三、逻辑回归logistic regression——分类问题
3.1 线性回归对于分类问题的局限性
由于离群点的存在,线性回归不适用于分类问题。如下图(阈值为0.5),由于最右离群点,再用线性回归与实际情况不拟合。引入 逻辑回归(logistic regression) 算法,来解决这个问题。
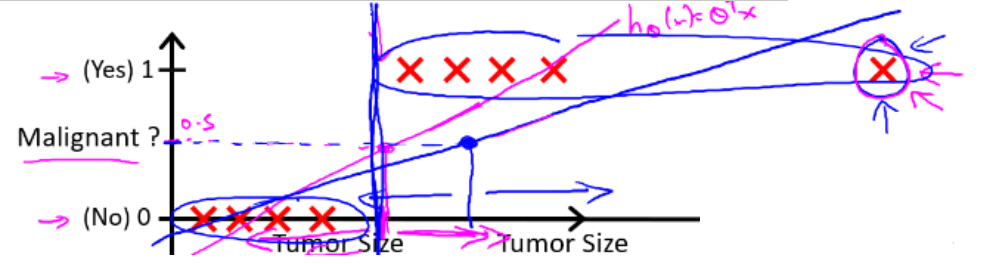
- 逻辑回归模型

3.2 决策边界 decision boundary
- 什么情况下是分界线
- eg1
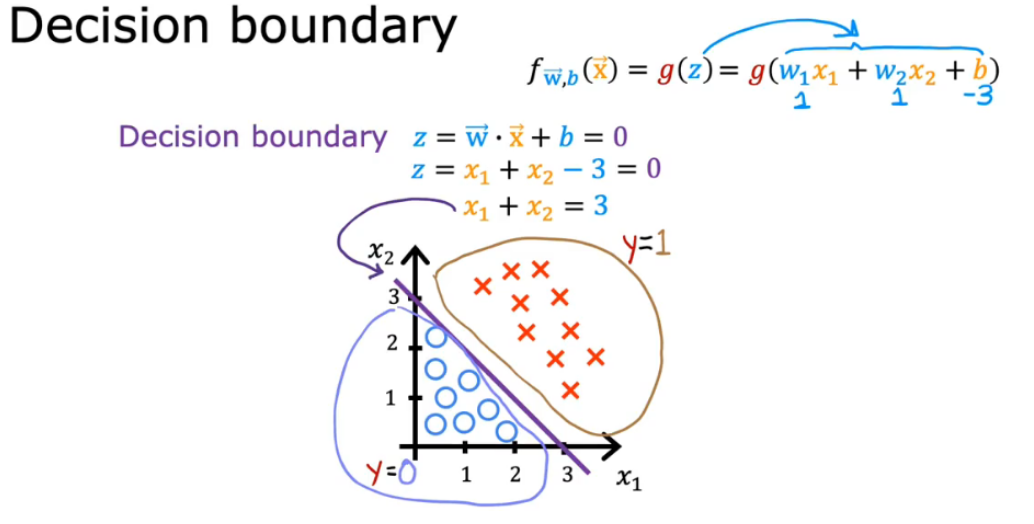
- eg2

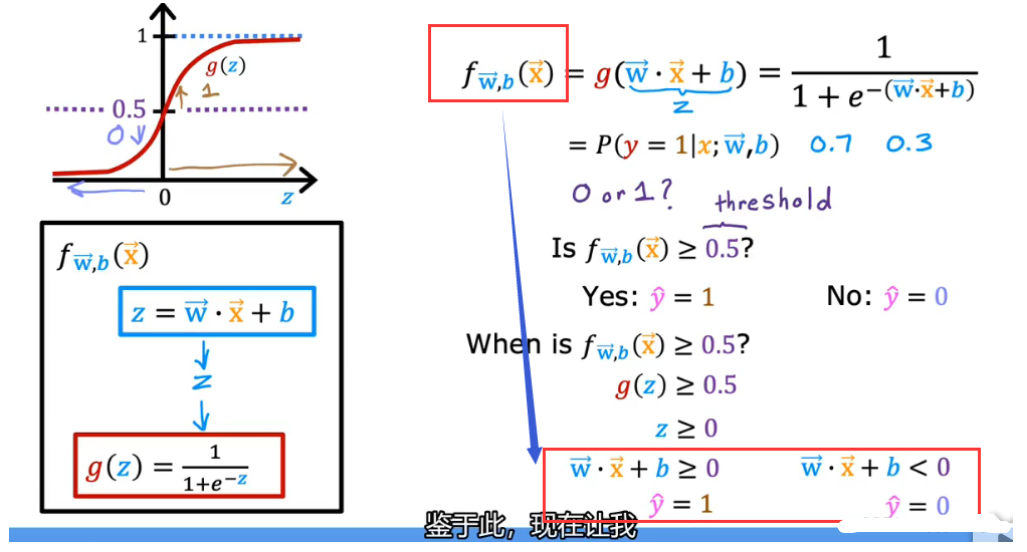
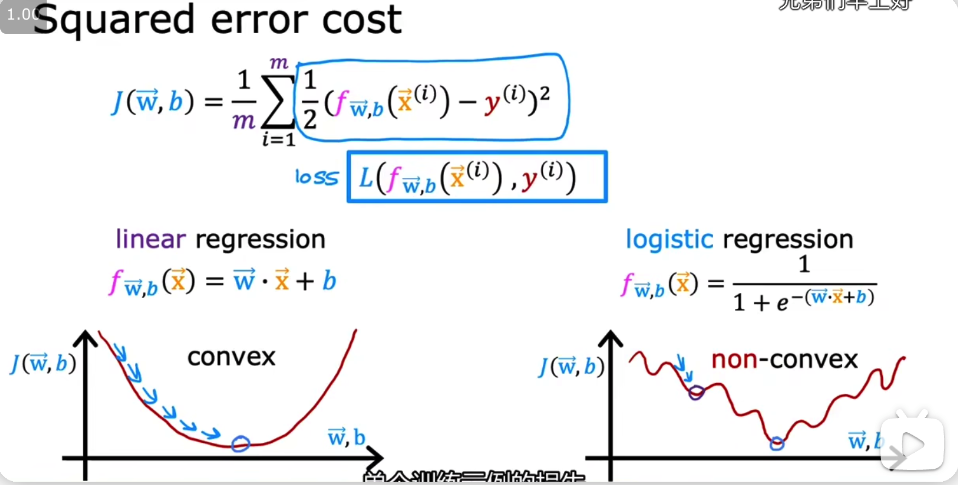
3.3 代价函数 cost function
3.3.1 cost function的导出
