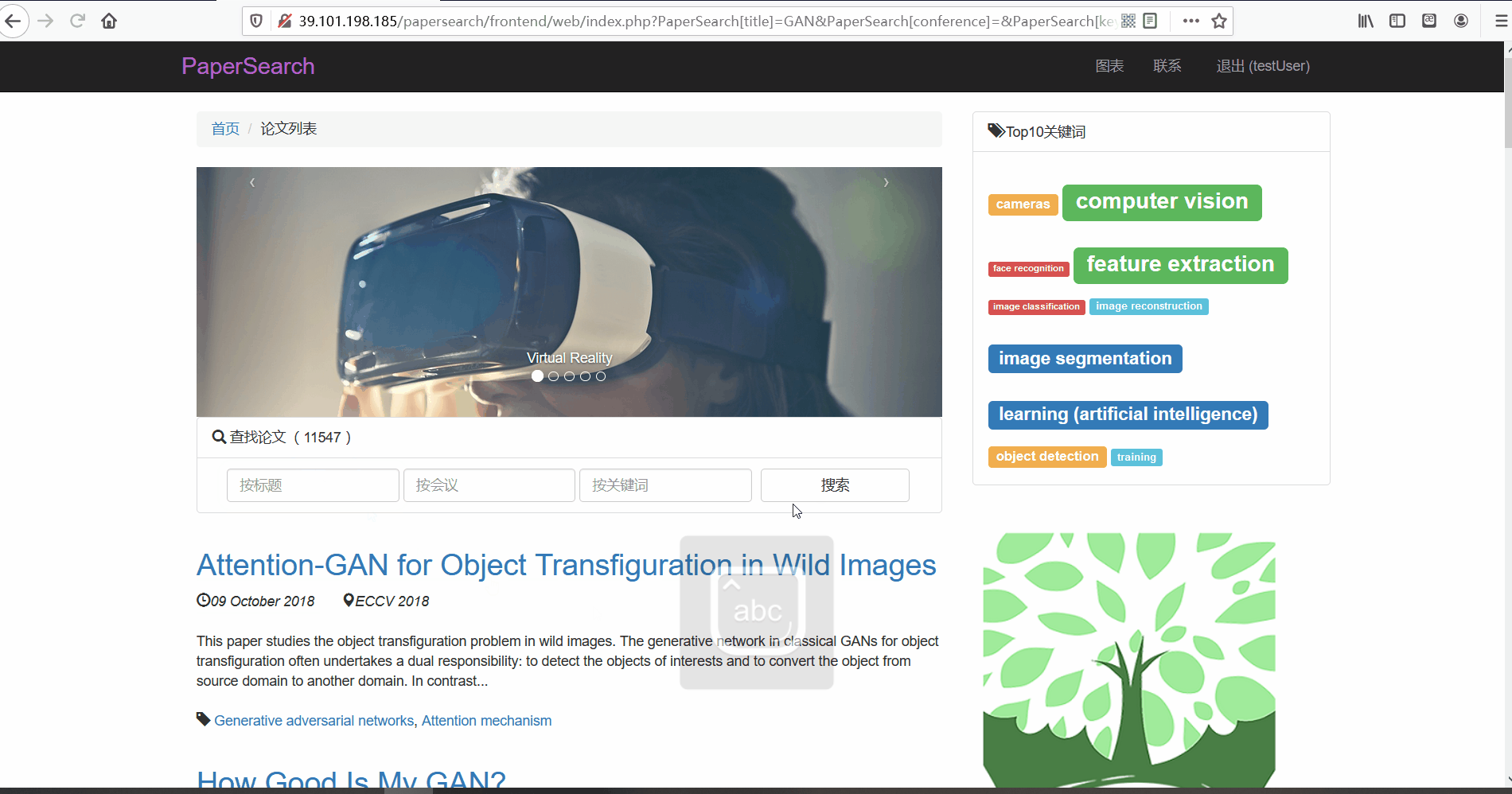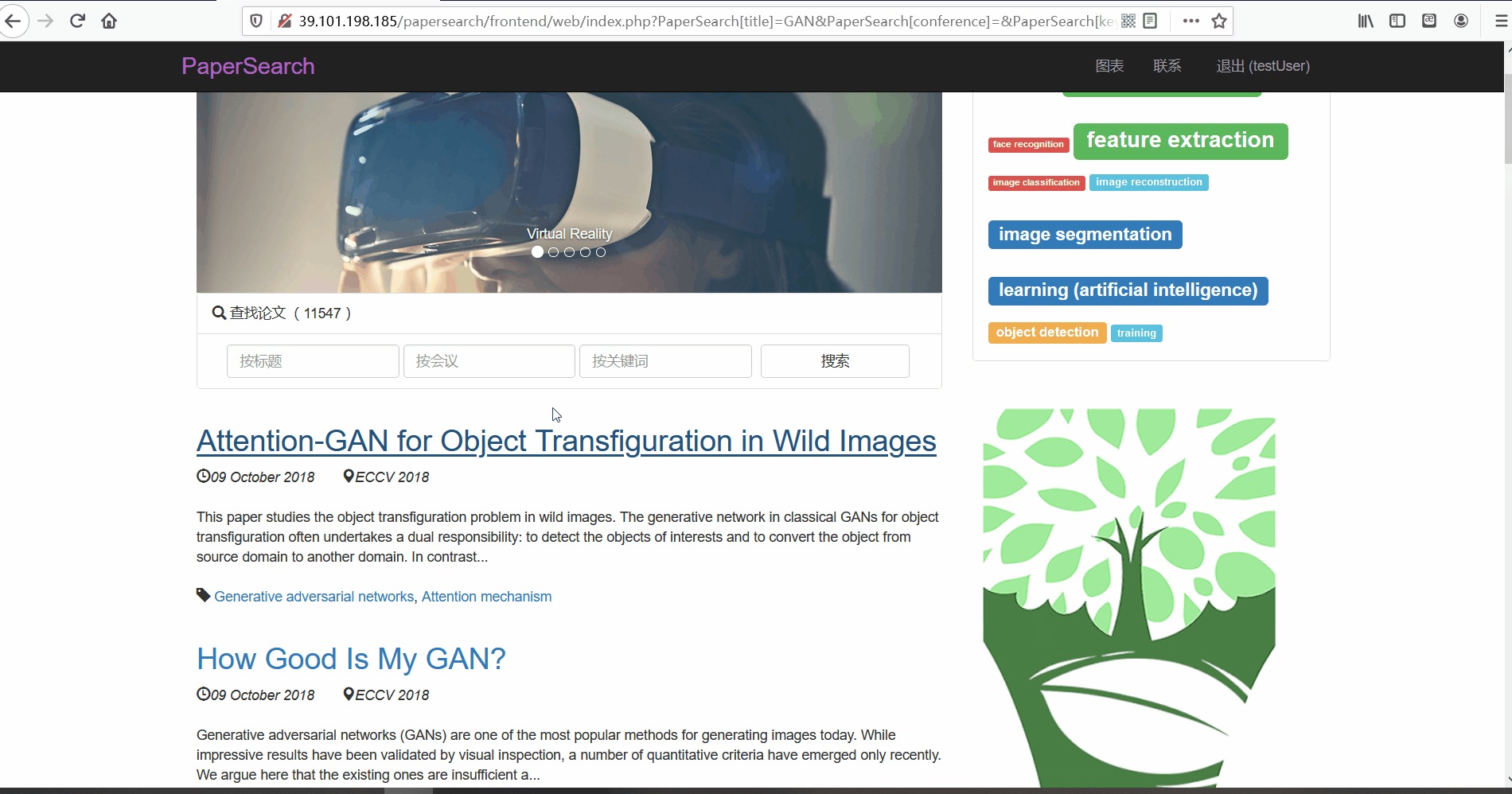
- 按标题搜索
- 按会议搜索
- 按关键词搜索
- 按标题搜索
十大热词词云图
- 功能描述:展示所有论文中出现频率最高的十个词汇,用户也可以点击词卡对论文进行搜索
分析图表
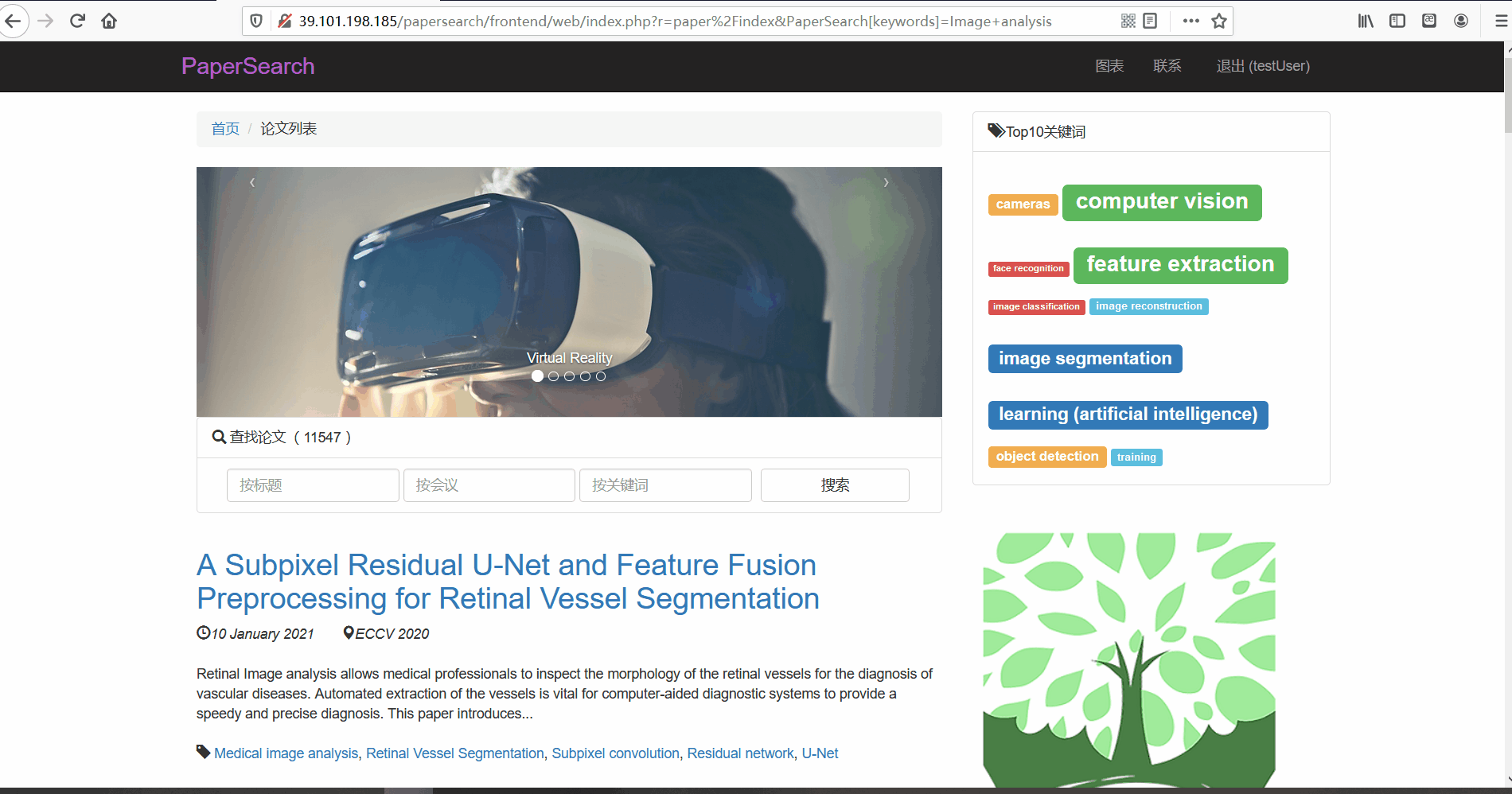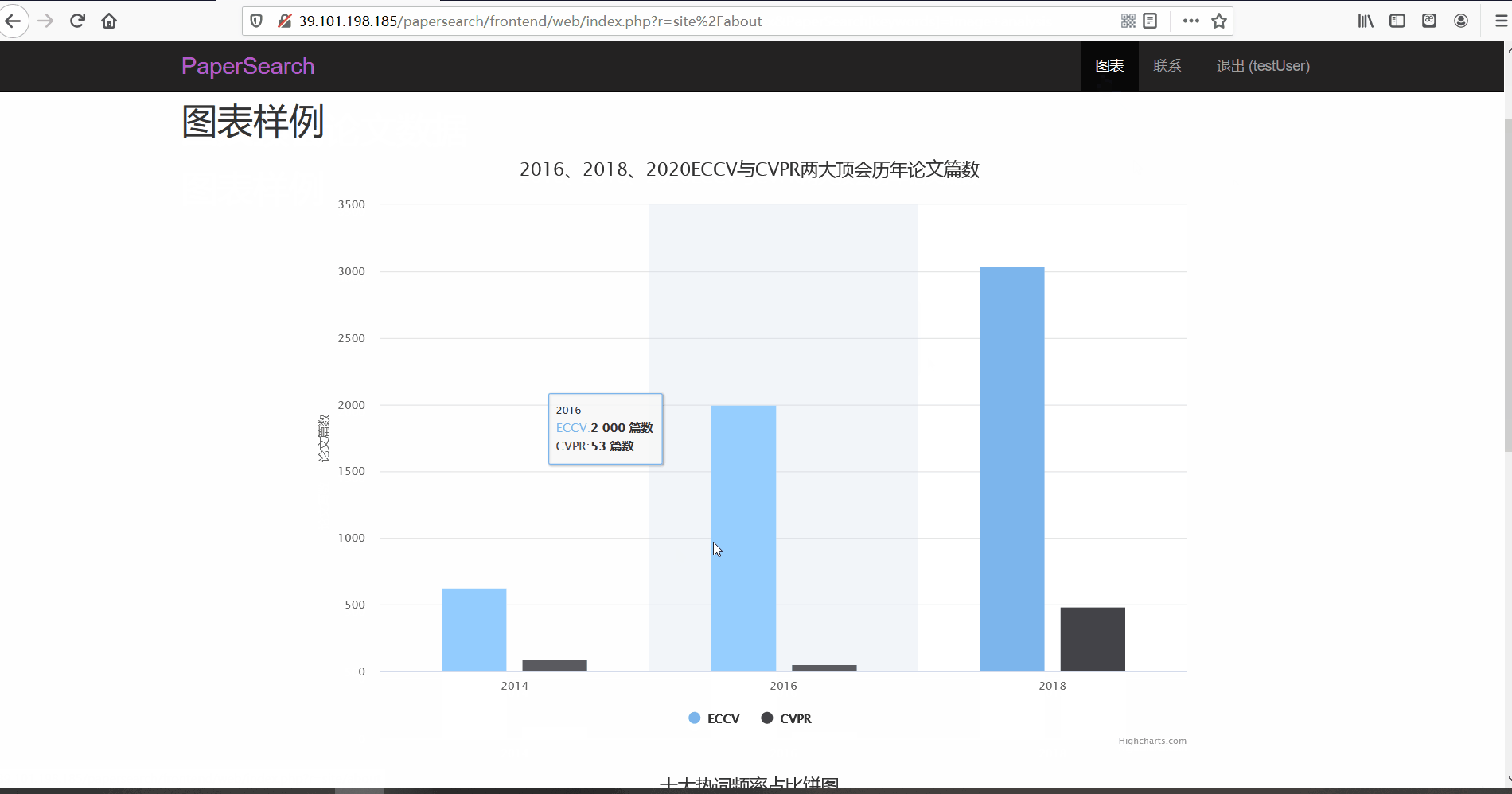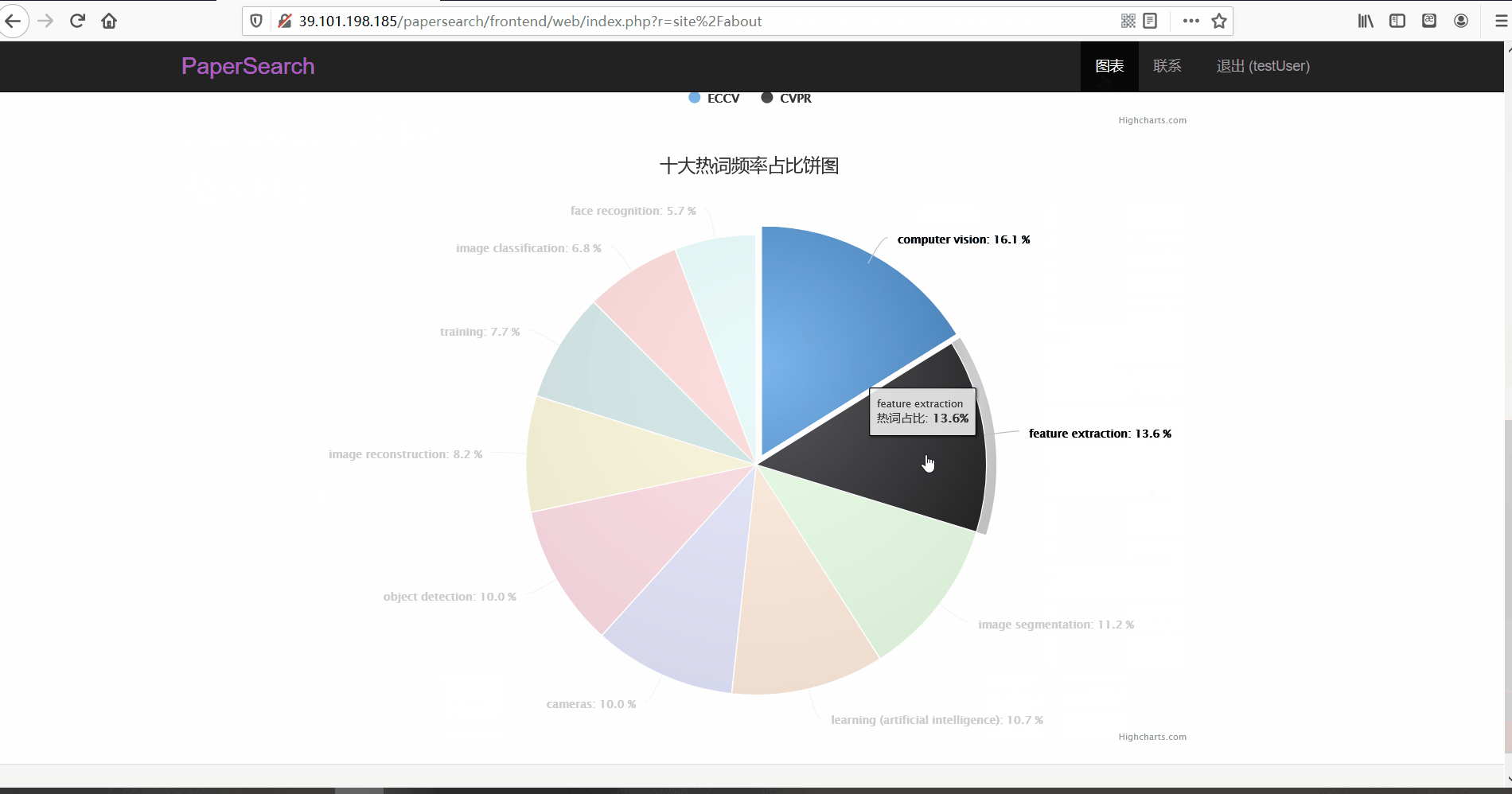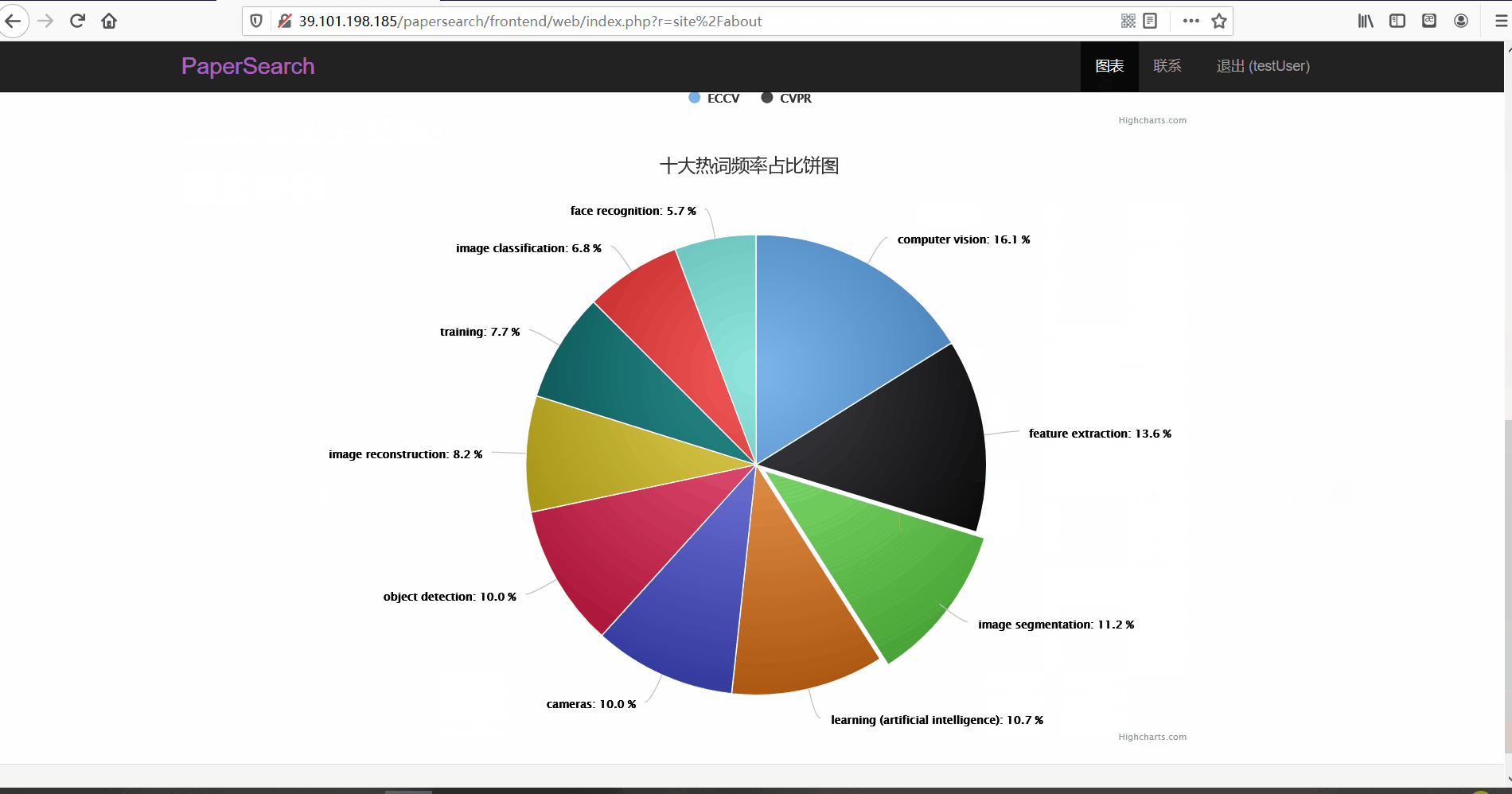
- 功能描述:柱状图:对两大顶会的论文篇数进行比较(注:由于ECCV的举办是两年一次,所以只选取了16、18、20年进行对比分析及展示);饼图:十大热词频率占比
2. 后台功能展示
管理员登录
- 功能描述:在后台界面,管理员需要登录账号来对论文与用户进行管理。并且管理员账号不能进行注册。
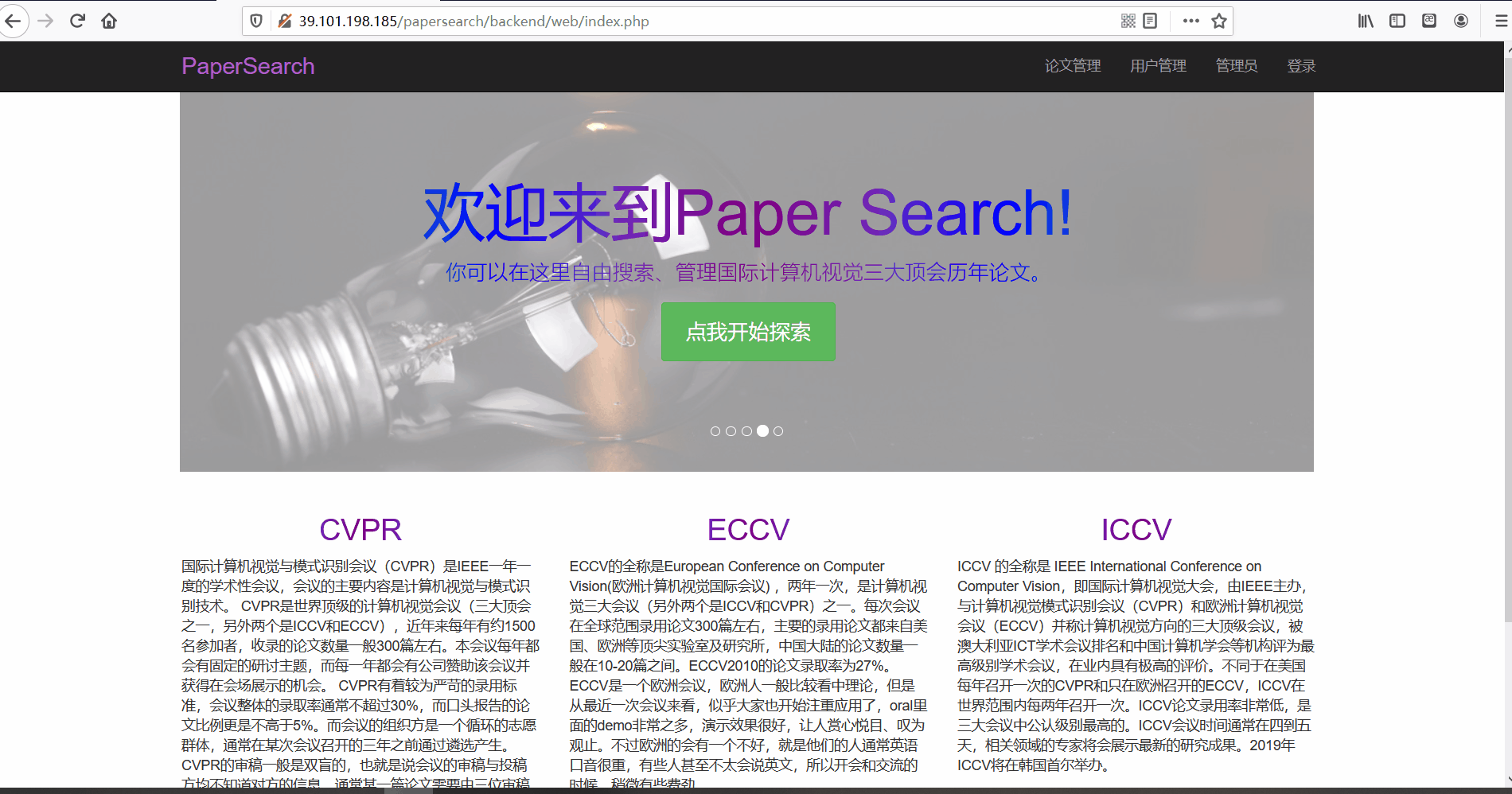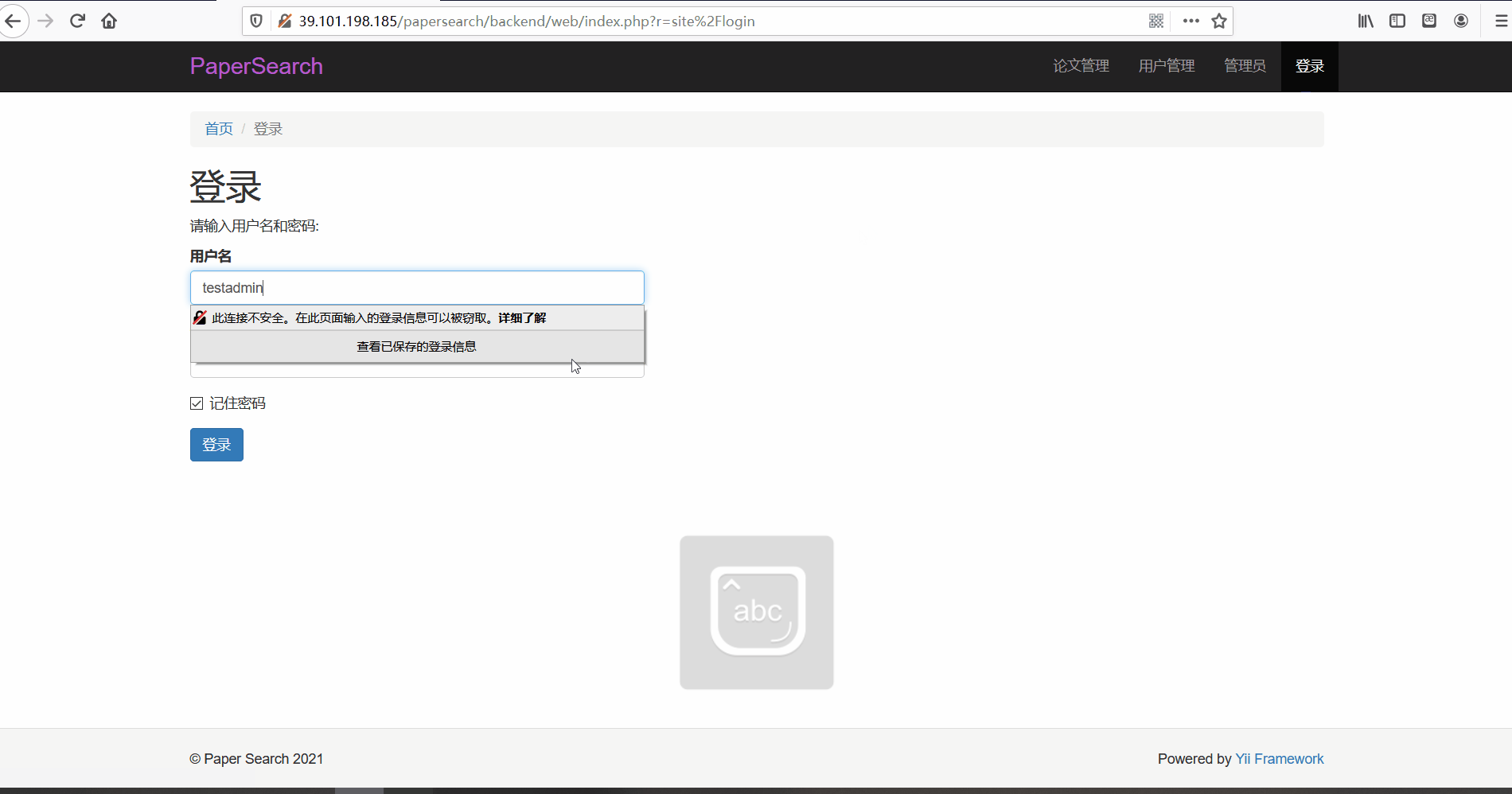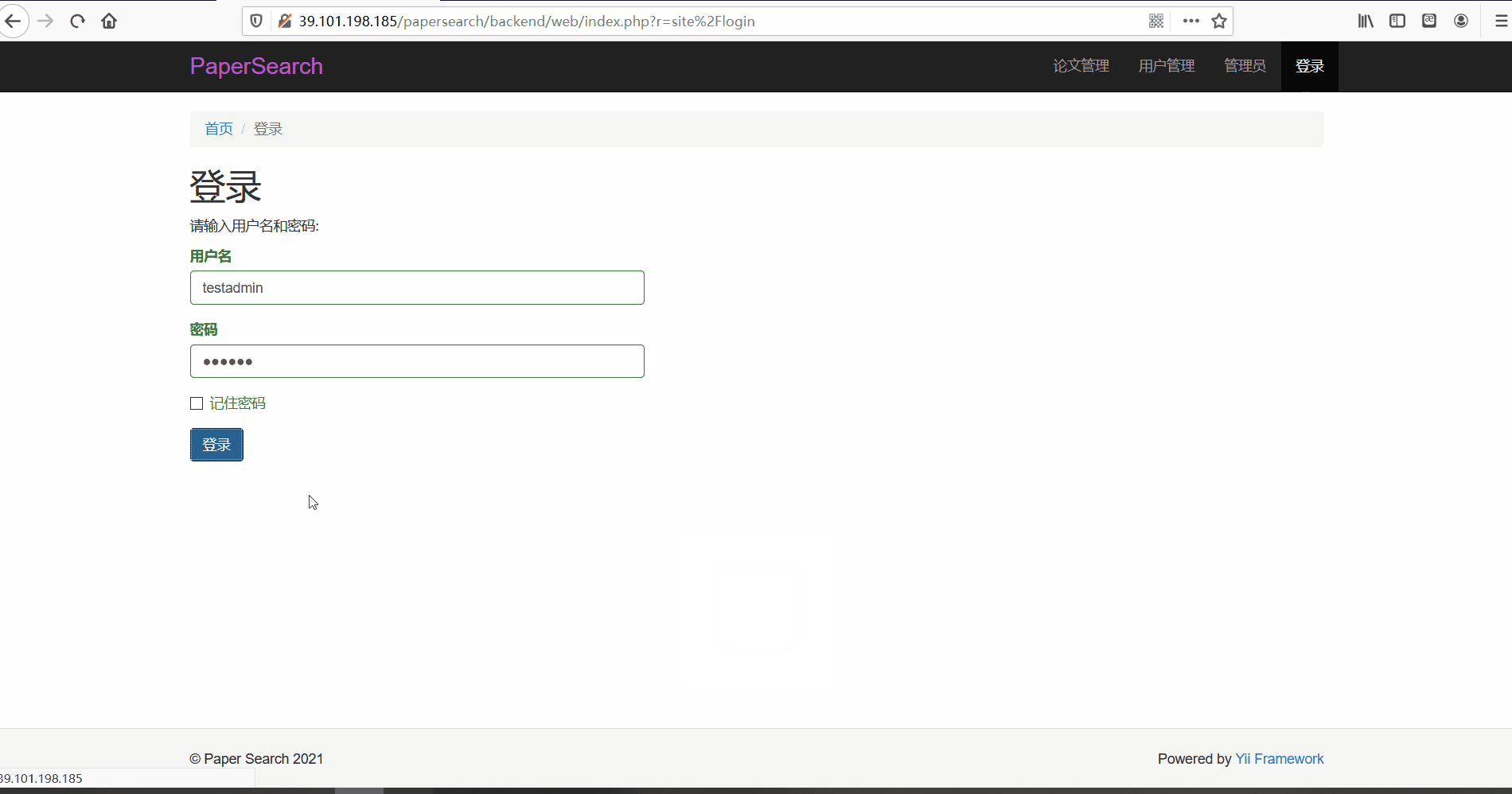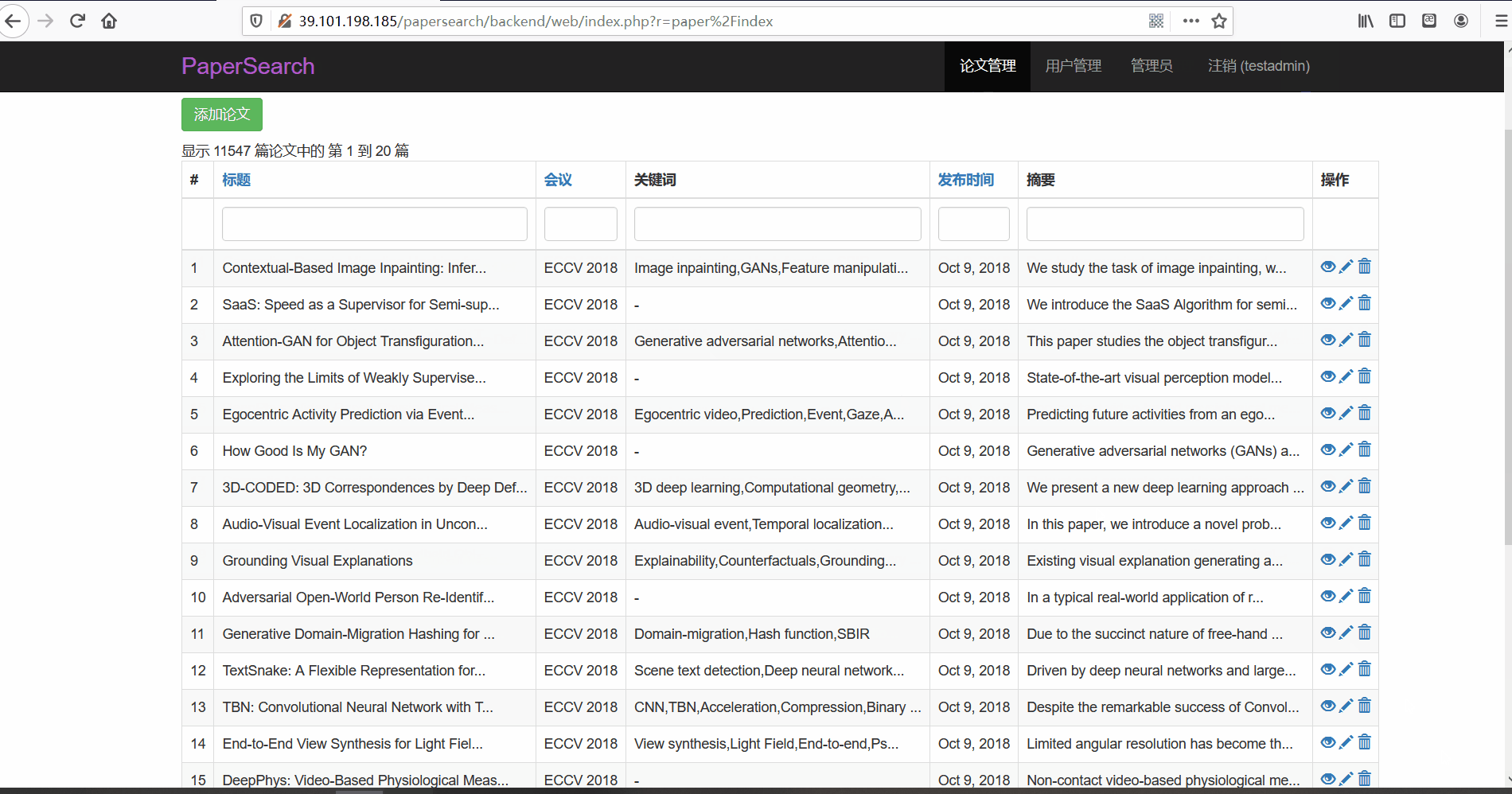
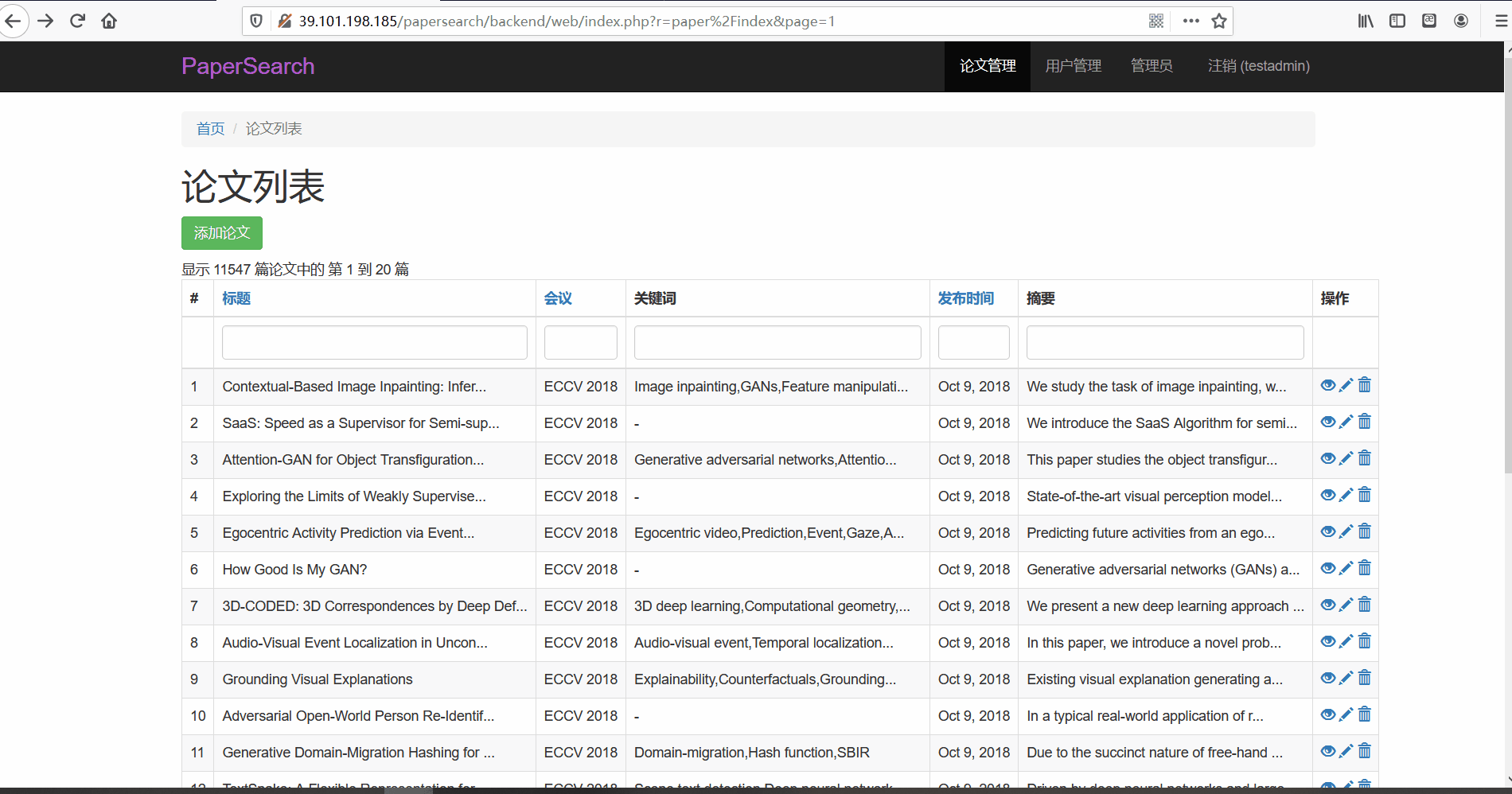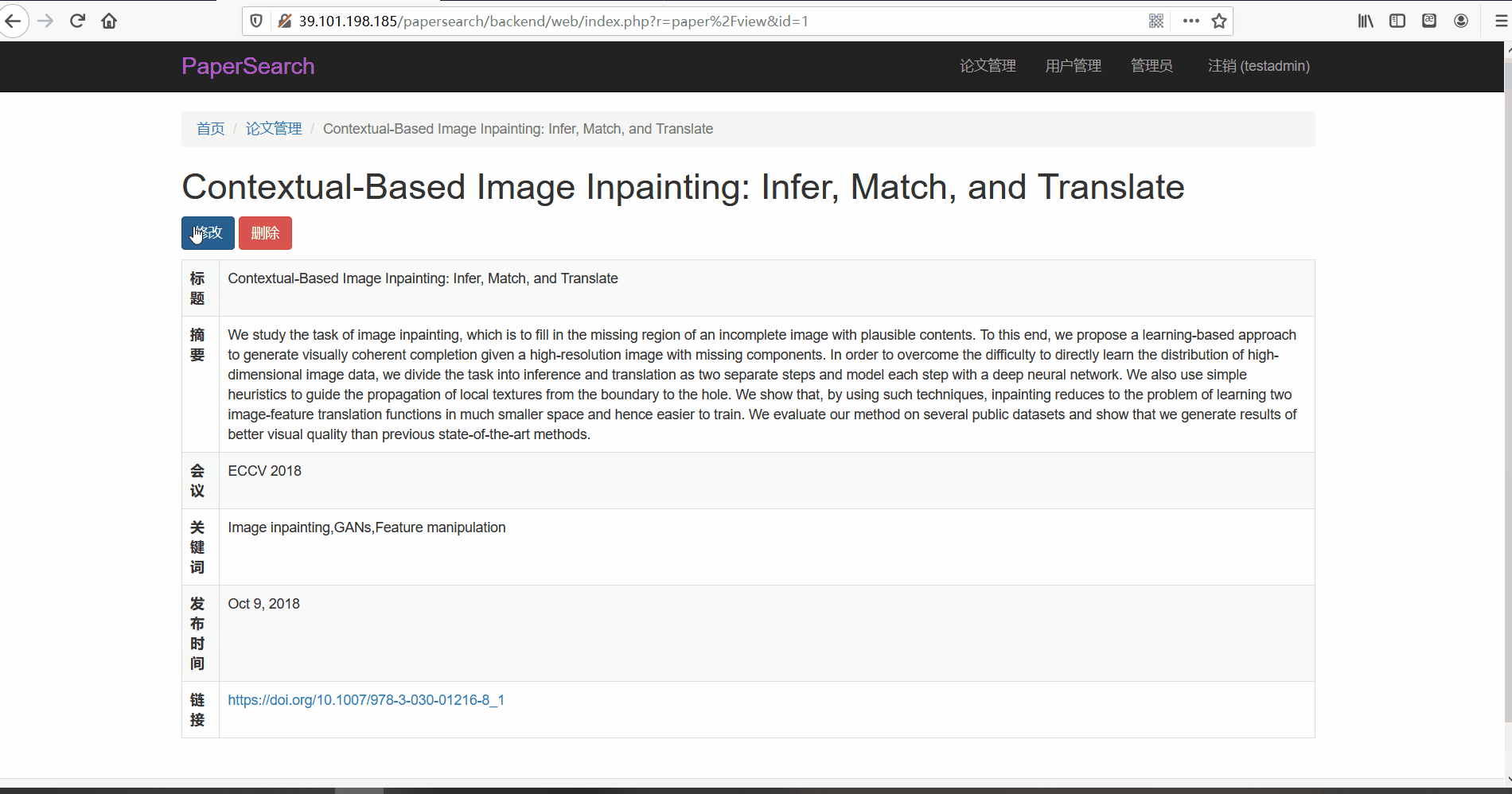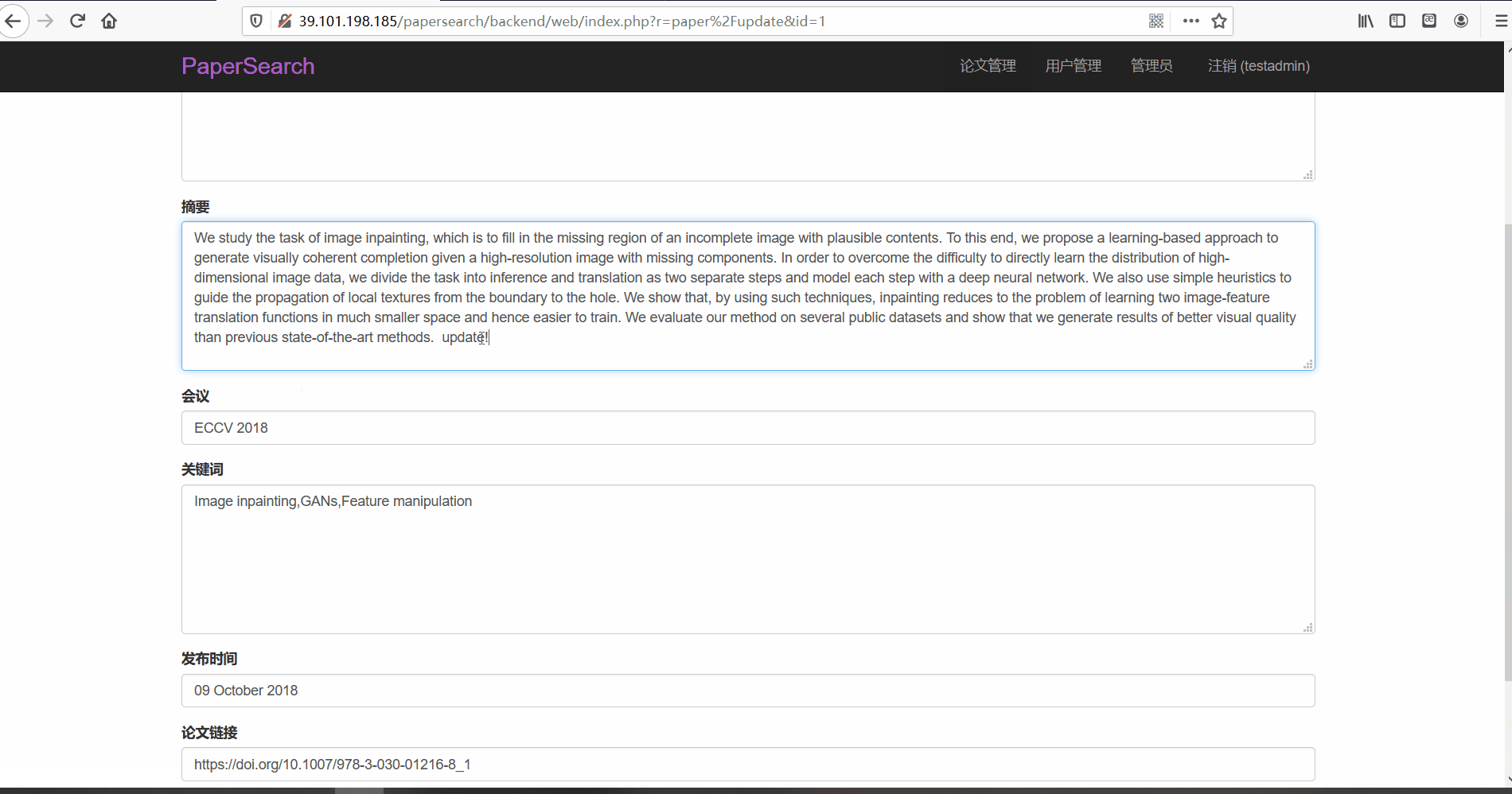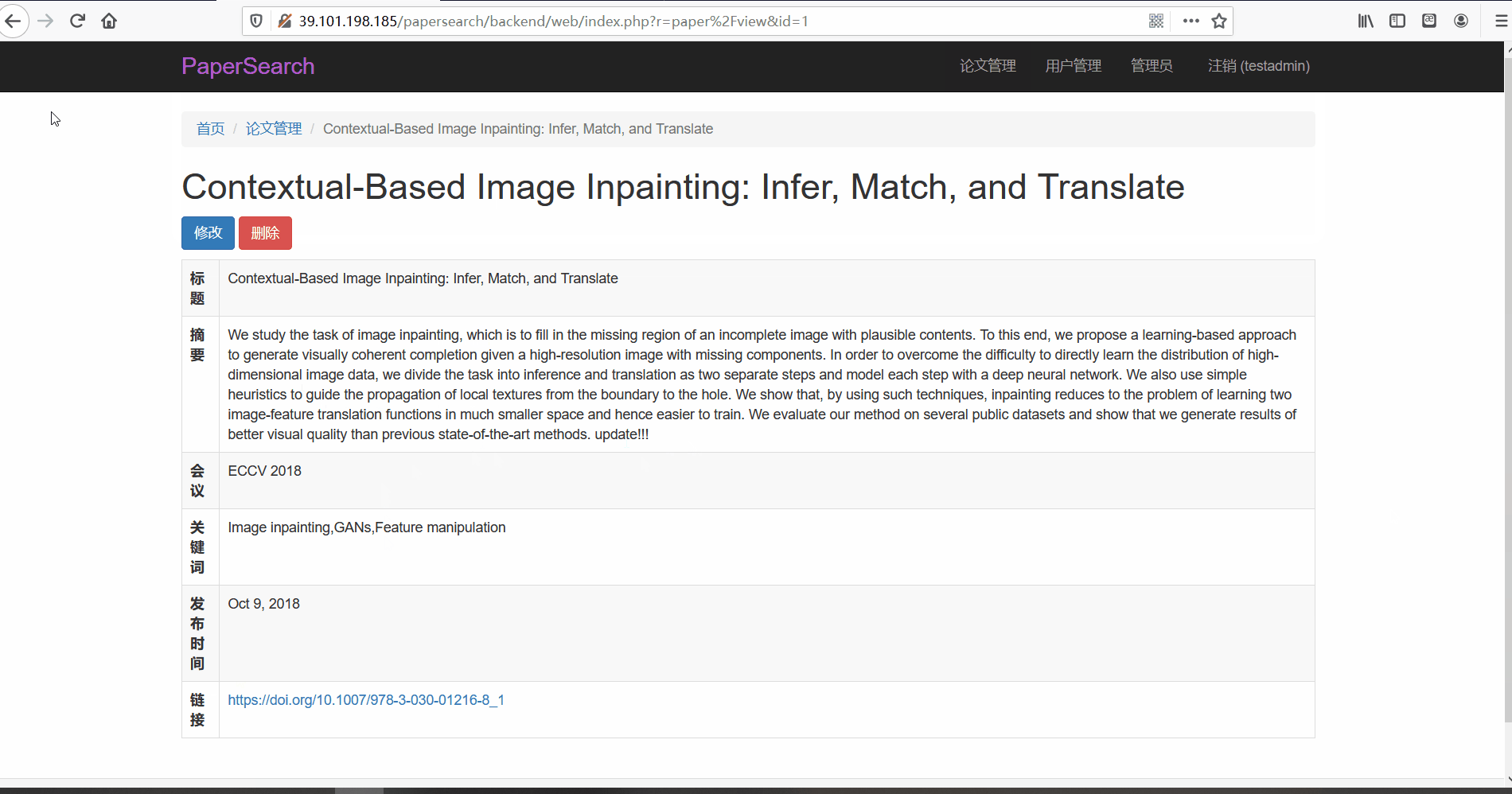
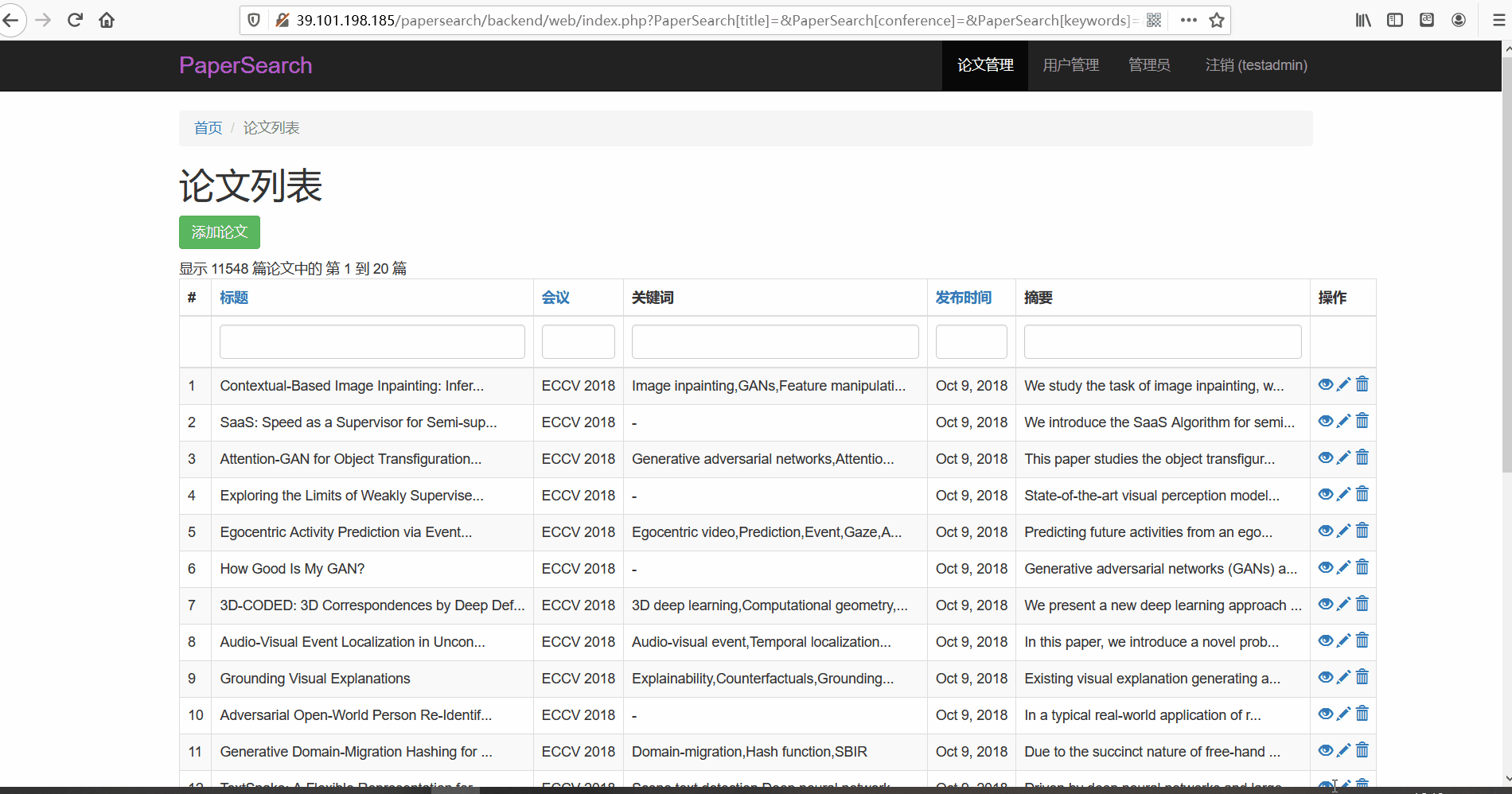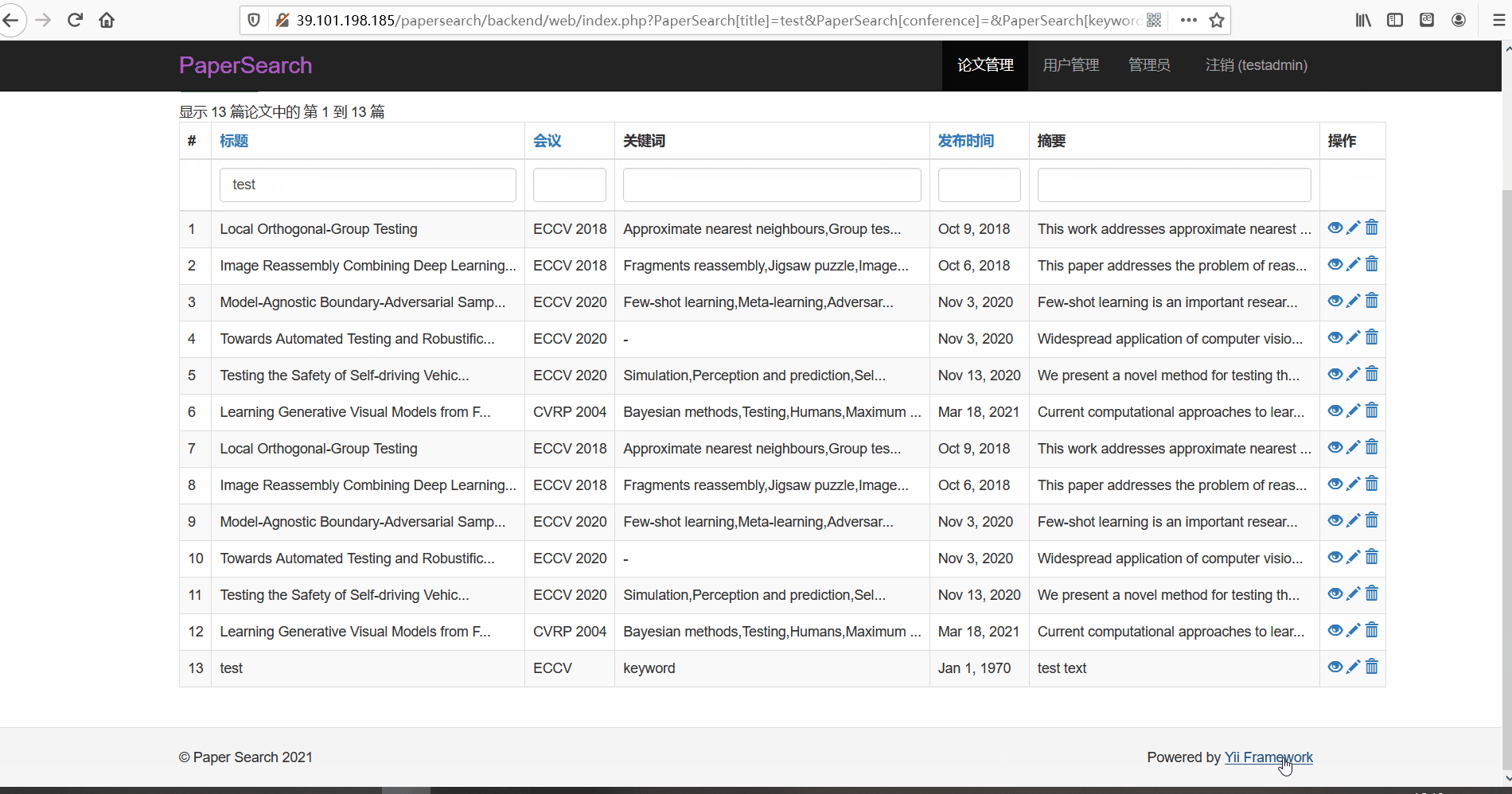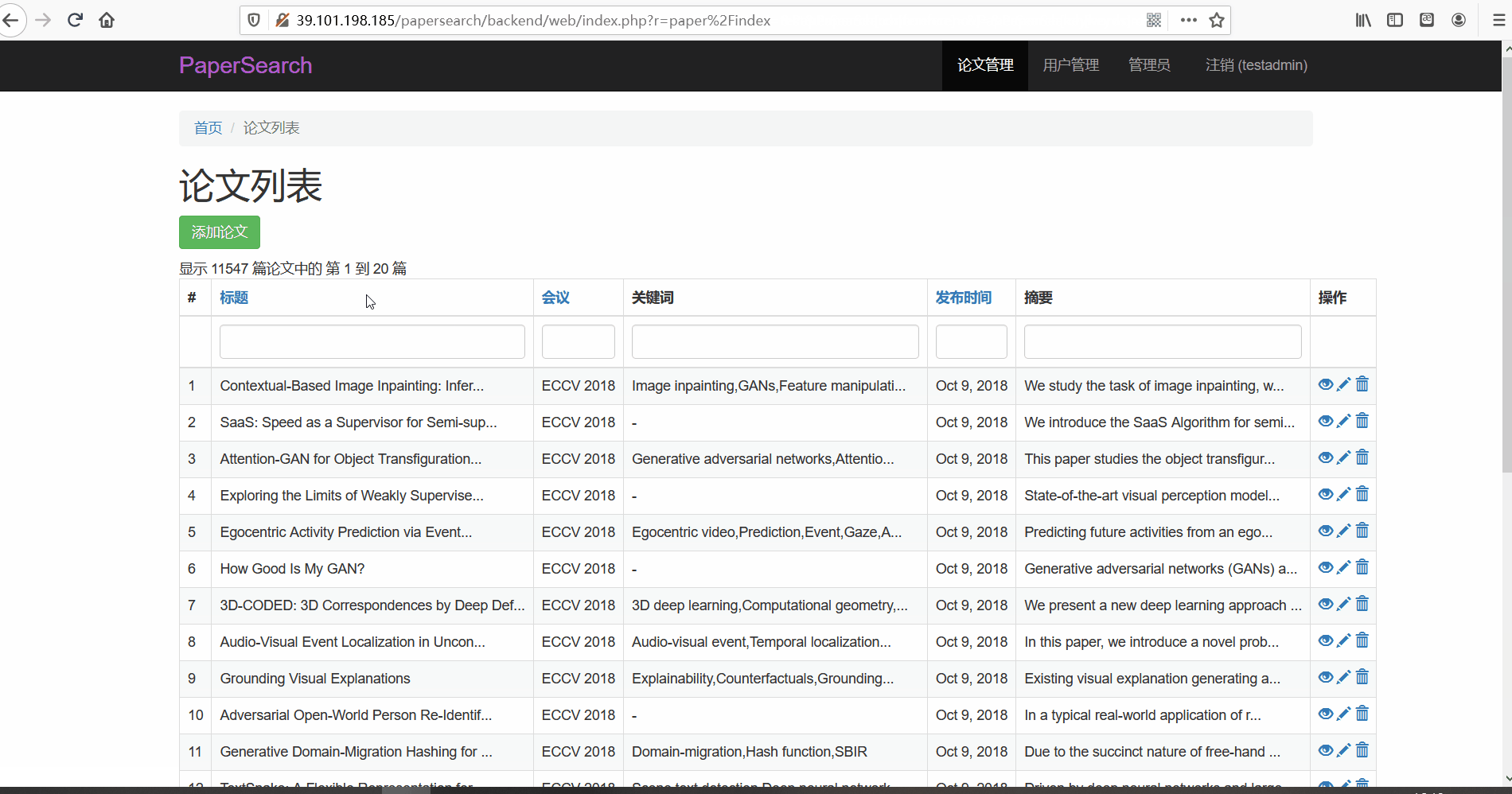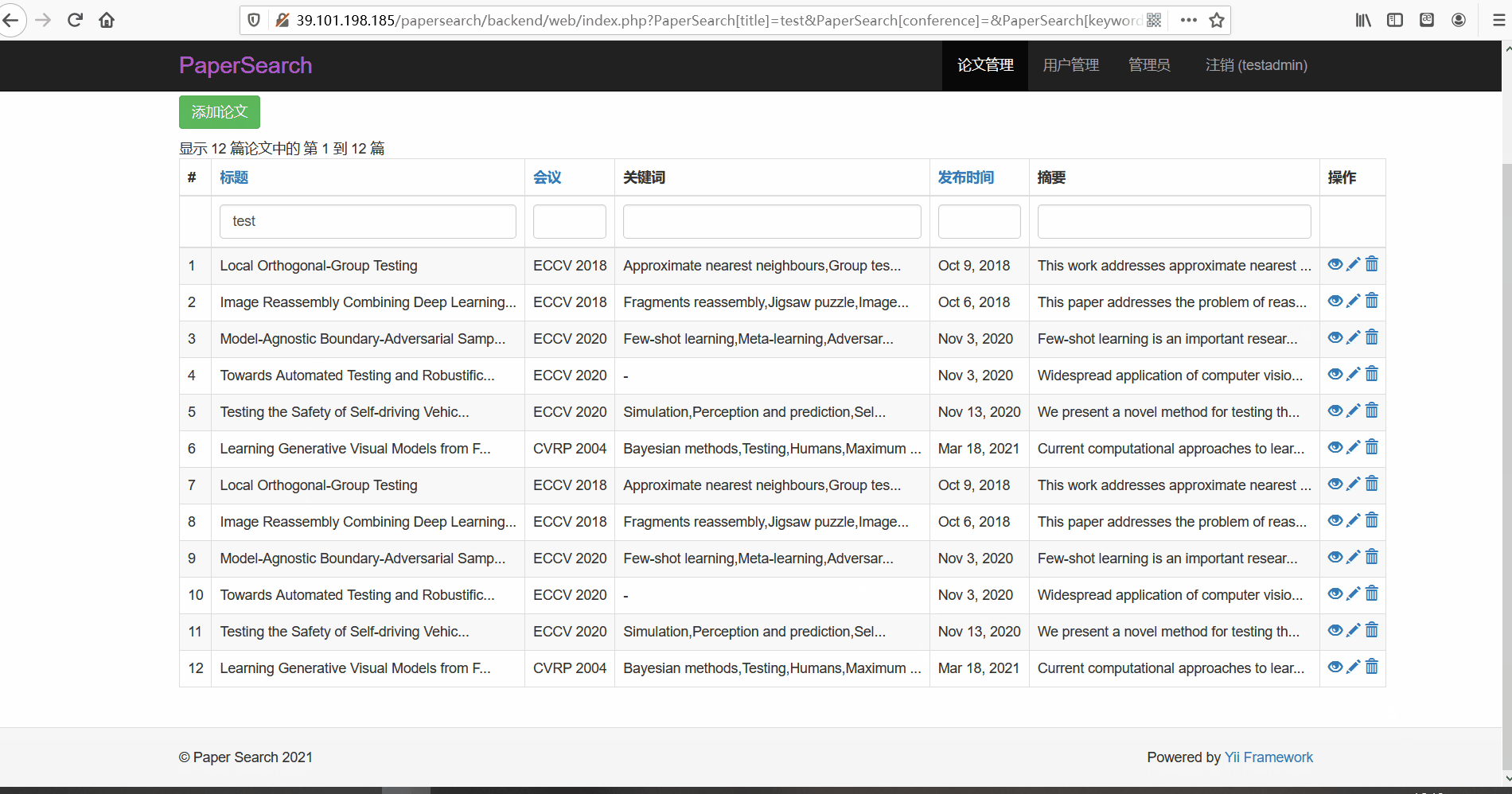
论文管理
