寒假作业2/2
| 这个作业属于哪个课程 | 软件工程2021春软件工程W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 1.阅读《构建之法》并提问;2.完成词频统计个人作业 |
| 其他参考文献 | CSDN,菜鸟网站 |
任务一:阅读《构建之法》并提问
关于运用客户调查
在第八章需求分析中,作者提出了焦点小组、深入面谈、卡片分类、用户调查问卷、用户日志研究、人类学调查、眼动跟踪测试、快速原调查、A/B测试等调查方法,那么对于日常的开发来说,通过这些方法得到的海量用户数据,如何筛选出对开发有用的部分,以及最常用的方法是什么呢
关于软件工程思想
在第三章中,作者提出了对初级软件工程人员成长方面的一些评价,其中提到了对软件设计思想和软件工程思想的理解,那么请问对于这两种思想要达到什么程度才算好呢,以及评判是否有思想,是否是会思想的人有什么标准吗?
关于团队开发效率
在第五章介绍到了团队合作开发的模式,以及在第七章中介绍到MSF基本原则,其中有三条:1.推动信息共享与沟通,2:学习所有的经验和3:与客户合作。在实际开发中,如果遇到团队人数多,沟通所花费的时间以及精力必然上升,这会影响到开发效率。那么,该如何解决大团队开发效率问题?
关于项目经理
第九章讲了项目经理,作者介绍了其职责与能力要求。在现实生活中,项目管理难免和程序员之间产生分歧,进而引发冲突。那么,一个好的项目经理该如何养成?项目经理如何处理团队、客户之间的关系。
关于长期任务
在第六章的第二小节提到了长期任务,这种任务比较难且对项目又很重要,当完成的时间超过Sprint的计划时间,该如何到如何较好的解决这类问题。先做简单的还先做难的呢,是不是对这“长期任务”也应该今早安排固定的人来承担这部分任务?
附加题
现今,“Bug”一词,是指电脑系统的硬件、系统软件(如操作系统)或应用软件(如文字处理软件)出错。然而它其实来源于编译器的发明者格蕾斯·哈珀。1945年9月9日,下午三点。哈珀中尉正领着她的小组构造一个称为“马克二型”的计算机。但是,马克二型遇到不明问题死机。最后,哈珀在70号继电器中发现了一只死去的飞蛾。将飞蛾解决后,机器重新运行。后来,人们将计算机错误戏称为虫子(bug),而把找寻错误的工作称为(debug)。
参考链接
任务二:WordCount编程
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 540 | 700 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 120 |
| • Design Spec | • 生成设计文档 | 30 | 40 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 60 | 90 |
| • Coding | • 具体编码 | 180 | 240 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 70 | 80 |
| • Test Repor | • 测试报告 | 30 | 40 |
| • Size Measurement | • 计算工作量 | 10 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 630 | 810 |
解题思路描述
这次作业要求从文件中读取字符串,并按照要求对其进行处理,然后得出相应的数据,最后将得到的结果存入文件中。那么将需要解决如下几个基本问题:
- 文件的读取
- 计算文件中的ascii码数量
- 计算文件的合法的单词数量
- 计算文件的有效行数
- 获取文件中10个出现次数最多的单词
-
对于第一问题,一开始是用的BufferReader的readLine()方法,但是这个方法读取到'\n'时并不会将其插入字符串,所以后面更改为read()方法读取,解决了这个问题。
-
这个问题是比较简单的,直接遍历读入的字符串然后判断其值是否小于127就可以。
-
计算单词数量一开始我是没有头绪的,然后想到了之前JS开发中中处理非法字符的正则表达式,然后网上查找了java处理正则表达式的相关类和方法进行解决的。
-
有效行数也是使用正则表达式匹配字符串,但是这里要注意的是如果某一行只有"\n"的情况,我最早用的表达式会将这种情况视为合法,后面更换了正则表达式后解决。
-
这个问题我感觉是最复杂的,正则表达式匹配单词我会,但如何保存单词以及相应的频率信息,还有字典序排序的问题难到我了。后面是通过群里热心同学的分享链接知道了字典序的原理,也和舍友交流出使用键值对的方式来存储单词以及相应的频率信息。
代码规范
设计与实现过程