- 线性回归的损失函数J 采用的是平方误差squared error cost,应用到分类问题时候的J图像不是convext凸函数,无法用梯度下降找到全局最小值!
![]()
- 将线性回归的代价函数改写为如下形式 (即把1/2提到后面去)得到逻辑回归的cost function
![]()
- 定义loss function
![]()
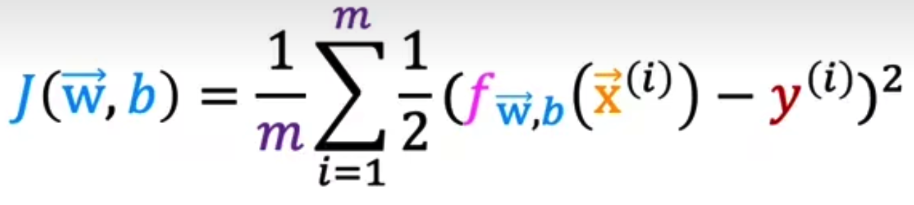
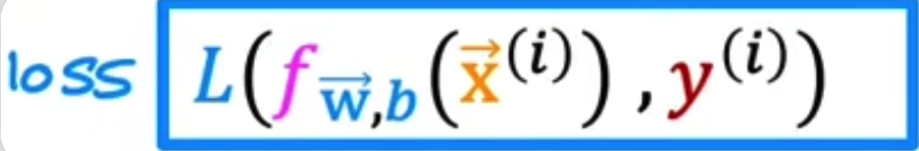
注意区分loss function和cost function
损失函数 loss function是在一个训练样本的表现,把所有训练样本的损失加起来得到的代价函数cost function,才能衡量模型在整个训练集上的表现
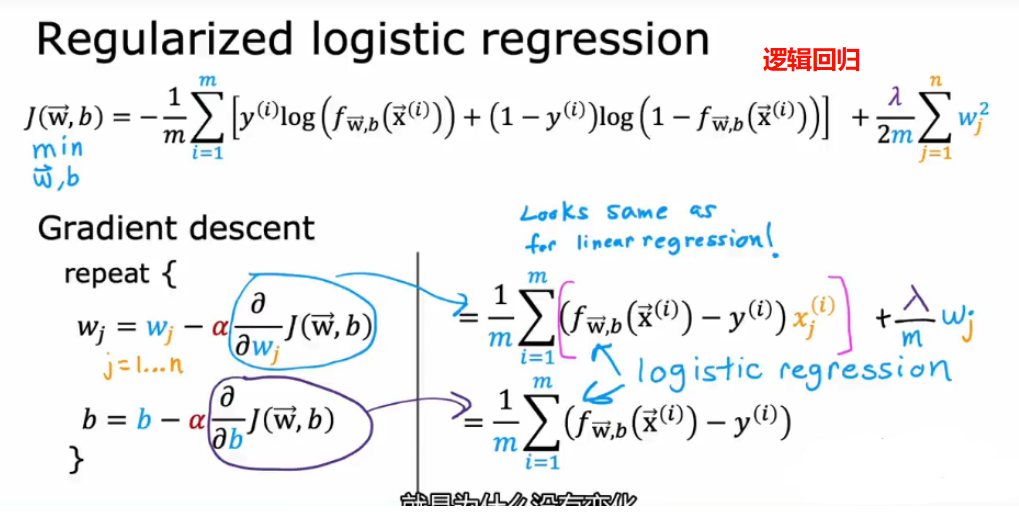
