二、线性回归
单变量线性回归
2.1 单变量线性函数
假设函数 hθ(x) = θ0 + θ1x
代价函数:平方误差函数或者平方误差代价函数
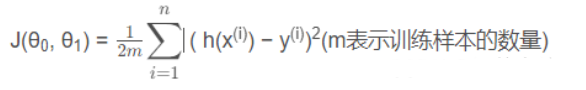
h(x(i))是预测值,也写做y帽,y(i)是实际值,两者取差分母的2是为了后续求偏导更好计算。
目标: 最小化代价函数,即minimize J(θ0, θ1)
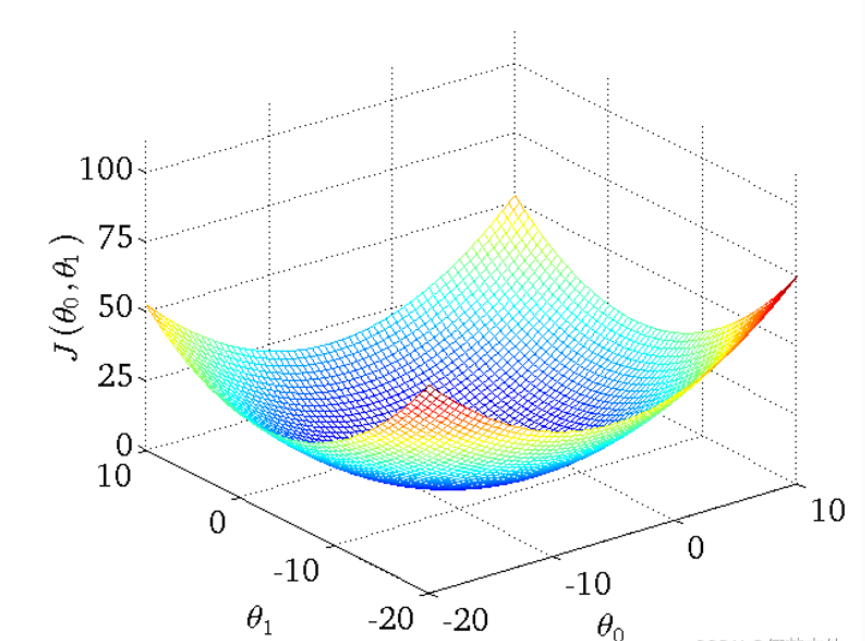
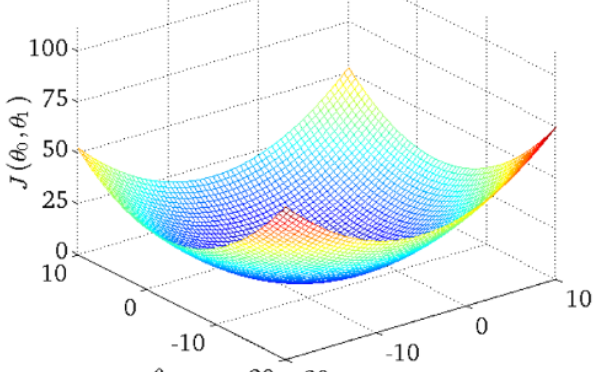
- 得到的代价函数的 三维图如下
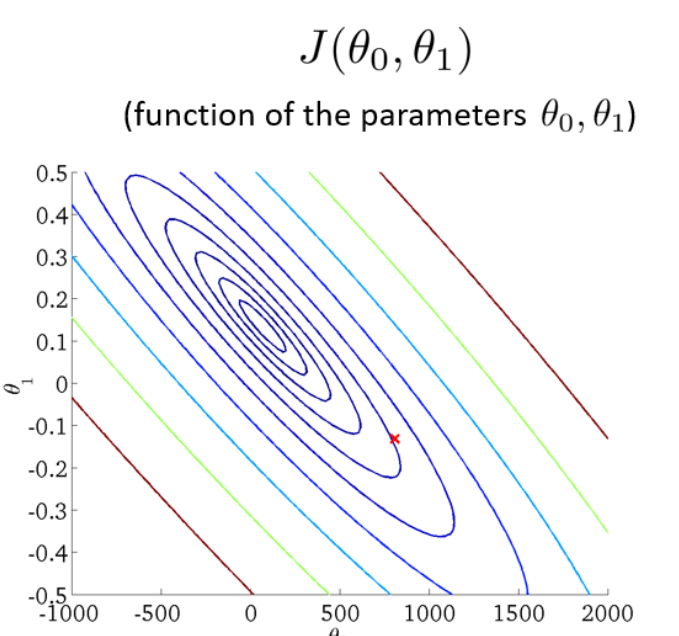
- 将三维图平面化 等高线图 contour plot
等高线的中心对应最小代价函数
2.2 梯度下降算法 Gradient Descent algorithm
算法思路
- 指定θ0 和 θ1的初始值
- 不断改变θ0和θ1的值,使J(θ0,θ1)不断减小
- 得到一个最小值或局部最小值时停止
梯度: 函数中某一点(x, y)的梯度代表函数在该点变化最快的方向
(选用不同的点开始可能达到另一个局部最小值)
梯度下降公式

- θ0和θ1应同步更新,否则如果先更新θ0,会使得θ1是根据更新后的θ0去更新的,与正确结果不相符
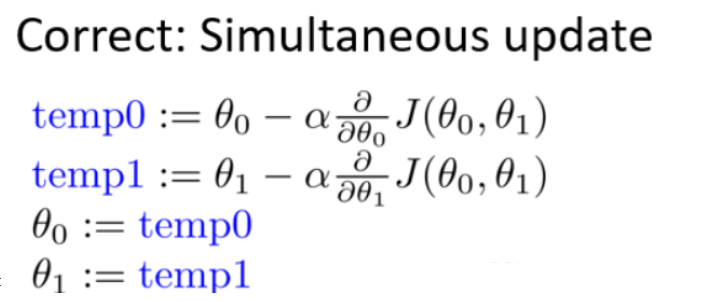
关于α的选择
如果α选择太小,会导致每次移动的步幅都很小,最终需要很多步才能最终收敛
如果α选择太大,会导致每次移动的步幅过大,可能会越过最小值,无法收敛甚至会发散
2.3 用于线性回归的梯度下降 ——Batch梯度下降

- 梯度回归的局限性: 可能得到的是局部最优解
线性回归的梯度下降的函数是凸函数,bowl shape,因此没有局部最优解,只有全局最优解
-
批量梯度下降 代码实现
批处理是指在一次迭代中运行所有的例子
验证梯度下降是否正常工作的一个好方法是看一下𝐽(𝑤,𝑏)的值。并检查它是否每一步都在减少
def gradient_descent(x, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters):