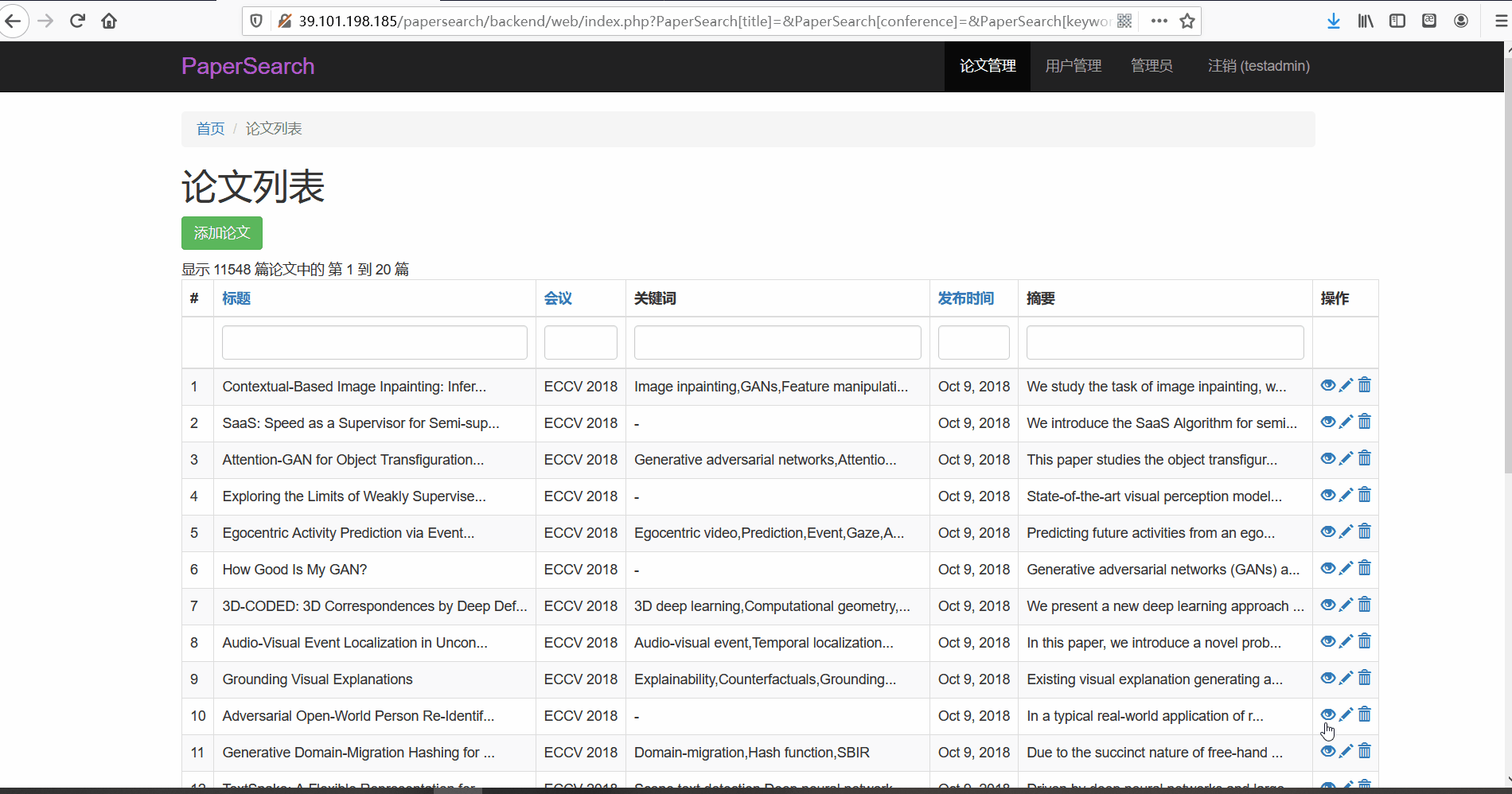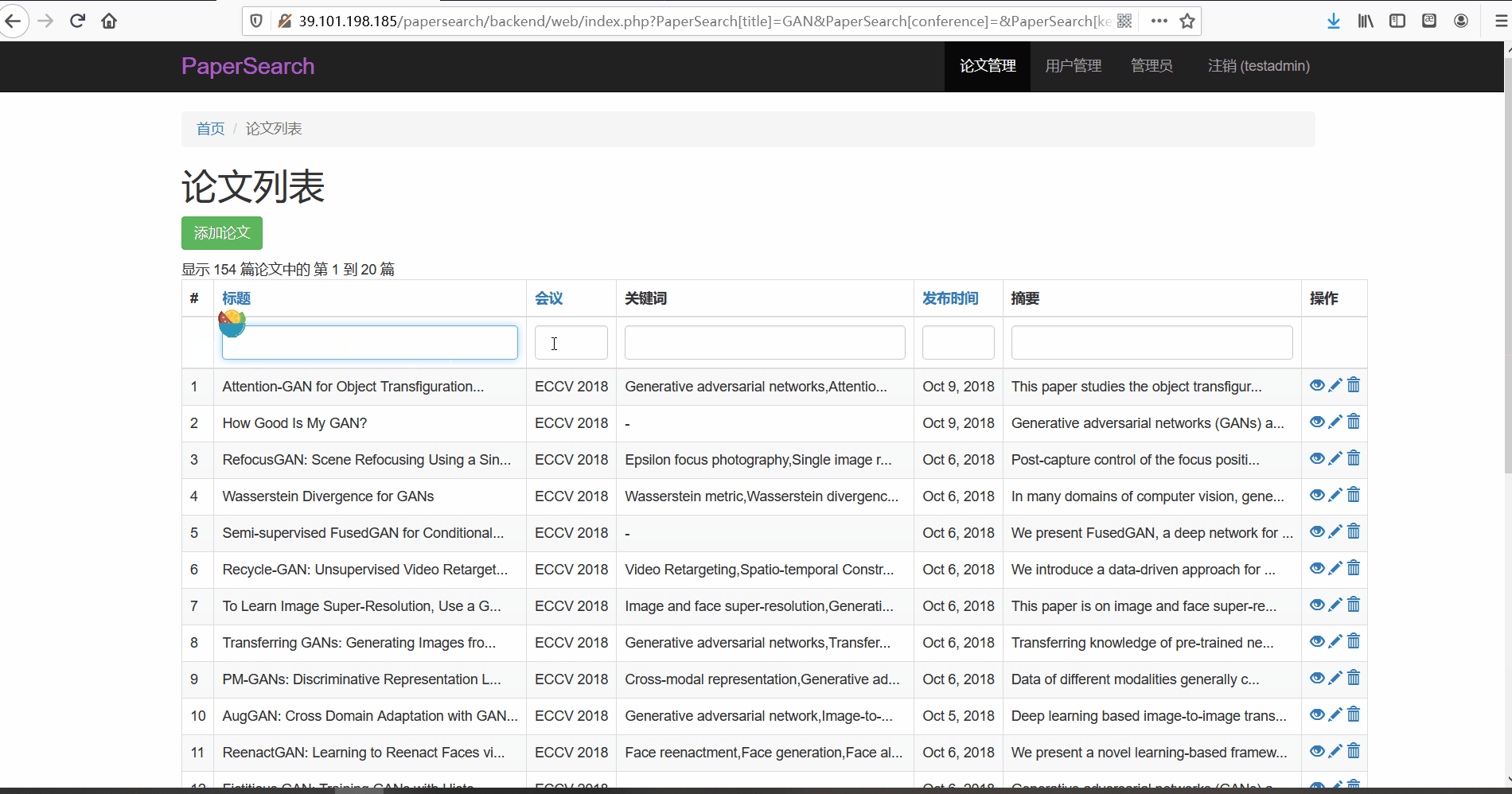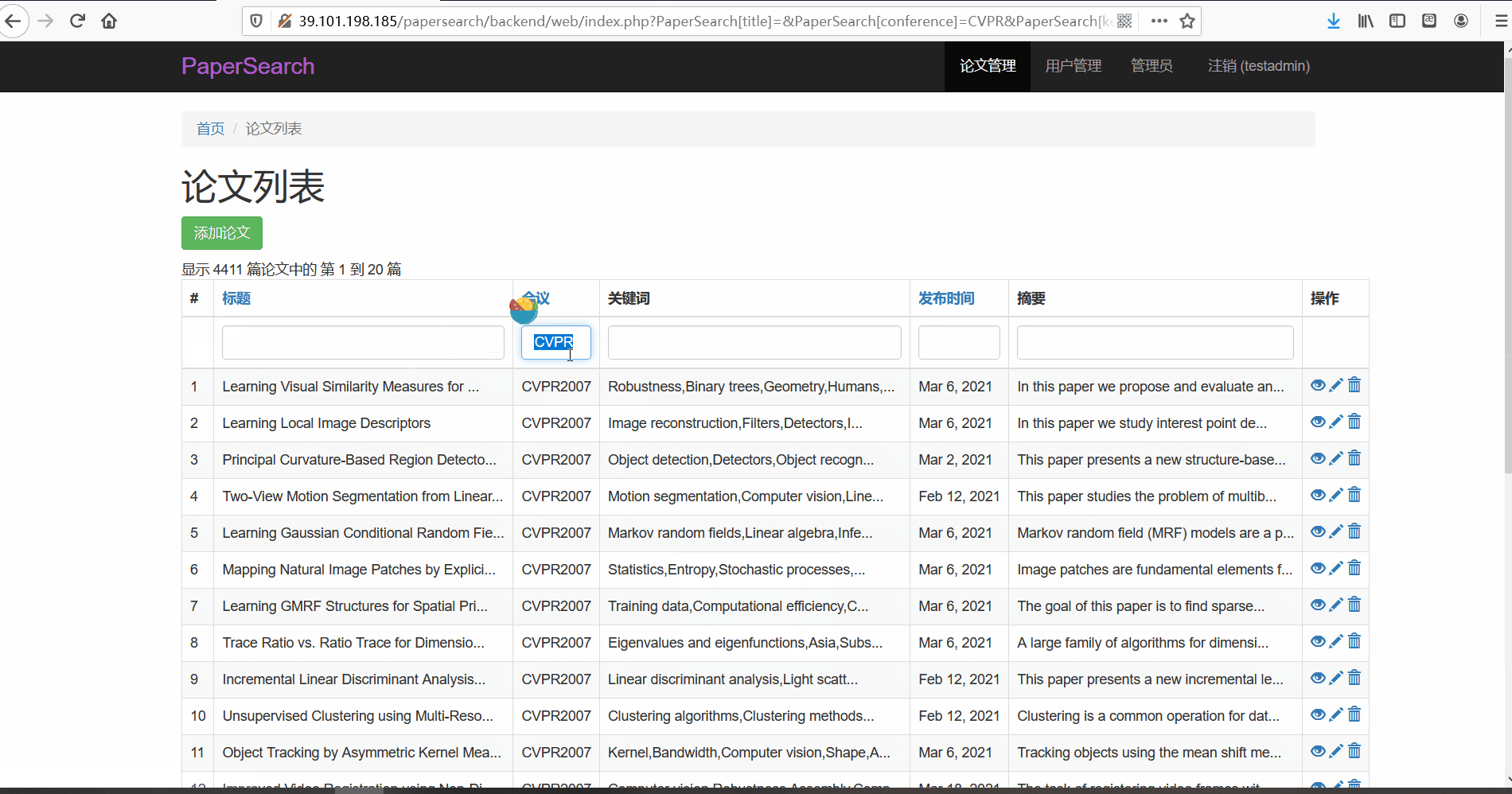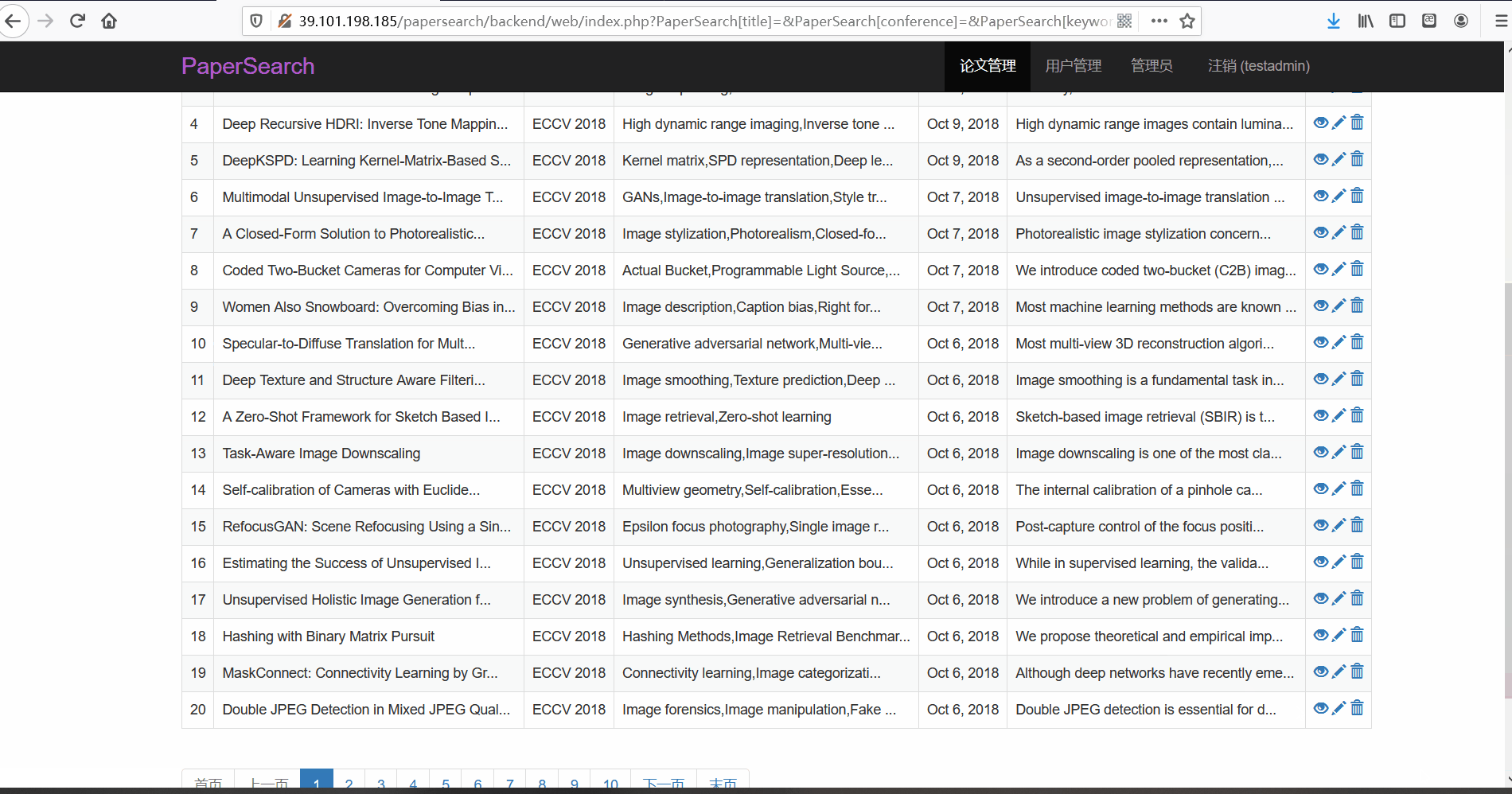
- 功能描述:在论文管理页面,管理员可以对论文进行查看、修改与删除。管理员可以按标题、会议以及关键词、发布时间以及摘要内容进行搜索
- 论文搜索
- 查看与修改论文
- 删除文章
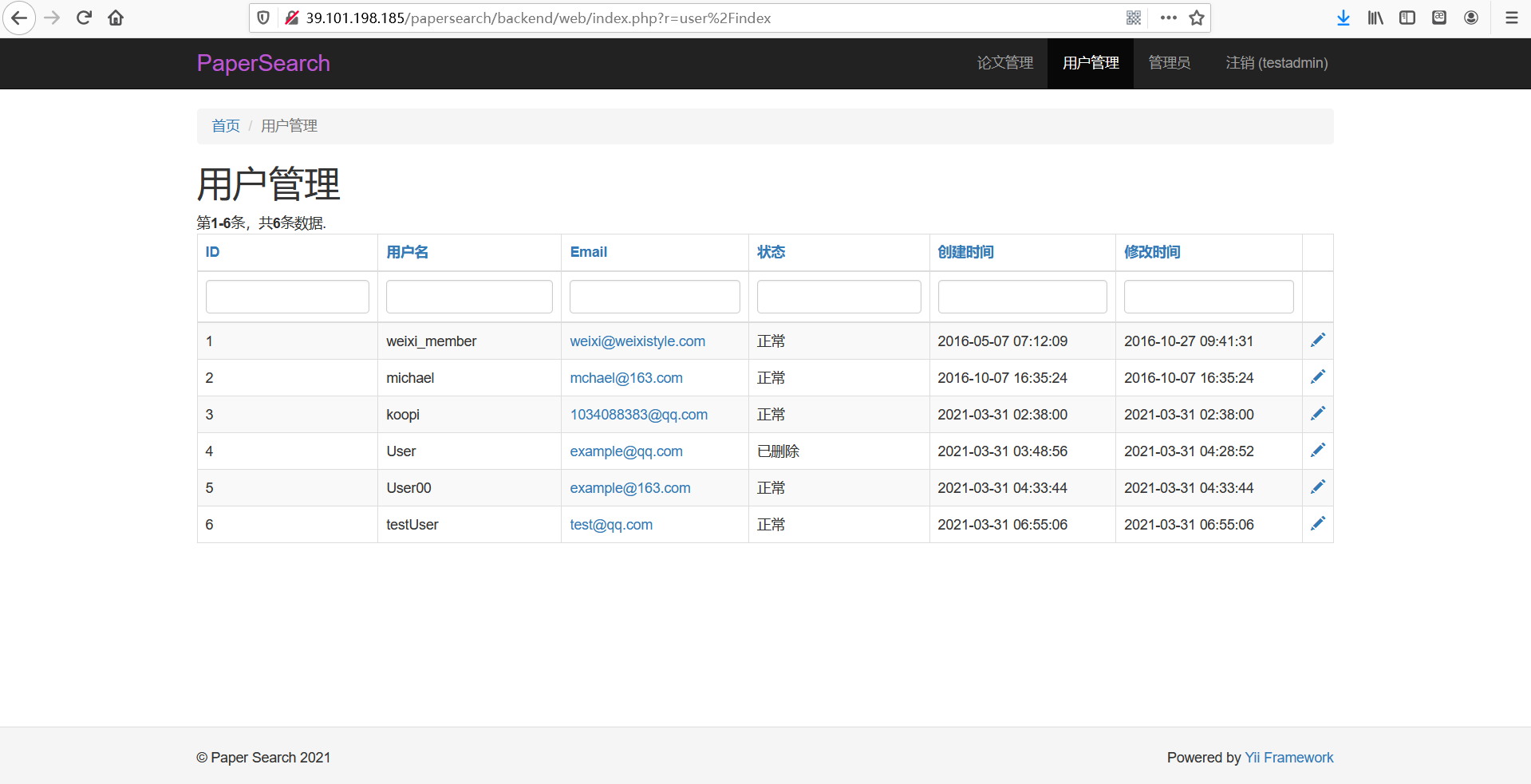
用户管理
- 功能描述:管理员可以对已有用户进行管理,查看他们的ID、用户名、Email以及状态等。
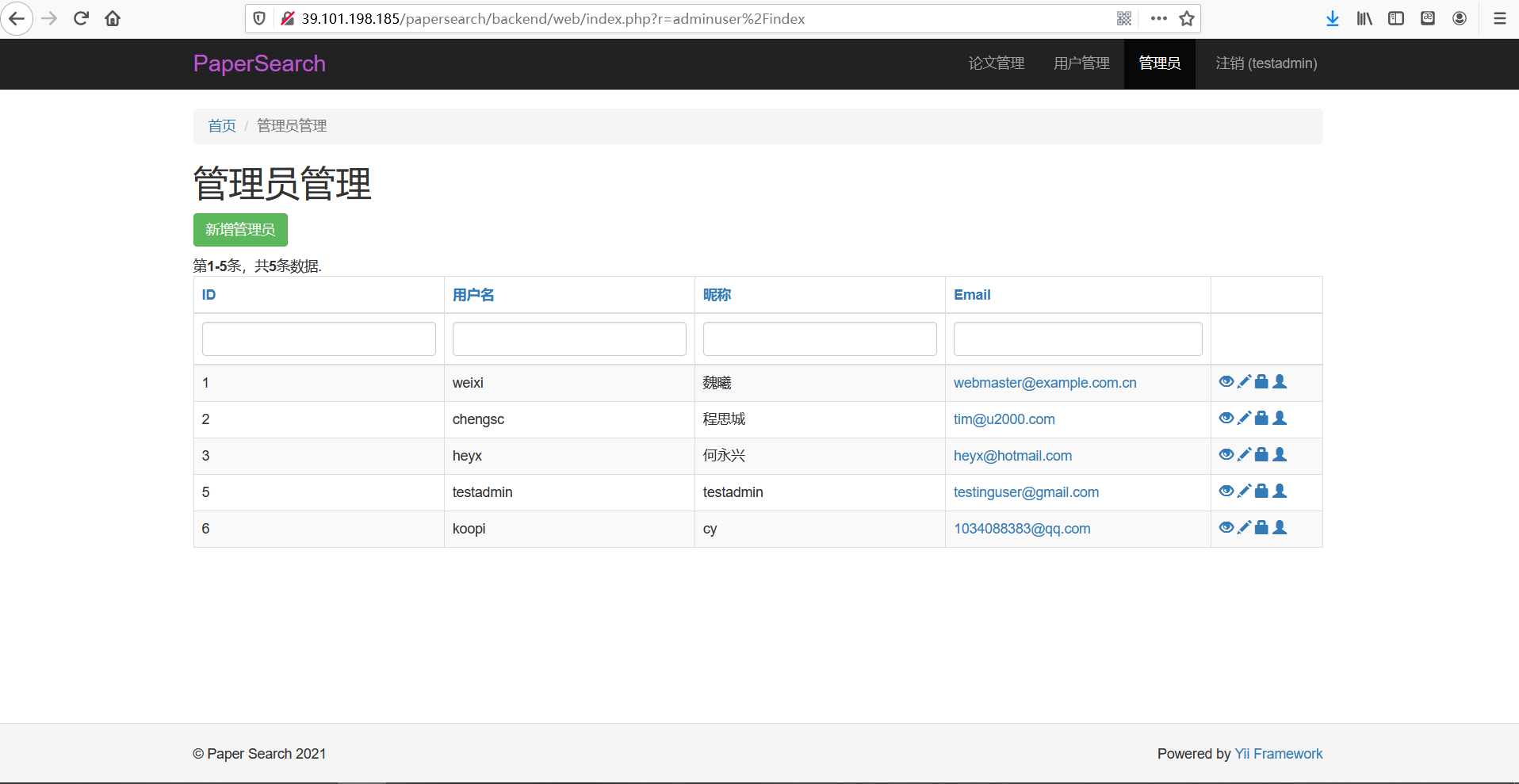
管理员管理
- 功能描述:管理员也可以对管理员列表进行查看与管理。
结对讨论过程描述
- 在作业发布不久后后,我们就进行了一次讨论。鉴于上学期WEB实践我们都有使用Yii2.0框架编写博客的经验,我们确定使用Yii2.0框架进行论文网页的编写。同时我们对需求进行分析并初步进行数据库设计。我们对任务进行了分工,LG(221801427)同学主要负责后台页面、注册登录功能以及用户权限管理的实现,尝试了爬取功能,搭建云服务器。而AQ(221801413)同学主要实现前台页面、论文列表、分析图表以及页面缓存、url美化功能。为了方便项目的实现与管理,我们还结合各自的代码规范,制定了一份共同使用的代码规范。
- 我们使用Github对项目进行版本管理。由于大家每周课程不一致,平时多用qq进行线上讨论,主要内容就是前后台功能模块的实现以及对接,同时我们会对各自提交的代码进行复审以便及时找出问题并讨论解决。开发方面,我们使用wampserver工具包进行环境配置,它集成了apache、php与mysql,使用起来比较方便。但在使用时需要注意wamp端口占用问题,本地的MySql与phpMyadmin会冲突(解决方法:关闭MySql服务),导致wampserver无法使用。

- 在结对过程中,如果出现问题会在qq上进行讨论并解决。
设计实现过程
红线删去的为不必要的原先参考模板
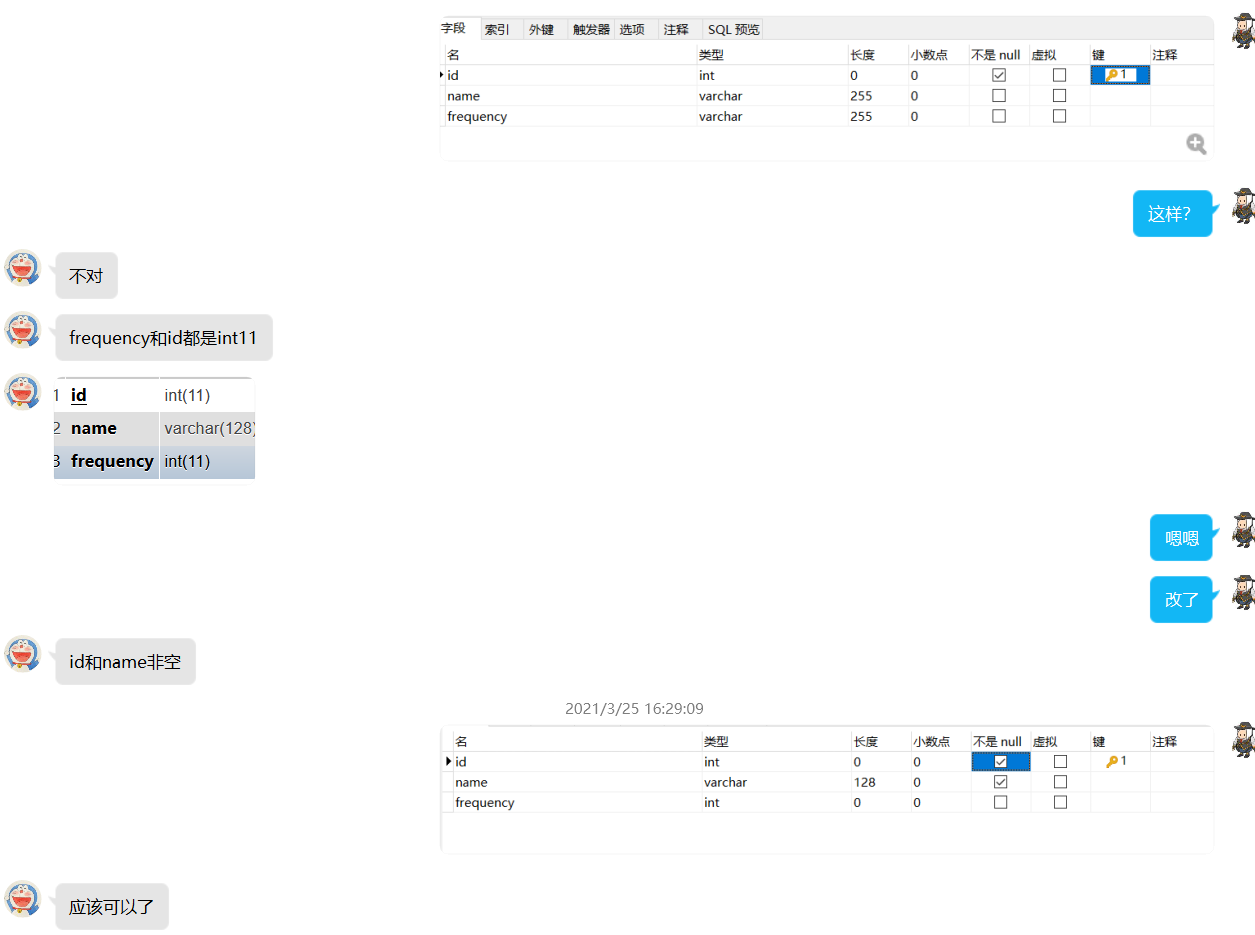
-