对于问题1,一开始的想法,使用了readLine(),然后将得到的字符使用builder对象的append()方法插入局部String变量中保存,发现问题后,使用了read()方法逐个读取,,代码如下:
public static String readFile(String filePath) {
int temp;
BufferedReader br = null;
StringBuilder builder = null;
try {
br = new BufferedReader(new FileReader(filePath));
builder = new StringBuilder();
while((temp = br.read()) != -1){
builder.append((char)temp);
}
}
catch (FileNotFoundException e) {
e.printStackTrace();
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
br.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
return builder.toString();
}
文件的写入,我分成了两个方法,一个方法先整合所有的信息转换为String,然后将String传入文件写入的方法,以此来完成文件的写操作,代码如下:
- 整合信息:
/** * 将处理后的信息进行统合,得到字符串 * * @ param words,lines,characters, * @ return list * */ public static String outMessage(long words, int lines, long characters, List<Map.Entry<String, Integer>> topTenWords) { //拼接信息 String outMessage = "characters: "+characters+"\nwords: "+words+"\nlines: "+lines+"\n"; for(Map.Entry<String,Integer> map : topTenWords) { outMessage += map.getKey()+": "+map.getValue()+"\n"; } return outMessage; } - 文件写入:
/** * 将单词数,有效行数以及词频信息写入文件 * * @ param wordMap * @ return list * */ public static void writeFile(String outMessage, String filePath) { //创建输出流 FileOutputStream fileOutputStream = null; OutputStreamWriter streamWriter = null; BufferedWriter bufferedWriter = null; try { fileOutputStream = new FileOutputStream(filePath); streamWriter = new OutputStreamWriter(fileOutputStream,"UTF-8"); bufferedWriter = new BufferedWriter(streamWriter); //将得到的数据写入对应路径的文件 bufferedWriter.write(outMessage); bufferedWriter.flush(); } catch (FileNotFoundException e) { System.out.println("File not found!!!"); e.printStackTrace(); } catch (UnsupportedEncodingException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { //关闭输出流 fileOutputStream.close(); streamWriter.close(); bufferedWriter.close(); } catch (IOException e) { e.printStackTrace(); } } }
对于问题2,按照了最初的思路解决了问题,遍历字符串,然后判断其是否小于127,代码如下:
/**
* 遍历字符串,判断其是否为Ascii码并统计其数量
*
* @ param chStr
* @ return characters' number
* */
public static long getCharactersNum(String chStr) {
long charCount = 0;