"""
Performs batch gradient descent to learn theta. Updates theta by taking
num_iters gradient steps with learning rate alpha
Args:
x : (ndarray): Shape (m,)
y : (ndarray): Shape (m,)
w_in, b_in : (scalar) Initial values of parameters of the model
cost_function: function to compute cost
gradient_function: function to compute the gradient
alpha : (float) Learning rate
num_iters : (int) number of iterations to run gradient descent
Returns
w : (ndarray): Shape (1,) Updated values of parameters of the model after
running gradient descent
b : (scalar) Updated value of parameter of the model after
running gradient descent
"""
# number of training examples
m = len(x)
# An array to store cost J and w's at each iteration — primarily for graphing later
J_history = []
w_history = []
w = copy.deepcopy(w_in) #avoid modifying global w within function
b = b_in
for i in range(num_iters):
# Calculate the gradient and update the parameters
dj_dw, dj_db = gradient_function(x, y, w, b )
# Update Parameters using w, b, alpha and gradient
w = w - alpha * dj_dw
b = b - alpha * dj_db
# Save cost J at each iteration
if i<100000: # prevent resource exhaustion
cost = cost_function(x, y, w, b)
J_history.append(cost)
# Print cost every at intervals 10 times or as many iterations if < 10
if i% math.ceil(num_iters/10) == 0:
w_history.append(w)
print(f"Iteration {i:4}: Cost {float(J_history[-1]):8.2f} ")
return w, b, J_history, w_history #return w and J,w history for graphing多变量线性回归
2.4 多维特征和特征参数
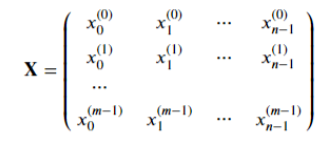
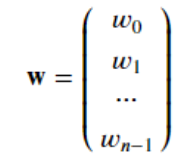
- x(i) 表示第 i 组样本
xj(i) 表示第 i 组样本中的第 j 个数据
2.5 多元变量线性回归模型
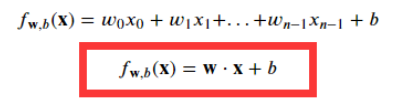
2.6 多元梯度下降法
- 损失函数计算J
![]()
- 计算梯度
![]()
![]()
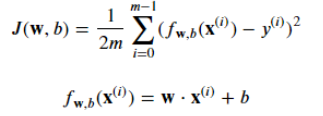
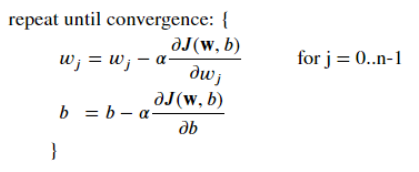
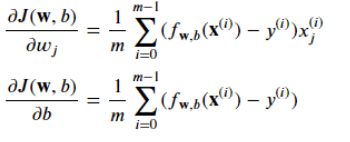