在完成数据库的创建后,我们通过Gii(Yii自带的一个开发模块)来生成与数据库表对应的module类、controller类以及views类,以及相应的表的增删改查处理。这节省了我们一部分的代码编写量,为后续的功能实现打下了基础。
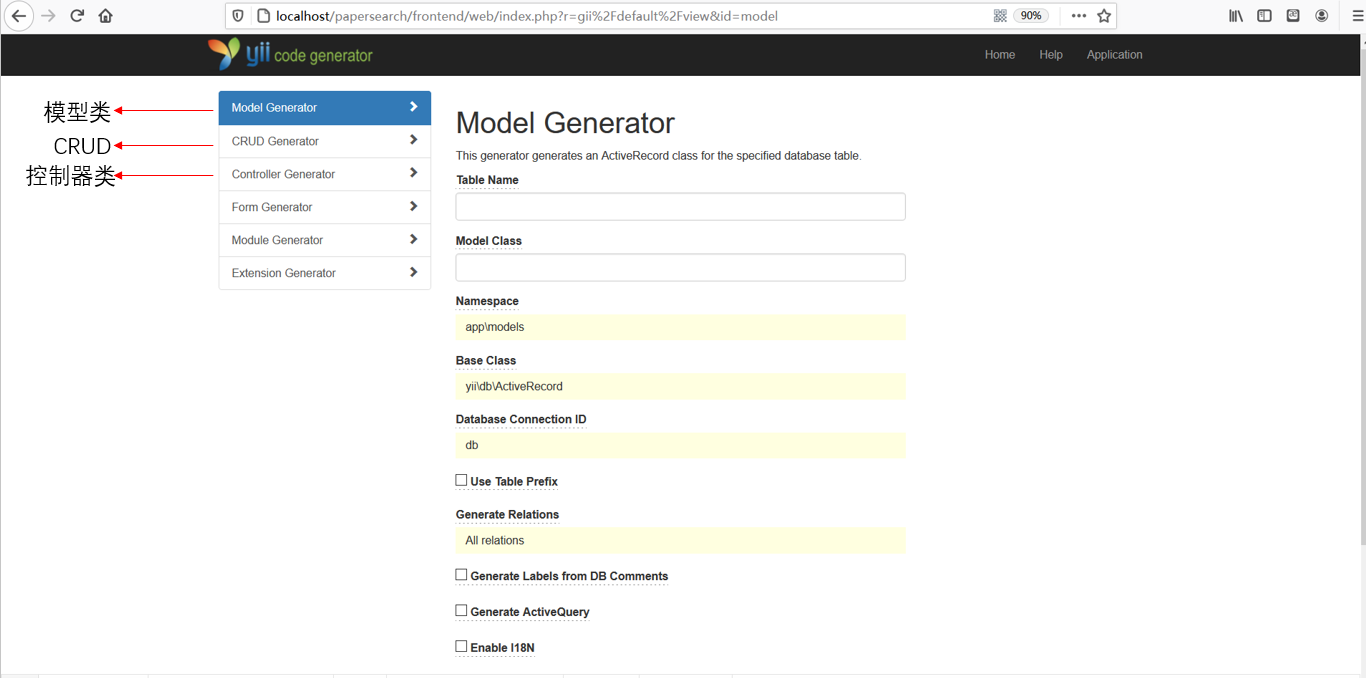
-
我们将页面分为前台与后台,网页结构如下图。
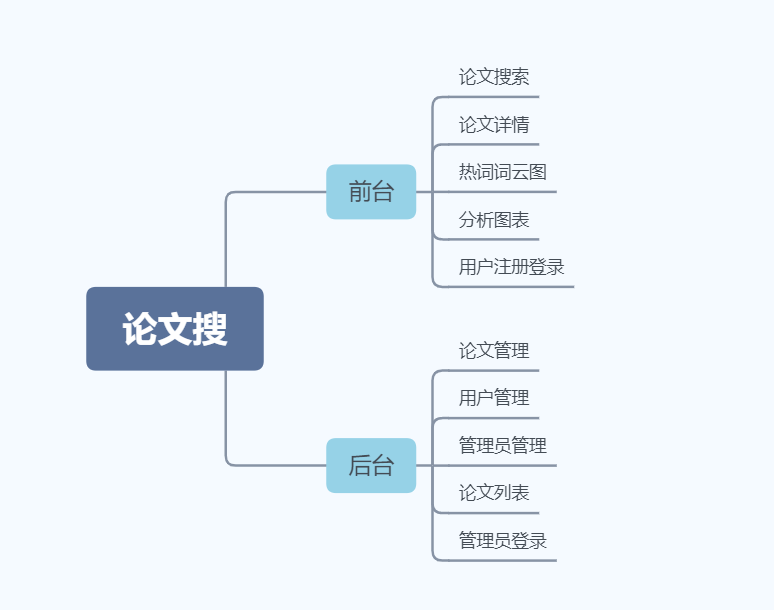
-
前台为普通用户使用,其主要功能就是让用户对论文进行浏览与查看。用户在注册账号并登录后可以浏览论文的列表并查看论文详情,还可以按标题、关键词、所属会议对论文进行搜索。同时,用户也可以点击论文的关键词标签和热词标签对论文进行搜索。此外,前台还有图表分析页面,对ECCV与CVPR的三年论文篇数进行对比以及十大热词频率占比饼图。
-
而在后台,管理员进行登录后可以对论文、用户进行管理。在论文管理页面,可以对文章进行查看、修改与删除。同时为了方便管理,我们也在这个页面添加了搜索功能。此外,后台页面还有用户管理功能,管理员可以查看用户的一些信息(诸如ID、用户名、email等),并且管理员可以删除一个用户。
-
最后,我们尝试使用爬虫来对论文进行爬取。爬取结果如下:
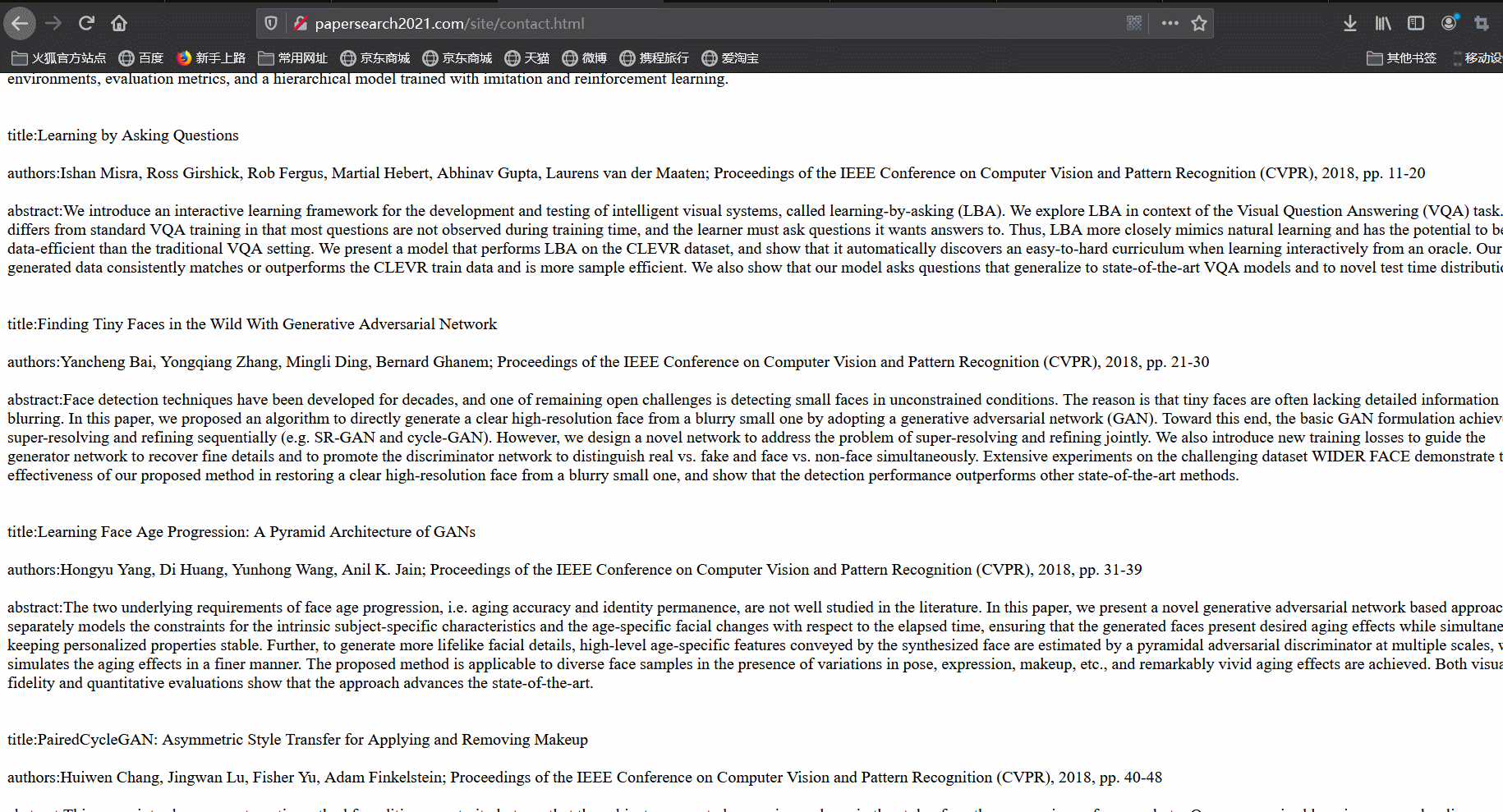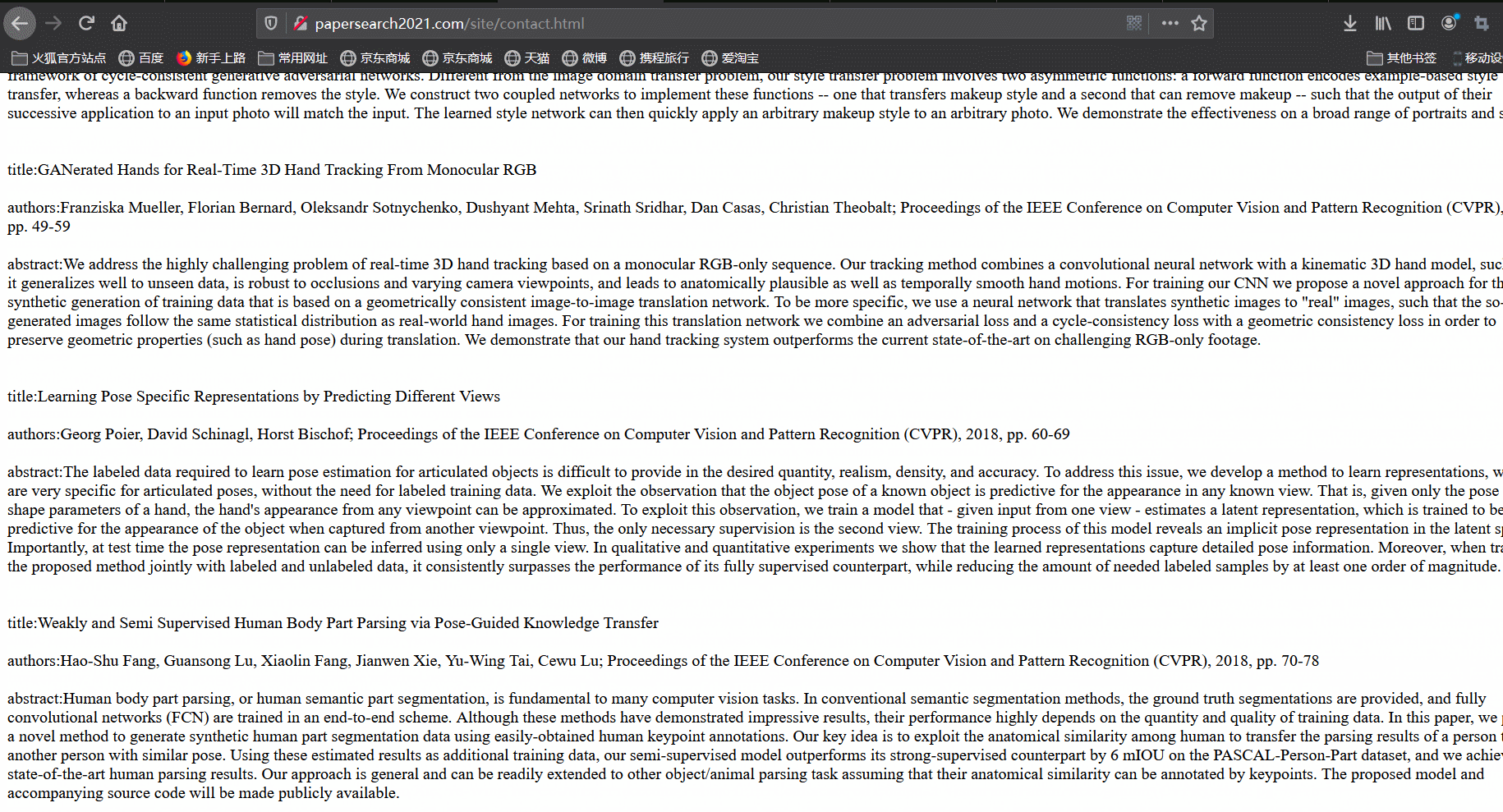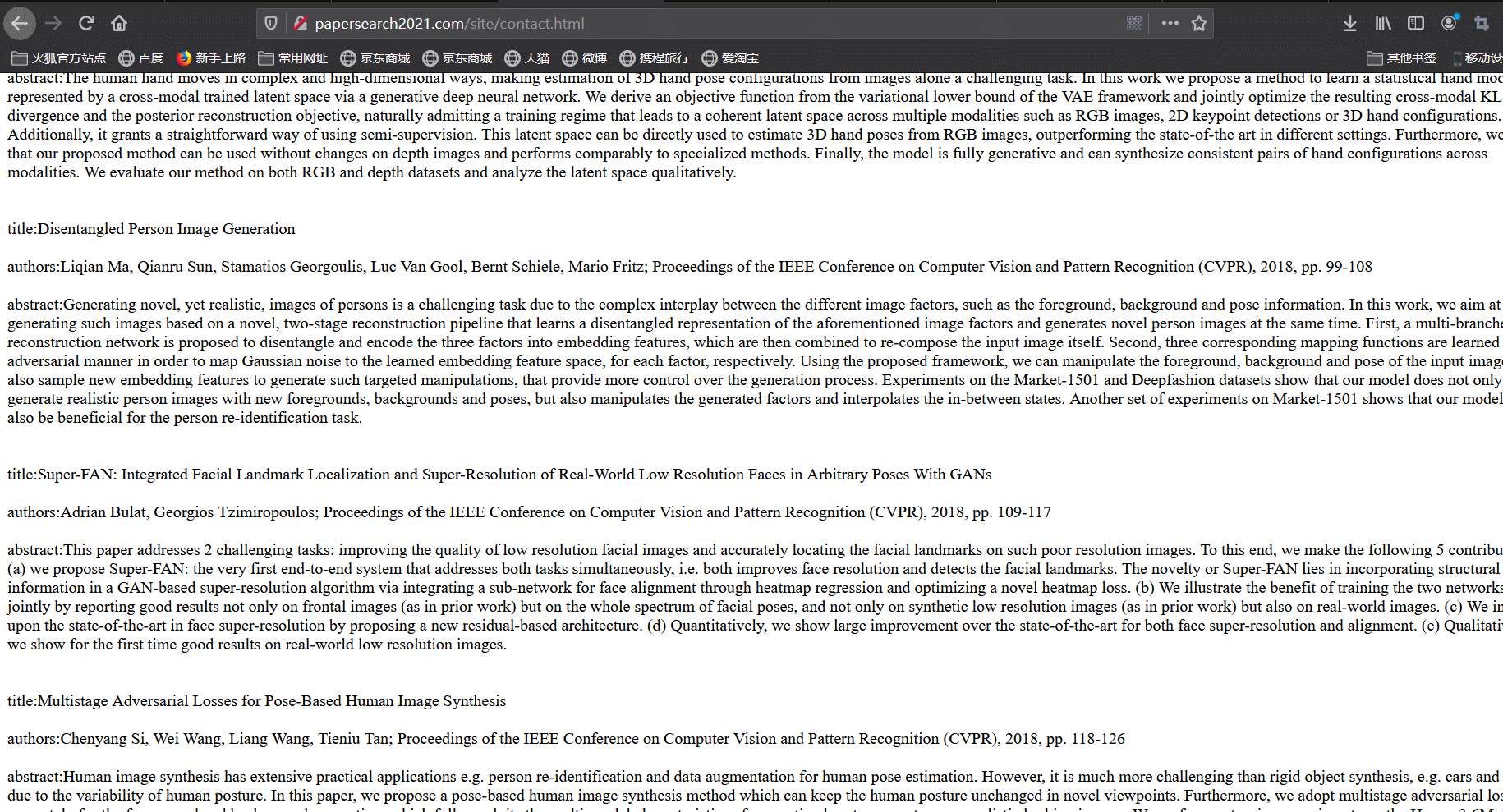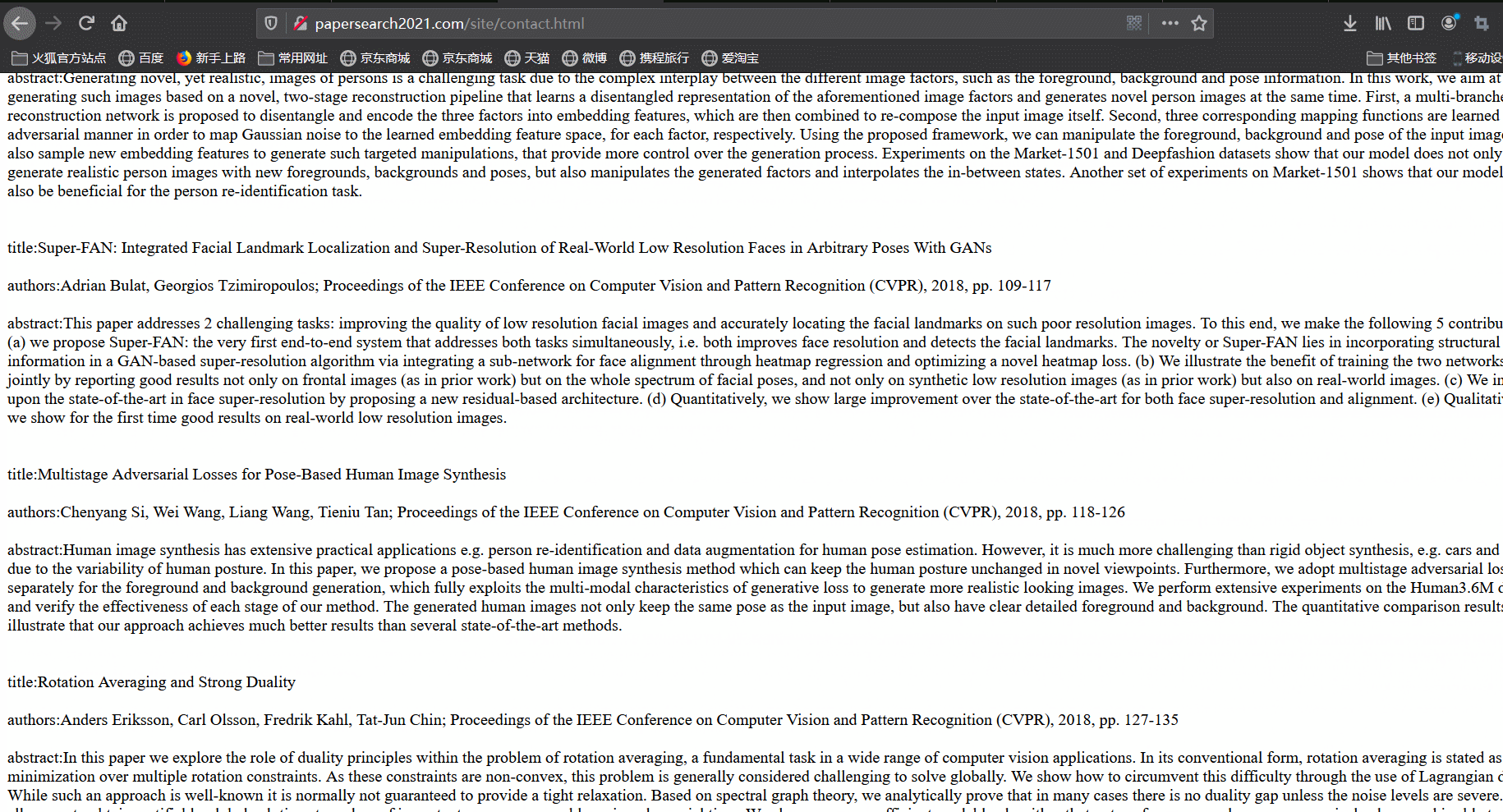
-
在数据库设计方面,我们分别使用adminuser表与user表来存储管理员与用户信息,两者的不同之处在于,管理员可以登录后台对论文进行增删改查、对用户进行管理等功能,而用户可以在前台查看论文列表、搜索论文以及查看分析图表;我们使用paper表来存储论文的信息,kewords表存储关键词与其词频。
代码说明
字符串数组转换
1、PHP preg_split() 函数:array preg_split ( string $pattern , string $subject [, int $limit = -1 [, int $flags = 0 ]] )
