使用sklearn中的BaggingClassifier去实现bagging分类
使用sklearn去实现bagging分类
这里采用3次10折交叉验证
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, # 样本数目
n_features=20, # 特征数目
n_informative=15, # 有效特征数目
n_redundant=5, #冗余特征数目
# n_repeated=0, # 重复特征个数(有效特征和冗余特征的随机组合)
# n_classes=3, # 样本类别
# n_clusters_per_class=1, # 簇的个数
random_state=5)
# summarize the dataset
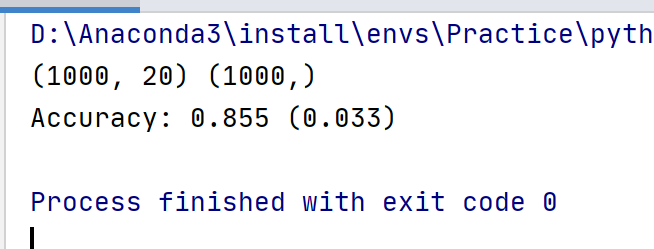
print(X.shape, y.shape)
# evaluate bagging algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.ensemble import BaggingClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=5)
# define the model
model = BaggingClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) #重复三次的10折交叉验证
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号