3.3.2 逻辑回归的代价函数和梯度下降
把分类讨论巧妙利用条件合并为一个式子

进而得到的cost function J 为
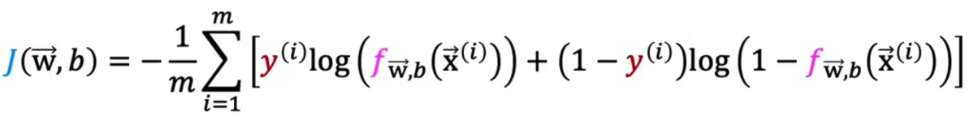
- 梯度下降
![]()
- 注意:逻辑回归的梯度下降看似与线性回归的梯度下降相同,但本质不同,因为他们的fx的原型不一样

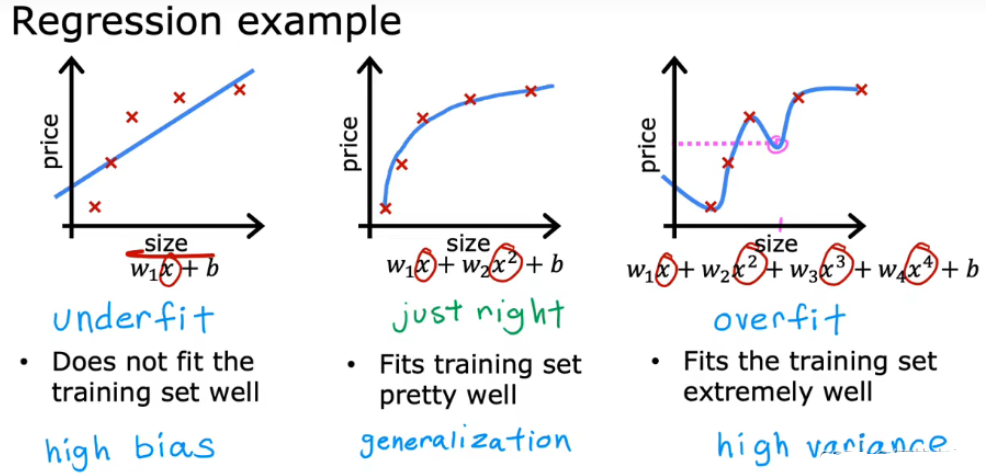
3.4 过拟合问题
3.4.1 过拟合
- 当变量过多时,训练出来的假设能很好地拟合训练集,所以代价函数实际上可能非常接近于0,但得到的曲线为了千方百计的拟合数据集,导致它无法泛化到新的样本中,无法预测新样本数据
- eg
![]()
![]()
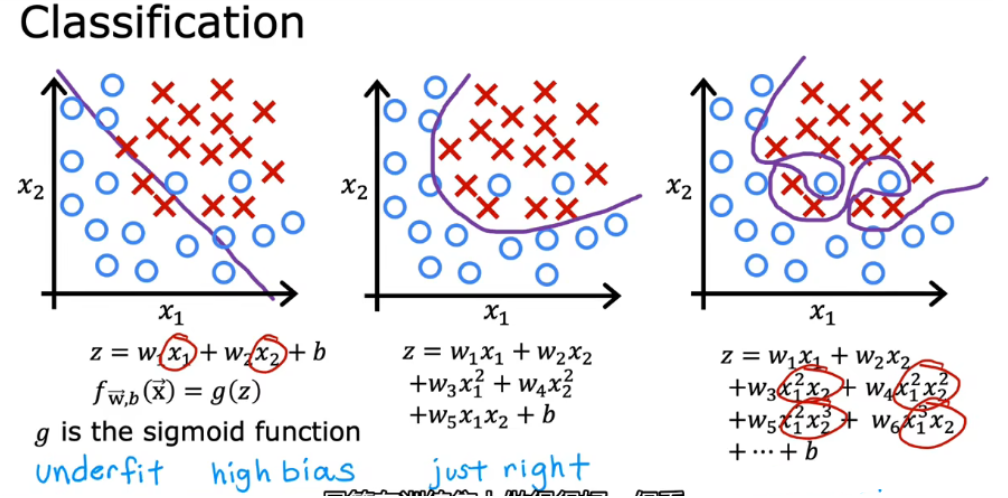
解决过拟合方法:
- 得到更多的数据
- 特征选择——选用特征的一部分
- 正则化——减少参数大小