$pattern: 用于搜索的模式,字符串形式。
$subject: 输入字符串。
$limit: 可选,如果指定,将限制分隔得到的子串最多只有limit个,返回的最后一个 子串将包含所有剩余部分。limit值为-1, 0或null时都代表"不限制"。
$flags: PREG_SPLIT_NO_EMPTY: 如果这个标记被设置, preg_split() 将返回分隔后的非空部分。
2、PHP implode() 函数:implode(separator,array) ,函数返回一个由数组元素组合成的字符串。
| separator | 可选。规定数组元素之间放置的内容。默认是 ""(空字符串)。 |
|---|---|
| array | 必需。要组合为字符串的数组。 |
public static function string2array($keywords)
{
return preg_split('/\s*,\s*/',trim($keywords),-1,PREG_SPLIT_NO_EMPTY);
}
public static function array2string($keywords)
{
return implode(', ',$keywords);// 此处选逗号分割,因数据库中的关键词是以逗号分隔。
}
关键词根据文章增删而变动
public static function addKeywords($keywords)
{
if(empty($keywords)) return ;
foreach ($keywords as $name)
{
$aKeyword = Keyword::find()->where(['name'=>$name])->one(); //查找返回一条数据
$aKeywordCount = Keyword::find()->where(['name'=>$name])->count(); //获取关键词数
if(!$aKeywordCount)
{
//若关键词不存在,则新加入,创建对象并赋值频率为1
$keyword = new Keyword;
$keyword->name = $name;
$keyword->frequency = 1;
$keyword->save();
}
else
{