2.7 特征缩放 feature scaling (使具有不同特征值之间有相似的范围)
- 目的:让梯度下降运行的更快
- 问题:当特征范围相差太大时,会一直来回振荡,梯度下降效率低。如下例中,x1范围为0~2000, x2范围为 1~5
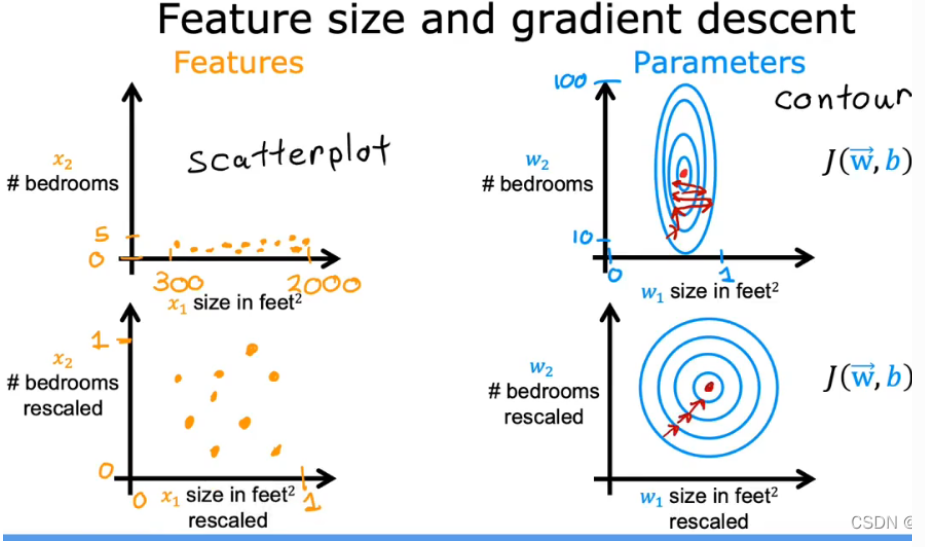
- 为什么要采用特征缩放:在梯度下降过程中对参数的更新可以使每个参数的进展相等
2.7.1 Mean normalization 均值归一化法
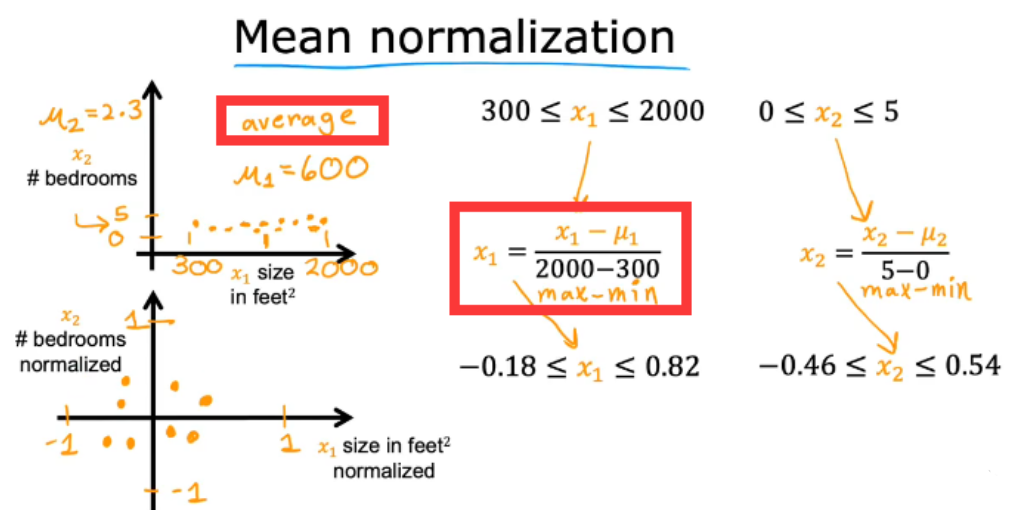
2.7.2 Z-score normalization Z-score归一化法
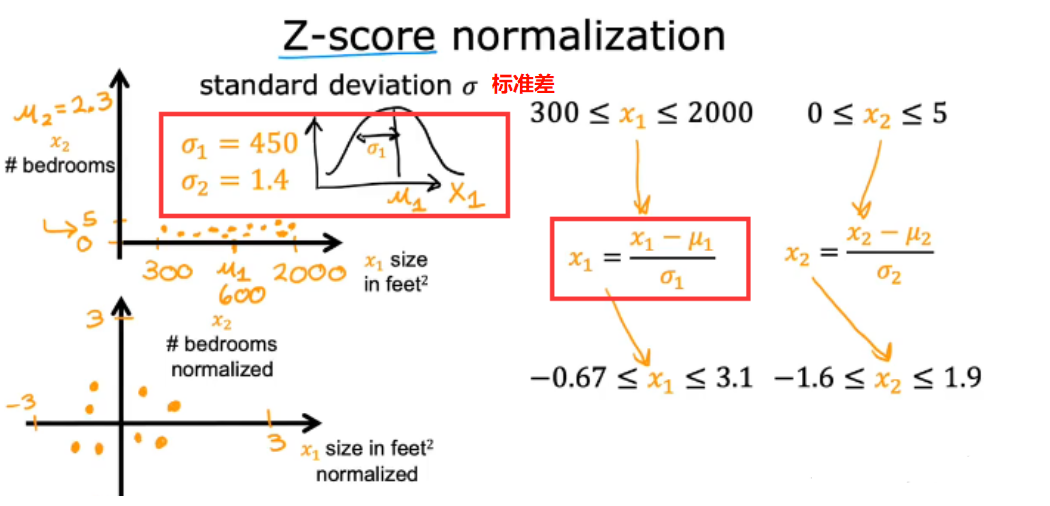
- 最终缩放范围

2.8 如何选择学习率
2.8.1 学习曲线 learning curve
通过学习曲线(左图),可以找到何时可以开始训练我的模型,即多少次iterations后收敛
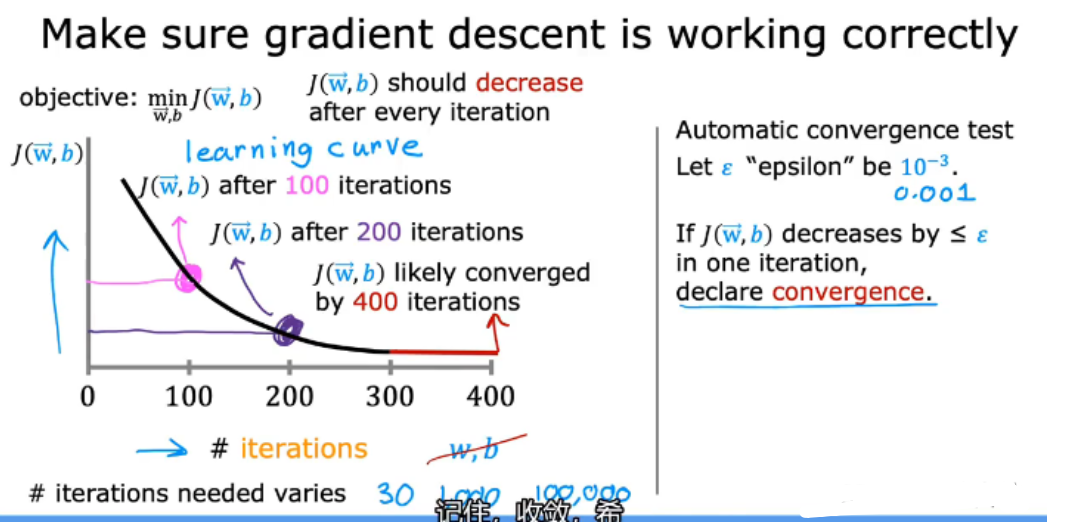
右边为另一种方法:自动收敛测试(没有学习曲线直观)
2.8.2 学习率的选择
- 学习率过大、过小以及J函数求解代码出错都会导致无法得到有效的曲线图
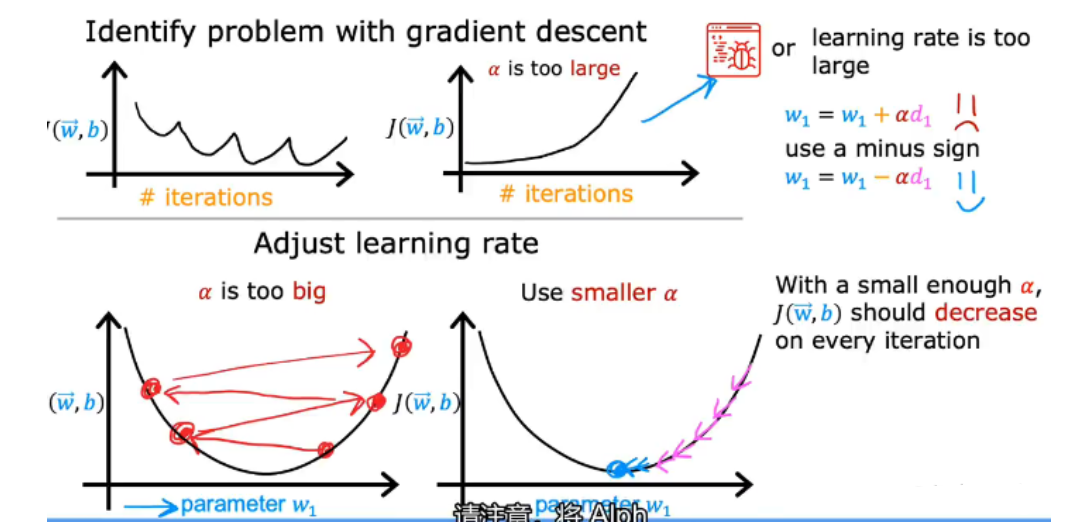
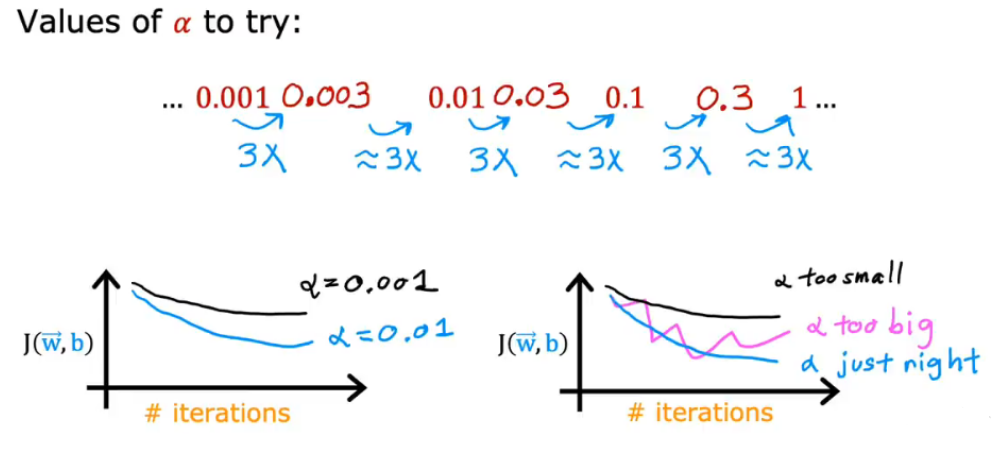
- 选取合适的α:
- …, 0.001,0.003,0.01,0.03,0.1,0.3,1,…
以3为倍数找到一个最大值,以该最大值 或比该最大值略小的值作为α
2.9 特征和多项式回归
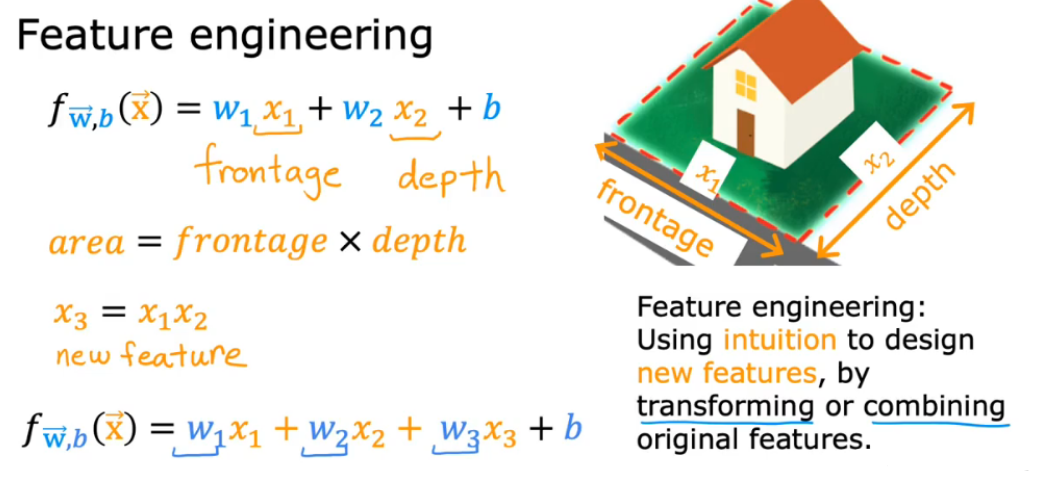
2.9.1 特征工程(通过转换、结合设计新的特征x)
假设有两个特征:x1 是土地宽度,x2 是土地纵向深度,则有hθ(x) = θ0 + θ1x1 + θ2x2
由于房价实际与面积挂钩,所以可假设x = x1 * x2,则有hθ(x) = θ0 + θ1x
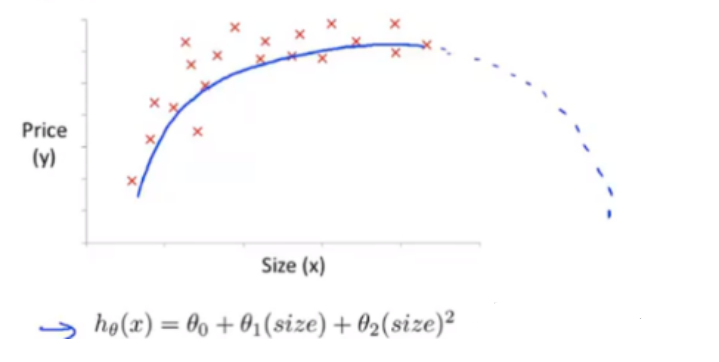