3.5 过拟合的代价函数(正则化原理)
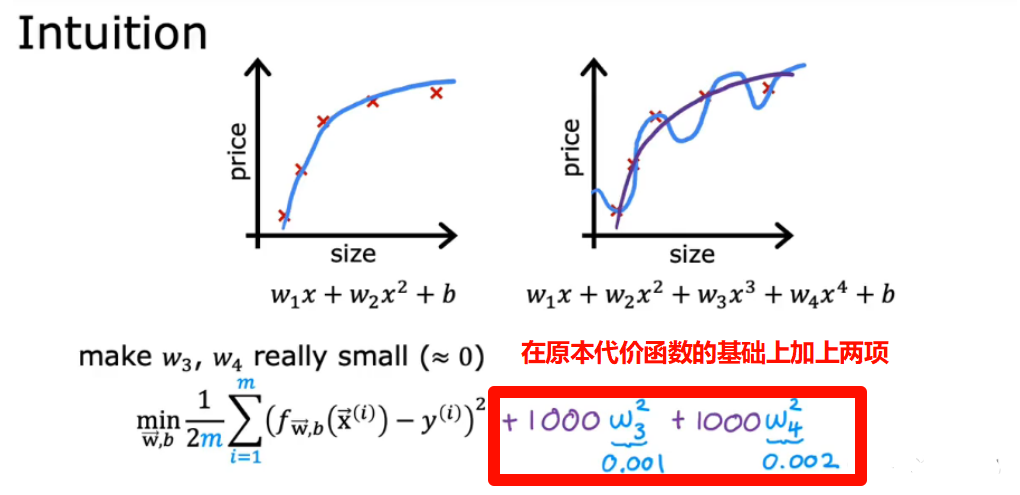
加上两项后,为了最小化代价函数,自然而然地w3,w4要尽可能小,相当于惩罚这两项使得原来的式子变为二次函数
在一般的回归函数中,使参数的值更小一般会使得曲线更为平滑而减少过拟合情况的发生
- 引入正则化项 的代价函数
![]()
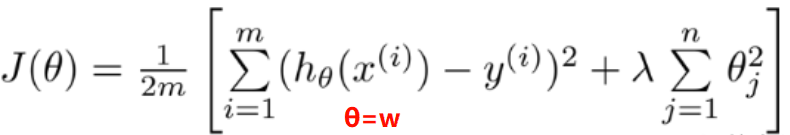
- 如果有很多参数,我们不清楚哪个参数是高阶项,即不知道惩罚哪个能获得更好拟合的结果,因此引入正则化项统一惩罚参数以得到较为简单的函数
- 统一惩罚能得到简单结果是因为,高阶项受到惩罚的效果会更强,反映在图像上就是使其影响变弱
- 其中
.+ 后的一项为正则化项,
λ 为正则化参数,作用是控制两个不同目标之间的取舍
(1)第一个目标与第一项有关,即我们想要更加拟合数据集 fit data!