$aKeyword->frequency += 1; //若关键词已存在,频率+1并保存
$aKeyword->save();
}
}
}
public static function removeKeywords($keywords)
{
if(empty($keywords)) return ;
foreach($keywords as $name)
{
$aKeyword = Keyword::find()->where(['name'=>$name])->one();
$aKeywordCount = Keyword::find()->where(['name'=>$name])->count();
if($aKeywordCount)
{
if($aKeywordCount && $aKeyword->frequency<=1)
{
//若关键词频度为1或已经小于1,则减少后频度将小于1,需删除
$aKeyword->delete();
}
else
{
$aKeyword->frequency -= 1;
$aKeyword->save();
}
}
}
}
热词频率更新与计算权重
public static function updateFrequency($oldKeywords,$newKeywords)
{
if(!empty($oldKeywords) || !empty($newKeywords))
{
//修改关键词时,将新旧字符串传入,转化为数组
$oldKeywordsArray = self::string2array($oldKeywords);
$newKeywordsArray = self::string2array($newKeywords);
//array_diff计算数组的差集,得到新增与移除的关键词,对应的在上面设计的函数中进行数据库中数据的删除
self::addKeywords(array_values(array_diff($newKeywordsArray,$oldKeywordsArray)));
self::removeKeywords(array_values(array_diff($oldKeywordsArray,$newKeywordsArray)));
}
}