2.9.2 多项式回归
- 选用二次模型拟合
- 房价曲线后半明显下降,不符合实际
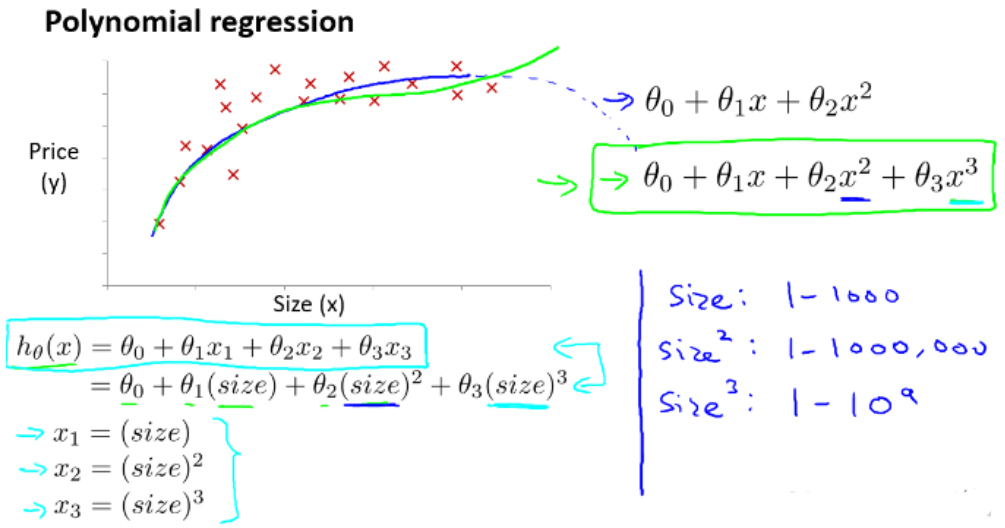
- 选用三次模型规划
- 曲线符合实际,但由于次方的出现,要十分注意自变量范围的选取
特征被重新标定,所以要特征缩放,让它们彼此之间具有可比性
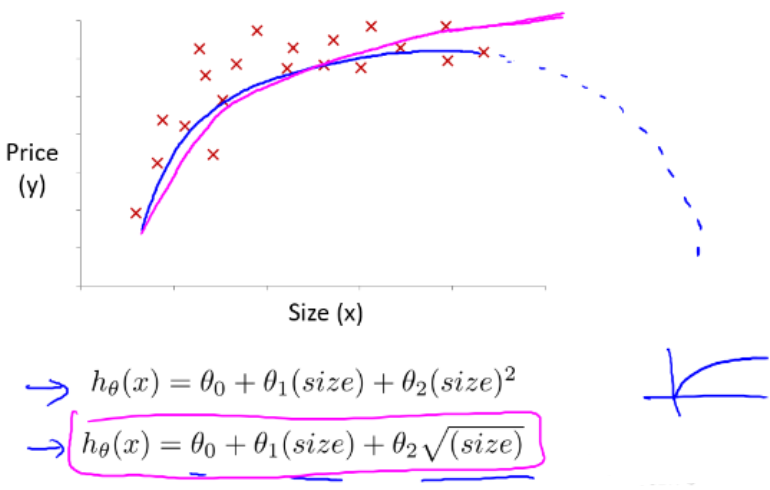
- 选用根号模型
- 能充分拟合,且自变量范围可变曲度大
2.10 课后习题作业
# 在本部分的练习中,您将使用一个变量实现线性回归,以预测食品卡车的利润。假设你是一家餐馆的首席执行官,正在考虑不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,而且你有来自城市的利润和人口数据。
# 您希望使用这些数据来帮助您选择将哪个城市扩展到下一个城市。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('ex1data1.txt',header=None,names=['Population','Profit'])
# names添加列名,header用指定的行来作为标题,若原无标题且指定标题则设为None
data.head()
data.describe
data.plot(kind='scatter',x='Population',y='Profit',figsize=(8,5)) # 该函数不支持设置dpi
# matplotlib 中设置图形大小的语句如下:
# fig = plt.figure(figsize=(a, b), dpi=dpi)
plt.show()
# 代价函数
def computeCost(X,y,theta):
inner = np.power(((X * theta.T)-y), 2) #.T是用于转置矩阵或向量的方法
return np.sum(inner) / (2 * len(X))
data.insert(0, 'ones', 1) # 在最前列插入‘ones’列,并且所有值都为1
