制作VOC数据集
- 摄像头采集样张
使用opencv,外接摄像头,按一定帧率采集图像,代码如下:
import cv2 as cv
cap = cv.VideoCapture(0)
fourcc = cv.VideoWriter_fourcc('X', 'V', 'I', 'D')
out = cv.VideoWriter(r'C:\Users\chen\Desktop\PyTorch练习\output.avi', fourcc, 20.0, (640,480))
i = 0
while cap.isOpened():
i = i+1
ret, frame = cap.read()
if not ret:
break
frame = cv.flip(frame, 1)
if i%10 == 0:
j = i//10
cv.imwrite(str(j) + '.jpg', frame)
#cv.line(frame, (0,0),(639,479),(255,0,0),15)
out.write(frame)
cv.imshow('frame', frame)
if cv.waitKey(1) == ord('q'):
break
cap.release()
out.release()
cv.destroyAllWindows()
- 标注
工具Windows10+Python3.7+LableImg
1.下载LableImg
链接:https://pan.baidu.com/s/1u-S42NUrDeyAz53IE7E_3g 密码:hxsz
2.安装Python
3.配置环境
打开cmd,依次输入
pip install PyQt5
pip install pyqt5-tools
pip install lxml
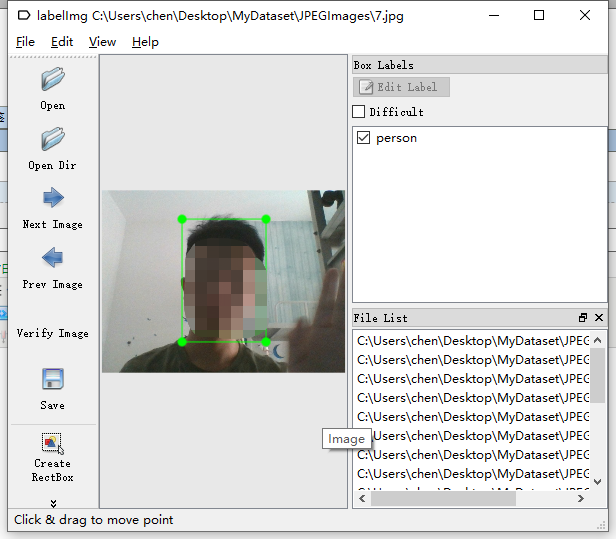
4.标注
双击软件,开始标注(在/data/文件中编辑自己的类别)
- 生成Main文件中的txt文件
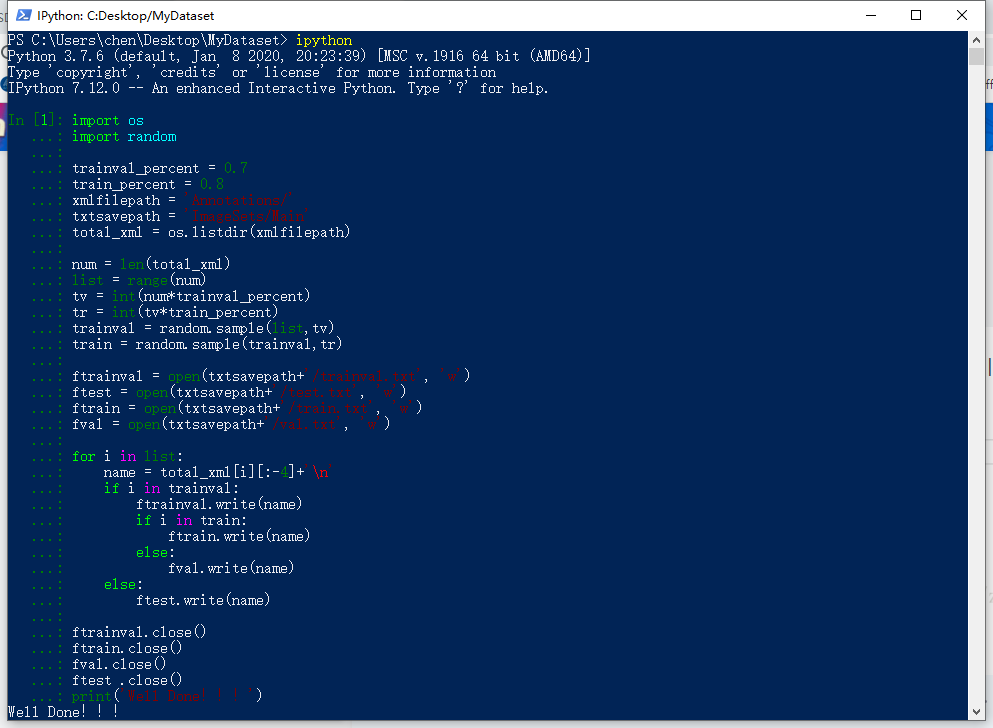
在数据集根目录下,我的是Mydataset文件夹,按住shift+鼠标右键,选择powershell,键入ipython
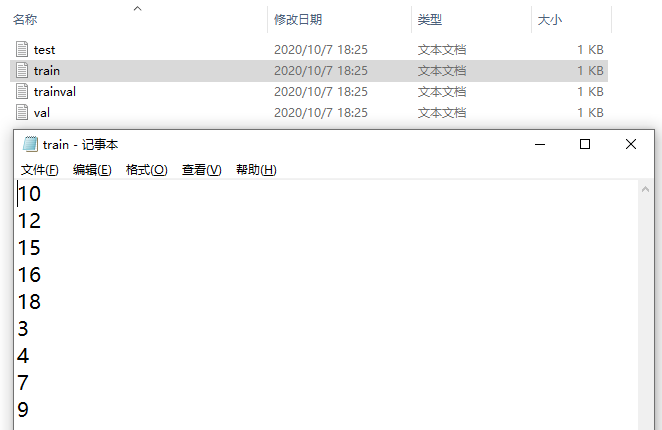
输入如下代码,即可在Main文件中生成4个txt文件。一共是2-19,共18张图,train9个(12x0.8=9.6=9),test6个,val3个,trainval12个(18x0.7=12.6=12)
import os
import random
trainval_percent = 0.7
train_percent = 0.8
xmlfilepath = 'Annotations/'
txtsavepath = 'ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval = random.sample(list,tv)
train = random.sample(trainval,tr)
ftrainval = open(txtsavepath+'/trainval.txt', 'w')
ftest = open(txtsavepath+'/test.txt', 'w')
ftrain = open(txtsavepath+'/train.txt', 'w')
fval = open(txtsavepath+'/val.txt', 'w')
for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
print('Well Done!!!')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号