public static function findKeywordWeights($limit=10) //在这里可以设置获取Top($limit)个词频权重
{
$keyword_size_level = 5; //词云图单词大小规模等级设置为五个档次
$models=Keyword::find()->orderBy('frequency desc')->limit($limit)->all(); //将关键词数据表根据频度降序统计,限定为前($limit)个
$total=Keyword::find()->limit($limit)->count();
$stepper=ceil($total/$keyword_size_level); //总数除以规模等级数,获得每个档次的单词数
$keywords=array();
$counter=1;
if($total>0)
{
foreach ($models as $model)
{
$weight=ceil($counter/$stepper)+1; //根据计数与每个档次单词数计算获得单词权重
$keywords[$model->name]=$weight;
$counter++;
}
ksort($keywords);
}
return $keywords;
}
。。。
public function run()
{
$tagString='';
//指定五种档次关键词云按钮(指向链接)的样式
$fontStyle=array("6"=>"danger",
"5"=>"info",
"4"=>"warning",
"3"=>"primary",
"2"=>"success",
);
//以关键词名=>权重的形式循环关键词数组
foreach ($this->keywords as $tag=>$weight)
{
//用框架的PaperSearch方法搜索存在指定关键词的所有论文,并用urlManager工具获得所渲染页面(搜索结果)的链接
$url = Yii::$app->urlManager->createUrl(['paper/index','PaperSearch[keywords]'=>$tag]);
//利用字符串拼接,制作链接指向搜索结果,样式和权重相关联的关键词云按钮
$tagString.='<a href="'.$url.'">'.
' <h'.$weight.' style="display:inline-block;"><span class="label label-'
.$fontStyle[$weight].'">'.$tag.'</span></h'.$weight.'></a>';
}
sleep(3);
return $tagString;
}
搜索框与搜索结果展示小模块,实现思路就是先编写一个listitem小模块,然后放在listview里以列表形式渲染,搜索框制作为按三种方式模糊搜索
//前台首页搜索框
<li class="list-group-item">
<form class="form-inline" action="<?= Yii::$app->urlManager->createUrl(['paper/index']);?>" id="w0" method="get">
<div class="form-group" style="margin-left:15px">
<input type="text" class="form-control" name="PaperSearch[title]" id="w0input" placeholder="按标题">
<input type="text" class="form-control" name="PaperSearch[conference]" id="w0input" placeholder="按会议">
<input type="text" class="form-control" name="PaperSearch[keywords]" id="w0input" placeholder="按关键词">
</div>
<button type="submit" class="btn btn-default" style="width:150px;margin-left:5px">搜索</button>
</form>
</li>
//ListView小部件渲染
<?= ListView::widget([
'id'=>'paperList',
'dataProvider'=>$dataProvider,
'itemView'=>'_listitem', //子视图,显示一篇论文的标题等内容.