char[] charArray = chStr.toCharArray();
for(int i = 0; i < charArray.length; i++) {
if(charArray[i] <= 127)
charCount++;
}
return charCount;
}
对于问题3,在查看相关的CSDN的一些处理单词的方法后,选择了使用正则表达式,用Matcher类的find()方法去匹配字符串的解决思路,原因在于相对于matches(),find()方法在处理的时候效率会比较高,代码如下:
/**
* 利用正则表达式,判断有效单词数,记录其出现次数,将该单词与其出现次数存入Map集合中
*
* @ param chStr
* @ return valid words‘ number
* */
public static long getWordNum(String chStr){
long wordNum = 0;
//使用正则表达式匹配
Pattern wordPattern = Pattern.compile(WORD_REGEX);
Matcher wordMatcher = wordPattern.matcher(chStr);
while(wordMatcher.find()){
String temp = wordMatcher.group(2).trim();
wordNum++;
//若单词不存在,则加入wordMap
if(!wordMap.containsKey(temp)) {
wordMap.put(temp, 1);
}
//若存在,则将其value值加1
else {
int value = 1 + wordMap.get(temp);
wordMap.put(temp, value);
}
}
return wordNum;
}
对于问题4,一开始使用了"\s+"的正则表达式去匹配,但发现这样会将单独"\n"算一行,后面更换为"(\n|^)\s*\S+"解决问题,代码如下:
/**
* 利用正则表达式,判断有效行数
*
* @ param chStr
* @ return valid lines
* */
public static int getLinesNum(String chStr){
int lines = 0;
//使用正则表达式匹配有效的字符行
Pattern charPattern = Pattern.compile(LINE_REGEX);
Matcher charmatcher = charPattern.matcher(chStr);
while(charmatcher.find()){
lines++;
}
return lines;
}
对于问题5,基本思路是使用正则表达式去匹配单词,然后将其存入静态变量Map中。存入时,判断单词是否已经存在,如果存在,则其value值加一,不存在,则将其加入map并将value值置为1,然后编写了相应的排序算法实现了字典序排序以及单词频率排序,代码如下:
- 创建单词map<String, Integer>集合
//使用正则表达式匹配
Pattern wordPattern = Pattern.compile(WORD_REGEX);
Matcher wordMatcher = wordPattern.matcher(chStr);
while(wordMatcher.find()){
String temp = wordMatcher.group(2).trim();
wordNum++;
//若单词不存在,则加入wordMap
if(!wordMap.containsKey(temp)) {
wordMap.put(temp, 1);
}
//若存在,则将其value值加1
else {
int value = 1 + wordMap.get(temp);
wordMap.put(temp, value);
}
}
- 排序算法:
/**
* 使用比较器对单词频率进行排序
*
* @ param wordMap
* @ return list
* */
public static List sortWordMap() {
//将wordMap转换为List,方便排序
List<Map.Entry<String, Integer>> list =new ArrayList<Map.Entry<String, Integer>>(wordMap.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
//若value相同,则对key值进行字典排序
if(o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
}
//否则按频率排序
else {