# set X(training date) and y (target variable)
cols = data.shape[1] # 输出列数,默认输出行数和列数
X = data.iloc[:,0:cols-1] # 取前cols-1列,即输入向量
y = data.iloc[:,cols-1:cols] # 取最后一列,即目标向量
X.head()
y.head()
# 代价函数应该是numpy矩阵,所以要转换x,y,才能使用它们,还需要初始化theta
# 使用的是matrix而不是array,两者基本通用。matrix适用于进行大量的矩阵乘法和线性代数运算时,
# 两者区别:
# 单独两个元素相乘:matrix可以用np.multiply(X2,X1),array直接X1*X2
# 两个矩阵点乘:matrix直接X1*X2,array可以 X1@X2 或 X1.dot(X2) 或 np.dot(X1, X2)
X = np.matrix(X.values)
y = np.matrix(y.values)
theta = np.matrix([0,0])
# theta是一个(1,2)矩阵
np.array([[0,0]]).shape
# 确认各个参数的维度
X.shape,theta.shape,y.shape
computeCost(X,y,theta)
# 梯度下降函数
def gradientDescent(X,y,theta,alpha,epoch):
temp = np.matrix(np.zeros(theta.shape)) # 初始化一个θ临时矩阵(1, 2)
parameters = int(theta.flatten().shape[1]) # theta.flatten() 将数组 theta 展平为一个一维数组。最后输出参数θ的数量
cost = np.zeros(epoch) # 初始化一个ndarray,包含每次epoch的cost
m = X.shape[0] # 样本数量m
for i in range(epoch):
# 利用向量化vectorization一步求解
temp = theta - (alpha/m) * (X*theta.T - y).T * X