(2)第二个目标与第二项有关,即我们想要参数θj尽量小 keep wj samll - 惩罚从w1到wn,不包括b(之所以不惩罚b是为了让拟合的函数尽量简单,极端情况就是hw(x) = b,代表的一条水平线,不过实操中有无b影响不大)
- 若 λ 设置的过大,即对w1w2w3w4的惩罚程度过大,导致w1w2w3w4都接近于0,最后假设模型只剩一个b,出现欠拟合情况
3.6 用于线性回归和逻辑回归的正则方法
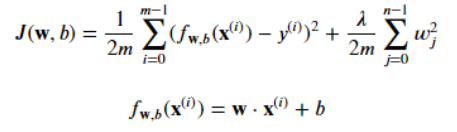
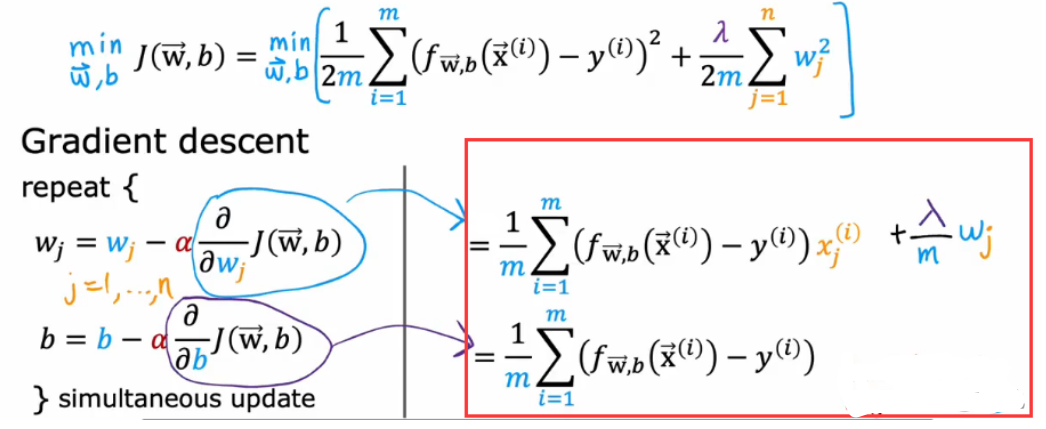
- 因为我们没有对b正则化,没有试图去缩小b,因此求偏导没有影响
3.7 课后作业
# 在这部分的练习中,你将建立一个逻辑回归模型来预测一个学生是否能进入大学。假设你是一所大学的行政管理人员,
# 你想根据两门考试的结果,来决定每个申请人是否被录取。你有以前申请人的历史数据,可以将其用作逻辑回归训练集。
# 对于每一个训练样本,你有申请人两次测评的分数以及录取的结果。为了完成这个预测任务,
# 我们准备构建一个可以基于两次测试评分来评估录取可能性的分类模型。
# %matplotlib inline 用于 Jupyter Notebook 中以在笔记本中直接显示Matplotlib绘制的图形,而不是在单独的窗口中弹出。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import scipy.optimize as opt
data = pd.read_csv('ex2data1.txt', names=['exam1', 'exam2', 'admitted'])
# 在开始实现任何学习算法之前,如果可能的话,最好将数据可视化。
data.head()
data.describe()
# print(data.dtypes)
# 根据 admitted 列中的值对数据进行过滤,并分别创建两个新的 DataFrame:positive 和 negative,这里查明了admitted列的值整数类型
positive = data[data.admitted.isin([1])] # 1
negetive = data[data.admitted.isin([0])] # 0
fig, ax = plt.subplots(figsize=(6, 5))
ax.scatter(positive['exam1'], positive['exam2'], c='b', label='Admitted')
ax.scatter(negetive['exam1'], negetive['exam2'], s=50, c='r', marker='x', label='No Admitted') # marker 参数指定了点的形状
# 设置图例显示在图的上方
box = ax.get_position()
ax.set_position([box.x0, box.y0, box.width, box.height * 0.8])
ax.legend(loc='center left', bbox_to_anchor=(0.2, 1.12), ncol=3)
# 设置横纵坐标名
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
# plt.show()
# 通过散点图,看起来在两类间,有一个清晰的决策边界。现在我们需要实现逻辑回归,那样就可以训练一个模型来预测结果。
# Sigmoid function
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 做一个快速的检查,来确保它可以工作。
# x1 = np.arange(-10, 10, 0.1)
# plt.plot(x1, sigmoid(x1), c='r')
# plt.show()
# 逻辑回归Cost function
def cost(theta, X, y):
first = (-y) * np.log(sigmoid(X @ theta))
second = (1 - y) * np.log(1 - sigmoid(X @ theta))
return np.mean(first - second)
# 做一些设置来获取训练集数据
if 'Ones' not in data.columns:
data.insert(0, 'Ones', 1)
X = data.iloc[:, :-1].to_numpy()
y = data.iloc[:, -1].to_numpy()
theta = np.zeros(X.shape[1])
# 检查矩阵维度
# print(X.shape, theta.shape, y.shape)
cost(theta, X, y)
