七、超参数调试、Batch正则化
1、调整过程
在训练神经网络时,超参数的调试十分重要,下面分享一些指导原则。

通常来说,①学习因子α是最重要的超参数,也是需要重点调试的超参数。②动量梯度下降因子beta、各隐藏层神经元个数hidden units和mini-batch size的重要性仅次于alpha。③然后就是神经网络层数layers和学习因子下降参数learning rate decay。④最后,Adam算法的三个参数bata1,bata2,sigma一般常设置为0.9,0.999和10^-8,不需要反复调试。当然,这里超参数重要性的排名并不是绝对的,具体情况,具体分析。
当你尝试调整一些超参数时,在深度学习领域,推荐随机选择点,另一个惯例是采用由粗糙到精细的策略。

2、为超参数选择合适的范围
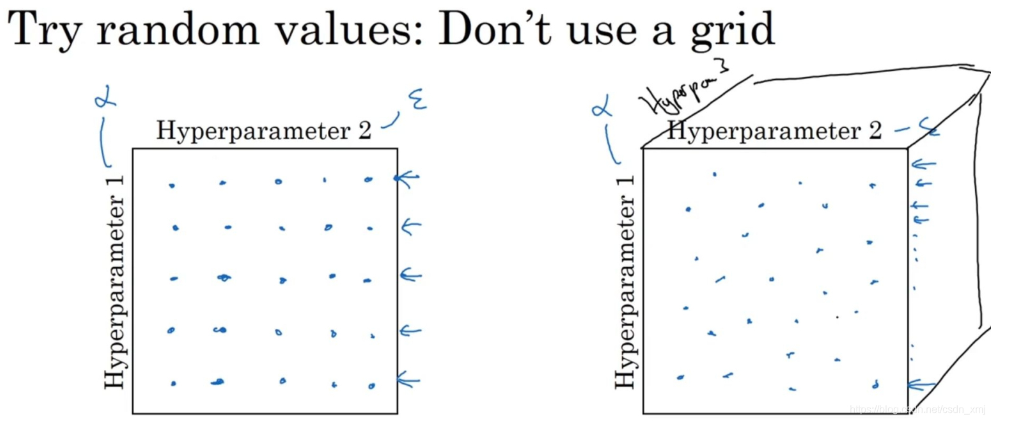
在超参数范围中,随机取值可以提升你的搜索效率。但随机取值并不是在有效范围内的随机均匀取值,而是选择合适的标尺,用于探究这些超参数,这很重要。
对于某些超参数(隐藏单元的数量或者神经网络的层数)是可以进行尺度均匀采样的,它们都是正整数,是可以进行均匀随机采样的(即超参数每次变化的尺度都是一致的),这是合理的。

某些超参数需要选择不同的合适尺度进行随机采样。设你在搜索超参数α(学习速率),假设你怀疑其值最小是0.0001或最大是1。如果你画一条从0.0001到1的数轴,沿其随机均匀取值,那90%的数值将会落在0.1到1之间,结果就是,在0.1到1之间,应用了90%的资源,而在0.0001到0.1之间,只有10%的搜索资源,这看上去不太对。反而,用对数标尺搜索超参数的方式会更合理,因此这里不使用线性轴,分别依次取0.0001,0.001,0.01,0.1,1,在对数轴上均匀随机取点。