return o2.getValue()-o1.getValue();
}
}
});
性能改进
在进行单元测试时,我将上述的几个方法分为了几个模块,进行了单元测试,在进行测试后,发现计算并排序最高频率的10个单词时使用的creatWordMap()与sortwordMap()方法耗费时间是getWordNum()方法的几乎两倍。测试结果如下图(测试了1w+单词数量):
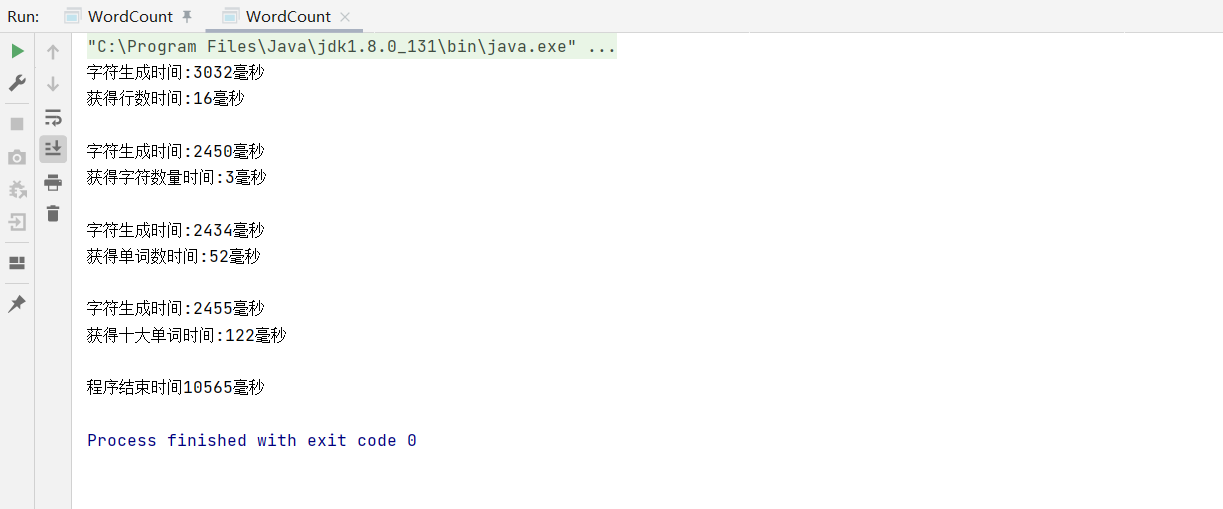
- 由此,我对creatWordMap()与sortwordMap()进行了分析,发现了原因所在:,一开始我是将查找单词数与初始化单词Map<>集合分开的,并且在创建Map<>集合时,先使用了split()分割字符串,然后使用正则表达式匹配,这种做法是没有问题的,但是我一开始没用考虑到的当单词数非常大的时候,查询单词和创建Map<>集合都需要消耗匹配单词的时间,并且由于使用了split(),创建集合时还需要先进行分隔并且需要String[]来保存分隔后的字符,这样一来也耗费了很多空间去存储这个给临时变量,代码如下:
public static void creatWordMap(String chStr, Map<String, Integer> wordMap){
//匹配分隔符分离单词,并用String[]保存
String[] words = chStr.split("\\s");
String regexWord = "[a-zA-Z]{4,}[a-zA-Z0-9]*";
//验证单词有效性,有效的单词存入集合Map<String, Integer>中
for(int i = 0; i < words.length; i++){
if(words[i].matches(regexWord)) {
//忽略单词大小写,判断其是否已经存在,若存在,则其value值加一
if(wordMap.containsKey(words[i].toLowerCase())){
int value = 1 + wordMap.get(words[i].toLowerCase());
wordMap.put(words[i], value);
}
//若不存在,则存入wordMap
else {
wordMap.put(words[i], 1);
}
}
}
为了改进代码,我将creatWordMap()方法删除,考虑将其整合至计算单词数使用的方法getWordNum()中,并且放弃使用split,转而使用matcher.find()匹配字符串,然后使用mathcer.group(2)方法来提取单词,然后存入Map,改善后,明显看到程序运行时间得到改善,用同样的方法测试,结果如图:

单元测试
编写了测试类LibTest,编写了相关方法进行测试,使用循环构造字符串,然后测试对应方法
- 字符数量测试,代码如下:
void testCharacters(){
String sample = "tree12\nword11\nword apple23 banana word200 word8 word15\nhuman3000 sfss";
String testStr = "";
long a= System.currentTimeMillis();
int loop = 10000;
for(int i = 0; i < loop; i++) {
testStr += sample;
}
System.out.print("字符生成时间:");
System.out.println(System.currentTimeMillis()-a+"毫秒");
long b = System.currentTimeMillis();
Lib lib = new Lib();
lib.getCharactersNum(testStr);
System.out.print("获得字符数量时间:");
System.out.println(System.currentTimeMillis()-b+"毫秒\n");
// System.out.println("characters:"+lib.getCharactersNum(testStr));
}
- 行数测试,代码如下:
void testLines(){
String sample = "tree12\nword11\nword apple23 banana word200 word8 word15\nhuman3000 sfss";
String testStr = "";
long a= System.currentTimeMillis();
int loop = 10000;
for(int i = 0; i < loop; i++) {
testStr += sample;
}