# Gradient
def gradient(theta, X, y):
return (X.T @ (sigmoid(X @ theta) - y)) / len(X)
# 注意,我们实际上没有在这个函数中执行梯度下降,我们仅仅在计算梯度。在练习中,一个称为“fminunc”的Octave函数是用来优化函数来计算成本和梯度参数。
# 由于我们使用Python,我们可以用SciPy的“optimize”命名空间来做同样的事情。
# 这里我们使用的是高级优化算法,运行速度通常远远超过梯度下降。方便快捷。
# 只需传入cost函数,已经所求的变量theta,和梯度。cost函数定义变量时变量tehta要放在第一个,若cost函数只返回cost,
# 则设置fprime = gradient。
# 方法1
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
# result 是 fmin_tnc 返回的一个元组,包含多个元素:
# result[0]:优化后的参数值,即使目标函数最小化的参数。
# result[1]:一个整数代码,表示优化的退出状态(成功、达到最大迭代次数等)。
# result[2]:字典,包含优化过程的信息,如函数调用次数。
result # (array([-25.16131846, 0.20623159, 0.20147148]), 36, 0)
# 方法2
res = opt.minimize(fun=cost, x0=theta, args=(X, y), method='TNC', jac=gradient)
res.x
# 模型预测
def predict(theta, X):
probability = sigmoid(X @ theta)
return [1 if x >= 0.5 else 0 for x in probability]
final_theta = result[0]
predictions = predict(final_theta, X)
correct = [1 if a==b else 0 for (a, b) in zip(predictions, y)]
accuracy = sum(correct) / len(X)
accuracy # 0.89
# Decision boundary(决策边界)
x1 = np.arange(130, step=0.1)
x2 = -(final_theta[0] + x1*final_theta[1]) / final_theta[2]
fig, ax = plt.subplots(figsize=(8,5))
ax.scatter(positive['exam1'], positive['exam2'], c='b', label='Admitted')
ax.scatter(negetive['exam1'], negetive['exam2'], s=50, c='r', marker='x', label='Not Admitted')
ax.plot(x1, x2)
ax.set_xlim(0, 130)
ax.set_ylim(0, 130)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('Decision Boundary')
# plt.show()
# 设想你是工厂的生产主管,你有一些芯片在两次测试中的测试结果。对于这两次测试,你想决定是否芯片要被接受或抛弃。
# 为了帮助你做出艰难的决定,你拥有过去芯片的测试数据集,从其中你可以构建一个逻辑回归模型。
# 将要通过加入正则项提升逻辑回归算法
data2 = pd.read_csv('ex2data2.txt', names=['Test 1', 'Test 2', 'Accepted'])
data2.head()
def plot_data():
positive = data2[data2.Accepted.isin([1])]
negative = data2[data2.Accepted.isin([0])]
fig, ax = plt.subplots(figsize=(8, 5))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative['Test 1'], negative['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.legend()
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
# plt.show()
plot_data()