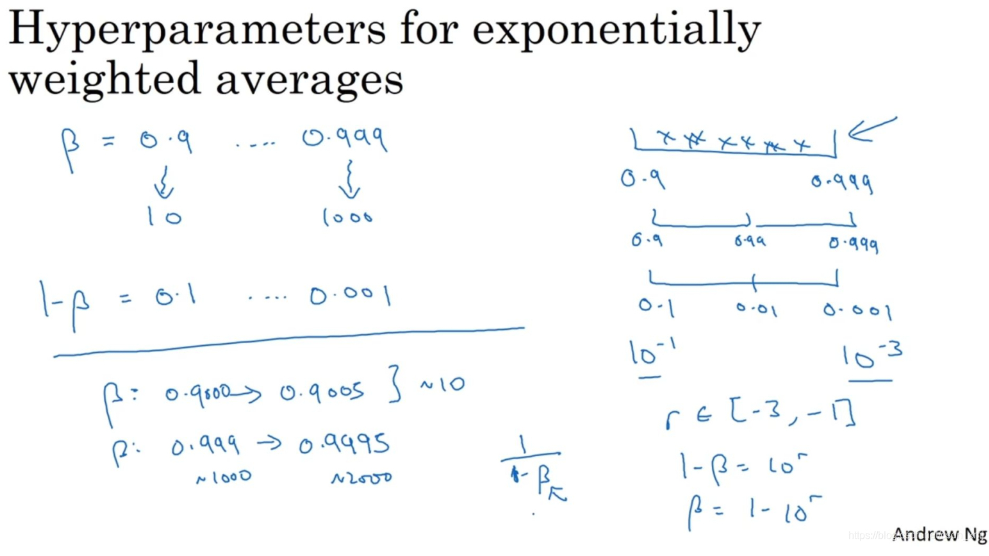
除了α之外,动量梯度因子β(用于计算指数的加权平均数)的取值也是一样,在超参数调试的时候也需要进行非均匀采样,因为当β越接近1时,所得结果的灵敏度(sensitivity)会变化,即使只有微小的变化,所以需要更加密集地取值。一般β的取值范围在[0.9, 0.999]之间,那么1−β的取值范围就在[0.001, 0.1]之间。那么直接对1−β在[0.001, 0.1]区间内进行log变换即可。
3、超参数调试实践:Pandas VS Caviar
如今的深度学习(deep learning)已经应用到许多不同的领域,某个应用领域的超参数设定,有可能通用于另一领域,不同的应用领域出现相互交融。关于如何搜索超参数的问题,人们通常采用的两种重要但不同的方式,分别如下图所示:
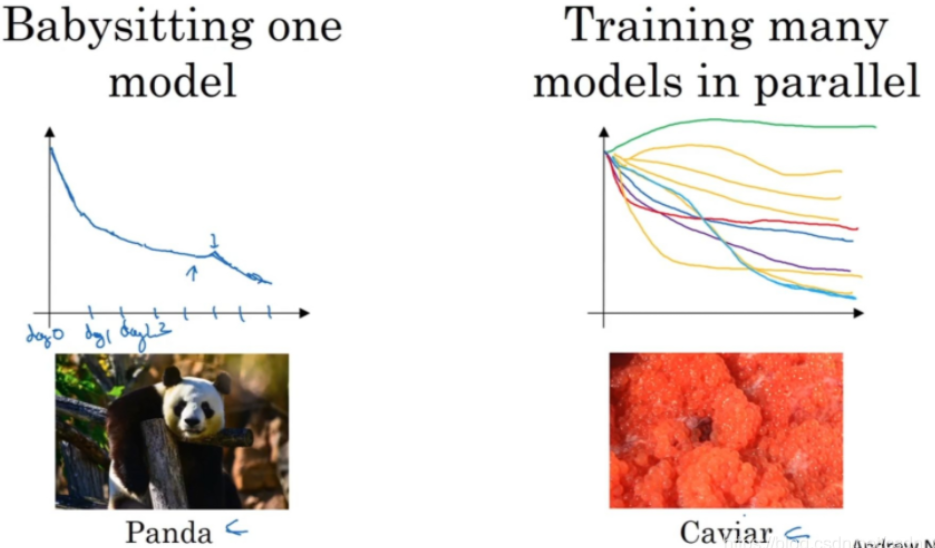
一种是照看一个模型(babysit one model),通常有庞大的数据组,但是没有许多计算资源或足够的CPU和GPU,这样的话一次试验一个模型或者一小批模型,然后每天花时间观察它,不断调整参数,如上图左。
另一种方法则是同时试验多种模型,已经设置了一些超参数,让它自己运行,或者是一天甚至多天,然后会获得像这样的学习曲线,这可以是损失函数 J 或训练误差的损失或数据误差的损失,但都是曲线轨迹的度量,如上图右。
4、归一化网络的激活函数