'layout'=>'{items} {pager}',
'pager'=>[
'maxButtonCount'=>10, //翻页栏一次显示的最大页数
'nextPageLabel'=>Yii::t('app','下一页'),
'prevPageLabel'=>Yii::t('app','上一页'),
],
])?>
//Listitem小部件,显示论文的标题、发布时间、所属会议、摘要、与附带链接的关键词,并配上相应的小图标美化页面。
<?php
use yii\helpers\Html;
?>
<div class="post">
<div class="title" style="margin-top: 36px">
<h2><a href="<?= $model->url;?>"><?= Html::encode($model->title);?></a></h2>
<div class="origin">
<span class="glyphicon glyphicon-time" aria-hidden="true"></span><em><?= $model->release_time." ";?></em>
<span class="glyphicon glyphicon-map-marker" aria-hidden="true"></span><em><?= $model->conference;?></em>
</div>
</div>
<br>
<div class="content">
<?= $model->beginning;?>
</div>
<br>
<div class="nav">
<span class="glyphicon glyphicon-tag" aria-hidden="true"></span>
<?= implode(', ',$model->tagLinks);?>
</div>
</div>
数据库增删改查(使用Gii自动生成,以paper表即论文表为例)
public function actionCreate()
{
$model = new Paper();
//获取用户输入数据,验证并保存
if ($model->load(Yii::$app->request->post()) && $model->save()) {
return $this->redirect(['view', 'id' => $model->id]);
} else {
//通过render渲染网页,显示创建的论文
return $this->render('create', [
'model' => $model,
]);
}
}
public function actionUpdate($id)
{ //找出ID对应的数据
$model = $this->findModel($id);
//获取用户的修改数据,验证并保存
if ($model->load(Yii::$app->request->post()) && $model->save()) {
return $this->redirect(['view', 'id' => $model->id]);
} else {
//通过render渲染网页,显示被修改的论文
return $this->render('update', [
'model' => $model,
]);
}
}
public function actionDelete($id)
{ //找出ID对应的论文并删除
$this->findModel($id)->delete();
//返回至论文列表页
return $this->redirect(['index']);
}
protected function findModel($id)
{
//根据ID查询论文
if (($model = Paper::findOne($id)) !== null) {
return $model;
} else {
throw new NotFoundHttpException('The requested page does not exist.');
}
}
分析图表代码(以柱状图为例),直接引用用highchart网站的模板,修改其文本以及数据,数据由数据库查询传入
<script type='text/javascript' src="http://cdn.highcharts.com.cn/highcharts/9.0.1/highcharts.js"></script>
<script type="text/javascript"> //获取php从数据库提取的数据并转换为js需要的变量
var ECCV2016 = parseInt("<?php echo $Eccv2016; ?>");
var CVPR2016 = parseInt("<?php echo $Cvpr2016; ?>");
var ECCV2020 = parseInt("<?php echo $Eccv2020; ?>");
var CVPR2020 = parseInt("<?php echo $Cvpr2020; ?>");
var ECCV2018 = parseInt("<?php echo $Eccv2018; ?>");
var CVPR2018 = parseInt("<?php echo $Cvpr2018; ?>");
//修改部分文本与数据
var chart = Highcharts.chart('chart01',{
chart: {
type: 'column'
},
title: {
text: '2016、2018、2020ECCV与CVPR两大顶会历年论文篇数'
},
xAxis: {
categories: [
'2014','2016','2018'
],
crosshair: true
},
yAxis: {
min: 0,
title: {
text: '论文篇数'
}
},
tooltip: {
// head + 每个 point + footer 拼接成完整的 table
headerFormat: '<span style="font-size:10px">{point.key}</span><table>',
pointFormat: '<tr><td style="color:{series.color};padding:0">{series.name}: </td>' +
'<td style="padding:0"><b>{point.y} 篇数</b></td></tr>',
footerFormat: '</table>',
shared: true,
useHTML: true
},
plotOptions: {
column: {
borderWidth: 0
}
},
//将不同年份对应的会议的论文篇数传入
series: [{
name: 'ECCV',
data: [ECCV2016, ECCV2018,ECCV2020]
},
{
name: 'CVPR',
data: [CVPR2016,CVPR2018,CVPR2020]
}]
});
</script>
经过学习,尝试做了简单的爬取功能,描述见注释,最终没有部署到服务器上。原因:1、时间来不及做完完整功能和优化,页面加载很慢,不适合部署到远程端。2、QueryList更高级的功能、语法糖等需要更高版本的php,与自己已经开发的项目使用的部署环境不匹配,编写十分吃力。
<?php
//以下实现简单的爬取事件
//引入QueryList3
require 'phpQuery.php';
require 'QueryList.php';
use \QL\QueryList;
error_reporting(1);
//设置执行限时为无限,防止超时错误
ini_set('max_execution_time', '0');
//爬取网站为CVPR2018开源官网
$html = "https://openaccess.thecvf.com/CVPR2018?day=2018-06-19" ;
//用于拼接的baseurl
$baseUrl = "https://openaccess.thecvf.com/" ;
//递归采集
$data = QueryList::Query($html,array(
//选取所有ptitle类,爬取内容为<a href中的链接后缀文本
"ptitle"=>array('.ptitle>a', 'href','',function($content) use($baseUrl){
//返回拼接后的字符串,即为可访问的每个论文详情页
return $baseUrl.$content;
}),
))->getData(function($item){
//对每个ptitle链接进行循环爬取
$item['ptitle'] = QueryList::Query($item['ptitle'],array(
//爬取id为papertitle、authors、abstract中的文本
"title" => array('#papertitle','text'),
'authors' =>array('#authors','text'),
'abstract' =>array('#abstract','text'),
))->data;
return $item;
});
//数据格式化打印
foreach ($data as $arr) {
echo "title:";print_r($arr['ptitle'][0]['title']); echo "<br/>";echo "<br/>";
echo "authors:";print_r($arr['ptitle'][0]['authors']); echo "<br/>";echo "<br/>";
echo "abstract:";print_r($arr['ptitle'][0]['abstract']); echo "<br/>";echo "<br/>";echo "<br/>";
}
exit;
?>
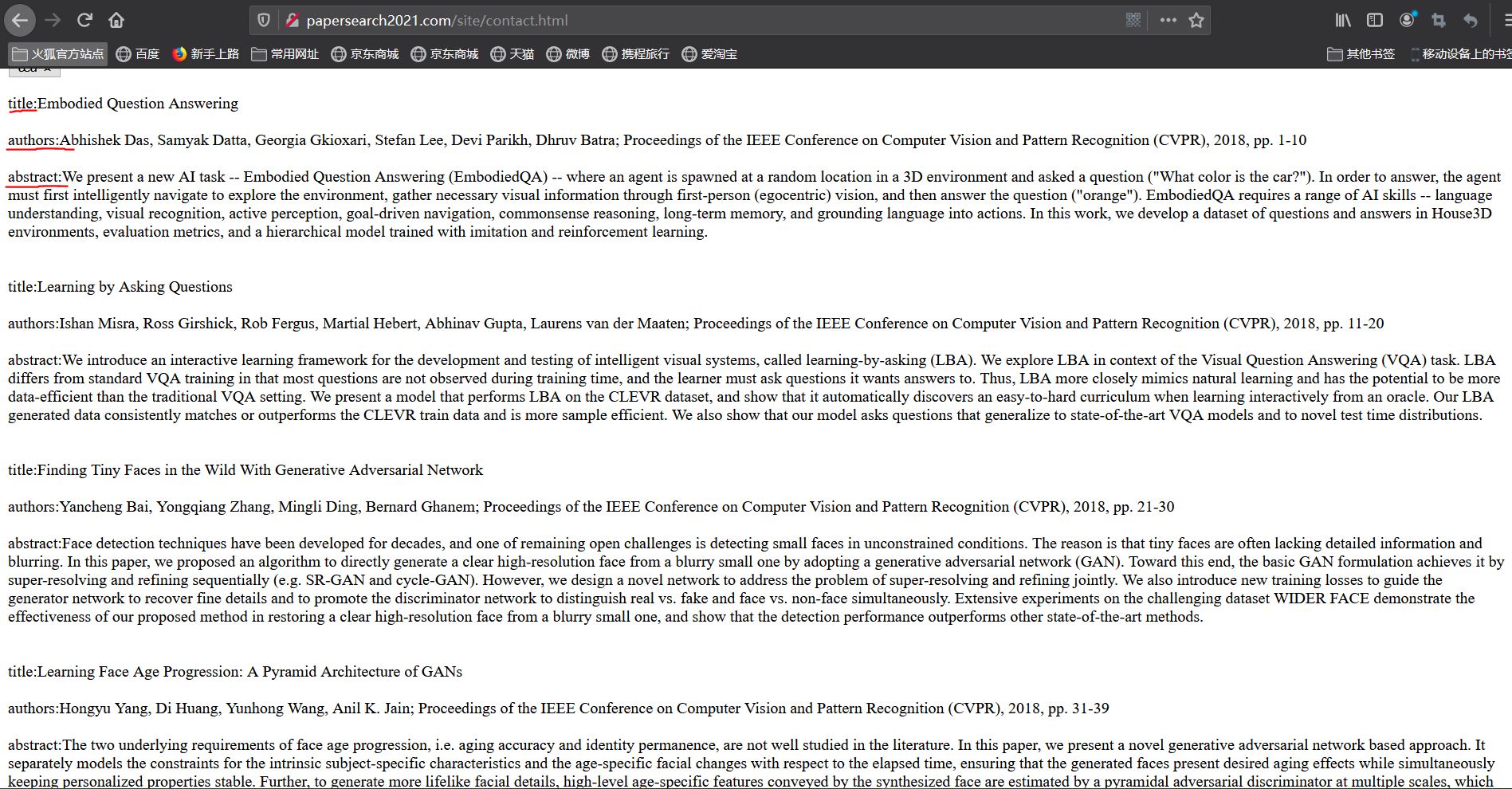
爬取网页源代码示例图


爬取结果
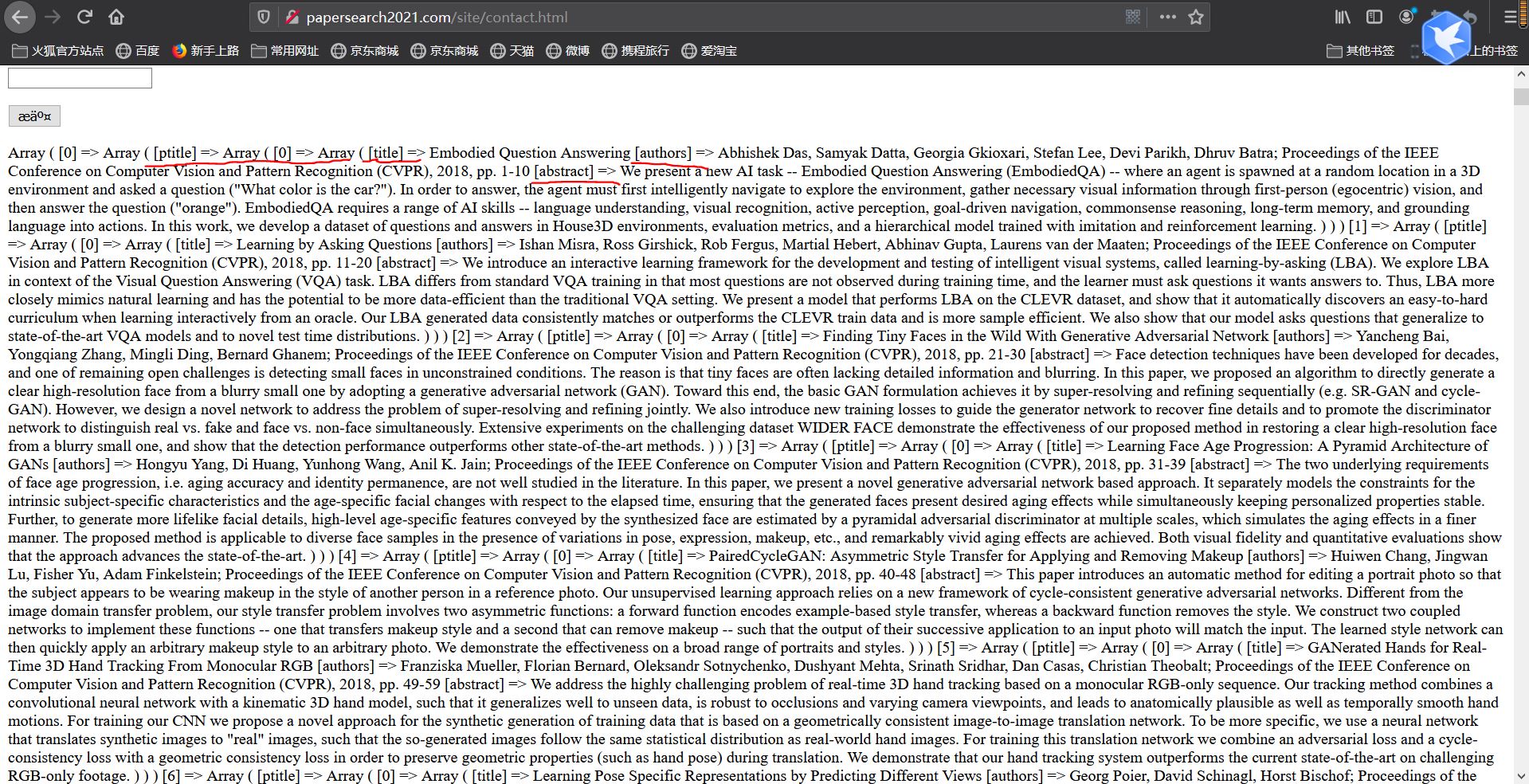
后台论文列表渲染,采用yii2的GridView,长文本省略显示
<?= GridView::widget([
'dataProvider' => $dataProvider,
'filterModel' => $searchModel,
'layout'=>"{summary}{items}{pager}<div class='text-right tooltip-demo'></div>",
'summary' => " 显示 {totalCount} 篇论文中的 第 {begin} 到 {end} 篇 ",
'formatter' => ['class' => 'yii\i18n\Formatter','nullDisplay' => ' - '],
'pager' => [
'prevPageLabel' => '上一页',
'nextPageLabel' => '下一页',
'firstPageLabel' => '首页',
'lastPageLabel' => '末页',
'maxButtonCount' => 10,
],
'columns' => [
['class' => 'yii\grid\SerialColumn'],
//'id',
//'title:ntext',
[
'attribute' => 'title',
'headerOptions' => ['width' => '20%'],
'value' => function ($model) {
return $model->summary;
},
'format' => 'ntext',
],
'conference',
//'keywords:ntext',
[
'attribute' => 'keywords',
'headerOptions' => ['width' => '20%'],
'value' => function ($model) {
if($model->short)
return $model->short;
},
'format' => 'ntext',
],
'release_time:date',
//'link',
[
'attribute' => 'abstract',
'headerOptions' => ['width' => '20%'],
'value' => function ($model) {
return $model->beginning2;
},
'format' => 'ntext',
],
['class' => 'yii\grid\ActionColumn',
'contentOptions' => ['style' => 'width:10%;'],
'header'=>'操作',
],
],
]); ?>
定长截取字符串、获取关键词(标签)对应查询结果链接、获取论文原文链接的函数
public function getBeginning($length=288)
{
$tmpStr = strip_tags($this->abstract);
$tmpLen = mb_strlen($tmpStr);
$tmpStr = mb_substr($tmpStr,0,$length,'utf-8');
return $tmpStr.($tmpLen>$length?'...':''); //字符串超出指定长度就以省略号代替展示
}
public function getTagLinks()
{
$links=array();
foreach(Keyword::string2array($this->keywords) as $tag)
{
//关键词转化,以数组形式循环,获取搜索结果链接存入链接列表以展示到页面上。
$links[]=Html::a(Html::encode($tag),array('paper/index','PaperSearch[keywords]'=>$tag));
}
return $links;
}
public function getOrgLink()
{
return Html::a($this->link, "//{$this->link}", ['target' => '_blank']);
}
附:开发时还开启了url美化的功能,不过部署到服务器上后会遇到问题,故在云端删去该部分。
心路历程和收获
221801427:本次结对作业是一个漫长的过程,心路历程就是:迷茫->明确选
择何种技术框架进行开发,得知ddl延后有了动力->肝肝肝累累累->抱怨一些难以
解决的坑->部署成功时会开心点->改各种哭笑不得的bug->最后松了一口气。
前端的开发和之前的个人作业有着本质上的区别。主要特点就是坑变得很多
很多,错了一小小点就会全白给,调试纠错的过程很“有趣”;技术/框架在刚上手
时候常会感到迷茫,即使是之前学过的;设计需要想象力,同一个东西一改再改
咋都不顺眼最后可能删除了,但有时候随便写一下反而刚好成效很好。
感受就是遇到困难多查开发手册、开发者社区,搜索引擎的使用能力提升了;遇到无
法逾越的困难多求助别人,互帮互助,自己死磕效率不高;更熟悉了php开发以及
html+css等,功能的实现上,根据作业要求着重于界面设计、数据调用和云服务
器部署上,但最后发现用php做爬虫其实也没想象中那么难,难点涉及到
Jquery、数据处理等。可惜时间来不及做相关界面和数据存取了,后续只得留着
自己探索,如果一开始就着重于学习这个最后可能就做出完整的东西来了(附加
功能)。
收获最大的个人觉得还是学会了将项目部署到云服务器上,虽然其
用时在整个作业过程中不占大头,但也遇到了不少坑并一一克服了,最终能实现
远程访问较有成就感。
221801413:有了第一次结对编程的经验,我感觉和队友的配合会更好。在完
成这次的作业的过程中,遇到了非常多的问题,比如页面缓存导致的登录状态问
题、服务器部署时apache的重写规则问题等等。当发发生这种情况时,我会和同
学讨论以及寻找网络资料来解决,在这个过程中,自己也确实学到了实实在在的
知识。并且第一次实现并部署一个网站,虽然遇到了各种艰难险阻吧,但个人而
言还是非常高兴能完成这个任务的。通过这个任务,我不仅加深了对Yii2.0的理
解,并且还初步了解了服务器的部署流程。我觉得十分值得。
评价结对队友
221801427:队友很有耐心,积极,技术也很可以!这种作业拿来结对编程效
果还是很好的,虽然git上可能会遇到一些小小问题,但开发上的问题就好解决
了。有些东西就是自己打死都做不出来,队友用同样的时间一下就完成了;遇到
了坑、bug,两个人可以从不同的方向尝试解决它,总会成功一种的,效率较高。
一旦解决了坑,那么心态就会比自己一个人死磕要好点。总之这次结对经历不难
受。
221801413:非常感谢两次结对中队友的合作和帮助。在这次的结对编程过程
中,我感触最深的就是队友那种对待项目认真负责的态度。在完成后台页面功能
编写后,又对页面的布局以及组件进行了细节优化与美化处理,让使用体验有了
极大提升。同时,队友通过计划表来推进每天的进度,让项目管理效率得到提
升。并且,我遇到一时半会儿无法问题时,也会积极与我讨论并查找资料解决问
题。总结:队友管理能力好,态度认真负责并且十分积极,非常高兴能和他两有
次的合作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号