# 注意到散点图其中的正负两类数据并没有线性的决策界限。因此直接用logistic回归在这个数据集上并不能表现良好,
# 因为它只能用来寻找一个线性的决策边界。
# 所以接下会提到一个新的方法。
# Feature mapping(特征映射)
# 当数据中的关系是非线性的,而你使用的是线性模型(如线性回归或逻辑回归)时,特征映射可以帮助模型捕捉这些非线性关系。
def feature_mapping(x1, x2, power):
data = {}
for i in np.arange(power + 1):
for p in np.arange(i + 1):
data["f{}{}".format(i - p, p)] = np.power(x1, i - p) * np.power(x2, p)
return pd.DataFrame(data) # 将字典data转换为PandasDataFrame返回。每个列名为组合后的特征名,每列的数据为对应的多项式特征值。
x1 = data2['Test 1'].to_numpy()
x2 = data2['Test 2'].to_numpy()
_data2 = feature_mapping(x1, x2, power=6)
_data2.head()
# 经过映射,我们将有两个特征的向量转化成了一个28维的向量。
# 在这个高维特征向量上训练的logistic回归分类器将会有一个更复杂的决策边界,当我们在二维图中绘制时,会出现非线性。
# 虽然特征映射允许我们构建一个更有表现力的分类器,但它也更容易过拟合。
# 在接下来的练习中,我们将实现正则化的logistic回归来拟合数据,并且可以看到正则化如何帮助解决过拟合的问题。
# Regularized Cost function
# 注意:不惩罚第一项b,先获取特征,标签以及参数theta,确保维度良好。
# 这里因为做特征映射的时候已经添加了偏置项,所以不用手动添加了。
X = _data2.to_numpy()
y = data2['Accepted'].to_numpy()
theta = np.zeros(X.shape[1])
X.shape, y.shape, theta.shape # ((118, 28), (118,), (28,))
def costReg(theta, X, y, l=1):
# 不惩罚第一项
_theta = theta[1:]
reg = (l / (2 * len(X))) * (_theta @ _theta) # _theta@_theta == inner product
return cost(theta, X, y) + reg
# Regularized gradient
def gradientReg(theta, X, y, l=1):
reg = (1 / len(X)) * theta
reg[0] = 0
return gradient(theta, X, y) + reg
result2 = opt.fmin_tnc(func=costReg, x0=theta, fprime=gradientReg, args=(X, y, 2))
result2
# Evaluating logistic regression 评估逻辑回归
final_theta = result2[0]
predictions = predict(final_theta, X)
correct = [1 if a==b else 0 for (a, b) in zip(predictions, y)]
accuracy = sum(correct) / len(correct)
accuracy # 0.8135593220338984
# Decision boundary(决策边界)
x = np.linspace(-1, 1.5, 250) # 从 -1 到 1.5 的 250 个等间距点。
xx, yy = np.meshgrid(x, x) # 成一个网格坐标矩阵,其中 xx 和 yy 分别是网格的 x 坐标和 y 坐标。
z = feature_mapping(xx.ravel(), yy.ravel(), 6).to_numpy() # xx.ravel()和yy.ravel():将xx和yy数组展平为一维数组。
z = z @ final_theta
z = z.reshape(xx.shape) # 将计算结果z重新调整为xx的形状,以便于绘制。
plot_data()
plt.contour(xx, yy, z, 0) # 在 z = 0 处绘制等高线,这表示决策边界。
plt.ylim(-.8, 1.2) # 设置 y 轴的显示范围。
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号