System.out.print("字符生成时间:");
System.out.println(System.currentTimeMillis()-a+"毫秒");
long b = System.currentTimeMillis();
Lib lib = new Lib();
lib.getLinesNum(testStr);
System.out.print("获得行数时间:");
System.out.println(System.currentTimeMillis()-b+"毫秒\n");
// System.out.println("Lines:"+lib.getLines(testStr));
}
- 单词数测试,代码如下:
//单词数测试
void testWords(){
String sample = "tree12\nword11\nword apple23 banana word200 word8 word15\nhuman3000 sfss";
String testStr = "";
long a= System.currentTimeMillis();
int loop = 10000;
for(int i = 0; i < loop; i++) {
testStr += sample;
}
System.out.print("字符生成时间:");
System.out.println(System.currentTimeMillis()-a+"毫秒");
long b = System.currentTimeMillis();
Lib lib = new Lib();
lib.getWordNum(testStr);
System.out.print("获得单词数时间:");
System.out.println(System.currentTimeMillis()-b+"毫秒\n");
// System.out.println("words:"+lib.getWordNum(testStr));
}
- 词频测试,代码如下:
//词频测试
void testSort() {
String sample = "tree12\nword11\nword apple23 banana word200 word8 word15\nhuman3000 sfss";
String testStr = "";
long a= System.currentTimeMillis();
int loop = 10000;
for(int i = 0; i < loop; i++) {
testStr += sample;
}
System.out.print("字符生成时间:");
System.out.println(System.currentTimeMillis()-a+"毫秒");
long b = System.currentTimeMillis();
Lib lib = new Lib();
List<Map.Entry<String, Integer>> topTenWords = new ArrayList<Map.Entry<String, Integer>>();
topTenWords = lib.sortWordMap();
System.out.print("获得十大单词时间:");
System.out.println(System.currentTimeMillis()-b+"毫秒\n");
for(Map.Entry<String,Integer> map : topTenWords) {
System.out.println(map.getKey()+":"+map.getValue());
}
}
测试结果
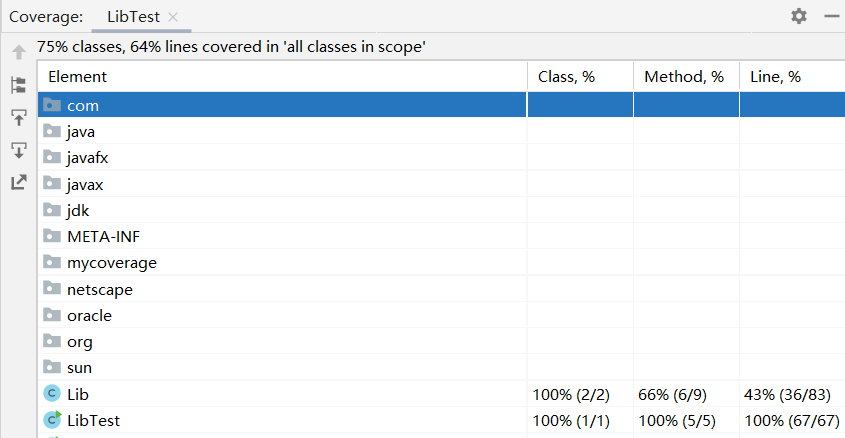
- 使用LibTest测试(未对文件读写进行测试),字符串为上图中循环得到的字符串,
测试结果及覆盖率:
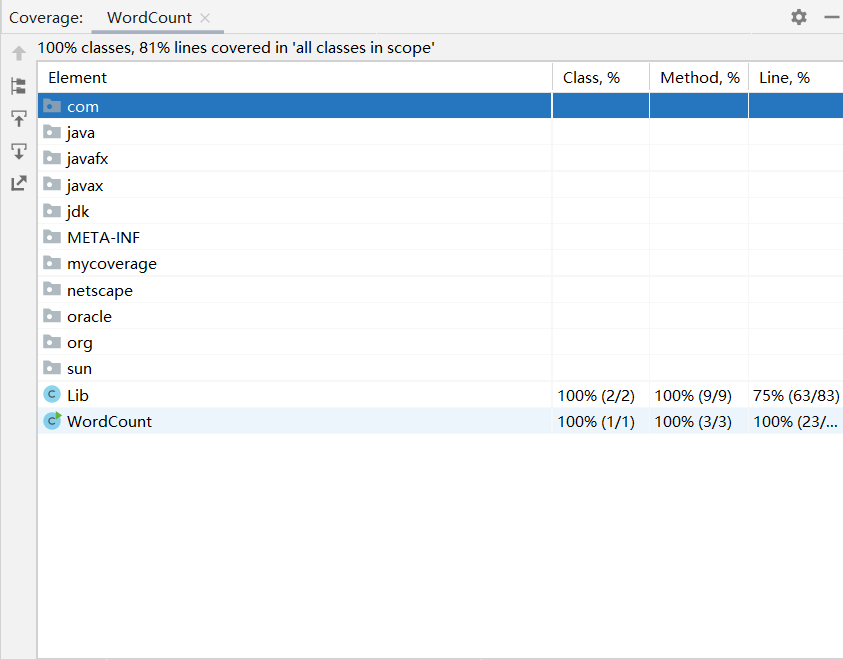
- 使用WorCount测试,100mb文件,包含几篇文章,文件如图:
测试结果及覆盖率:

异常处理说明
只在有文件读写方法中进行了简单的IO异常处理,没有单独编写异常类。命令行传入参数时,会对args[]进行判断。
心路历程与收获
通过这次的作业,我得到了如下收获:
- 我再次温习了java的一些知识点,也学会了使用正则表达式和Patter以及Matcher类的一些方法
- 学会使用了Git以及Github desktop,并喜欢上这种模式。
- 学会了使用PSP表格对项目进行预估,帮助自己合理分配时间
- 初步了解并实践了单元测试,对代码进行了分析后提升了性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号