# 以下是不用Vectorization求解梯度下降
# error = (X * theta.T) - y # (97, 1)
# for j in range(parameters):
# term = np.multiply(error, X[:,j]) # (97, 1)
# temp[0,j] = theta[0,j] - ((alpha / m) * np.sum(term)) # (1,1)
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost
alpha = 0.01
epoch = 1000
# 运行梯度下降算法来将我们的参数θ适合于训练集。
final_theta, cost = gradientDescent(X, y, theta, alpha, epoch)
# 使用拟合参数计算训练模型的代价函数(误差)
computeCost(X, y, final_theta)
# 绘制线性模型以及数据,直观的看出它的拟合
# np.linspace()在指定间隔内返回均匀间隔的数字
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 横坐标
f = final_theta[0, 0] + (final_theta[0, 1] * x) # 纵坐标,利润
fig, ax = plt.subplots(figsize=(6, 4))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data['Population'], data.Profit, label='Traning Data')
ax.legend(loc=2) # 2表示在左上角
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
# 绘制代价函数随迭代次数变化图
fig, ax = plt.subplots(figsize=(8,4))
ax.plot(np.arange(epoch), cost, 'r') # np.arange()返回NumPy等差数组
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()
# 练习1还包括一个房屋价格数据集,其中有2个变量(房子的大小,卧室的数量)和目标(房子的价格)。
# 我们使用我们已经应用的技术来分析数据集。
path = 'ex1data2.txt'
data2 = pd.read_csv(path, names=['Size', 'Bedrooms', 'Price'])
data2.head()
# 因为各特征之间的取值范围过大,所以事先对数据集进行特征归一化
data2 = (data2 - data2.mean()) / data2.std()
data2.head()
# add ones column
data2.insert(0, 'Ones', 1)
# set X (training data) and y (target variable)
cols = data2.shape[1]
X2 = data2.iloc[:,0:cols-1]
y2 = data2.iloc[:,cols-1:cols]
# convert to matrices and initialize theta
X2 = np.matrix(X2.values)
y2 = np.matrix(y2.values)
theta2 = np.matrix(np.array([0,0,0]))
# perform linear regression on the data set
g2, cost2 = gradientDescent(X2, y2, theta2, alpha, epoch)
# get the cost (error) of the model
computeCost(X2, y2, g2), g2
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(epoch), cost2, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号