在深度学习兴起后,最重要的一个思想是它的一种算法,叫做Batch归一化(Batch Normalization)。Batch归一化旨在加速神经网络训练并提高模型的泛化能力。通过对每个mini-batch内的激活值进行归一化,Batch归一化能够有效地缓解梯度消失和梯度爆炸的问题,使得模型在深层网络中表现更加稳定。
Batch归一化还有一个作用,它有轻微的正则化效果(不要当做是正则化,正则化效果微弱),它的特点表现为:
- 加速训练:Batch归一化可以使得模型的训练更加稳定,允许使用更高的学习率,从而加速了训练过程。
- 减轻梯度消失和梯度爆炸问题
- 减少对参数初始化的敏感性:Batch归一化可以让模型对权重初始化不那么敏感,即使是较差的权重初始化,也能通过归一化操作纠正输入分布,从而加快收敛。
- 一定程度的正则化效果:由于每个mini-batch的数据都不一样,因此Batch归一化会在训练中引入一些噪声,这种噪声在一定程度上具有正则化效果,能够减少模型的过拟合。
- 依赖mini-batch的大小:Batch归一化依赖于mini-batch的大小,较小的mini-batch可能导致均值和方差估计不准确,影响训练效果。
5、Softmax回归(Softmax Regression)
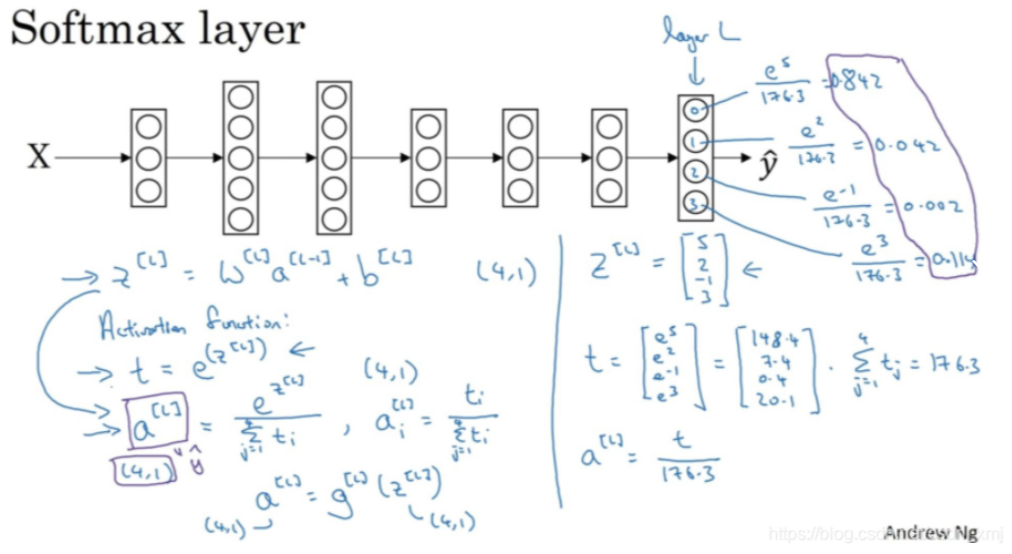
Softmax回归(Softmax Regression)是分类问题中的一种常见方法,特别适用于多分类问题。它是逻辑回归的扩展版,逻辑回归通常用于二分类问题,而Softmax回归则用于处理多个类别的分类任务。
Softmax回归模型的核心思想是通过Softmax函数将模型的输出转化为每个类别的概率分布,并选择概率最大的类别作为最终的预测结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号